| CARVIEW |
The Day Chess “Died” and Was Reborn
On May 11, 1997, IBM’s Deep Blue defeated world champion Garry Kasparov. Game 6. Match point. After 19 moves, Kasparov resigned, stood up, and walked away from the board in stunned disbelief. For the first time in history, a computer had beaten the world’s best human chess player in a formal match.
The headlines were dramatic: “The Brain’s Last Stand.” “Man vs. Machine: Machine Wins.” Many declared it the end of an era. If computers could master chess, what was left for human intelligence?
But here’s where things get interesting.
Rather than retreating in defeat, Kasparov did something revolutionary. If he couldn’t beat the machines, why not join them? In 1998, he created “Advanced Chess,” tournaments where humans partnered with computers. These human-computer teams, nicknamed “centaurs,” didn’t just compete with the best chess engines but consistently crushed them.
Even more remarkable: the strongest centaur teams weren’t led by grandmasters. Amateur players who understood how to work with computers routinely defeated chess legends using identical technology. Anson Williams, an unrated British engineer who couldn’t achieve master-level play in traditional chess, dominated freestyle tournaments for years, winning 23 games and losing only one across four major competitions.
What people thought would be the end of human chess actually evolved into something more sophisticated. Humans and AI became partners, creating a form of chess that reached heights neither could achieve alone.
From Chess to Code: AI-Augmented Software Engineering
Today, as AI coding tools flood the software engineering landscape, we’re hearing eerily familiar narratives: “Software engineers will be obsolete.” “AI will replace programmers.” “The end of coding as we know it.”
But the chess story suggests we’re not witnessing an ending. We’re witnessing a transformation. Just as Deep Blue’s victory didn’t kill chess but evolved it into something more sophisticated, AI tools aren’t eliminating software engineering but pushing it to operate at an entirely different level.
The real question isn’t whether AI will replace software engineers. The question is: what type of software engineer will thrive in the centaur era?
The Grandmaster’s Cognitive Trap
When grandmasters first encountered centaur play, something unexpected happened. Their decades of pattern recognition and chess intuition sometimes became liabilities. They would override the computer’s tactical calculations based on “feel,” or trust the machine when their strategic insight should have prevailed. The very expertise that made them great at traditional chess occasionally hindered their ability to collaborate effectively with AI.
I see this phenomenon playing out daily in software engineering. Many experienced developers exhibit similar behavioral patterns with AI coding tools. We’re cognitively wired to write code heuristically, drawing from years of accumulated best practices, design patterns, and hard-learned lessons about maintainability, scalability, and architectural elegance.
Consider the internal monologue of a seasoned developer encountering AI-generated code: “This doesn’t follow proper abstraction principles.” “The variable names are inconsistent.” “It’s not using the Repository pattern.” “There’s too much repetition.” These observations aren’t wrong, but they may be constraining our imagination of what becomes possible when human strategic thinking combines with AI’s raw computational power.
The challenge isn’t that our experience lacks value. Rather, it’s that our assumptions about AI capabilities become outdated faster than we can update them. What we “knew” about coding AI limitations in early 2024 was largely irrelevant by late 2024. The landscape evolves so rapidly that rigid mental models become cognitive anchors, preventing us from exploring the full potential of human-AI collaboration.
The Rapid Evolution Problem
Here’s perhaps the most critical insight: younger developers are using these tools far more extensively than their experienced counterparts. This usage pattern creates a compounding advantage that extends far beyond simple tool familiarity.
While experienced developers critique AI-generated code quality by pointing out repetition, questioning architectural decisions, or lamenting violations of clean code principles, younger developers are discovering what’s actually possible today. And “today” changes every six months.
This creates an accelerating feedback loop. The more intensively someone uses AI tools, the faster they discover new capabilities. The faster they discover capabilities, the more they push against perceived boundaries. Meanwhile, those anchored to six-month-old assumptions about AI limitations find themselves falling behind an exponentially accelerating curve.
The phenomenon extends beyond mere technical proficiency. Through extensive interaction with AI systems, younger developers develop intuitive understanding of how to guide, coach, and collaborate with artificial intelligence across various contexts. This applies not just in code generation, but in problem decomposition, solution exploration, and iterative refinement.
Experience Reconsidered
The chess evolution reveals a crucial distinction between different types of expertise. Traditional chess knowledge like opening theory, tactical patterns, and endgame technique remained valuable in the centaur era, but its application shifted dramatically. Instead of using this knowledge to calculate variations (which computers did better), grandmasters learned to apply it strategically: choosing which positions to steer toward, understanding opponent psychology, and making high-level decisions about game direction.
Similarly, software engineering experience maintains immense value, but requires recontextualization. Our accumulated understanding of user needs, system complexity, business constraints, and technical tradeoffs becomes more important than ever. However, we need to stop applying this experience to critique AI-generated implementations and start applying it to envision AI-enabled possibilities.
The question isn’t “How many years have you been coding?” but rather “How effectively can you solve complex problems under real-world constraints when implementation speed increases by an order of magnitude?” Years of debugging experience matter enormously, but primarily for understanding what can go wrong at the system level, not for line-by-line code review of AI output.
Elevating the Game
The chess story offers a profound lesson about technological disruption. When the tactical layer gets automated, successful players don’t fight the automation. Instead, they elevate their game to focus on what becomes newly important.
Grandmasters who thrived in the centaur era weren’t those who fought the computer’s calculations, but those who learned to think more strategically about positioning, long-term planning, and meta-game considerations. The computer handled tactical variations; humans focused on strategic direction and creative pattern-breaking.
In software engineering, this elevation principle suggests shifting focus from code craft to system craft. Instead of lamenting that AI generates “messy” code (which improves monthly), we should be exploring fundamental questions about what becomes possible when implementation constraints change dramatically.
Consider how these tools change our approach to system architecture when prototyping becomes nearly free. What new possibilities emerge when the cost of experimentation approaches zero? How do we design systems when we can rapidly test ideas that would have required weeks of manual implementation? What becomes possible when we can instantly explore multiple architectural approaches and compare their real-world performance?
The AI isn’t writing “bad” code that needs fixing. It’s writing functional code that frees us to operate at higher levels of abstraction. Just like chess engines freed grandmasters from calculating tactical variations so they could focus on strategic planning, AI tools should free us from implementation minutiae so we can focus on user problems, system design, and creative solution exploration.
The Acceleration Advantage
To understand the magnitude of this shift, consider how learning curves might change in the AI era. Traditional software engineering improvement follows a familiar pattern: rapid initial progress followed by diminishing returns as developers encounter increasingly complex challenges that require deep experience to navigate.

