15 October 2025 | Research
Rig3R: Learning 3D Perception for Autonomous Vehicles
Modern self-driving vehicles rely on multi-camera rigs to see the world, but transforming those streams into 3D understanding is an immense challenge. Rig3R is our latest advance in geometric foundation models, designed to power robust ego-motion and 3D structure estimation from embodied camera rigs.
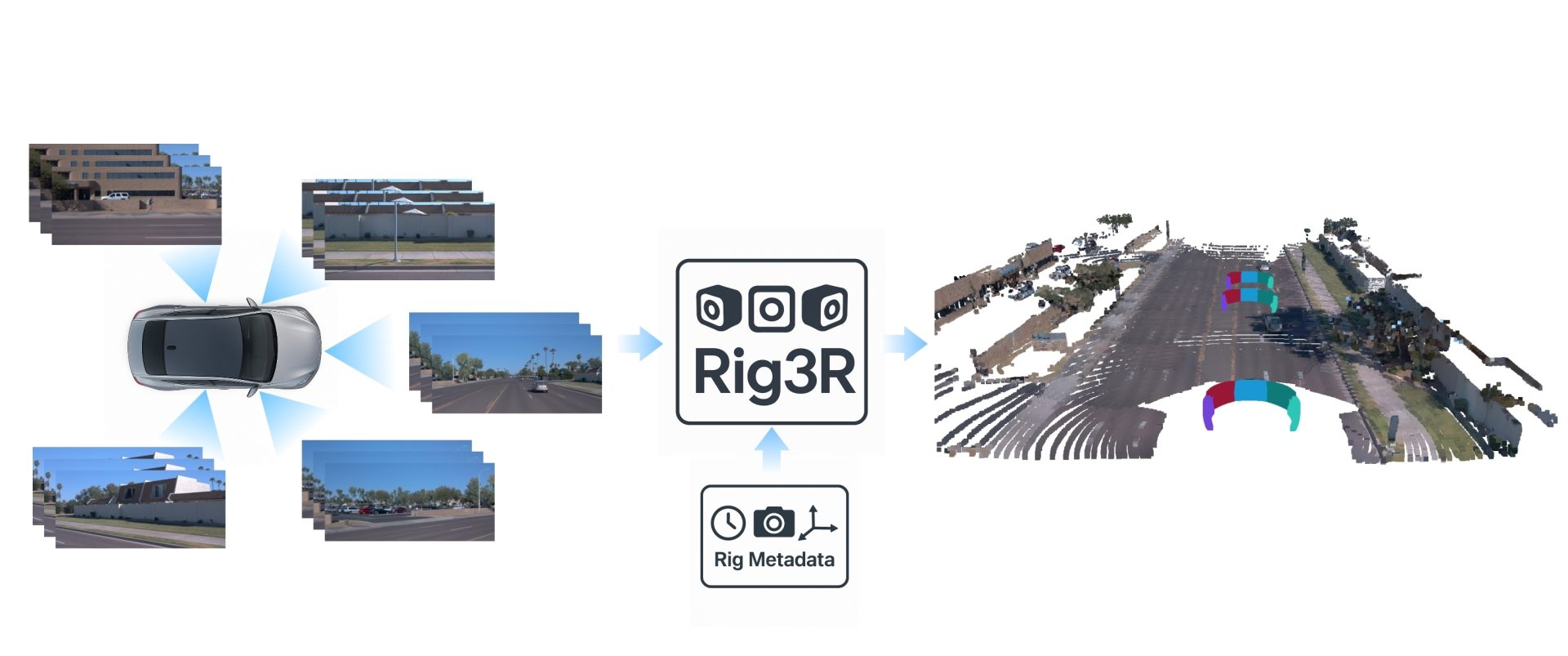
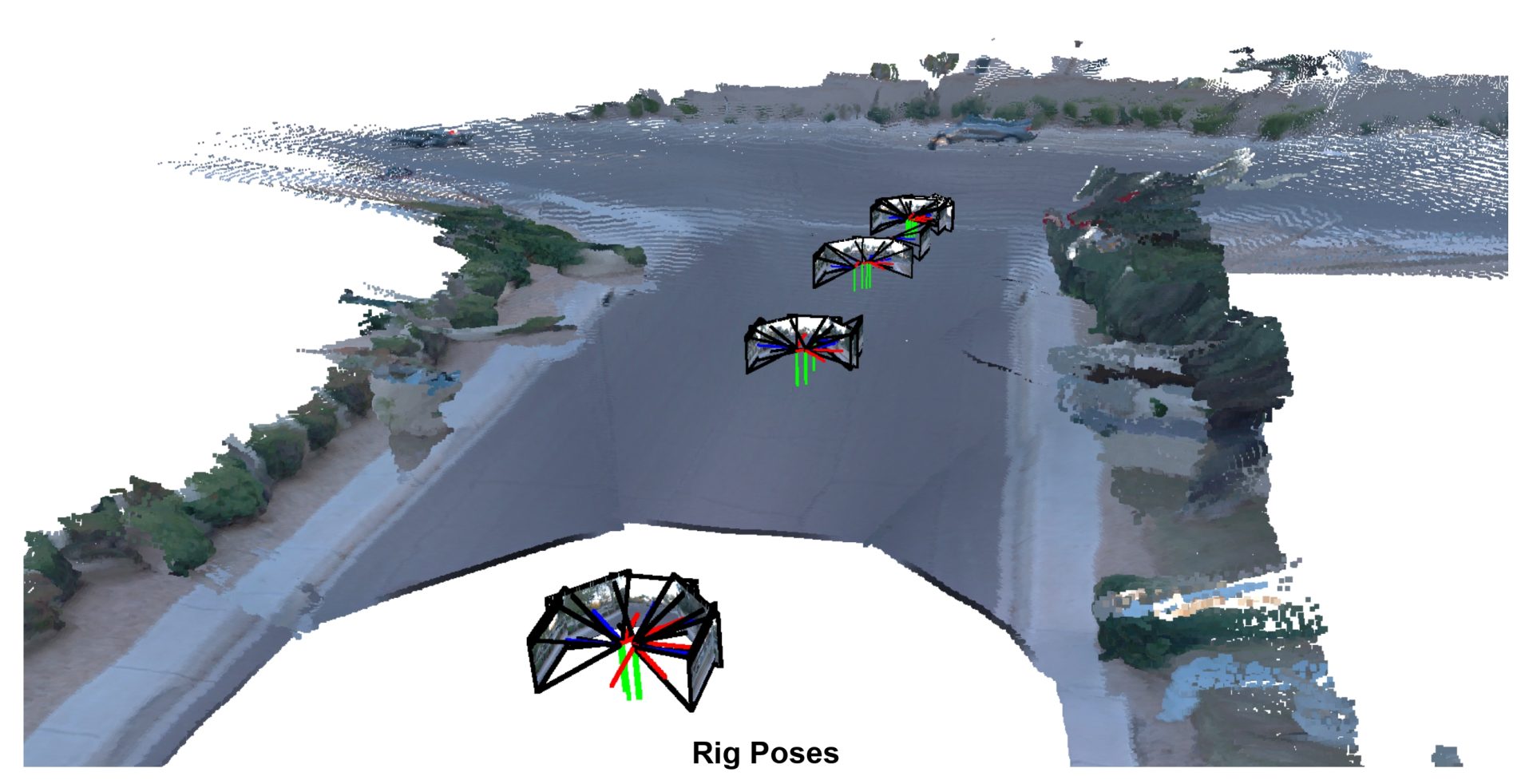
Visualization of Rig3R’s predicted poses and 3D pointmaps over a long run. The multi-cam input video streams are shown at the top, with the predicted future poses overlayed onto the road. The corresponding pointmap reconstruction is shown on the bottom. The full rig calibration is supplied as input.
Entering the Era of Geometric Foundation Models
At the heart of autonomous driving lies one enduring challenge: helping AI truly understand the world in 3D.
Robustly estimating the structure of the world and ego-motion of the vehicle has been a multi-decade pursuit in computer vision. Classical feature-based and photogrammetry methods have long defined the state of the art in multi-view geometry. However, recent advances have shown that large-scale, transformer-based learning can push this frontier even further. Still, these methods fall short in the autonomous vehicle setting, where multiple cameras continuously capture the world through synchronized, structured rigs.
To address this gap, we present Rig3R—a new model developed by Wayve that enables accurate and robust 3D reconstruction for multi-camera rigs. Rig3R is the first learned method to explicitly leverage rig constraints when available, achieving state-of-the-art 3D understanding in complex, real-world driving scenarios.
Why this Matters for Autonomous Vehicles
Rig3R extends geometric foundation models such as VGGT with the advantage of rig awareness, leveraging rig information when available, and inferring rig structure and calibration when it is not. This flexibility is essential for handling the diverse and evolving sensor setups found in embodied AI systems, delivering 3D understanding that is:
- Fast – Processing multiple frames and camera views in a single forward pass.
- Robust – Seamlessly handling everything from unstructured images to synchronized rigs of varying configurations, even with missing or incomplete calibration.
- Accurate – Outperforming traditional and learned methods by 17–45% on real-world driving benchmarks.
Together, these capabilities make Rig3R a foundation for reliable, geometry-aware perception in real driving conditions, a critical step toward safe, scalable autonomy.
