| CARVIEW |
Playing with models: quantitative exploration of life.
Altruism benefits everyone. At least in transportation models.
The eovlution of cooperation and altruism fascinates me. The difficulty is in explaining how cooperative behavior can stable with respect to being exploited by freeloaders who don’t engage in cooperation but benefit from every one else’s cooperative behavior. It is usually less difficult to demonstrate that in a system in which everyone cooperates, everyone is better off. I will stick to this aspect here. We already saw an example of the benfit of cooperation in the models of highway lane-switching behavior. We learned that, not surprisingly, when everyone adopts the same lane-switching strategy, the flow of traffic decreases compared to the situation when everyone stays in their lane.

This post also explores the value of altruism and cooperation in a different transportation model. We look at a transportation system, inspired by Via, in which rides share vehicles. Although Via recently shut down its ride hailing/sharing app to focus exclusively on the on-demand public transportation projects, it offered a very intersting approach to ride hailing. Via proposed to combine rides like Uber Pool and UberX Share, but in a more dynamic and systematic way, and, most importantly, the service performed pickups and dropoffs only along major roads requiring riders to walk to the pickup point. The efficiencies of shared rides and simplified routing allowed Via to charge singnificantly lower rates than Uber and Lyft.
Asking people to share a vehicle with strangers is a risky proposition. This is likely one of the reasons why Via’s ambitious vision of shared personal rides failed. Moreover, as we are about to see, to achieve a truly efficient transportation system based on shared rides, one must ask even more of the riders. It turns out that when riders are prepared to be altruistic, and be willing to accept an additional delay due to extra rides being pickup or dropped off by the vehicle, the whole system functions more efficiently, especially, when the supply of vehicles is limited and every vehicle fills to capacity most of the time.
WIthout further ado let’s dive into the details of the simulation and the results. In our simulation, rides are routed on a simplified transportation network with nodes and edges. Each edge is characterized by the traversal time which we assume to be fixed. We also assume that intersections (nodes) do not introduce an additional delay. Rides are picked up and dropped off at the nodes and we assume that neither the pickup nor the dropoff introduce additional delays. Each vehicle has the same capacity (number of concurrent rides). The simulation starts by generating ride requests via a Poisson process with a fixed rate. Each ride’s origin and destination nodes are picked at random with the condition that the origin and destination cannot be the same node. The vehicles are placed at random onto the nodes of the network at the beginning of the simulation. When a vehicle is idle (has no current rides and no pickups to perform), it remains stationary at the node where it dropped off the last ride. The ride requests are processed in the order they are introduced and when a new ride is requested, it is matched to a vehicle via the following assignment algorithm.
For each vehicle with an existing order of ride pickups and dropoffs, insert the new ride’s pickup and drop off into all possible places in the current order and compute the total delays of all the rides. The insertions of the new ride’s pickup/dropoff points must satisfy the total vehicle capacity constraint.
At this point an additional constraint can be introduced which we will call the selfish constraint. When the rides are selfish, only the waypoint (pickup and dropoff) orders that don’t increase the current ride delays are allowed. This way neither the pickup delay (the amount of time between the ride request and the pickup time) nor the travel delay (the difference between the shortest route time and the actual route time) can change after the ride has been scheduled. This is probably the way a real world scheduling system has to operate to gain user acceptance.
With the selfish constraint, the new ride request is assigned to a vehicle which minimizes the total delay of the new ride. Without this constraint, the new ride is assigned to the vehicle that minimizes sum of the the additional delays of the existing rides and the delay of the new ride.
In this post we will compare the performance of the scheduling systems with and without the selfish constraint and see that the system in which the users are prepared to accept additional delays after their ride had been scheduled performs significantly better on average especially when it is close to capacity (vehilces are fully loaded most of the time).
However, before we dive into the benefits of altruism, let’s look at the benefits of ride-sharing in general, as well as the benefits of the network effect.
Ride-sharing benefits
The main, not so surprising, result of running the simulation is that additional seats (ride = seat) in each vehicle improve the system throughput almost in proportion to the number of seats. To quantify this we plot the average ride delay (y-axis) measured in the units of the duration of the average ride, versus the scaled system throughput which is defined as the ride rate per vehicle (number of new ride requests per unit time per vehicle) multiplied by the average ride duration. In a system with 100% efficiency (when vehicles never idle and always travel with all seats filled) this scaled throughput is equal to the number of seats in the vehicle.

