I’ve recently been pondering this picture

(Yes, I used comic sans. For a reason.)
| CARVIEW |
I’ve recently been pondering this picture
(Yes, I used comic sans. For a reason.)
 3 Comments |
3 Comments |  soft post | Tagged: advice, ideas |
soft post | Tagged: advice, ideas |  Permalink
Permalink
 Posted by tobiasosborne
Posted by tobiasosborne
“It’s better to pursue one bad idea to its logical conclusion than it is to start and not finish ten good ones,” Michael said.
I was sitting in Michael Nielsen’s office at The University of Queensland: it was early 2002 — a steamy Brisbane summer afternoon — and the air conditioner struggled to cool the room. I had just finished with a long despairing complaint about the disappointing lack of progress I’d been making on my PhD when he issued me with his advice. (I was beginning the third and final year of my PhD.)
I’d had an interesting ride so far: I began my PhD in the year 2000 in applied mathematics studying free-surface problems in fluid mechanics. Fluid dynamics is a challenging and mature research area and requires a lot of effort to get up to speed. Unfortunately, I am very lazy and it had taken me a very long time. Also, I quickly found out that I just wasn’t that interested in the motion of fluids (although, one of the papers I’m proudest of emerged from this period). I quickly became unmotivated and I had begun to distract myself by reading quantum field theory textbooks to procrastinate instead of finding that sneaky bug in my code…
Then everything changed. I think it was in late 2001 when Michael arrived at UQ and gave a series of talks on quantum computers. I was hooked and I immediately dropped everything and started working with Michael “in my free time” on quantum entanglement and condensed matter systems.
I once heard a definition of a golden age in science as a period when mediocre scientists could make great contributions. (I forget when and where I heard this and a cursory google search didn’t turn up anything.) The early 2000s were definitely a golden age for quantum information theory and I had the greatest luck to work with one of its architects. In practically no time whatsoever (in comparison with applied mathematics) we’d written a couple of papers on entanglement in quantum phase transitions.
It had been just so effortless. Now I’d finally found a research field that appealed to me: with an absolute minimum of effort one could write a paper that’d be read by more than two people. Wow! (Alas, this is no longer true…)
All this went to my head. I figured that if one could just stick two buzzwords together (entanglement and quantum phase transitions) and get a paper then why not do it again? I was skimming through texts on partial differential equations, algebraic topology, and stochastic calculus and seeing connections EVERYWHERE! I was discovering “deep” connections between entanglement and homotopy theory before breathlessly diving into an idea for a quantum algorithm to solve PDEs. I would spiral into hypnotic trances, staring distractedly into space while one amazing idea after the other flowed through mind. (This is the closest I ever got to the flow state so beloved of hackers.)
But at the same time frustration, edged with desperation, was growing. I was having all these amazing ideas but, somehow, when I started writing one of them down it started to seem just sooooo boring and I promptly had a better one. My hard drive filled with unfinished papers. I had less than a year until my money was gone and no new papers!
I was lost in the dark playground:

I then went to Michael and told him of my frustration. And it was this complaint that had prompted him to give me his advice. All at once, it was clear to me what I’d been doing wrong. So I threw my energies into a problem Micheal suggested might be interesting: proving the general Coffman-Kundu-Wootters inequality. This was a hugely satisfying time; although I didn’t end up proving the inequality during my PhD I managed to, mostly by myself, work out a generalisation of a formula for a mixed-state entanglement measure that I was convinced would be essential for a proof (this sort of thing was a big deal in those days, I guess not anymore). Every day I was tempted by new and more interesting ideas, but I now knew them for the temptation of procrastination that they were.
Michael’s advice has stuck with me ever since and has become one of my most cherished principles. These days I’m often heard giving the same advice to people suffering from the same temptation of the “better idea”.
Now “focus on one idea” is all very well, but which idea should you focus on? (You will have no doubt noticed that I was rather lucky Michael had the perspective to suggest what was actually a rather good one.) What do we do if we have lots and lots of good ideas, each one of them clamoring for attention? How do we break the symmetry? How can we best choose just one or two ideas to focus on? How should you split your most precious resource, your time, while balancing the riskiness of an idea against its potential return?