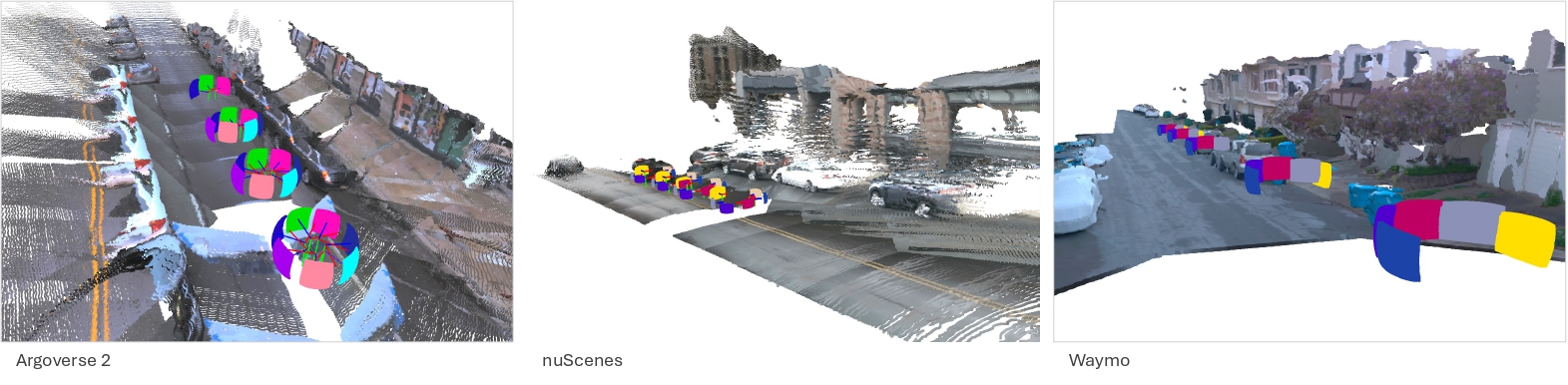
These are examples of rig scene reconstructions on the Argoverse, nuScenes and Waymo validation sets. The colored planes denote predicted raymaps, with their colors corresponding to camera ID from the predicted rig calibrations. The rig raymap outputs enable camera identification and calibration, and the rig metadata inputs enable enhanced 3D reconstruction and pose estimation.
How Rig3R Works
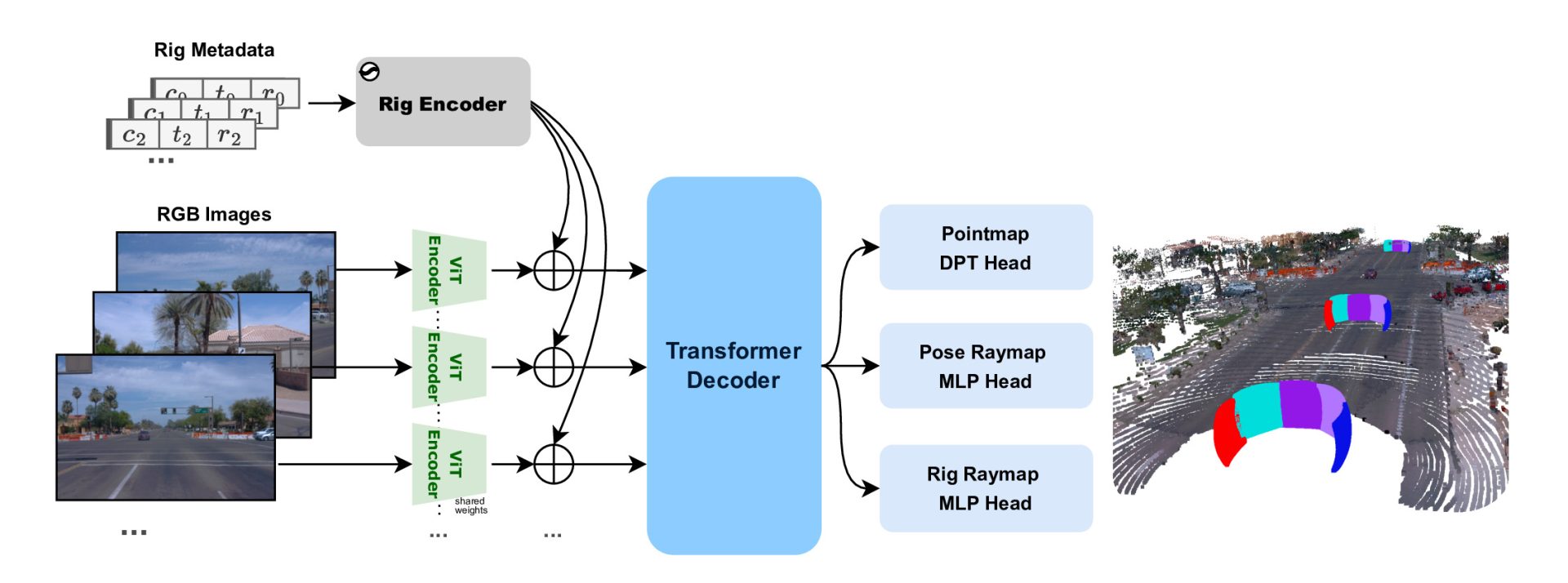
We describe our new method Rig3R in a conference paper to be presented as a Spotlight at NeurIPS 2025. Rig3R introduces a rig encoder to inject known rig constraints into the transformer’s decoder fusion stage, enabling geometry-aware multi-view reasoning.