But AI-assisted development potentially alters this fundamental relationship. When AI handles routine implementation tasks, developers can focus immediately on higher-order problems. When debugging becomes more efficient through AI assistance, the feedback loop between experimentation and learning accelerates. When architectural exploration becomes rapid and low-cost, developers can gain experience with system-level decisions much earlier in their careers.
This suggests that AI-assisted developers might not just learn faster. They might achieve performance levels that traditional experience curves suggest should be impossible. Like the amateur chess players who defeated grandmasters in centaur tournaments, developers who master AI collaboration early might leapfrog traditional experience hierarchies entirely.
The Generational Divide
The most striking observation from contemporary practice is generational. Developers born in the 1990s and early 2000s occupy a particularly challenging position in this transition. We possess enough experience to recognize quality and understand best practices, but not enough financial security to opt out of the technological shift entirely.
More problematically, our cognitive frameworks have crystallized around patterns that may no longer optimize for the right outcomes. We think in terms of code elegance, architectural purity, and implementation efficiency. These are mental models developed during an era when human coding time was the primary constraint.
In contrast, developers entering the field today approach AI tools with what Zen Buddhism calls “beginner’s mind.” They don’t carry cognitive baggage about “how things should be done.” They experiment fearlessly, fail quickly, learn rapidly, and iterate continuously. They treat AI as a natural extension of their problem-solving toolkit rather than a threat to established practices.
This isn’t merely about tool adoption. It represents a fundamental difference in problem-solving approach. Experienced developers often try to guide AI toward producing “proper” code. Newer developers focus on guiding AI toward solving problems effectively, regardless of whether the intermediate steps conform to traditional best practices.
The Path Forward
For those of us navigating this transition from positions of established expertise, the chess narrative suggests a specific approach: intellectual humility combined with strategic elevation.
Intellectual humility means suspending judgment about AI capabilities based on outdated experiences. The tools evolve faster than our ability to form accurate mental models about their limitations. What felt impossible six months ago may be routine today. What seems like a fundamental limitation may be tomorrow’s solved problem.
This doesn’t mean abandoning critical thinking. It means being more precise about where to apply our analytical energy. Instead of critiquing AI-generated implementations line by line, we should be critiquing problem decomposition, solution architecture, and strategic direction. Instead of optimizing for code elegance, we should be optimizing for user outcomes, system reliability, and business value creation.
Strategic elevation means focusing on what becomes newly important when implementation speed dramatically increases. System thinking across technical and business domains. Creative problem-solving when standard solutions don’t apply to novel contexts. Product intuition and user empathy. Stakeholder communication and requirement translation. These fundamentally human capabilities become more valuable, not less, in an AI-augmented world.
Redefining Excellence
The chess evolution ultimately redefined what it meant to be excellent at the game. Traditional metrics became less relevant than new capabilities: ability to guide computer analysis toward strategic goals, skill at choosing promising positions to explore, intuition about when to trust or override the machine’s recommendations.
Similarly, software engineering excellence is undergoing a similar redefinition. Traditional metrics matter less than new capabilities: skill at problem decomposition, ability to guide AI toward effective solutions, intuition about system architecture and user needs, proficiency at rapid iteration and experimentation.
This shift doesn’t diminish the importance of technical depth but redirects that depth toward different areas. Understanding databases becomes less about optimizing individual queries and more about designing data architectures that remain coherent across rapid iteration cycles. Understanding algorithms becomes less about implementing them from scratch and more about knowing when and how to apply them strategically within larger systems.
Conclusion
The story of chess after Deep Blue offers a fundamentally optimistic perspective on the AI transformation of software engineering. Rather than replacement, we’re likely to see evolution. We’ll witness the emergence of new forms of human-computer collaboration that achieve outcomes neither humans nor AI could accomplish independently.
The developers who will thrive in this new landscape are those who learn to be exceptional centaurs: leveraging AI’s computational power while providing strategic guidance, creative insight, and contextual wisdom. This requires not just learning new tools, but unlearning some old assumptions about what constitutes good engineering practice.
For those of us carrying forward experience from the pre-AI era, the chess story suggests a specific approach: apply our accumulated knowledge strategically rather than tactically. Use our understanding of user needs, system complexity, and business constraints to guide AI toward better solutions, not to critique AI output against outdated standards.
Most importantly, the chess evolution reminds us that technological disruption often creates entirely new categories of human potential rather than simply replacing existing capabilities. Kasparov didn’t become irrelevant after losing to Deep Blue. He became the pioneer of an entirely new form of chess that reached heights neither humans nor computers could achieve alone.
The same transformation awaits software engineering, if we’re wise enough to embrace it. The future belongs not to those who can write the most elegant code by hand, but to those who can orchestrate the most elegant solutions using all available tools. This includes human creativity, AI computation, and the emergent capabilities that arise from their thoughtful combination.
In this new era, our most valuable skill may not be coding at all, but rather the ability to envision possibilities, decompose complex problems, and guide intelligent systems toward solutions that genuinely improve human life. The game has changed, but the players who adapt thoughtfully will find it more rewarding than ever.
References
[1] Lee, S., et al. “AI and Critical Thinking in Software Development: A Survey Study.” Microsoft Research (2025). https://www.microsoft.com/en-us/research/wp-content/uploads/2025/01/lee_2025_ai_critical_thinking_survey.pdf
[2] Kosmyna, N., et al. “The Impact of Code Generation Tools on Developer Problem-Solving.” arXiv preprint arXiv:2506.08872 (2025). https://arxiv.org/abs/2506.08872
]]>

