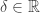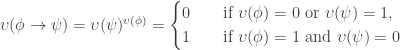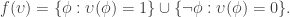Recently I’ve been learning about torsors. A torsor is, in informal terms, an algebraic structure that’s like a group with the identity element “forgotten”. The precise definition (whose connection to the informal notion is not meant to be obvious!) is: a torsor is a set 



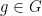

My interest in torsors comes from the idea that the set of all possible values of a dimensional physical quantity, such as mass, is intrinsically a torsor, because the choice of the unit of measurement is arbitrary. Therefore it might make sense to formalize dimensional analysis using the notion of a torsor.
I might have more to say about torsors themselves, and the connection to dimensional analysis, in a future post. But for now, I just want to write about one alternative way of capturing the idea of a “group with the identity element forgotten”, which was described in a blog post by Matt Baker.
Baker introduces the notion of a proportion space, which is a non-empty set 

- (PS1) For any two elements
.
- (PS2) For any three elements
of
such that
.
The idea here is that 


For example, in elementary mathematics, where 

Even if you heard about torsors for the first time when reading this article, you likely correctly inferred that “torsors” was the plural of “torsor” by way of the above analogy. Note however that the “existence” part of (PS2) does not seem to be appropriate in a linguistic context: I can easily think of triples of words where there isn’t a natural fourth word to complete the analogy, such as

Anyway, Baker claims that proportion spaces, as defined above, are essentially the same as torsors. More precisely, he sketches a proof of the following theorem:
For every set
Unfortunately, this theorem appears to be false for the chosen definition of proportion spaces. The flaw is in the second part of the proof, where a torsor is constructed from a proportion space. In order to construct the group the torsor is to be over, Baker takes the quotient set 
![\displaystyle [(a, b)]_{::} \cdot [(c, d)]_{::} = [(t(a, b, c), d)]_{::}, \ \ \ \ \ (1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+++%5B%28a%2C+b%29%5D_%7B%3A%3A%7D+%5Ccdot+%5B%28c%2C+d%29%5D_%7B%3A%3A%7D+%3D+%5B%28t%28a%2C+b%2C+c%29%2C+d%29%5D_%7B%3A%3A%7D%2C+%5C+%5C+%5C+%5C+%5C+%281%29&bg=ffffff&fg=000000&s=0&c=20201002)
where 


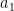
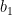
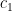
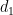



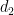



It turns out that for a general proportion space, this can’t be verified, because it’s a false statement!
Here’s a counterexample. Let 

The resulting equivalence relation 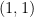



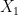
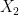
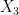


then we have

so for the product operation to be well-defined, we would have to have

and this is false.
By the way, I didn’t find this counterexample by myself. I used Mace4 to do it, using the following input:
formulas(assumptions).
R(x,y,x,y). % reflexivity
R(x,y,w,z) -> R(w,z,x,y). % symmetry
R(x,y,w,z) & R(w,z,u,v) -> R(x,y,u,v). R(x,x,y,y). % transitivity
R(x,y,w1,z) & R(x,y,w2,z) -> w1 = w2. % PS2 (uniqueness)
exists w R(x,y,w,z). % PS2 (existence)
end_of_list.
formulas(goals).
R(x1,y1,x2,y2) & R(z1,w1,z2,w2)
& R(x1,y1,u1,z1) & R(x2,y2,u2,z2)
-> R(u1,w1,u2,w2).
end_of_list.Anyway, what this shows is that the definition of proportion space given by Baker is too weak: to get the desired equivalence with torsors, we need to add an additional axiom to the definition, or strengthen one of the existing axioms. My preference is to strengthen (PS1) to the following statement:
(PS1′) For any four elements 

This implies (PS1), since we may take 


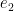

we have 



as desired.
Edit (9 June 2024): It turns out that I made a mistake too, in the opposite direction! Axiom (PS1′) is in fact too strong. For example, if you consider a group as a torsor over itself, then when turning the torsor into a proportion space, (PS1′) becomes

but this is only true when the group is Abelian (in general, 

In terms of the

There is a well-known alternative characterization of torsors, which says that a torsor is equivalent to a heap, which is a set

Mace4 readily finds a counterexample where the heap axioms are satisified, but not (2).
OK, here’s my second attempt at amending the definition: I suggest keeping (PS1) in its original form, which says that 

This can be understood as saying that the binary relation 

is transitive (while (PS1) says it’s reflexive; one can also easily prove that it’s then symmetric). Checking this with Prover9/Mace4, the conjunction of (PS1), (PS2) and (PS3) (along with the stipulation that
Here’s another proof that the product defined by (1) is well-defined, using (PS3) instead of (PS1′). We are given ten elements
and we need to prove that 