Each input image can optionally carry a compact metadata tuple, consisting of a camera ID, timestamp, and rig calibration represented as a raymap (a per-pixel ray from the camera center that encodes its rig-relative pose). These fields provide geometric and temporal context that strongly guide multi-view alignment. Crucially, Rig3R is trained to leverage rig metadata when available and to remain robust when such information is missing.
Architecture at a Glance
Shared Image Encoder
A ViT-Large encoder transforms each input image into patch tokens with 2D sine-cosine positional embeddings.
Metadata Embedding
For each patch, Rig3R adds three types of metadata: camera ID, timestamp, and 6-D raymap patch. Discrete fields (camera ID and timestamp) are encoded using 1D sine–cosine embeddings, while the raymap is linearly projected and concatenated with the image tokens. During training, each metadata field is randomly dropped to encourage robustness. This teaches Rig3R to leverage metadata when available, and to infer missing context from image content and cross-view relationships when it is not. Each frame also includes a unique random ID to remain distinguishable under full-dropout.
Multiview Decoder
A second ViT-Large operates as a multiview fusion decoder, jointly attending across all images (views and timesteps). By conditioning on available metadata, it fuses spatial, temporal, and geometric cues within a shared latent space, forming the core of Rig3R’s multi-view 3D understanding.
Three Prediction Heads
Pointmap Head: A DPT-style head that predicts per-pixel 3D points along with a confidence map.
Pose Raymap Head: An MLP head that predicts per-pixel ray directions and a global camera center, enabling camera pose estimation.
Rig Raymap Head: An MLP head that predicts per-pixel ray directions and a rig-frame camera center, enabling rig calibration estimation.
Together, these three heads enable Rig3R to perform a wide range of downstream tasks, including dense 3D reconstruction, camera pose estimation, and rig calibration, all within a single forward pass.
Training Recipe
We train Rig3R with a multitask objective that jointly supervises:
- Confidence-weighted 3D pointmap prediction
- Global ray geometry prediction
- Rig-centric ray geometry prediction
The raymap losses combine errors from both ray directions and camera centers using a weighted sum. The total training loss is then computed as a weighted combination of these task objectives, encouraging Rig3R to learn a consistent, rig-aware 3D representation across views and frames:
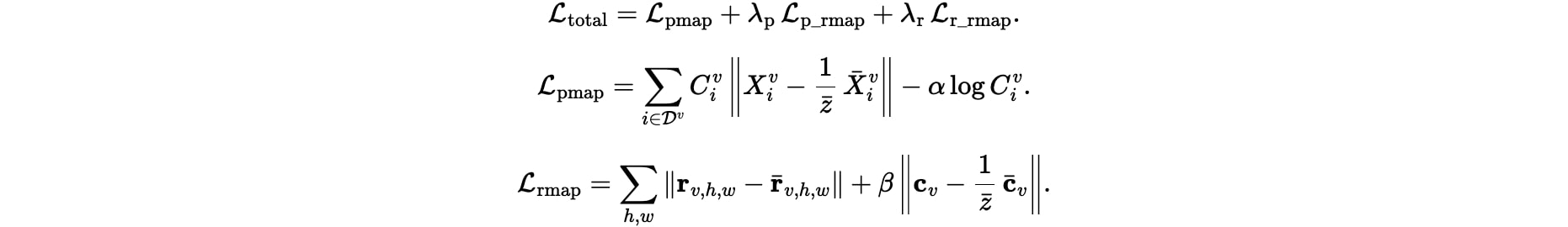
Rig3R is trained on a diverse corpus spanning indoor, driving, synthetic, and object-centric datasets, with a deliberate emphasis on multi-camera rigs. This design exposes the model to a wide range of rig configurations and enables it to effectively leverage rig embeddings. The training corpus includes both external datasets and internal Wayve driving data.
The data sampling strategy is tailored to each dataset type:
- For COLMAP reconstruction datasets, images are sampled by covisibility to ensure visual overlap.
- For image datasets, frames are drawn with a random temporal stride to vary motion magnitude.
- For rig-based sequences, cameras are subsampled to increase the diversity of rig geometries, typically retaining at least one forward-facing camera to preserve inter-frame overlap and mirror common monocular setups.
This combination of heterogeneous datasets and targeted sampling strategies greatly broadens Rig3R’s training distribution, encouraging strong generalization across scene types, rig configurations, and time scales.