The delay of 2 means that the average delay is twice the average ride duration (without delay). The benefit of extra seats is apparent. If the quality of service requirement for the system is that the average delay cannot be greater than the average ride duration, without ride sharing the system throughput is about 0.7. Making the second seat available increases the throughput to about 1.15 and adding the third seat to 1.5. While the benefit of each additional seat diminishes, the third seat still offers a substantial throughput increase.
The benefit of network effects
An important parameter that determines how well the system as a whole performs is the vehicle density, or the number of vehicles divided by the number of nodes in the network. The lower the vehicle density, the longer a vehicle needs to travel on average to pickup points. In the limit of very large density, when many rides are queued on every node, a vehicle can usually pick a new ride at the same node it performed a dropoff. To see this quantitatively we examine the delay-throuput chart like the one above for vehicles with the same capacity (3) but systems with different vehicle densities.

The network effect shown in this chart is for vehicles with capacity of 3 clearly demonstrates the benefits of a high density transportation system. For example, if delay must be limited to be below 0.5 to gain user acceptance, the throughput acheived by the transportation system varies by a factor of 2.5 when the vehicle density is increased by a factor of 5. Therefore, not surprisingly, the ride haling transportation systems can operate cost-effectively only above a certain ride density threshold. This threshold depeds on the characteristics of the ride sharing business model.
Benefit of altruism
Up until now we considered what could be called an altruistic ride scheduling approach. When a new ride is added to a vehicle, what’s minimized is the total delay across all rides. This means that the delays of rides already assigned to the vehicle might increase in order to reduce the total delay. In a system like this riders must accept that the delay quoted to them when they request the ride may increase. In the real world, this strategy may not fly. The customers of a ride-sharing system will reasonably expect the delay quoted to them when they accept a ride to be the actual delay at the end of their ride when they are dropped off. Let me be bold and call this ride scheduling appoach “selfish”.

The impact of switching from the “altruistic” to the “selfish” ride scheduling strategy is massive. As we can see on chart to the right of this text, the delay increases by a factor of 3 or more when the system is reasonably loaded (i.e. few vehicles are idle and a substantial fraction of the vehicles is close to capacity). Another way to look at the effect is to note that if the delay of 1 or smaller is acceptable, the system’s throughput increases by 50% when the “altruistic” approach is adopted. Therefore, when everyne accepts that their personal ride delay might increase guarantees that the average delay decreases for everybody.
Conclusions
There are three main takeaways from this simulation excercise:
- Given a road network and a number of vehicles, the average ride delay in steady state diverges at a threshold ride rate. If the ride rate is above this threshold, the system does not reach steady state and the ride delay grows linearly with time. The value of the threshold depends on the road network topology and size, vehicle capacity, and ride scheduling algorithm.
- The vehicle capacity and the vehicle density both greatly increase the overall system throughput.
- The altruistic ride scheduling algorithm whereby riders are prepared to accept additional delays after the ride is scheduled results in a substantial decrease in the average delay.
Published simulation code
The Python code used to perform the ride sharing simulations on a square grid network is available on GitHub at https://github.com/meitiv/ride-sharing-simulation
Size matters
My teenage son who is currently into cars pointed out to me that the grill emblems have been steadily increasing in size as can be readily seen in the side by side comparison the 1992 and 2018 versions of the Honda Accord.


