
[This is a guest post by Boris Alexeev. Now over to Boris.]
I’m here to tell you about various exciting developments centering on Erdős problems, especially involving the formalization of old and new mathematics using artificial intelligence.
Background
As is well known, Paul Erdős was a prolific mathematician of the 20th century who posed an extraordinary number of conjectures. Around May 2023, Thomas Bloom set up erdosproblems.com to collect these problems and keep track of progress on them. Over the past 2.5 years, this progress has accelerated as many people realized they could solve problems that were previously unknown to them. In August 2025, Thomas added a forum that became active very quickly, further accelerating developments.
In May 2025, Google DeepMind launched the Formal Conjectures project, an open repository of formalized mathematics conjectures, including (but not at all limited to) Erdős problems. In August 2025, Thomas Bloom and Terence Tao proposed a crowdsourced project to link up erdosproblems.com to the Online Encyclopedia of Integer Sequences (OEIS). These are both part of a greater push to increase the number of mathematical databases, as well as links between them.
At present, there are over 1100 problems on erdosproblems.com, of which approximately 40% have been solved. (Note that only ~100 problems are known to have monetary prizes associated with them.) Approximately 240 problems have statements formalized in Lean, and 17 have solutions formalized in Lean. Approximately 260 problems have been linked to sequences in the OEIS. Alexis Olson has implemented a progress graph displaying these statistics visually over time.
Human formalization without AI
At first, formalization was not a large part of the story with Erdős problems. One of the first developments was several years ago when Thomas Bloom and Bhavik Mehta formalized Bloom’s solution to Problem 47 about unit fractions (and its further applications to several related problems). I would like to highlight a couple of passages from their paper (emphasis mine):
The formalisation began in January 2022 and concluded in July 2022. At the beginning of the formalisation, the first author had no experience with Lean at all, and learnt Lean (or at least a sufficient subset of Lean) through the formalising process.
and
This formalisation is a first in several respects: it is the first recent analytic number theory result to be formally verified; the first instance of the circle method; the first solution to a long-standing problem of Erdős. Part of the motivation for this formalisation was as a proof of concept: the Lean proof assistant and accompanying mathlib is advanced enough to make feasible the fast formalisation of new research results in mathematics, on the same timescale as the production of the ‘human-readable’ paper. Of course, this was made feasible by the relatively elementary and self-contained nature of the mathematics involved. Nonetheless, we believe that this arrangement, with a formal certificate of validation accompanying the human version of the paper, is a sign of things to come.
In this post, I focus mostly on the formalization of solutions that completely resolve a problem, but following this proof, there was a lot of great formalization work for results that don’t technically resolve a problem in full. Luckily, this blog has already featured a guest post by Bhavik Mehta of this kind involving Problem 77. Similarly, last year, there was some extensive work on Problem 216 and separately involving the Hadwiger-Nelson problem (which is Problem 508).
I am not personally aware of any further developments in this area (my apologies to anyone I left out!) until the launch of the Formal Conjectures project. This project, of course, includes the formalization of a large (and increasing) number of the statements of Erdős problems, but does not generally include the formalization of solutions. Nonetheless, it does include a succinct proof by Bhavik Mehta of a counterexample to Problem 316 found by Tom Stobart (slightly smaller than Csaba Sándor’s original counterexample).
Shortly after the launch of the forum on erdosproblems.com, a collaboration between Stijn Cambie, Vjekoslav Kovač, and Terence Tao resolved Problem 379, with the solution formalized in Lean. A couple of days later, Terence Tao also resolved Problem 987 (unaware that Erdős himself had done so) and formalized the solution in Lean. I believe that both of these formalizations were done primarily “by hand”.
Human formalization with AI
Kevin’s latest blog post, discussing the formal and informal approaches to theorem proving, mentioned my paper with Dustin Mixon (and maybe also ChatGPT and Lean — should we have further included Marshall Hall?) resolving Problem 707. There are several fun aspects to that story, and I encourage readers to look at Sections 7 and 1 of our paper for more details (or perhaps they may enjoy a summary). However, the part of the story relevant to formalization is that after the “usual” mathematics was complete, we were able to vibe code the proof in Lean using ChatGPT (without Pro).