可能認識我的人都知道 Neurips 這個會議我對它頗有微詞,但它的時間點與規模依然有它獨特優勢(相對其他 conference ICML, ICLR, COLM? .. ):
- 每年最後一個 AI 會議 - 這讓我們能總覽過去1-2 年的研究趨勢(明年能做、還不能做與明年開始已經太晚的題目)
- 像是今年 D&B oral 的作者去年就找過我聊她今年這篇論文的方向,而我今年也有稍微聊她明年想做的方向
- 全世界最大的 AI 會議 - 最多 industry 的人參與,創造了跨領域想法碰撞的最佳場域
另外定義一下 GPU 乞丐 : 凡是沒有 8張 A100 可以揮霍的都是乞丐
2023 vs 2024 的觀察
2023 年的主要觀察
- 學界與非 frontier lab 對於 LLM 的應用策略仍在摸索中。許多應用依然停留在簡單的場景,但是一旦上線遇到問題還很難解決問題 Reddit : AI Agents: too early, too expensive, too unreliable
- 在不需要重新訓練的條件下,仍有研究空間:如探索 LLM 行為、漏洞 (looking inward, let me speak freely, selection bias)
- 2023 年的小型模型仍有提升潛力,但2024 年透過大量 high quality post training task + model soup, 這差距已經被大型實驗室快速填補起來了 (mix data or merge model?, llama 3.2)
- 開源多模態模型尚未成熟,簡單的 LLaVA 架構已能達到不錯效果(主要靠堆疊數據)
2024 年的疏忽
小模型的天花板
我在 2024 年確實在 LLM 行為漏洞方面發表了一些研究。但我也忽視了小型模型在數學能力上的突破:現在 3B 參數的數學特化模型竟能超越 2023 年十倍大小的模型。甚至 pretrain 的 base model 還超越去年大一個數量級的微調模型 (qwen2.5-math-1.5B MATH score 75.8, arithmetic without algorithm)。我認為這塊,我忽視了去年數學資料的骯髒程度、也高估了LLM 在解數學任務的難度。
Think step by step is computation
其中還有我認為忽視了step by step reasoning 的本質意義:將生成新的字當作是搜尋的步驟,並且把蒙地卡羅擴散搜尋的動作攤平後則可以看成是一系列扁平化的探索操作的話,本質上這就是 think step by step 在做的事 。
2024 年 NeurIPS 觀察到的趨勢
上升趨勢
- Academic 研究方向的轉移:
- 過去在 pretrain scaling 受限於高工程門檻與運算成本,今年除了oral 的那篇 not all token is all you need, 幾乎很少說 pretraining 相關的論文 - 體感
- Test time scaling 提供了新機會(可控制在 5B 參數內),並且我認為是GPU乞丐還可以做的題目 - test time is more effective scaling, incentivize, don’t teach
- Agent 研究的進展:
- Language agent 有重大突破(部分歸功於 LLM 基礎能力提升) - CS 194/294-196
- 但距離真正的 agent-native 效果仍有距離,目前更像是優化後的 workflow
- 資料品質與稀缺性:
- 評測資料氾濫但質量下降
- 評測資料幾乎沒有附上任何訓練資料
- 我認為很多 benchmark 沒有從使用 benchmark 的角度思考(評測環境設定難度、評測資料數量、數字的意義)- spider2-v
式微趨勢
- 預訓練研究減少:
- 預訓練幾乎無人問津
- 微調討論降溫
- 轉向 TTA(test time adaptation): 也就是模型在 inference 模式時根據資料的輸入調整自己去適應 input - ARC-AGI test time training
- Prompting 方法演進:
- 純 prompting 改善 Chain of thought 的方法減少
- 轉向結合 training 與 external guidance 提升下游能力
2025 年研究方向展望
如果我在 2025 年想做 LLM 研究且跟我一樣房間裡一樣只有一張 3090 你可以:
- Reward Modeling 研究方向:
- 如何訓練更好的 scalar-based reward model
- 探索 reward model 行為一致性問題
- 原因:訓練成本相對較低,模型穩定性高
- 特別是多模態 reward model(如 audio-based)仍有很大發展空間
- Agent-First 研究:
- 深入探討 language agent 中 language 與 agent 的本質
- 思考 language 的局限性,agent 能彌補什麼?
- 研究 language agent 在解決高挑戰性 benchmark 時的優勢
- 例如:ARC-AGI、AIME-2024 等
- Test time inference / adaptation :
- 這方向具體做法還是在百花齊放的時候,但是我認為這裡每個 flops 帶來的下游提升幅度會是遠小於 pretraining 或是 large post-training 的需要。
- 另一個我個人私心也想探討的是 program synthesis 方向(偏門題目)但屬於 underrated 的題目也會是能在數學、ARC-AGI 繼續大放異彩的地方
- 但是這類題目我認為對於運算的把控需要更加的精準,如果你問題對於提升 compute 進而帶來的下游提升不夠大則不是一個很好的方法。

source : Ilya neurips 2024 - test of time talk
反思、復刻、討論
讀到這裡我希望你先不要急著去選擇做任何的題目,而是花更多時間去補齊每個領域已有的 paper 再來做。因為大概70-90% 的 idea 已經有人做過類似的。我覺得在 AI 發表論文速度遠遠甩開人類閱讀速度的時代,從更高維度去反思這些做法的矛盾、缺陷在哪裡。另外如果你沒有親自跑過任何相關的論文,我極度建議去復刻看看每個方法,親自體驗一下任務難度、解決方法的實際弊病、LLM 具體說了什麼,才開始提出自己的見解。
卷、卷、卷
記得地球另一端的魔法師對於 6個月3篇論文的評價 : this is a normal pace