Being a data geek, I immediately wanted to know if there is a rational basis for the design choices car manufacturers seem to be making en masse. I needed data. Sales data was easy to obtain at Car Sales Base. The emblem size was harder to find and I ended up finding photos of cars taken head on and measuring the size of the grill emblem relative to the car width. To keep this undertaking manageable and fun, I focused on three Japanese mid-size cars that compete directly against each other: Toyota Camry, Honda Accord and Nissan Altima. The yearly unit sales and the relative grill logo sizes are plotted in the charts below.

Yearly US unit sales of three mid-size auto models that compete directly against each other. Note the late-2000’s housing bubble recession effect.

The grill emblem size relative to the width of the vehicle vs. the model year.
Its virtually impossible to tell from the plots of the sales and emblem sizes whether there is any association between the two. However, if we plot these data in a different way it becomes apparent. In the plot below, each point represents a pair of car models for a particular year. The x-coordinate of the point is the ratio of the unit sales for that year while the y-coordinate is the ratio of the emblem sizes for that year. If there was a model change that year, I took the average emblem size. The solid line has slope of 0.356 and the P-value of this kind of correlation occurring at random is 0.002

Each symbol represents a pair of car models in a particular year. The x-coordinate of each symbol is the ratio of the number of unit sales in that year and the y-coordinate is the ratio of the relative grill emblem sizes. The solid line is a linear fit.
We found a highly significant, moderate correlation between the emblem size and sales. But as any scientist repeats as a mantra: “correlation is not causation.” For example, a change in the emblem size almost always coincides with the change in the model of the vehicle. It’s impossible to disentangle the effect of the emblem size from the effect of the new model on the sales. At least some of the effect has to be due to the emblem size because it stayed relatively constant over several model changes.
In the end, alas, one would have to gather a richer and larger dataset to say with any certainty whether the emblem size influences sales.
Money plus endorsements equals votes
Montgomery county in Maryland where I live is one of the largest and wealthiest counties in the US. It is, however, not immune to the sense of dissatisfaction with business as usual in the government. Last year, a ballot initiative (which passed by a landslide), introduced and championed by conservatives, limited the number of consecutive terms a council-member could serve. As a result, the nominations for three out of four at-large seats on the county council were up for grabs in this year’s primary. The county council is a 9-person legislative body that makes important county wide decisions, most notably allocating the $5.5 billion budget. That’s a lot of power. It’s therefore not a surprise that this year an unprecedented 33 candidates ran for the 4 at large seats, including my spouse, Danielle Meitiv.
The complete election results can be found on the Maryland Board of Elections website. A cursory look at the results and the several high profile such as Washington Post and the MCEA, apple ballot suggests that these endorsements may have been a key factor determining the outcome of the elections. Being a data scientist, I wanted to go further than a cursory look and a explore the results of a rigorous regression analysis. The dataset for the analysis was constructed by combining data from three different sources.
- The Maryland Board of Elections for the final vote count
- The Seventh State blog for the endorsements
- Maryland Campaign Reporting Information System for the financial information and the number of times a candidate ran before in Montgomery county
The dataset assembled it was straightforward to use R to construct and run linear regression models. A linear model assumes that all factors are independent and their effect on the total number of votes obtained is additive. I started with a model which had all factors in it and proceeded to remove insignificant (P-value < 0.05) factors one at a time rerunning the model after every removal until all factors were significant. The significant influence factors that remained at the end of the factor elimination process are summarized in the table below
| Factor | Votes |
| Baseline | 2,475 votes in absence of other factors |
| Money raised | 47 votes per $1K raised |
| Washington Post | 14,200 votes |
| MCEA | 14,600 votes |
| SEIU500 | 7,340 votes |
| Gender (M/F) | 4,150 for F, 0 for M |
The main conclusion of the analysis is the importance of the Washington Post endorsement and the Apple Ballot. The model seems to suggest that bulk of the votes of the top 7 vote-getters came from these endorsements. Another interesting conclusion is the Male gender liability or Female gender advantage). This much talked about Trump era effect is perhaps less pronounced in the MoCo election than in other races, but nevertheless measurable.
One has to be cautions interpreting the results of simple regression models. The fundamental assumption in computing the significance of factors is the statistical independence of the factor effects. This is, of course, not true. The Washington Post endorsement probably helped with fundraising or vice versa, WaPo endorsed the clear fundraising front-runners. Another thorny issue is causality. Did the endorsements influence the outcome of the elections or did the endorsing organisation simply read the tea leaves better and predicted the winners?
If you would like to run your own models–here is the MoCoCouncilAtLargeVoteData.
Inspections, fines and the honor system