Experiments
Benchmarks & Setup
We evaluate Rig3R on two multi-camera driving benchmarks: the Waymo Open validation set and WayveScenes101. Waymo Open provides LiDAR-based ground-truth poses and points, and WayveScenes101 uses COLMAP reconstruction as ground-truth. For the version of Rig3R presented in our paper, the model is trained on the Waymo train split, meaning the Waymo rig is seen during training. In contrast, WayveScenes101’s rig is never observed, serving as an out-of-distribution (OOD) test for generalization.
Both benchmarks employ five-camera rigs capturing approximately 200 frames per scene, sampled at 10 FPS. For each scene, we extract two 24-frame clips (full 5-camera rigs), spaced roughly two seconds apart. We benchmark multiple configurations of Rig3R against several feed-forward baselines, as well as classical structure-from-motion (SfM) and rig-aware methods.
Our evaluation tasks focus on two objectives:
- Pose Estimation, reported using Relative Rotation Accuracy (RRA) and Relative Translation Accuracy (RTA) at 5° and 15° thresholds, and mean Average Accuracy (mAA) up to 30°.
- 3D Pointmap Reconstruction, evaluated using Accuracy, Completeness, and Chamfer Distance.
Results: Pose Estimation & Pointmap Reconstruction
The figure below compares pose estimation and pointmap reconstruction across four methods—Fast3R, DUSt3R-GA, Rig3R (unstructured), and Rig3R (with rig constraints) — on the same driving scene. The progression clearly shows how Rig3R’s rig awareness improves both geometric coherence and reconstruction quality: while baseline methods often produce noisy or spatially inconsistent pointmaps and poses, Rig3R yields sharper, more consistent structures with rig poses that align sensibly across all views.
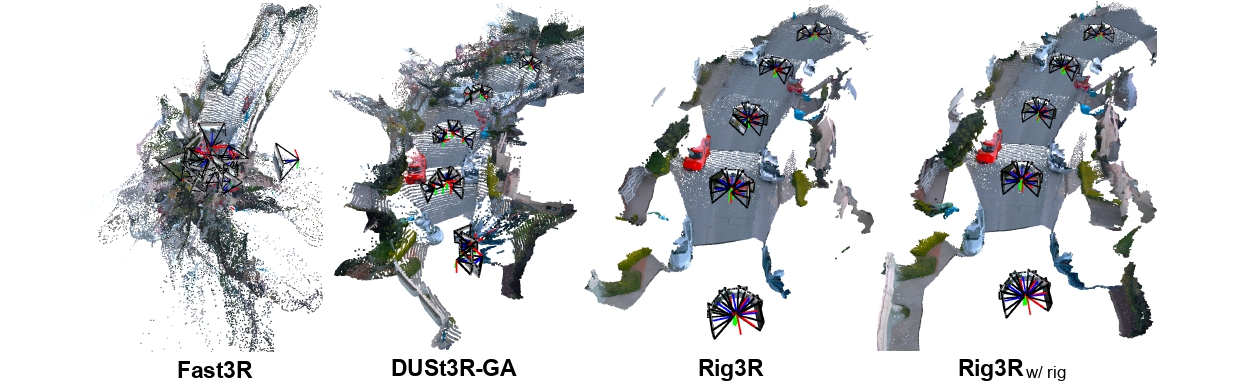
Qualitative comparison across methods. Baseline models produce blurrier and less consistent reconstructions, with unstable structure, poses, and rig geometry. Rig3R produces coherent trajectories and spatially consistent 3D reconstructions, while incorporating rig constraints further refines the recovered rig geometry with improved to visual appearance.
The bar plots below summarize pose estimation performance across Waymo Open and WayveScenes101. The lighter shaded bars (for Rig3R and COLMAP) indicate the performance gain from leveraging rig metadata. On Waymo, where the rig configuration was seen during training, Rig3R (unstructured) already outperforms all baselines, and incorporating rig calibration provides a modest yet consistent boost in rotation and translation accuracy. On WayveScenes101, where the rig is unseen, the effect of rig metadata is far more pronounced. Rig3R with rig constraints achieves the highest overall accuracy, substantially improving mAA and reducing geometric error. Among all baselines, only COLMAP can leverage rig constraints, but Rig3R is the first learned model to do so effectively, showing that incorporating rig priors enables strong zero-shot generalization to novel multi-camera setups. These trends hold consistently across both pose estimation and pointmap reconstruction metrics. For detailed quantitative results and extended discussion, please refer to our paper.