Ultimately I do not have an answer, but I do have a decision tool that can help you to make your mind up. The idea is to regard research ideas as investments, i.e. assets, and to evaluate their potential return and their risk. In this language we have reduced the problem to that of investing some capital, your time, amongst several assets. This is an old problem in portfolio management and there is a very nice tool to help you work out the best strategy: the risk-return plane. The idea is pretty simple. In the case of portfolio management you have some capital you want to split amongst a portfolio of assets which are characterised by two numbers, their average return and their risk, i.e., the standard deviation of their return. Take a two-dimensional plane and label the x-axis with the word “risk” and the y-axis with the word “return”. Each asset is plotted as a point on the risk-return plane:

Now something should be obvious: you should never invest in an asset with the same return but higher risk, nor should you ever invest in an asset with the same risk but lower return. This picks out a thin set of assets living on the “boundary” of (basically the convex hull of) all the assets, called the efficient frontier. You should only ever invest in assets on the efficient frontier.
For a joke I once suggested using the risk-return plane to work out what research idea you should work on. However, it quickly became apparent that some people found it a useful tool. Here’s one way to do things: first write down all your research ideas. Then, after some honest reflection on what you think the most likely outcome of a successful result from the project would be, associate a “return” to each idea. (Just ask yourself: if everything worked out how happy would you be? How much would the completed idea contribute to science? Insert your own metric here.) The way I did this was, somewhat flippantly, to label each idea with a journal that I thought would accept the idea. Thus I created a list:
It is totally silly but it has just sort of stuck since then. Next, you have to assess the risk of each project. I think a reasonable way to do this is to quantify each research idea according to what you think is required to solve it, e.g., according to
For an example let’s just take a look at my top twelve research ideas for the last year:
Here’s my risk-return plane:

Looking at the results it quickly became apparent that I shouldn’t really invest my energy in a formula for the 2-qubit distillable entanglement (shame! I would be interested in solving that one, but I just can’t see how it would be useful to anyone, including to myself!!!) Also, I should steer clear of the quantum KKL inequality, the quantum PCP conjecture, and K-theory for MREGS.
Note that all of this is completely and utterly subjective! You might well argue that a proof of the quantum PCP conjecture would be a tremendously impactful result on par with the quantisation of quantum gravity. But my purely subjective assessment at the time was that it would not be of the same level of impact (for me) as, say, classifying topological order in all dimensions.
Thus, out of the top 12 ideas floating around my head only 5 remained. This is still way too many! To winnow down the list it is helpful to use an investment strategy employed in portfolio management which is, roughly speaking, to invest a more of your capital in less risky assets than riskier assets (i.e., don’t put all your eggs in one risky basket!!!!) Thus I dropped the riskiest idea and I also dropped the most trivial one as not really giving much personal reward. I was left with three ideas. This was just about enough for me, and I spent most of my available energies on those.
I find it helpful to keep this risk return plane around and to periodically update it as I get more information, or when I get new ideas. Looking at it today I figure I’ll move the adiabatic gap, Chern-Weil theory, and the scattering problem ideas up a bit. Maybe I’ll work on them soon…
6 Comments | soft post | Tagged: portfolio management, research ideas, risk-return plane | Permalink
Posted by tobiasosborne
There are several stories of great discoveries been made in dreams (see this wonderful wikipedia list for some famous ones).
Unfortunately I have never had the good luck to have a dream which gave me a creative insight to solve a problem. That isn’t to say that I don’t dream about my research. Last night, for instance, I dreamt of classifying two-dimensional quantum phases using a quantum generalisation of the j-invariant and some other invariant which I, in my dream, for some reason wrote as 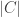
I’ve also been rather envious of those who seem to be able to exploit unconscious cognition. When I was doing my PhD, I was mightily impressed by Michael Nielsen who would sometimes pause in the middle of a conversation and exclaim “I now know how to solve problem x!”. I mean, how cool is that!? Alas, it never worked for me. Oh, I do get “aha” moments rather often, but the result is usually complete junk…
I only get results after hard slog. I have to make lots and lots and lots of mistakes and only then, slowly and gradually, the result emerges, reluctantly and complaining all the while, in its final form.