Alexanderplatz U-Bahn station in Berlin
This summer we visited Berlin and enjoyed its excellent public transportation system. Unlike the controlled access system prevalent in the US, Berlin’s (and Prague’s for that matter) system is an honor system. You can buy a ticket at any time and when you board a train or a bus you stamp the ticket with the date and time the trip started. Compliance is enforced by periodic inspections and the fine for riding without a validated ticket (Schwarzfahren) is a modest €60. During our 8 days in Berlin we saw inspectors once and did not get inspected ourselves.
Given the ticket price, is the combination of the fine size and inspection frequency sensible? That is, could BVG (the transit authority) save money by changing the fine amount and/or number of inspectors it has to hire?
To answer this question we must know how people decide whether to buy a ticket or risk being fined. Many factors come into play here. A purely rational and amoral consumer would buy the ticket if the product of the inspection probability and fine amount is larger than the ticket price. This way, not buying tickets costs more in the long run. However, there is a strong national pride and the concept of Beitragen (contributing) which keeps Schwarzfahren low (just a few percent according to this article in German). Being caught without a valid ticket may also result not just in a fine but also in a court summons which presumably has a higher deterrent power.
Let’s explore the effect of the frequency of inspections (and the associated cost) and the fine amount on the total amount of money collected. I will define the single ride ticket cost to be 1 and the fine amount to be 
I will assume for simplicity that the population of transit rides consists of two distinct pools. The conscientious riders always buy the ticket (population size 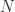
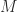




Within our simplistic model, given the fine amount 





it does not make sense to inspect. Another way to look at this equation is that the fine amount has to be at least the cost per inspection divided by the fraction of evaders to justify inspections.
Of course the situation in real life is different. Most people are opportunistic evaders. Each person is characterized by a risk aversion parameter which balances the financial benefit of evasion with the emotional toll of being caught. Because of this fact, some level of inspection is always necessary. The level itself depends on the distribution of the risk aversion parameter in the population and the recovery rate of the fines as a function of the fine amount. But that’s for another post.
Debunking the “Keep the AC on while away” myth
 We all heard the supposedly common wisdom of leaving the AC (or heat) on in the house when away on a trip. This “wisdom” is perpetuated by the HVAC professionals themselves. Well, it’s wrong, at least under the simplifying assumptions below. You will always save energy and money by turning the heat/AC off when you go on a trip, no matter how short.
We all heard the supposedly common wisdom of leaving the AC (or heat) on in the house when away on a trip. This “wisdom” is perpetuated by the HVAC professionals themselves. Well, it’s wrong, at least under the simplifying assumptions below. You will always save energy and money by turning the heat/AC off when you go on a trip, no matter how short.
To quantitatively compute the difference in the money/electricity for the two scenarios: 1) maintain house temperature, and 2) turn the heat/AC off while away we will need to know the cost of either removing or adding the amount of heat 
Let me assume that the house has heat capacity 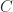




Therefore, under scenario 1 (keep heat/AC on), if the duration of the trip is 


When heat/AC is off, the house temperature will approach the mean outdoor temperature exponentially with the charateristic time scale 