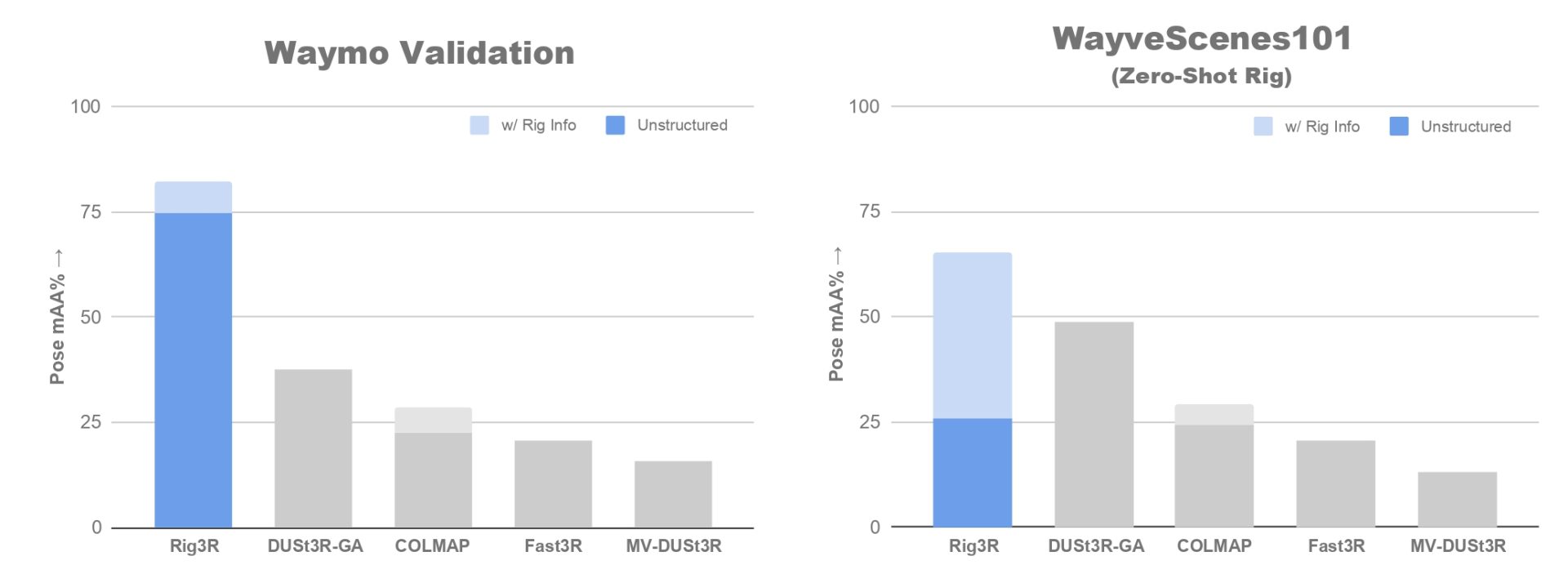
Quantitative results on pose estimation across the Waymo Open and WayveScenes101 benchmarks. Rig3R outperforms all feed-forward baselines in both settings, with the inclusion of rig constraints providing the largest gains on the unseen WayveScenes101 rig. Only COLMAP can otherwise exploit rig metadata, but Rig3R is the first learned model to do so effectively, demonstrating strong zero-shot generalization to novel multi-camera setups.

Quantitative results on pointmap reconstruction. Trends mirror those observed in pose estimation, with Rig3R achieving the best overall performance and the largest gains on the unseen WayveScenes101 rig when rig constraints are applied.
Why Metadata Matters
In the example below, we break down how different forms of metadata, from camera IDs and timestamps, to rig pose, and finally the full set, contribute to Rig3R’s performance. As more metadata is introduced, both pose estimation and pointmap reconstruction improve: predicted camera trajectories progressively align with the physical rig, and reconstructed pointmaps become sharper and more consistent. This analysis illustrates how such structured priors, often readily available in embodied and robotic systems, can be effectively integrated into a learned geometric model to enhance both accuracy and generalization.