I can’t remember ever really experiencing a dream or an “aha” moment that turned out to be really correct.
Leave a Comment » | soft post | Tagged: dreams | Permalink
Posted by tobiasosborne
Waterloo, Canada. It was early 2004. It was cold.
I was cocky and full of the naive self-satisfied arrogance of a young physicist convinced of his powers. Filled with dreams of glory I made my way onto the airport shuttle to return home to Bristol. I was returning from QIP 2004.
It had been an exciting week.
I had just enjoyed a string of inspiring talks on a variety of fascinating topics across the full spectrum of quantum information theory. There was a palpable buzz in the air: quantum computers were coming! We were all positioning ourselves for the game of the millennium. As far as I was concerned, the only game in town was quantum algorithms, and fame and fortune would be awarded to those lucky few who could find a quantum algorithm yielding the holy grail of the exponential speedup.
My mind was a ferment of ideas; I’d just seen a fabulous talk by Oded Regev on quantum complexity, cryptography, and lattice point problems. I was convinced this was where quantum computers would exhibit a speedup. Oded had presented a truly lovely result showing that if you could prepare a very special kind of quantum state, a superposition of gaussians centred on the points of an (unknown) lattice in 
Thus began the worst year of my life.
The year 2003 had already been very difficult for me for a variety of reasons. I’d started my first two-year postdoc in 2003 and it had taken me a long long time to settle down. I had found moving countries to be so much more difficult than I imagined. This meant that my productivity had basically fallen to zero for a year (everything you see from me on the arXiv during this period, with one exception, are papers that had been developed during my PhD.) So there I was, at the beginning of 2004, resolved to write the big one: a paper that would one day become as famous as Shor’s algorithm. I figured they’d call it Osborne’s lattice algorithm. Of course, when giving a talk, I already knew I’d always modestly refer to it as “the quantum lattice point algorithm”. Awesome.
I worked tirelessly. I spent hours and hours in a row, day after day, completely focussed on this one problem. I dreamt about it.
To solve it, I deployed the full arsenal of my quantum optical tricks to annihilate this problem. And at the beginning it looked really promising. I had the basic idea clear (use a phase kickback trick and continuous-variable teleportation to create the superposition, then correct the phases afterward).
Slowly, but surely, a disturbing pattern emerged. I’d begin really inspired, convinced that I was finally on the right track. Then I’d carefully write up my latest version of the algorithm. Then I’d find the mistake, which always turned out to be that I’d simply misunderstood some aspect of the problem. Then I was right back at square one. There was simply nothing to be recovered because every damn time the mistake was that I’d misunderstood the problem and tried to solve the wrong thing. This ecstasy/agony cycle took, variously, one week to one month each time.
This lasted over 6 months. I was becoming exhausted. I didn’t work on anything else. My personal life was in a shambles.

But I persisted. Surely this time I would do it. Giving up was for losers.
Instead of giving up I doubled down and enlisted the help of Nick Jones, a PhD student at Bristol at the time. I am filled with admiration for Nick who, with limitless patience, worked with me at the board hour after hour on this wretched problem. But it was, alas, to no avail.
Finally, humiliated and defeated, I gave up. I think it was October 2004.
This was the worst feeling: nearly a whole year gone with absolutely nothing to show for it. Worse, I was wracked with guilt, feeling I’d totally wasted Nick’s time.
…
Things soon got better. By a miracle my postdoc had been extended for a while, so at least I wasn’t on the job market straight away. Secondly, at the end of 2004 I went to a truly inspiring conference at the Isaac Newton institute where I met up with Guifre Vidal who showed me something amazing: the Multiscale Entanglement Renormalisation Ansatz, and I realised that what I should do is focus on more my core skill set (quantum entanglement and many body quantum spin systems). I began working on tensor networks, read a fantastic paper of Hastings, and got into the Lieb-Robinson game.
If I had my time again what would I do differently? I don’t regret working on this problem. It was worth a try. My mistake was to keep working on it, to the exclusion of everything else, for too long. These days I am mindful of the advice of Wheeler: you should never do a calculation until you already know the answer. I also try to keep a portfolio of problems on the go, some risky ones, and some safe ones. (More on that in a future post.) Finally, upon reflection, I think my motivation for working on this problem was totally wrong. I was primarily interested in solving a famous problem and becoming famous rather than the problem itself. In the past decade I’ve learnt to be very critical of this kind of motivation, as I’ve seldom found it successful.