While writing the paper, we felt like we were trying a new style of mathematical research: combining large language models with formal verification to produce significant, certifiably correct results. I’m happy to have heard from several friends that our experience motivated them to look into formalizing results in Lean themselves. One mentioned that they hadn’t looked at Lean in three years, and they found that the landscape had changed completely in that time: improvements to Mathlib and Lean, together with the rise of LLMs, made it significantly easier to prove results in a reasonable amount of time. Our experience also motivated Terence Tao to similarly vibe code a solution to Problem 613 by Oleg Pikhurko.
In retrospect, I feel that our paper was written during a very brief window in time when our specific manner of interacting with an LLM and a formal assistant was the most effective manner for a novice to formalize (existing) mathematics. In Section 7 of the paper, we describe what our preferred interaction style would have been using a simple schematic drawing:

This is much closer to reality now. Approximately at the same time as we finished our paper, Harmonic released Aristotle to the general public.
At first, Aristotle could only fill in a sorry in a Lean proof; in other words, given a statement that had already been formalized in Lean, it could (attempt to) supply a proof. This immediately transformed my interactions with Lean. Problem 105 had been recently solved by Wu Xichuan in the forum, and I was able to use ChatGPT to generate formal Lean statements describing the proof, which Aristotle was able to fill in. Before Aristotle, I had tried to formalize this proof with ChatGPT alone, but did not succeed. Note that although Wu’s counterexample is not simple to find, verifying that it works is entirely straightforward. (I was also able to use Aristotle to formalize multiple results from non-Erdős mathematics I was working on. For example, see Section 5.3 of this paper, written in the first person from the perspective of my coauthor Dustin.)
As it turns out, that style of interaction was also a brief moment in time. Shortly thereafter, Aristotle released “informal” mode, which accepts mathematics written in informal language (possibly in LaTeX) and formalizes it all. As a result, Wouter van Doorn, Gemini DeepThink, Terence Tao, Aristotle, and I were able to formalize a solution to part of Problem 367.
I was excited to try using these tools to formalize more solutions. I noticed Problem 418 had recent activity on the forum and that it might be suitable for an experiment. I asked ChatGPT to explain the solution to the problem and then Aristotle to auto-formalize the resulting LaTeX file. The actual theorem statement was already available at the Formal Conjectures project. This process worked beautifully, and I noticed that no intelligent interaction was involved on my part.
As a result, I wrote a pipeline to automate the entire process. After I selected a promising problem number by hand, ChatGPT explained a solution, Aristotle auto-formalized it, and then it was glued together with the statement from the Formal Conjectures project. The solution was verified by Lean and posted automatically to GitHub. My program even wrote a comment on erdosproblems.com for me, but then I would make sure everything looks good before pressing “Post comment”. This process worked perfectly the first time I tried it, on Problem 645. Subsequent runs have revealed that my pipeline is quite fragile, and I occasionally have to intervene manually, but I have run it successfully approximately ten times. Note that ChatGPT is not a necessary component of the formalization step, as Aristotle handles informal text quite well by itself, but I still find it useful for various auxiliary tasks, such as finding the relevant proofs and transcribing (and translating!) PDFs.
Between the pipeline and other uses, Aristotle has now written the majority of the public formalized solutions on erdosproblems.com. (By this, I mean the number of problems, as reported in the community database. If you have solved a problem, whether formally or not, please let someone know either on erdosproblems.com or on the community database!) Furthermore, interaction with Aristotle is currently on the timescale of hours, which while not yet “real time”, is a far cry from the half a year it took at the beginning of this story. The time also mainly consists of waiting, as no interactvity is required or possible (as of today). Given my previous experiences with outdated workflows, I have no doubt that soon, this process will change completely yet again and become even better.