Comparing the two amounts of heat we see that because 

In other words, the amount of heat that must be removed/added from/to the house is always greater when you keep the system on during the trip. Therefore, unless there are counter indications like the pets dying or pipes freezing, it is better to turn the heat/AC off when you travel or at least change the thermostat to a setting that is closer to the outdoor temperature.
The optimal strategy for setting the price of event tickets
 I love tennis and always visit the ATP tournament in DC in August. This year I went with a friend who bought the ticket at the last moment online and discovered that it was deeply discounted (almost 50%). That fact coupled with the observation that the stadium as less than half full got me thinking: are the organizers employing the best ticket price strategy to maximize the receipts?
I love tennis and always visit the ATP tournament in DC in August. This year I went with a friend who bought the ticket at the last moment online and discovered that it was deeply discounted (almost 50%). That fact coupled with the observation that the stadium as less than half full got me thinking: are the organizers employing the best ticket price strategy to maximize the receipts?
To determine the optimal ticket pricing strategy we need to know something about how people make buying decisions. There are a number of different ways of describing this decision making process. Here I will make several simplifying assumptions to make the problem analytically tractable. These assumptions can be relaxed in practice albeit at a cost of having more complex equations.
In the simplest formulation, each person has an internal valuation 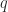

The final ingredient in describing the population of people is the distribution of ticket valuations. If the only information we have about this population is its size 



Let me first consider the case of a fixed ticket price 



Therefore, the expected number of tickets bought is

The gross receipts 

The main conclusion is that when the ticket price is fixed and the event capacity is greater than 
The population of people potentially interested in the event is characterized by three parameters: 1) size
Having explained why partially sold out events could be the outcome of a rational pricing strategy we could call it a day and quit. However, pushing a little further turns out to yield something unexpected.
Let’s relax the assumption of a fixed ticket price. A declining ticket price which starts out quite high makes sense because people with a high ticket valuation will have likely bought a ticket early on and therefore more money can be made by expanding the pool of people who will buy a ticket at a lower price as the time of the event nears.
Let’s consider a linearly declining ticket price which starts high at 

To be clear, the results below are for the case when the event capacity is large enough so that the best strategy is not to sell out. It turns out that when the ticket sale duration
In real life, each person’s ticket valuation is not a constant and can depend on a lot of factors such as how soon the event is, promotions and the number of tickets already sold. A full model which takes all these factors into account would have to be constructed if precise quantitative predictions are to be made.

Gross receipts for two different pricing strategies as a function of the time


When the ticket sale duration 
Money does buy Olympic medals … squared!
 As I was watching the Jamaican sprinters sweep the 200m dash, I started wondering how such a relatively small and not wealthy by any stretch of imagination country could achieve such dominance. Is there a correlation between the population of the country and its haul of medals? Almost certainly. Perhaps a more incendiary and more interesting question is “does money buy medals?” Not in a literal sense, of course, but in a statistical sense. Is there a correlation between the per-capita medal count and per-capita income? There should be. Money buys equipment, coaching and medical staff, transportation, etc.
As I was watching the Jamaican sprinters sweep the 200m dash, I started wondering how such a relatively small and not wealthy by any stretch of imagination country could achieve such dominance. Is there a correlation between the population of the country and its haul of medals? Almost certainly. Perhaps a more incendiary and more interesting question is “does money buy medals?” Not in a literal sense, of course, but in a statistical sense. Is there a correlation between the per-capita medal count and per-capita income? There should be. Money buys equipment, coaching and medical staff, transportation, etc.
As I embarked on this project, I expected to find a significant positive correlation. But what I found was even more shocking. Medal count per person grows as the square of per-capita income. The graph below shows the medal count (obtained from https://www.london2012.com and a Wikipedia article) divided by the population of each country (obtained from Wikipedia) vs. the purchasing parity GDP per capita (obtained from the CIA column of this Wikipedia article). Only populous (>50,000,000) countries are included since statistical trends are more clear in large samples and the fluctuations that obscure these trends are smaller. The straight line is the quadratic fit.
Why does the medal haul grow faster than linearly with the resources? I have an explanation for this striking phenomenon which assumes that each sport has an entrance threshold 



Thus the quadratic dependence of the medal haul on the GDP per capita comes from the fact that richer contries enter more sports and it is easier to win medals in more expensive sports since not as many countries can enter.