PS. I find the QIP 2004 conference photo rather striking: so many of the attendees have moved on to great success in quantum information theory and have now become household names. It was still a year before Scott Aaronson would start his famous blog. I never would have guessed at the time.
2 Comments | soft post | Tagged: mistakes | Permalink
Posted by tobiasosborne
A common complaint I’ve heard from my colleagues is that their favourite and best work is their least appreciated and least cited work. (I certainly feel this way.) It is not hard to imagine why this is: probably their best work is the one that contains the most unfamiliar and original ideas, the most difficult calculations, and is probably the least clear to anyone except the author because it is very difficult to explain something truly new.
(This all rather puts me in mind of the quote:
Don’t worry about people stealing an idea. If it’s original, you will have to ram it down their throats.
Howard H. Aiken, as quoted in Portraits in Silicon (1987) by Robert Slater
)
So, if you are looking for something truly interesting to work on why not pick an author you respect and find their oldest least cited paper. (I.e., don’t choose a new one that simply hasn’t been read yet.) Read it forwards and backwards until you completely understand it.
There will surely be some treasure buried in there.
And hey, you can be pretty sure that absolutely noone else will be working on the same thing.
(My personal pick is the intriguing paper of Bill Wootters on entanglement and parallel transport.)
Leave a Comment » | soft post | Tagged: ideas, science | Permalink
Posted by tobiasosborne
This blog and my twitter account have been very quiet for the past year. This time it wasn’t entirely due to laziness or a lack of motivation. Instead, as an experiment, I gave up all forms of social networking and online news: I stopped reading all blogs, I uninstalled the twitter and facebook apps, I deleted all bookmarks to anything resembling an online news service, and I removed all chat programs. Apart from one or two minor lapses, in order to obtain some contact details, the closest I was to anything resembling a social network is arxiv.org and the closest news source has been (occasionally) the radio. (Not internet radio though.) I did, however, read email (alas, this seems to be necessary for daily functioning in a large institution in the modern world…)
Why did I do this? I think it is an understatement to say that the internet is distracting and I increasingly had the suspicion that news and social networks did not make me happier. I also suspected that the internet was a serious drain on productivity. So, what is the result? Disappointingly, my productivity didn’t soar. It turns out that you can be distracted by things that aren’t the internet, e.g., unfortunately, books. This problem must be solved by some other productivity measure (however, visiting a lifehacker site is still strictly forbidden!).
What about happiness? This is more interesting: I think I am, in general, actually a teensy weensy bit happier. It is abundantly clear that “giving up the internet” is not a miracle cure for the malaise of modern life. But one does feel noticeably calmer on a day to day basis when not exposed to people being wrong on the Internet.
But didn’t I miss out on loads of important things? Well, it seems not. It gives you a sense of perspective to stop living in the sometimes hollow echo chamber that is the blogo-twitter-gplus-facebook-sphere. I’m sure I missed out on loads of really important scandals and outrages. I do know that I missed out on a couple of really very good blog articles: but the nice thing is that the good ones I did miss got recommended to me by word of mouth.
I am now returning to a more active internet presence: I strongly believe in open access science, and open science in general. I also believe that social networks are a fantastic medium with which to interact with others in science. I just wish there was a really simple way to filter out all the negative stuff.
To kick things back off on this blog I will be right back with a guest post 😉
5 Comments | soft post, weblog administration | Tagged: social media | Permalink
Posted by tobiasosborne
Quantum information theory has evolved in fascinating ways over the past two decades or so and I’ve been privileged to directly witness its development for ten of these years. In this post, I thought I’d have a go at predicting where it will go, and what the “next big thing” for quantum information theory will be.
Around the year 2000 quantum information theory seemed to be primarily focussed on two broad themes: building a quantum computer and developing quantum algorithms for it, and building a resource theory for quantum information via, e.g., quantum entanglement theory and quantum Shannon theory. To a large extent both of these themes continue strongly today. Although, I’d suggest that quantum Shannon theory has fared much better than the theory of quantum entanglement, in particular, that of entanglement measures, which seemed really important a decade ago but not so much now.