Formalization entirely by AI
Aristotle can also solve problems by itself, achieving gold-medal-equivalent performance on the 2025 International Mathematical Olympiad (IMO) problems.
I was curious what this meant in practice. As a trial run, I found Problem 488, which was available on the Formal Conjectures project and for which Stijn Cambie had already found a counterexample. And indeed, provided only with the formal statement of the problem, Aristotle was able to disprove the conjecture by itself. (Note: the statement of Problem 488 has since been modified.)
Excited, I moved on to open Erdős problems. And so last Friday night, I selected several problems by hand, launched Aristotle, and went to bed. (As mentioned previously, Aristotle runs can take several hours but you don’t have to do anything.) I must say, I was not emotionally prepared to wake up to an email that Aristotle had successfully resolved Problem 124. But after checking its proof and investigating various issues with the precise statement, I saw that indeed, Aristotle had resolved a problem listed by Erdős as open in two collections in 1997 (published shortly after his death).
As can be expected with many “firsts” or other records, there is an “asterisk” regarding this solution. In this case, it seems that Erdős probably intended a different formulation of the problem (and thus unfortunately note: the statement of Problem 124 has since been modified). Much of the discussion online about this accomplishment centered around how simple Aristotle’s solution to the problem was. Indeed, many described it as “Olympiad-level”, which we previously knew was within Aristotle’s capabilities. I would like to offer a different description of the solution: fundamentally, it is from “The Book”. While I agree the solution is simple, I find it remarkable that one of the first open problems resolved in this manner had such a beautiful proof, and I think it’s perfect for an Erdős problem.
Shortly thereafter, Kevin Barreto resolved Problem 481 (not knowing that it had already been resolved by David Klarner in 1982, as that reference was only located later), also with a nice proof. He then made two requests to Aristotle: one to formalize his proof, and one to solve the problem by itself. Both succeeded. Accordingly, this is another problem that Aristotle was able to solve by itself (in Lean), but had been solved by a human already. Afterwards, multiple other teams claimed to have solved these two problems autonomously.
AlphaProof, which produces Lean output, has also autonomously contributed to the community’s knowledge about Erdős problems. For example, it has found an interesting example for Problem 730 and a nice counterexample for Problem 198. The Lean proofs it produces are often reworked manually to be more readable; also, its counterexamples have often caused the problem statements to be changed. Sadly, as a result, no current Lean formalization on erdosproblems.com originates from AlphaProof. (Perhaps AlphaProof or other programs have independently solved more problems, but they have not yet published their results publicly.)
Efforts are underway to autonomously solve even more Erdős problems. Accordingly, I look forward to seeing more formalized proofs of both open and previously-solved problems from Aristotle, AlphaProof, and the other agents becoming available.
Side notes
I am aware of the recent paper about DeepSeekMath-V2, but I have not mentioned it because it has not (yet) directly contributed to formalization on erdosproblems.com. AlphaProof is mentioned briefly above, but I further note that there is a recent AlphaProof paper that may be of interest.
ChatGPT was used to find many problems on erdosproblems.com that had been labeled as “open” but were actually solved. ChatGPT has also been used to help solve (the “sufficiently large” statement of) Problem 848. I did not dive into those topics either because they are not related to formalization, though I will opine that ChatGPT Pro is very useful both for literature review and actual exploratory mathematics.
Misformalization
During my formalization adventures, I have encountered many instances of misformalization. I’m not attempting a full classification here, but they have come in three styles: “low-level” issues like bugs or incorrect definitions, “missing hypotheses” specifically, and “high-level” issues like the human mathematician missing something. Let me give an example of each of these:
- Low-level: The formalization of Problem 480 said
m ≠ 0but meant to sayn ≠ 0. This was discovered when Aristotle found a counterexample taking advantage of this issue, which also happened to interact with the issue of “junk values” in Mathlib. (Problem 480 was solved by Fan Chung and Ron Graham with a very nice solution. I have not yet succeeded in getting Aristotle to formalize the proof.) Similarly, I have seen flipped inequalities, a trivial zero case forgotten, and flipped quantifiers. - Missing hypotheses: in 1994, Rudolf Ahlswede and Levon Khachatrian found a counterexample to Problem 56 with a parameter equal to 212. When I attempted to formalize their proof, Aristotle found a completely trivial counterexample with tiny parameters like 2. It turns out that the conjecture was missing a hypothesis, somewhat implicitly. (I succeeded in formalizing the original proof with the added hypothesis, though not without making a low-level off-by-one error myself in the process.)