Let’s also check that if we have a

satisfies (PS3). (Here 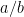

![\displaystyle a/e = [(a/b)b]/e = (a/b)(b/e) = (c/d)(d/f) = [(c/d)d]/f = c/f,](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++a%2Fe+%3D+%5B%28a%2Fb%29b%5D%2Fe+%3D+%28a%2Fb%29%28b%2Fe%29+%3D+%28c%2Fd%29%28d%2Ff%29+%3D+%5B%28c%2Fd%29d%5D%2Ff+%3D+c%2Ff%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
using the identity ![{[(a/b)c]/d = (a/b)(c/d)}](https://s0.wp.com/latex.php?latex=%7B%5B%28a%2Fb%29c%5D%2Fd+%3D+%28a%2Fb%29%28c%2Fd%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)
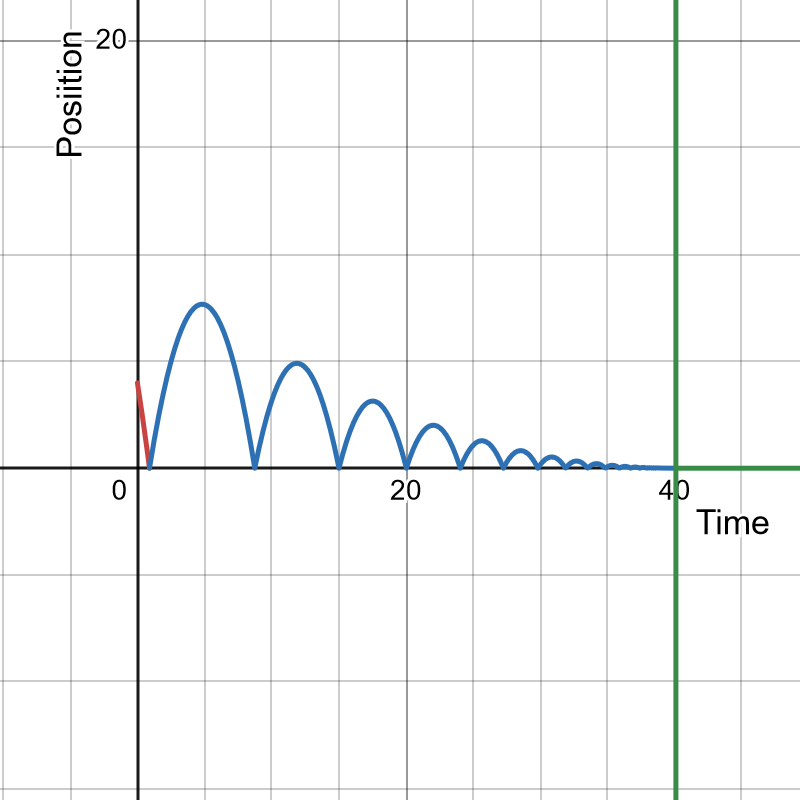
 . When the ball hits the ground, it is instantaneously deflected upwards, resulting in its velocity being scaled by a factor of
. When the ball hits the ground, it is instantaneously deflected upwards, resulting in its velocity being scaled by a factor of  , where
, where  is a constant strictly between 0 and 1 (the
is a constant strictly between 0 and 1 (the  such that the sum of their durations is always less than, but can be made arbitrarily close to
such that the sum of their durations is always less than, but can be made arbitrarily close to 
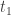 is the time at which the first bounce begins and
is the time at which the first bounce begins and  is the velocity of the ball at the start of this first bounce. (The formula does require you to know
is the velocity of the ball at the start of this first bounce. (The formula does require you to know  . So if we consider a bounce starting at a time
. So if we consider a bounce starting at a time 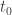 , where the ball has velocity
, where the ball has velocity 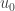 as it begins the bounce, the ball’s velocity
as it begins the bounce, the ball’s velocity  and position
and position  at any subsequent time
at any subsequent time  before the next bounce will be given by the equations
before the next bounce will be given by the equations
 . Using the equation for
. Using the equation for  :
:

 (which we already knew) and also that
(which we already knew) and also that 
 . Furthermore, substituting
. Furthermore, substituting  into the equation for
into the equation for  (this is also obvious if you visualize the bounce as a parabola). Hence the velocity at the start of the next bounce will be
(this is also obvious if you visualize the bounce as a parabola). Hence the velocity at the start of the next bounce will be  .
. and the velocity of the start of the next bounce will be
and the velocity of the start of the next bounce will be 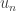 at the start of the
at the start of the  th bounce (for
th bounce (for 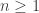 ):
):
 . Hence the total time taken by the first
. Hence the total time taken by the first 

 , we can take the limit as
, we can take the limit as 
 . If we say that the positive direction is upwards, then we can assume that
. If we say that the positive direction is upwards, then we can assume that  , because the ball can’t be below the ground. We also have an arbitrary initial velocity
, because the ball can’t be below the ground. We also have an arbitrary initial velocity  , and this doesn’t have to be positive like the velocity at the start of a bounce. It can be negative, positive or zero. So the equations of motion for the ball from time 0 up to the time the first bounce begins are:
, and this doesn’t have to be positive like the velocity at the start of a bounce. It can be negative, positive or zero. So the equations of motion for the ball from time 0 up to the time the first bounce begins are:


 and
and  , we have
, we have  , this means that
, this means that  and
and  . If
. If  , this means that
, this means that  and
and  . Whatever the case, we have that
. Whatever the case, we have that  is non-negative and
is non-negative and  is non-positive. So we can interpret the two roots as endpoints of a “0th bounce” which is already in progress initially.
is non-positive. So we can interpret the two roots as endpoints of a “0th bounce” which is already in progress initially.
 into the equation
into the equation  to get the velocity at the end of the 0th bounce:
to get the velocity at the end of the 0th bounce:  . The velocity at the start of the 1st bounce will be this scaled by
. The velocity at the start of the 1st bounce will be this scaled by 

 is the time the
is the time the  , we want to find the unique integer
, we want to find the unique integer  . Well, this chain of inequalities can also be written as
. Well, this chain of inequalities can also be written as
 and
and  are positive, we get the equivalent inequality
are positive, we get the equivalent inequality
 , and hence their composition is strictly increasing). So the chain of inequalities can also be written as
, and hence their composition is strictly increasing). So the chain of inequalities can also be written as
 , the “floor-plus-one”
, the “floor-plus-one”  of
of  ; hence we can conclude that
; hence we can conclude that

 , where
, where  of positive integers such that
of positive integers such that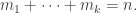
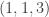 ,
, 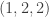 ,
, 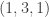 ,
, 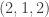 ,
,  , and
, and 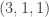 .
.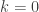 , the problem is simple. An ordered 0-partition is a 0-tuple. But there is only one 0-tuple: the empty tuple,
, the problem is simple. An ordered 0-partition is a 0-tuple. But there is only one 0-tuple: the empty tuple,  . And the sum of
. And the sum of 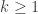 , we can try to reduce the problem to instances of the problem where
, we can try to reduce the problem to instances of the problem where 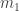 , …,
, …, 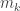 are positive integers that sum to
are positive integers that sum to 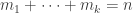 , we obtain the equivalent equation
, we obtain the equivalent equation  . This proves the following theorem:
. This proves the following theorem: is an ordered
is an ordered  -partition of
-partition of 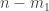 .
.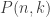 , and we denote concatenation of tuples by
, and we denote concatenation of tuples by  , we can write the following equations:
, we can write the following equations:
 taken in the third equation.
taken in the third equation.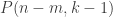 may be empty, so that nothing is contributed to the overall union by this particular value of
may be empty, so that nothing is contributed to the overall union by this particular value of 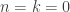 or
or  .
. , then
, then  1s, followed by
1s, followed by  (which is positive since
(which is positive since 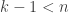 ), is an ordered
), is an ordered 
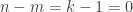 (i.e.
(i.e. 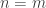 and
and 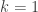 ) or
) or 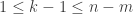 (i.e.
(i.e. 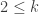 and
and 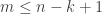 ). Hence we can rewrite the equations as follows:
). Hence we can rewrite the equations as follows: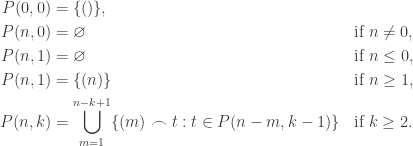
 in the category, which it is said to be on. The operation itself is an endomorphism on
in the category, which it is said to be on. The operation itself is an endomorphism on 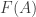 to
to 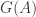 for some functors
for some functors  and
and  which are the same for every object. We call
which are the same for every object. We call 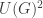 to
to  , where
, where 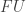 and
and 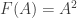 , and for every function
, and for every function 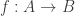 and any two elements
and any two elements  of
of 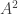 , we have
, we have 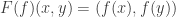 .
.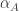 , then the naturality condition requires that for every morphism
, then the naturality condition requires that for every morphism 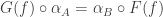 . This is just the requirement that
. This is just the requirement that  “preserves” the operation: applying
“preserves” the operation: applying 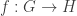 needs to have the property that for any two elements
needs to have the property that for any two elements 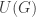 , we have
, we have 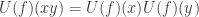 . (Of course we don’t usually write the forgetful functor explicitly, but we’re trying to be precise here.) If we write multiplication in
. (Of course we don’t usually write the forgetful functor explicitly, but we’re trying to be precise here.) If we write multiplication in  using prefix symbols
using prefix symbols 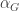 and
and  respectively, then this equation becomes
respectively, then this equation becomes 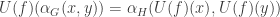 . Looking at the way
. Looking at the way 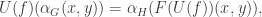
 .
. is a family of morphisms
is a family of morphisms 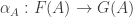 on objects
on objects  . In other words, it is like a natural transformation but it doesn’t need to satisfy the naturality condition. Now, if we have an operation like this we can consider the set of the morphisms
. In other words, it is like a natural transformation but it doesn’t need to satisfy the naturality condition. Now, if we have an operation like this we can consider the set of the morphisms  . It turns out that this set of morphisms is always closed under composition and contains every identity morphism, and therefore induces a subcategory of
. It turns out that this set of morphisms is always closed under composition and contains every identity morphism, and therefore induces a subcategory of  are morphisms in
are morphisms in 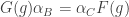 . Then
. Then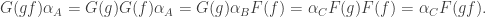
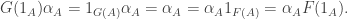
 , functors
, functors 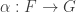 such that the morphisms in
such that the morphisms in