One thing that would have been harder to predict was the influence of quantum information theory on other areas of physics. For example, QI has now had some considerable impact in condensed matter physics, particularly with regard to the development of new classical simulation algorithms for complex quantum systems. From my considerably biased perspective I think that this second-order effect has been rather important. Also, there has been excitement about the role and influence of QI on biological physics.
So now to the question: what next for quantum information? I based the following list on topics that I personally find very interesting, and also on observations I’ve made about external pressures coming from funding agencies and from the job market.
1. Quantum computers
I firmly believe a quantum computer will be built, although I refuse to say how long this will take. One thing that I think may happen is the emphasis on fault tolerance thresholds in choosing a quantum computer architecture will diminish slightly as experimentalists engineer systems capable of supporting quantum coherence on longer timescales. I’m sure that cluster states will be exploited in some way in the successful quantum computer architectures. I also feel sure that as we get access to such systems this will spark our creativity in designing nontrivial things to do, i.e., in developing quantum algorithms using dissipative quantum processes.
2. Quantum algorithms
Thus I feel convinced that quantum algorithms development will continue, albeit slowly. One area which hasn’t received much attention — probably because it isn’t as glamourous as an exponential speedup — but which really should, is the development of quantum algorithms which give polynomial speedups for problems in P. These kind of speedups could turn out to be extremely important: if the best classical algorithm for a problem of major practical importance uses, say, 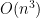

As mentioned above, another class of quantum algorithms which has been so far relatively unexplored, is that of dissipative quantum algorithms. (There are some exceptions here, see, e.g., and this, this, and, somewhat immodestly, this.) Such algorithms are extremely important because they give intermediate experimental implementations something to run!
3. Complex quantum systems
Quantum information will continue to play a role in the study of complex quantum systems. This is an easy prediction: QI trained people are generally quite good at thinking about quantum coherence, which plays a major role in the physics of strongly interacting quantum systems. I feel relatively confident in predicting that the physics of 2D and, to some extent, 3D lattice systems, will see major QI-inspired developments.
Another area which I am very enthusiastic about is that of quantum systems with continuous degrees of freedom, particularly, quantum fields. Lattice systems are, after all, an approximation to these systems, and it is clear that existing QI-inspired techniques will have some influence here (indeed, this is just beginning with the extension of MPS and MERA to the continuous setting). Additionally, if a good enough interplay can be developed then this would allow quantum field theorists to be able contribute to quantum information-type problems. Also, holographic correspondences such as the AdS/CFT correspondence have QI aspects, so we might see QI theorists and string theorists working together more strongly here.
4. Classical physics
My final prediction concerns the influence of QI on classical physics. The thing is, QI trained people are not only good at thinking about quantum coherence, but also about correlations in general (see, e.g., the continuing developments in the study of Bell’s inequalities, cryptography based on no-signalling, etc.). Correlations are always hard to think about, but the thing we’ve learnt in studying QI in the context of condensed matter is that if you have a way to think about correlations in a better way then this can lead to new simulation algorithms. Here I have in mind, for example, the study of fluid dynamics, as applied to the climate (see this for a longer discussion), and other problems of classical many body physics such as traffic flow via this, community detection, and image recognition. The nice thing about these areas is that they are much more directly connected with our everyday life. Any contribution here would have a much more direct impact on important problems facing humanity.
What do you think?
5 Comments | soft post, speculative ideas | Tagged: classical physics, complex quantum systems, predictions, quantum information theory | Permalink
Posted by tobiasosborne
Or, in defence of the 4 page paper.
As anyone who knows me can probably attest, I can sometimes passionately defend one position and then change my mind completely and hold the opposite position just as fervently. This post is an example of one of these changes of mind…
Today I want to talk about the four-page paper.
The four-page (plus/minus epsilon) paper is almost a cliche in physics on par with that of the three-part novel of the 19th century: when it’s four pages long you can submit it to PRL, or, maybe with some extra work, Nature or Science. And these are gold-class journals: if you get enough PRLs then this is likely to gain the respect of you colleagues and, more importantly, impress hiring/tenure/promotion committees. So it’s not hard to see why the four-page paper is an attractive format to aim for. I don’t want to dwell on the rightness or wrongness of the academic system here. Like it or not this is the way things currently are, and I’m not going to try and change it right now. (That’s a long post for another year.) I just want to focus on what four-page papers are doing to scientific scholarship.