- High-level: Problem 124 might fit this description. In 1996, Stefan Burr, Paul Erdős, Ronald Graham, and Winnie Li formulated a particular conjecture, which appears to still be open. Shortly thereafter (just before his death, at age 83), Erdős re-formulated the problem in a slightly different language and altered the hypotheses. Unfortunately, in doing so, he may have missed that this problem has a simple solution. (As discussed above, Aristotle solved this later version autonomously.)
Low-level errors are common in programming, of course, but I think at present mathematicians are probably more likely to make them in Lean than when writing similar code in, say, Python. I think this comes from relative unfamiliarity with Lean, as well as from the fact that the code is not “executed” in the same way. Over time, I expect these errors to decrease in frequency until they’re at a similar baseline level to other programming.
Tools like Aristotle can help find all of these kinds of errors. By itself, finding typos isn’t particularly impressive, but still useful. Finding missing hypotheses is nice, in part because it can help increase the correctness of existing mathematics; some of my first experiences with Lean involved realizing how many more hypotheses were necessary for a statement than I had realized. But perhaps it’s the third category that is most helpful, because as a result, we can focus our attention on the relevant mathematical details.
Takeaways
The world of mathematics formalization is moving fast! Tools for formalizing mathematics are available today and developing quickly. AI is making it much easier to formalize existing mathematics, and it is beginning to create new formalized mathematics by itself.
Some people might be tempted to dismiss the significance of some of these developments because they involve Erdős problems, which are often very accessible and not dependent on deep mathematics. While there is some truth to these thoughts, I feel there are other reasons why we are seeing results here. First, there is a social aspect in which a community of people value Erdős problems and encourage enthusiastic discussion about and collaboration on these problems. Second, this community has curated a large collection of problems available both as informal statements and as formal statements that work in Mathlib today. As more definitions and results are formalized, I expect similar developments across many fields of mathematics. In particular, open problems will be solved autonomously and viewed as “simple” in retrospect. Also, more significant conjectures will be resolved, though I refuse to hazard a guess regarding the timescale.
If you would like for your area of mathematics to see results from formalization, you can learn from the experience of the Erdős problems community. For example, if you have a nice conjecture you would like to see solved, you may submit it to the Formal Conjectures project and someone might try solving it (whether autonomously or the old-fashioned way). Beyond conjectures, Mathlib can always use contributions across all fields of mathematics. These definitions and theorems can then be used by both human and AI mathematicians. More broadly, organizing available results, open problems, and other data in curated databases (with some kind of forum!) has proven to be a very productive activity.
Finally, I did not want to go into too many of the details because it was a bit of a digression relative to the main discussion of AI, but in my opinion, misformalization is a big issue and was more frequent than I had expected. In particular, we need better tools to prevent and detect misformalization.
Acknowledgments
These exciting developments have been made possible by many people. Thank you to the lively community on erdosproblems.com, especially Thomas Bloom for creating and curating the site, and similarly for Lean and Mathlib. Thank you to Terence Tao, who has been supportive of many efforts involving AI, formalization, and increasing collaboration in mathematics. Thank you to OpenAI for access to ChatGPT Pro and Harmonic for access to Aristotle (which anyone can sign up for). Thank you to the Formal Conjectures authors. And thank you to Kevin Buzzard for suggesting a guest post on this wonderful blog!
 as I was now expected to call them, were a quotient group, and so by definition the elements were cosets. Turns out that 3 wasn’t an element of the integers mod 10 after all, turns out that the thing I was calling 3 was actually the infinite set
as I was now expected to call them, were a quotient group, and so by definition the elements were cosets. Turns out that 3 wasn’t an element of the integers mod 10 after all, turns out that the thing I was calling 3 was actually the infinite set  or
or  .