所以記得多組隊打怪,Ape together strong
]]>

Podcast episode : 特别放送:一个 AI 创业者的反思、观察和预测
Original transcript in chinese can be found here
I am not going to just do a english translation of this posts, you can copy and paste the entire post transcript into GPT-4 and it should give you a reasonable translated article. This article is about a short writeup on the interesting parts and some thoughts of mine.
The entire posts is quite long even in chinese, but they basically discussed these ideas which I find pretty interesting.
-
What’s the valuable part in this LLM trend?
-
Some predictions by the speaker : context and embedding
-
Gap widens between user needs and technical alignment
These are also some of the questions I have been asking myself since the start of chatGPT phase
1. What’s the valuable part in this LLM trend?
Basically there’s 3 parts the term valuable can be defined or viewed from:
We are all equal
Similar to the early phase of iPhone apps store where the most popular apps are still farts app or flashlight. Productivity apps would not emerge until a few years later. As of June 2023, we are still in the farts app in LLM applications (fart phase).
So for startups we are actually on the same starting point as the giants on the application side. Such as a rewind.ai like service running on your smartphone offline. Meaning your phone runs a “small” LLM which aggregates and answer all the questions you had in your phone. Or on-perm service using special accelerators such as MLU370 and M100 (not Mi100). Since there’s a need in China to replace certain percentage of your stack to china manufactured hardware, I think this example is only unique in China only.
I find the on-device idea pretty interesting because for one I was training a few 3B chat models few months back and 3B is actually in the range where you can run it on your iPhone. But for such as “small” model, its bit hard to make use since one of the core of LLM trending cause is that its very versatile, meaning you can use it to do any kinds of things without prior design. But for 3B model, it really can’t handle unseen task in my testing, this novel use is only and could only be improved via scaling the weights (3B -> 7B -> 13B). So in order to find any use of turning your iPhone into a hand warmer, there must a killer application for it to exist. For example, your on device LLMs would help you reply chat message or aggregate which apps you should open or use next?
Data
There’s a unique take on what defines data moat here which I find the most interesting and I quote (in slight translation of mine):
I think from the start of the chatGPT phase, a lot of voices are showing data platform are going to close up their access (Reddit, StackOverflow) to show case their own “unique” data value. But right now even proprietary data which you have collected would not be valuable anymore.
My personal interpretation of this means any “proprietary” you have collected to train a model would have no value. For example, the labeling and conversation data collected by OpenAI used to train the SFT or reward model phase. In the original article, the speaker refers to data collected in your vertical stack.
So what’s valuable then? Its the data which do not belongs to you. For on-premise deployment example, the solution and the data which was generated via this on-prem is valuable cause it bonds you (the service provider) and the enterprise (customer) together. For example a human feedback pipeline which is closely integrated with the customer stack and the customized module trained on this pipeline (ie LoRA).
Focus in building relationship with users
Subsequently after the popularization of LLM, you could now use in context learning prompts to solve any problem. So what’s most valuable left is in creating a relationship with your users instead of creating a custom model/service stack to solve the problem. Thats a echo for the data moat problem, which I agrees 100%
2. Some predictions by the speaker : context and embedding
Prior to word2vec understanding or query of text relies on building hard mapping of synonyms and antonyms of words. And word2vec would map word into a latent space where thinsg with similar meaning (the mapping) could be learned without supervised (unsupervised). But one problem with word2vec is that it would think Apple (the company) and the fruit are the same since it’s learned on a word basis without considering the context.
After word2vec, we have the next big change which is Elmo, solving the “Apple” problem of word2vec. Its not really popular compared to Elmo because after a year there’s BERT which tackles exactly the same problem but way faster due to the parallelism nature of transformer compared to recursive models (Bi-LSTM)
And the next big innovation the speaker thinks would be context size, ie the numbers of tokens your model can handle and still do well. Current method relies on embedding method for long context via retrieve and append to the prompt strategy. But in and my experience, embedding method rarely exceed traditional search method in 90% scenario. Another issue with embedding is the number of information stored vs traditional reverse index method. One trick I saw again and again used to encode long article is a overlapping window method where you only encode few sentences as a embedding and move the sentence window forward until you reach the end of article. This method obviously would generate a large amount of embeddings representation the article, but its currently the most effective method.
3. Product managers who really knows AI ML
Building a machine learning product or “AI” central product is very different than “traditional” product. Traditionally, services focus in QPS (query per second) and scalability. But for ML product, especially LLMs product there’s really no QPS. And the most important part is how feedback would be built in the product from the 1st day.
Midjourney for example, would generate 4 images for your prompt and the one you choose would be the human preference image which Midjourney could use it to train a better model (tweet)
But one concerning issue raised by Peak, is with the complexity of LLMs stacking up, the distance between users understanding and technical alignment gap are also going to get wider and wider.
Closing thoughts
I would like to quote Peak’s ending here, cause its really what I think of his previous product Magi search:
你覺得你解決了最顯眼的問題作為你的護城河,但其實有些人在用一個包抄你的方法在解決你的問題。對於任何一個技術創業者,絕對不要把最顯眼的 limitation 當成自己唯一的護城河,需要找到除此之外的點。不然會重蹈我的覆轍
Translate by GPT-4
“You believe that by solving the most conspicuous problems, you have created your moat, but in reality, some people are addressing your issues in a way that outflanks you. For any tech entrepreneur, never treat the most conspicuous limitation as your only moat; you need to find points beyond this. Otherwise, you will repeat my mistakes.”
(Canceling my grammarly subscription and hello ChatGPT Plus)
Just a little bit of context, Peak last founding company was Moji, basically they could generate a knowledge graph from a pool of corpus and achieve a near realtime update of the knowledge graph. Solving this requires a lot of NLU technique such as intent understanding, open information extraction, relation extraction etc back when solving NLP or NLU requires a dedicated model design. But as in June 2023, I could do all the same thing with a single prompt using GPT-4 and simply parsed the knowledge graph from the model response. Any prompt engineer could overtake any NLU based service as long as money is not an object.
This episode really sums up some of my consideration during this period of explosive technical application in LLMs. Embedding based query is cool and I have been using it since 2021 since CLIP, but pure embedding really add alot of hidden technical debt you can’t really tackle immediately, hence lengthen your release cycle. Chat based LLMs interface aren’t really useful other than programming domain, good luck buying and scrolling a ecommercial website via chat interface.
What I really think LLMs are really good is aggregate and summarize, and by summarization I don’t refer to the traditional point like summarization. But task based summarization for example you could train a LLM to look at bunch of images and tell me what does the overall image represent or give a transcription of podcast and convert it into a readable article. These kind of new data normalization flow is really where LLMs will shine. Not being sentient or solving MIT EECS problem
Glossary
]]>- Large Language Models (LLMs) like GPT-4 still face issues in search results relevance, tool usage, and planning, limiting their effectiveness for real work situations.
- OpenAI could use more targeted training and data generation to improve LLM performance in these areas, while the open-source community needs clever solutions to keep up with limited budgets.
- Although current limitations persist, collaborative efforts within the open research community could potentially address these issues and help accelerate AI development.
You could read it and judge whether its useful or not
Recently I have been spending more time reading than training LLMs (Large Language Models) as research publication in these domain started to surface due to hype started since release of ChatGPT around Nov 2022.
However, from myself and my peers personal encounters with employing AutoGPT to handle real world problems, the results more often than not dissapoints me. Of course don’t take me on face value that GPT-4 is bad, its still useful for other stuff but certainly not the job cutting excuse C-level came up to fire normies ~~ and not that company is burning out of cash~~.

Reference to retrieved materials
Luo, Hongyin et al. “SAIL: Search-Augmented Instruction Learning.” recently shows search results based response have problem with selecting the relevant reference out from the search result. This study shows that event ChatGPT with search sometimes failed to reference the relevant answer and started to hallucinate. Even in Bard with retrieval, the result also contain some imaginary facts tweet.
Tool use is still a problem
Since the release of Schick, Timo et al. “Toolformer: Language Models Can Teach Themselves to Use Tools.”, there are many research and commercial attempt in “teaching” LLMs to use as many online tools as possible. For example, knowing when to use search engine is pretty useful to solve the knowledge cutoff problem.
Recent release of chatgpt plugin found that LLM more often than not fails to execute the plugin correctly reddit post. I once saw a tweet about the success rate for plugins but failed to find it again, so you have to take me at face value for this single reddit post. Ideally, we should have a consensus of how plugin are tested and better a review function like play store and app store have been doing for years. But the underlying problem might be these LLMs are not trained to handle complex naming scheme or outlier inputs which took the attention way from the models and started to output gibberish results.
In the open source domain, there are datasets or ideas in teaching models to use tools and more specifically increase the success rate of tool use ( generate a correct requests, successfully output the reply based on the response from the requests )
Need more dataset in planning
When AutoGPT first came up on twitter, most SV or WSJ investors got pumped up as it promised the future where companies could fire all their expensive eng and remove the perks such as massage, business class flight expenditure from their quarterly reports.
But the experience for me and my peers are complaining about GPT-4 kept getting stucked in a loop where the “agent” kept repeating itself on the same sub task. Disclaimer, most of us tested on real programming challenge we faced IRL and not the generic planing a trip to somewhere or write a MVP app/plugin.
Recent paper by Valmeekam, Karthik et al. “Large Language Models Still Can’t Plan (A Benchmark for LLMs on Planning and Reasoning about Change).” discovered that neither of the LLMs (Large Language Models) can generate a plan to solve a basic toy problem. This study provides evidence that AutoGPT is not yet ready for its prime time and indicates an overhyped perception of its capabilities.
For OpenAI they could pay their sub contractors to generate more plaining questions and overfits teach the model to do plaining. But for open source community, its hard to came up with such expensive labeling solution so we might need a more clever way to generate such dataset.
Final notes
The 3 issues I mentioned above aren’t unsolvable problem, heck the open source community could waited for the next GPT update and simply clone them. But I think it would showcase the speed in where open research could cowork together and solve the solution through clever tricks and prompting which solving the problem within a small budget as compare to the closed AI research teams.