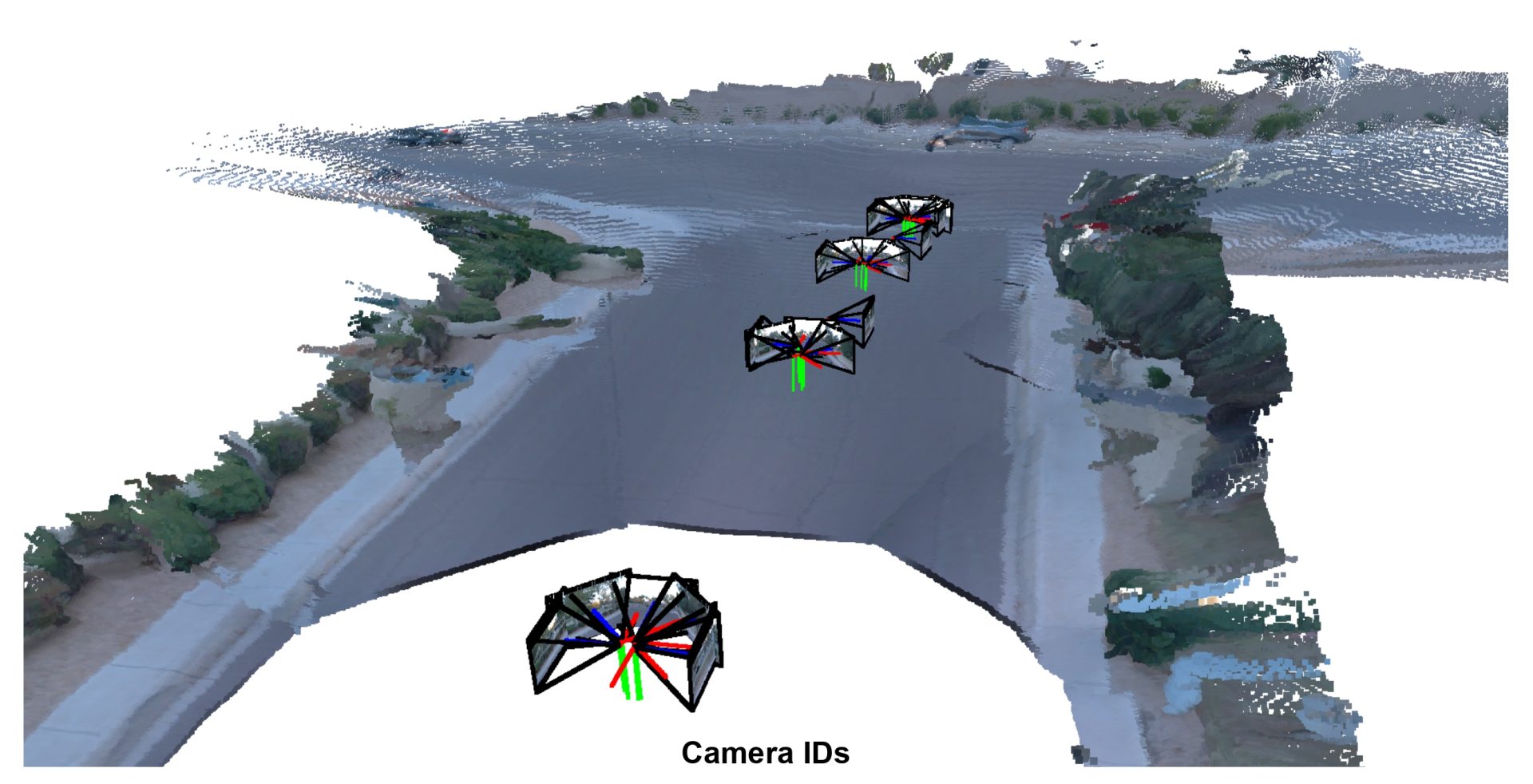
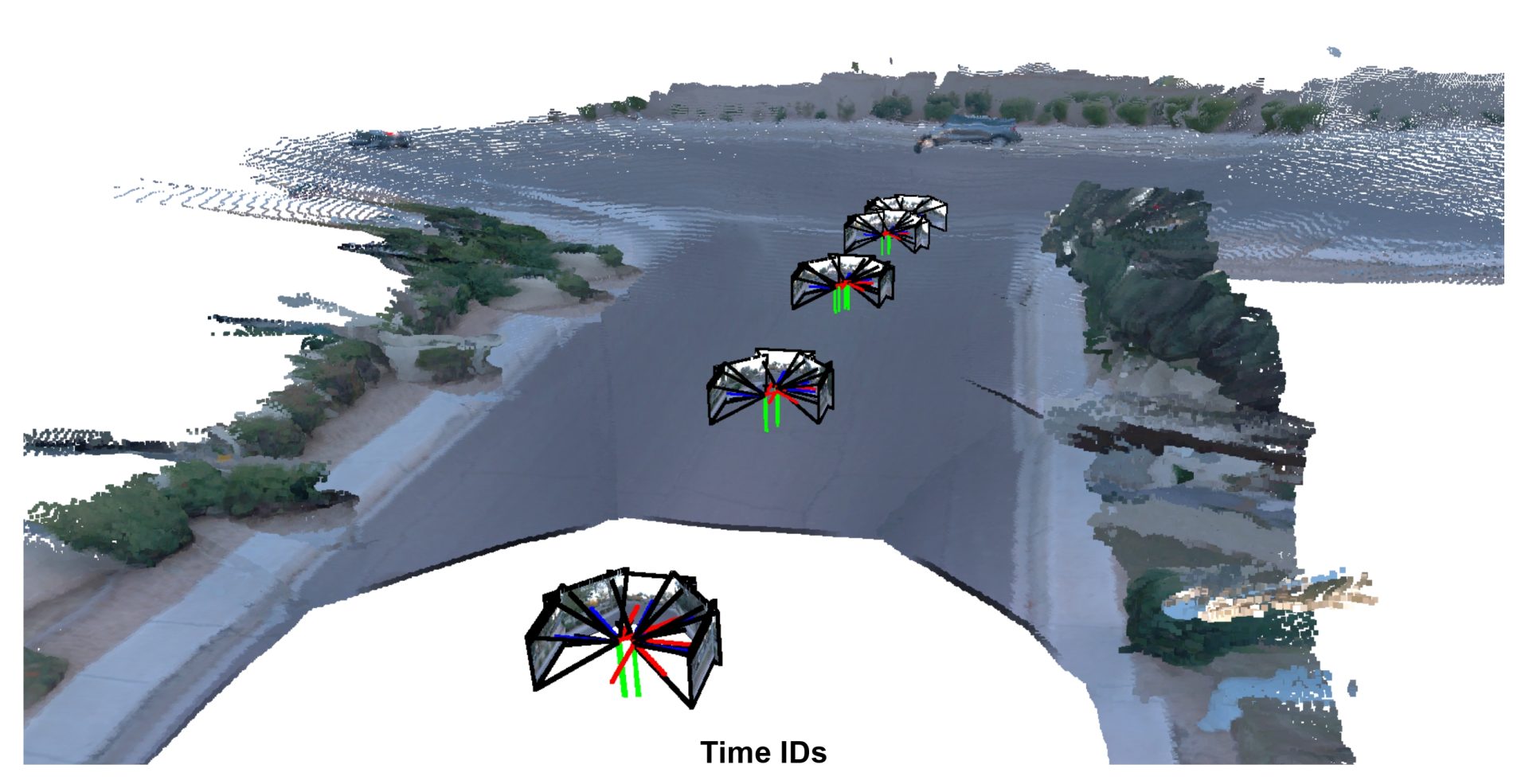

Rig3R performance improves steadily as more metadata is provided, from no metadata to the full set (camera ID, timestamps, and rig poses). The model achieves its best 3D reconstruction and pose estimation accuracy when all metadata fields are available.
Scalability and Generalization
Rig3R delivers strong pose estimation and dense 3D reconstruction across a wide range of rig configurations and environments. It performs robustly under short and long baselines, varied fields of view and resolutions, and diverse frame rates. Rig3R remains reliable even under challenging conditions such as day–night illumination changes, motion blur from high speeds, rain, snow, glare, and low-texture scenes. The videos below showcase Rig3R’s performance across these diverse settings.
Even at scale, Rig3R produces consistent and stable trajectories across diverse driving sequences, maintaining accuracy through sharp turns, stops, and occlusions. It demonstrates strong cross-dataset generalization: without any per-scene tuning, Rig3R transfers seamlessly from calibrated multi-camera rigs to mixed or uncalibrated setups, and even to monocular-only inputs, while preserving reliable poses and high-fidelity reconstructions. These capabilities extend to in-the-wild driving videos, where Rig3R continues to recover ego-motion and dense 3D structure despite significant variation, sensor noise, and incomplete metadata—making its outputs immediately usable for downstream tasks such as mapping, relocalization, and embodied AI training.
Even in single-camera vicinities, Rig3R displays strong performance. The video above displays Rig3R ‘s robust outputs over diverse, in-the-wild driving data, using only the RGB inputs and timestamps.