.
 and want to give a function
and want to give a function  from
from 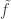 from
from  , and then just compose this with
, and then just compose this with 
 from the integers mod 10 to the set
from the integers mod 10 to the set 
![s([8])=\mathrm{Even}](https://s0.wp.com/latex.php?latex=s%28%5B8%5D%29%3D%5Cmathrm%7BEven%7D&bg=ffffff&fg=333333&s=0&c=20201002) .
. ![s([8])](https://s0.wp.com/latex.php?latex=s%28%5B8%5D%29&bg=ffffff&fg=333333&s=0&c=20201002) ; let’s now do the general case. Given
; let’s now do the general case. Given 
 from the integers to
from the integers to 
 :
:
 and
and  are congruent mod 10 then
are congruent mod 10 then  .
. and
and  are equal.
are equal. . Furthermore the Lean developers have designed things so that the proof that
. Furthermore the Lean developers have designed things so that the proof that  is just
is just 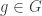 . But
. But 
 theorems we’ll need to push Wiles’ ideas over the line. The route we’ll be taking is not the original Wiles/Taylor-Wiles argument, but a more modern one due to Richard Taylor, who is collaborating with me on the mathematics of the project.
theorems we’ll need to push Wiles’ ideas over the line. The route we’ll be taking is not the original Wiles/Taylor-Wiles argument, but a more modern one due to Richard Taylor, who is collaborating with me on the mathematics of the project.
 and
and  ,
,  is the smallest number of people at a party you need, to find
is the smallest number of people at a party you need, to find  , (implying that the diagonal Ramsey number
, (implying that the diagonal Ramsey number  can be upper-bounded by
can be upper-bounded by  ). The research community attempted improvements to the problem of decreasing their upper bound, and in 1988 the first polynomial improvement was found by
). The research community attempted improvements to the problem of decreasing their upper bound, and in 1988 the first polynomial improvement was found by  . Conlon’s paper, giving the first super-polynomial improvement to the Erdős-Szekeres bound, was especially noteworthy and appeared in the Annals of Mathematics. But despite all of these successes, the question of decreasing the base of the exponent in the bound was still open. Is there a constant
. Conlon’s paper, giving the first super-polynomial improvement to the Erdős-Szekeres bound, was especially noteworthy and appeared in the Annals of Mathematics. But despite all of these successes, the question of decreasing the base of the exponent in the bound was still open. Is there a constant  for which
for which  ?
?  using a probabilistic argument which was itself groundbreaking, and gave rise to the field of probabilistic combinatorics. While a lower order improvement has been made to this, the base
using a probabilistic argument which was itself groundbreaking, and gave rise to the field of probabilistic combinatorics. While a lower order improvement has been made to this, the base 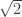 has not been improved, giving a wide gap between the lower and upper bounds of
has not been improved, giving a wide gap between the lower and upper bounds of 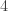 .
.  such that for all
such that for all  . This paper is in the publication process, and this is the result which I formalised.
. This paper is in the publication process, and this is the result which I formalised.  .
. and
and  , both of which are still unknown, and the main result of this post doesn’t get us any closer. Nonetheless, as part of this project, I formalised bounds on some of the known small values of Ramsey numbers, including
, both of which are still unknown, and the main result of this post doesn’t get us any closer. Nonetheless, as part of this project, I formalised bounds on some of the known small values of Ramsey numbers, including  .
. however, the proof can be recovered using that
however, the proof can be recovered using that 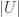 can be made large enough.
can be made large enough.  which I’d love to see formalised.
which I’d love to see formalised. 
{kind=link}
{kind=link}