- definition of real work is not writing test cases nor template code for CRUD app. some examples of real work: write a viable solution for finding the best voted rank of orders, parse simple text responses, etc
WebGPT: Browser-assisted question-answering with human feedback
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Meena - Towards a Human-like Open-Domain Chatbot
A previous version of Google LaMDA model
Cosmos - SODA: Million-scale Dialogue Distillation with Social Commonsense Contextualization
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
]]>Also note that I am not a CPU architect designer, nor do I work in related industry. I am just a random dude who happens to assemble a dozen of workstations, servers and spent a lot of time watching Youtube CPU reviews.
A basic understanding of simple CPU
So what a CPU does is do calculation : addition and moving data around. So in order to tell the CPU what to do, you need a set of rules and format to follow so everyone can follow. The rest are just abstraction or syntax sugar for the gen Z.
I try to be simple and skip something here because I need to spent the space on discussing “modern” CPU design

Instruction
Suppose you have some input store somewhere with the address of that data and you want to do an operation on these data ( addition, subtraction, division, move to other address ). You need to write these command.
So this is where instruction come to play.
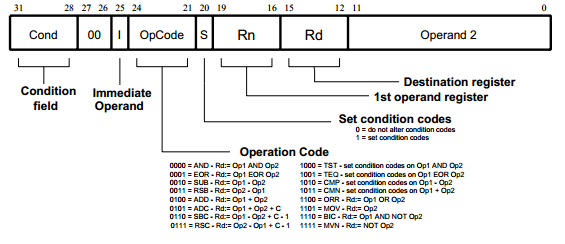
As of the 2022 modern world, we had x86 (CISC), ARM (RISC) making up the majority of CPU we use. Although the differences are becoming more blurred
Arithmetic logic unit (ALU)
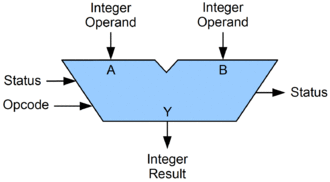
Once you know the instruction, a CPU can now parse these instruction and pass it to an ALU to do calculation. An ALU basically takes care of the addition, subtraction… all the math operations.
Execution Pipeline
So you have a instruction you wish to run, what steps are you going to do?
The steps of a CPU instruction can be broken down into the following phases:
-
Fetch: The CPU retrieves the next instruction to be executed from memory.
-
Decode: The CPU decodes the instruction to determine what operation it specifies.
-
Execute: The CPU carries out the operation specified by the instruction.
-
Store: The CPU stores the result of the operation in memory or in a register.
These steps are typically performed in a repeating cycle known as the fetch-decode-execute cycle, which allows the CPU to continuously execute instructions and perform operations on data. The speed at which the CPU can perform this cycle is known as the clock speed, and is measured in hertz (Hz). The faster the clock speed, the more instructions the CPU can execute per second.
However we doesn’t want to do only math function, we also want to do series of functions sometimes repeatedly. So we had Accumulator, that is used to hold the result of arithmetic and logic operations performed by the CPU. In most cases, the accumulator is a register that is used to store the result of an operation performed on data from memory or from another register. The accumulator is an important part of the CPU because it allows the CPU to perform a wide range of operations on data without having to constantly read and write to memory, which would slow down the computer’s performance.
Microcode engine (decoder)
As CPU design became more complex, the control logic for executing an instruction started becoming more complex and bigger. Hence microcode design was proposed to act as a abstraction between instruction and machine pipeline execution. Microcode optimization has since be one of the key optimization in many Intel CPU releases since 8086 (1978).
In modern CPU, the microcode is what drives the decoder section inside the CPU.
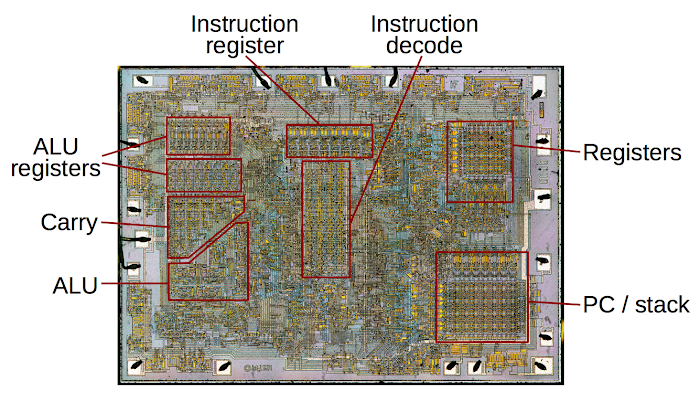
And here’s a i7-6700K die shot:
In modern CPU, the microcode is what drives the decoder section inside the CPU. | And here’s a i7-6700K die shot:
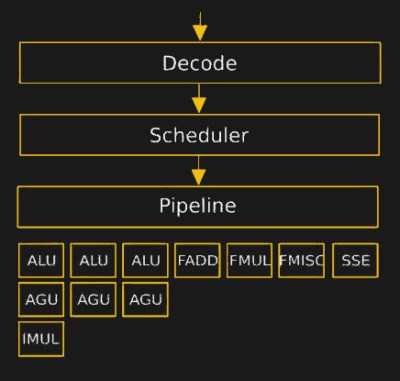
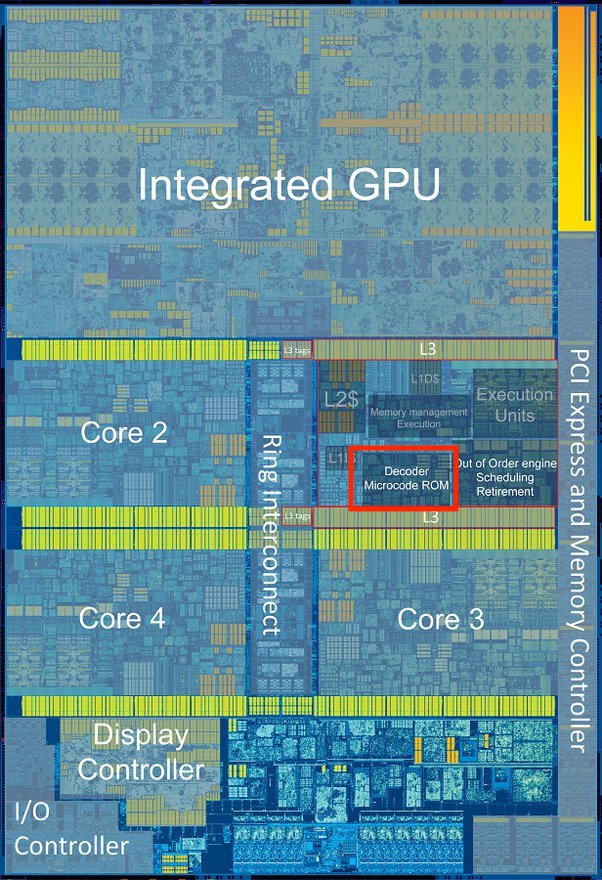
On the left, the microcode is what drives the decoder section inside the CPU (source). While on the right is a i7-6700K die shot, the microcode decoder is highlighted in red rectangle. Each core has their own microcode decoder.
I decided to skip multiplexor, scheduler, accumulator, register, how does an instruction work…, just google yourself. You are here for the “modern” part.
Modern tricks that make your CPU fast
As you might have noticed, a more modern CPU doesn’t look like this (source) 8008 CPU by Intel in 1983.
But this (source)