Future Work and Conclusion
Many open problems remain in the quest to build a spatially intelligent foundation model. In addition to scaling up training, future improvements to Rig3R could include streaming representations, handling scene motion, multimodal inputs, multiple embodiments and multi-task outputs.
At Wayve, we are using Rig3R to improve our 3D world understanding, synthesis, and foundation modelling capabilities. It’s a step on the road toward scalable autonomy, allowing us to adapt across multiple hardware configurations without bespoke calibration or brittle geometry pipelines. Ultimately, future versions of Rig3R will move us closer to embodied AI that truly understands the physical world, recovering 3D geometry and motion from any video to turn pixels into actionable spatial context.
Interested in joining us on this journey? Come chat with us at NeurIPS or explore our open roles.

17 December 2025 | Engineering
The AI-500 Roadshow: 500 Cities and What We Learned
Wayve’s AI-500 Roadshow tested a single global AI driving model in 500 cities, showcasing impressive zero-shot generalization.
Read more
2 December 2025 | Research
GAIA-3: Scaling World Models to Power Safety and Evaluation
Transforming world modeling from a tool for visual synthesis into a foundation for autonomy evaluation. ...
Read more
22 October 2025 | Engineering
Global Learning, Local Driving: Lessons From Japan
Our expansion to Japan put the Wayve AI Driver to the test in one of the world’s most complex driving environments. Within months, our AI adapted to Tokyo’s roads, improved global performance, and powered Nissan’s next-generation ProPILOT prototype—showcasing the scalability of AV2.0.
Read more