Much has been said about how the dominance of the four-page paper is a “bad thing” for scientific scholarship. Well, actually, at least, I’ve heard lots of people complaining about it (including myself). Now that I mention it I can’t find anything actually written down; maybe noone has the courage to do so? The brief summary of these criticisms is that four-page papers are, variously, incentivising authors to: (a) chop up perfectly good longer papers into many four-page “epsilon” papers; (b) “hype up” their results by talking about how revolutionary they are; and (c) forcing authors to crunch lots of valuable calculations into a ridiculously abbreviated form.
I hear comparatively fewer people talking about what’s good about the four-page paper. I wanted to set down some ideas here that I feel aren’t entirely fairly acknowledged in over-dinner rants. My actual position now is that the four-page paper format has it’s flaws, but isn’t *all* bad.
1. I agree, without question, that a paper without length restrictions can only be a better paper. Why? Well, introducing constraints to an optimisation problem can never improve the optimal value! But, sometimes, constraints force us to be more creative: e.g. vegetarian food can be much nicer. By being forced to communicate an idea in four pages you can be inspired to be much more creative…
2. Four-page papers are easier to read. I am a very lazy person and now I have less and less free time. I typically don’t even download papers which are 30 pages or more, I just look at the abstract. I don’t think I’m alone in this. The point here is that reader attention is a finite resource: four-page papers are not a major commitment, and could be skimmed rapidly for relevance. Longer papers require more energy. In this world where you have to compete simply for the attention of the reader you have to acknowledge that a little bit of marketing is in order.
3. Supplementary material! You can probably say the main idea in four pages. If you want to include the details use the supplementary material. This counts as four pages for me: the idea and argument are still expressed in four pages. The details are there for the interested reader.
My feeling is that the four-page paper functions extremely well as an extended abstract rather than a proper paper. But often an abstract is all that is required to inspire and motivate further research and communicate a new argument/technique. (I’m reminded of the tale that Landau would only read the abstract of a paper and then rederive its contents… I don’t think this is so unrealistic in many cases.)
7 Comments | soft post | Tagged: academia | Permalink
Posted by tobiasosborne
At the moment I am doing some work which involves many lengthy derivations. Typically these derivations involve multiple integrals of matrix functions. (If you’ve ever had to do perturbation theory in quantum field theory you will have done similar calculations.) The problem is that if I make even a tiny mistake, e.g., a minus-sign error, then this snowballs into a big BIG mess. And the final answer needs to be correct because it’s to be used in a numerical procedure; the method goes crazy otherwise! (These calculations are for an application of the variational principle over cMPS to some example quantum field theories; you can look at a summarised example here where I’ve written out all the equations required to reproduce the numerics of this paper.)
I’ve given up on writing these calculations on paper because I keep having to tear it up and start again. (This is very frustrating if you’ve just written 10 pages of derivations and then you find a sign error on page 2; how do you propagate the corrections through the following 8 pages without ending up with an unreadable mess?)
So I’ve adopted an “algorithm” which appears to be fairly robust: I write all the derivations in latex. Then I copy and paste the current equation and make one, and only one, substitution/evaluation/rearrangement, and then repeat. This procedure quickly produces very long latex files. But I’ve noticed that when I make a mistake it is fairly easy to propagate the correction through the remainder of the notes. Also, I seem to make fewer mistakes. It may seem like a lot of work, but I think it’s better than tearing up paper!
What I dream of now is some kind of “automated derivation error correction” for my procedure. I don’t mean anything sophisticated, just some protocol where a derivational error can be detected and corrected many steps later without having to correct all the intervening lines. Perhaps some kind repetition encoding…? Of course one would need the discipline to actually apply it… 😉
Leave a Comment » | holographic quantum states, soft post | Tagged: cMPS, derivations, holographic quantum states, LaTeX, variational principle | Permalink
Posted by tobiasosborne
You are currently browsing the archives for the soft post category.