Much have changed since and I will elaborate some of the major changes that shape our modern CPUs.
Do note what I am showing here is only the tip of an iceberg and are only those which are interesting. If you wish to go down the rabbit hole here’s some keyword that can kept you busy : NUMA topology, big LITTLE, Re-order buffer.
Multi thread
Multithreading is a technique used by computer systems to improve the performance of certain types of applications. It involves allowing a single CPU, or central processing unit, to execute multiple threads of execution concurrently. Each thread represents a separate sequence of instructions that can be executed independently of the other threads. By executing multiple threads concurrently, the CPU can improve its overall performance and make more efficient use of its resources. This is because it can switch between threads whenever one thread is waiting for input or output, allowing it to continue executing useful work even when some threads are idle.
SMT
SMT, or simultaneous multithreading, is a variant of multithreading that allows each physical CPU core to execute multiple threads simultaneously, rather than just one thread per core as in traditional multithreading. This allows the CPU to make more efficient use of its resources and improve its overall performance by allowing more work to be done in parallel. SMT is often used in applications that need to perform multiple tasks concurrently, such as web servers and media players.
Both multithreading and SMT are important techniques for improving the performance of modern computer systems, and they are used in a wide range of applications. These techniques allow CPUs to execute more instructions in parallel, which can improve the overall speed and efficiency of the system.
IBM Power CPU has 4 SMT (or 8) as compare to the typical 2 SMT (1 core running 2 threads at the same time). As discuss in this reddit thread.
Branch predictor
Branch instructions are a type of instruction that can cause the CPU to branch to a different part of the program and execute a different sequence of instructions depending on the result of a conditional test. For example, a branch instruction might be used to check if a number is greater than zero, and if it is, the CPU will branch to a different part of the program to execute a different set of instructions. Branch predictors are used to improve the performance of the CPU by predicting the outcome of branch instructions and speculatively executing the appropriate instructions before the result of the branch is known for sure.
TLDR; Predict the outcome of the branch (where do your instruction jump to next, for example : if-else logic ) in order to execute the branched instruction section while you wait for the predict branch to finish. If your predictions are incorrect, you need to fallback and execute the correct instruction.
This allows the CPU to avoid stalling and continue executing useful work while it waits for the result of the branch instruction.
The longer your branch pattern and branch count are, the worse branch predictor performs. You can see it quite clear in this i5-6600k branch predictor visualization by clamchowder

Speculative execution
Following the jazz of branch predictor, we can also predict what instruction you will need to execute next and run it first. If the prediction turns out to be correct, the results of the speculative execution can be used immediately, which can improve the overall performance of the CPU. If the prediction is incorrect, the results of the speculative execution are discarded and the correct instructions are executed instead. Speculative execution is a complex and highly optimized process that is essential to the performance of modern CPUs.
If you ever heard of Meltdown/Spectre, this is the part where designers fucked up which lets hackers to access unauthorized section of memory address. Intel releases a microcode patch which claims to have fix this issue with a 6-10% worse performance (source). We can safely assumes that speculative execution contributes at least the same margin of speedup.
Tiered cache (L0-L3,4 cache)
One unsung hero of double digit improvements over generations in CPU/GPU since 2019 must be the cache size increase.
Once CPU/GPU started became very efficient at number crunching, they will soon bottleneck by how fast the data can be fetched to keep them fully ultized. This is where tiered cache such as L0, L1, L2, L3 cache come into play. By storing some frequently accessed data and instructions near the ALUs, the idle time can be reduced significantly. However you also risk spending precious time searching each different cache level while you can fetch it from the memory.
| Previous generation | New generation | Improvements* | |
|---|---|---|---|
| Nvidia 90 series | L2 6MB (3090) | L2 72MB (4090) | 42% |
| Intel i9 | 30MB (12900k) | 37MB (13900k) | 13% |
| AMD ryzen 8 | 32MB (5800X) | 96MB (5800X3D) | 15% |
| Apple M1 series | 16MB (M1) | 48MB (M1 Max) | 0-1% |
Note : Improvements varies by benchmark and cannot be compared across different compute from different designs; single core benchmarks are taken for CPU.
For a very long time, cache was seen as a good to have but not important element (Intel cache size was stagnant for quite a while). I think there’s two major element at play here : low core count and cache space.
Since AMD releases their Zen CPU, cache size has been increasing generation over generation due to more core needing to cache more data. However cache also populate precious space on the CPU die which the cost increases exponentialy by area (the larger your die is the higher the cost). IBM was able to work around this by offering their own internal SRAM design (yes all the L0-L3 cache are assembled from many SRAM cells), for a long time are the smallest cell in the industry. I think is at the expense of more complex manufacturing process hence higher cost.
IBM show casing 256MB of L3 cache on HotChips 33

It was until recently TSMC was able to offer their SRAM design which is dense enough for IC designers to own the luxury of large cache size. As well as the new 3D Fabric which allows SRAM to be stacked on top of the CPU die.

More materials
Writing about the interiors of modern CPUs has been on my TODO list for a while. While I tried my best to elaborate on these concepts, ultimately executing the final results on the final product (CPU/GPU) are done by thousands of engineers and collaboration across different fields ( signal integrity, semiconductor fab … )
Here are a dozen of sources I usually read to keep up with the latest advancement in modern computing:
-
Moore’s Law Is Dead - Youtube channel
Good for rumours, consistently accurate enough to plan out my future builds.
-
They have pretty detail benchmarks for new product release.
Footnote:
This article is cowritten by ChatGPT in small sections to speed up my narrative writings. ChatGPT does not guide any of my writing direction and opinions.
]]>
I dont really like talking about myself either. And most of these things here I don’t really talk about myself. I do give anecdotes of my life but they’re more to illustrate a point. Because anything about myself is useless to you. Don’t be like me, that’s dumb. I try to give you information so you can think - George Hotz
關於我的背景:大學來台灣唸書6年(交大電機碩士),成績不怎麼樣,但是寫寫程式還行的普通人。目前在小公司擔任機器學習工程師
以前我在軟體實習的時候就感覺我是一個坐不住的人。用中文來說就是我無法長久專注,遇到我感興趣的問題就會沒日沒夜去找出 solution,大概3-6個月就會失去興趣。所以我的 side projects各種成長,但是沒幾個能持續維護的。因此在實習以後我就覺得我應該不會適合去大公司做企業印鈔器中的奈米螺絲。我就不想一天就寫一個 function 打卡下班
因此實習到一半其實我就做不下去提早結束實習,開始我的技能樹展開生活。大學從 android app、農委會計畫當程式打手、寫網頁前後端並搭上ML/AI崛起的熱潮,變成如今在 “AI” 騙吃騙喝 做關於文字理解 & 處理、影像處理、推薦相關的商業應用,偶爾實作 paper打臉人。然後2021年碩士電機畢業。
啊,2021年的電機系畢業,應該過得很好吧?
Nope, 因為我去了軟體業
台灣軟體業
1. 台灣軟體業心酸
蛤,軟體不是科技業啊
畢業的時候剛好遇到竹科大徵才時代的最後一波,因此同屆的朋友隨便面試都可以到年薪 > 120萬的級距(這是排除我後的低標),對我形成不小的壓力。但好在工作半年後升遷拿到了約竹科2022年二線水平的待遇。
2. 在薪資上,年資 > 實力??
“我有5年經驗,所以我值得 N ”
因為有幸獲得上司青睞,所以參加了幾場新人面試,我發現一個事實是舒適圈的可怕。有一次面試到一位竹科10幾年經驗的工程師(做內部雲服務),在面試時連簡單考的邏輯程式都寫不好(不是 leetcode 類題目),但是因為其他項目表現不錯於是讓他入取了。報到1個月後發現各個項目真的很茫,於是就還未滿3個月就走了。
那時候我其實在想,會不會以後我自己也會變成他那樣。尤其是在迭代速度如此快的 AI 領域,做一做就變成新鮮人眼中的老人了。
2. 台灣沒有 AI
其實這論述不能說錯,但也絕對不是沒有。至少從近年開始有外商公司將演算法部門設立在台灣來看就知道其實台灣是有 AI 人才,只是靠AI圈錢的公司還是太多。
但我自己認為深根AI技術的公司(例如 kakao brain, deepmind, 阿里達摩學院 這類)在2022年是不存在的。多數還是以商業問題為導向,看什麼行業火熱就發發新聞稿說自己導入AI圈錢/炒股
但反思這個問題的根本其實還有雞生蛋 or 蛋生雞的問題。雞可以看成AI深根,蛋就如人才/資本。如果在台灣AI最厲害人才的都去竹科工作那自然就不會有人在解決,而竹科因為成本競爭與文化因素,一般也不會做得太深入,反而選擇跟著領頭羊做到參數匹配但便宜就好。當然問題背後還有人才流失的問題、學界當RD部門用、市場規模 etc 等等因素。而我只是想吐槽當大家都去竹科,在軟體業的 AI 當然就剩下…
有興趣可以看看這本書《人工智慧在台灣:產業轉型的契機與挑戰》,作者在玉山那段時間的改革蠻有名的
收穫
1. weights(溝通) == weights(實力)
尤其是面對同溫層以外的人,有良好的溝通能力其實和技術實力一樣重要
我在工作第一次跨部門的溝通時就被我上司狠狠打槍,指出我的投影片太難理解。並且要求我退回再製作新的投影片。原因是我太習慣與同領域的朋友溝通,所以很多我習以為然的事務其實對於他們來說很難理解 (例如 F1-score)。
2. 不侷限自己
career think out of the box
因為公司關係有機會與簡立峰進行一對一聊天。過程中他給了我一個職涯建議,那是將自己定位為:能解決問題的工程師。不需要把自己侷限在 ML/AI 的問題上。這裡解決的問題可能是:資源分配問題、演算法問題、程式優化,而不再是只是ML建模而已。
這其實與 Taboola的 Algorithm Engineer理念滿相似的(沒有業配),雖然他們需要 ML 領域的人,但是也要會 DS (如何發掘資料 insight並呈現出來) 、DA (分析資料)。因為它們都是解決問題的一環。
或是如 mosky是一個解決問題的工程師,從backend到線型代數的generalist
3. 軟體業是個海納百川的環境
相較於竹科的公司分工明確,在小公司其實可以遇到很多不同領域/背景的同事。雖然過程中會有不少的摩擦,但是你會看到更多同溫層以外的人,像是我的 team 就有來自森林、應數、統計、金融、管科、新創大神等背景的人。
結語
在台灣大家都覺得AI待遇真的很爛,所以我有機會建立公司的AI基礎(雖然多數還是屬於胡搞瞎搞),作為累積眼界廣度的一種切入點。往好的方面想就是係上的大神都跑去SV或竹科工作了,潛在競爭者都離開這鬼島了。
But, 前提是你要遇到好的老闆
如果你是外籍人士:維持你的英語言能力,文件、筆記能用英文就英文。維持/增進實力以隨時跳槽其他國家的準備
AI 勘誤
AI都是模型套件仔
幾年前可能會看到一堆在酸說 “AI 不就是模型套一套就好了嗎?”。我覺得到了2022年,尤其景氣下滑的背景下,單會 keras 去 fit 模型應該是快混不下去了。我不敢說台灣不會有公司會收你,但如果面試遇到我你會過不了我這關。
至少在我工作上,我就需要寫新的 objective function/loss 去改善問題、調整模型架構讓它能滿足計算資源與預測效能的要求、從0開始解決一個學界沒有的問題(paper 找不到,但是有相似的問題)。與其說 AI 是套件仔,不如說是 paper 實作員

 Cover photo generated by dalle-mini with the prompt : “machine translating 1000 different languages”
Cover photo generated by dalle-mini with the prompt : “machine translating 1000 different languages”
This is a summary of the tricks Google latest paper : Building Machine Translation for Next Thousand Languages
I will split the tricks of this paper into two parts : data cleaning and training.
Data cleaning
Do note that in this section, the term cluster was mentioned in every section, hence I am writing the definition of cluster based on my understanding.
Cluster : For each document you predicts the language of each sentences. We can then group sentences with the same language code into a cluster. The result would be a cluster of possible languages where the dominant language is the document language. The example given from the paper was : if a document had 20 sentences in cluster A, 19 sentences in cluster B, and 18 in cluster C, we gave it a document-level ID of cluster A.
-
Consistency filtering
For each documents, the authors predict document level and sentence level language code. Any sentence which wasn’t aligned with document level predictions are discarded.
-
Percent-threshold wordlist filtering
For each document if there’s less than the 20% most frequent 800 words of the target language ( language decided in consistency filtering ), then this document will be discarded. My guess was this sentence may not be a proper sentence if it doesn’t had any of the most frequent words of the given language (zip-law).
For example this is a proper sentence with common verbs and subject
This is a proper sentence with commonly used verbsNot a very readable sentence
James Holden delightfully hate space -
Semi-Supervised LangID (SSLID) filtering
As pointed by Caswell et al., 2020, language identification in large scale (> 1000 languages) are yet a solved problem. One the proposed method was training a semi supervised langid (language identification) transformer (SSLID) from noisy data obtain from ngram langid.
The author uses SSLID to inference each document. If the predicted language wasn’t inside the document language cluster this document would be discarded. For example : SSLID => spanish, but you only had german, english inside the document.
At this point the text is still noisy as pointed out in the paper : “The worst case was Tok Pisin (tpi), whose dataset consisted of 1.3B sentences, of which over 99.7% were in Standard English (mostly containing the word “long”, which is also a common function word in Tok Pisin)”
-
Outlier detection using TF-IIF
Following the data filtering method by Caswell et al., 2020, this paper employ the same TF-IIF trick to remove any residual noise.
-
Outlier detection using Token-Frequency Anomalousness score
This method was unique to this paper and the approach seems pretty good and should be useful in other domain use.
However, TF-IIF cannot filter out template content ( those repeated content you see in the Youtube video description ). Technically it’s the right language but not very useful for training according to the author. This paper also faces the issue of “unlucky n-gram” (Caswell et al., 2020) effect. Examples of the type of content they found were:
i. Scottish Gaelic (gd) found 570M in-language sentences even after TF-IIF filtering. It turned out that this was mostly from one site, and the most common token was “Luchdaich a-nois” (“download”)
ii. Darija (ar-MA) came up with a dataset of over a billion sentences, but 94.9% contained some reference to “casinos”, “gambling”, etc.
iii. Cree (cr-Latn) was almost 100% “Lorem ipsum” sentences (lol)
(more in the paper section 2.1.8, I will only show the most related ones )
we hypothesized that the token distribution would be severely skewed. Therefore, we compared the distribution of the tokens in the LangID train data (the reference distribution) to the token distribution in the crawled data (the empirical distribution). To compare these distributions we looked at several scores for the top N=40 tokens in the empirical distribution: • 2n-overlap: This is simply the percentage of the top N tokens that appear in the top 2N tokens of the reference distribution; this metric is very simple and highly interpretable. • Euclidean: This is the Euclidean distance between the frequencies of the top N tokens and their corresponding frequencies from the reference distributionThe author then combine the mentioned two scores together with the harmonic mean, yielding the Harmonic Token Anomalousness Score
A low score of < 0.7 signal a low quality dataset while > 0.97 means the document was found in the training data
However, in this process there’s still human in the loop intervention for example
It was relatively straightforward to make filters for 62 of these, for instance excluding sentences containing “casino” in Arabic dialects. For some of the others, we made notes that they were the wrong language. For many others, there was no clear or obvious solution, so we left them as-is.Which is one of the lesson I learned during my time working in the industry : Always look at the data with your eye (trademark).
-
Sentence deduplication
The last step of was sentence deduplication which my guess was they are using some hash function to speed up the process. The final results was almost 2x reduction from the orignal data size (surprisingly not alot).
-
Reduce FNR using aglomerative clustering
Recall rates for related language can be high so they pass them through Hierarchical Agglomera- tive Clustering, using distance_threshold=None and affinity=”precomputed”, and linkage=average. Each cluster should not have more than 20 languages*. This trick doesn’t improve on overall recall but has big improvements in Hindustani and Arabic varieties, and a variety of cases like Oromo (om) and Eastern Oromo (hae).
* I still doesn’t understand why the threshold was choosen to be 20 languages, does it mean they discard these cluster? What language id does this cluster belongs to?
"A sentence was discarded if it had < 20% in-language words for any of the languages in the cluster
Model training
Since we already agree upon the best model architecture was encoder-decoder Transformer, we will just skip this and go right into the training section.
Tricks used during training:
-
MASS pretraining
-
back-translation in the second stage
-
self training in the second stage
I need to dive deeper into what does this actually mean
-
larger is better: use all the sweet A100 VRAM with 6B parameters encoder-decoder transformer
-
distillation into “smaller” model from a 6B model
One interesting note was the distilled model they used was a hybrid model ( Transformer encoder and LSTM decoder ). The paper doesn’t mention whether the decoder uses pointer network or not, but I assume it would help in this instance.
Based on the results, student model yielded a similar performance to the teacher model, showing a powerful encoder (850M parameters) is enough for a good translation model.

-
Period Trick
From the authors observation, they found certain language will fail if period was not added. Simply put without the period symbol, the model will output other language instead of the target ones.
I observe a similar results when I am using byte level tokenizers which missing a punctuation will have drastically different outputs (sometimes the opposite ones ). Although this paper doesn’t state the types of tokenizers they used, I suspect this can be circumvented with random punctuations insert during training?
Conclusion
What I love to read about Facebook research paper was the details they written in paper compared to other org (something with Open and artifical on the name). This was a good engineering problem solved with good data filtering method using statistic analysis and deep learning model as well as model training tricks.
]]>Homophily : 同質偏好,意思是節點相連的點也具有相同的屬性
Heterophily : 異質偏好,點與點之間雖然為鄰居關係,但是屬性差異巨大。例如職場上會特別選擇不同屬性的人合作。
In homo
]]>04/03/2022 Update: Instead of using ext4, you should simply consider other file format such as xfs, zfs, btrfs for high file counts storage
Its normal for a typical research projects to store each data as an individual file under a directory. Although this is not idea, no one seems to question what are the limits of such method.
Ext4
Ext4 is the most commonly used format in linux environment nowadays so we will focus in finding the limit of files under a directory.
According to this stackoverflow answer, ext4 limits is 2^32-1 (inode table maximum size) likely due to compatibility with 32-bit filesystem.
So the answer is 2^32 -1 or 4 billions right?

Introducing Index node aka Inode
However under linux things doesn’t work this way. In order to efficiently access each files, they are stored as index node or we typically call inodes. With this unique index number, we can do symbolic link which points different files to the same inode id. Inode is also where you store the permissions, owner, group settings.
Now the bad news is inodes are limited, but they usually comes with in a very large number. This default value grows proportionally with disk size. For example here’s a list of inodes number I get in my machine using df -i.
| Disk | Storage Size | Inodes Limit | Inodes in used | Storage Usage |
|---|---|---|---|---|
| Samsung 860 | 512G | 30,531,584 | 4,069,444 | 97% |
| WD Blue SSD | 512G | 30,498,816 | 1,029,493 | 93% |
| WD Blue SSD | 1T | 61,054,976 | 9,918,907 | 92% |
| WD Blue HDD | 6T | 183,144,448 | 4,392,142 | 10% |
As you can see filling both of my SSDs almost full with hundreds of millions of files doesn’t even come close to reaching the inode limit.
Unless you are storing billions of very small files ( ~ 1kB) inodes won’t be a problem. If you are the 1% who have such problems, I would recommend you take a look into this thread to create filesystem with larger inode size.
So everything is fine right?
Say hello to hash collision
This is practically CS data structure 101, so I would dwell into what hash collision is.
Since a single directory can potentially hold up to 2^32 files, ext4 also maintains a hash table of size 2^32 to speed up filename search.
This translate to subdirectory limits as well right?
dir_nlink
As mentioned in manpage about ext4
Normally, ext4 allows an inode to have no more than 65,000 hard links. This applies to regular files as well as directories, which means that there can be no more than 64,998 subdirectories in a directory
So no, it doesn’t
Issues with ext4 high inode setup
Although setting to the upper limits of ext4 inode count seems to solve most of other stackoverflow problems, this doesn’t solve mine.
Out of space errors still occur after reaching 15 millions of unique files in the filesystem. Using df -i shows inode counts using only 4% of total inodes. Hence I believe something is still missing which I failed to considered.
I decided to use XFS instead for solving the problem once and for all, since it has built in dynamic inodes structure by sacrificing more storage space ( empty xfs filesystem uses about 15G space in a 8T hard disk ). So far I was able to store all 30M files without hurdles at all.