Money does buy Olympic medals, Squared! (the green line has slope 2)
Only countries with population greatern than 50 million are included in this plot. Ethiopia is a particularly striking outlier winning more than two orders of magnitude more medals than predicted by the green line.
Immunization in the age of intercontinental travel

Face masks curtail the spread of the virus during the flu pandemic.
The efficacy of a vaccination program is quantified by the fraction of the non-immunized population that gets sick in an epidemic. This fraction can also be thought as the probability that a particular individual will get sick in an epidemic.
A number of factors determine the probability of infection in an epidemic:
How long is the sick person contagious? What is the probability of infection given the contact with a sick person? What is the average rate of inter-personal contacts? How far does a person travel during the sickness? The answers to these questions depend on the type of virus, and the properties of the population such as its density and the patterns of movement.
The situation seems too complex for predictive modeling. Could a simplified model offer meaningful insight? Yes, if we pick a narrow aspect of the problem to look at. How about this? You probably heard the doomsday scenarios of a deadly virus spread around the world aboard airplanes. Is a this kind of talk just fear-mongering or a realistic prediction?
Let us construct a model to study whether the doomsday scenario is plausible. Let’s start with a 2D square lattice, or a board, whose sites (spaces) can be empty of occupied by “people” — let’s call them “entities.” The entities could be in three states: immune, vulnerable, and sick. The sick entities can infect the vulnerable but not the immune ones. We need to decide what to do with the sick entities. For example, some fraction of them can “die”–be removed from the board. The simplest thing is to just let them become immune after the disease has run its course. This is what is done in our model.
The entities can move around the board. The movement models the short range everyday movement of the population: commute, shopping, going to and from school, etc. I will use a turn based (like the Conway’s game of life) set of movement rules that are often used in simulating fluid-vapor interfaces. The result is a collection of dense clusters of varying sizes that float in a sparsely inhabited sea. There is little exchange of entities between the clusters. Since the infection is acquired on contact, global epidemics are impeded by the limited inter-cluster movement. One could think of these semi-isolated clusters as communities, cities, or even continents depending on your perspective.
Below is the movie of the model simulation in which the sick entities (red) infect the vulnerable entities (blue) and after a while become immune (green). A fraction of the population is already immune at the onset of the epidemic. Observe how the disease propagates quickly across the clusters and makes infrequent jumps between the clusters. In this particular simulation, 37% of the vulnerable population got sick before the epidemic fizzled out.
You probably noticed that the immunization rate in the above example is rather low, 30% to be exact. Since most entities are vulnerable, the epidemic has no trouble spreading. When the immunization rate is more than doubled to 70%, most epidemics fizzle out early. As you can see in the PDF (probability density function) plot below of the total epidemic size (defined as the fraction of the vulnerable population that go sick), all epidemics involve fewer than 4% of the populace. There is simply not enough population movement for the disease to spread.

When the movement is local and the immunization rate is high, most epidemics fizzle out without affecting many people.
Time to include airplanes and examine the plausibility of the doomsday scenario!
In addition to the short range movement, let’s allow at each turn a certain small fraction of the population to move anywhere on the board. The second graph below is the PDF of the epidemic size for the same parameters as the one above, but with the additional 5% of the population executing large scale movement each turn. Notice the radical change in the scale of the x axis. When a small fraction of the population travels long distances each turn, most epidemics grow to encompass the majority of the population. The bimodal nature of the epidemic size distribution suggests that there is a threshold size. If the epidemic hits a cluster that happens to be larger than the threshold, the disease can escape and infect almost all other clusters.

When only 5% of the population execute large scale movement every turn, most epidemics grow to affect a significant fraction of the population.
Let us now quantitatively examine the effect of the large scale movements on the probability of significant epidemics. In the graph below I will plot the probability of occurrence of an epidemic that involves > 10% of the vulnerable populace as a function of the immunization rate for two different magnitudes of the large scale movement. Significant epidemics become rare as the immunization rate increases. However, perhaps not surprisingly, greater immunization rate is required to avoid epidemics for a larger magnitude of large scale population movement.

Greater large scale movement requires a higher immunization rate to avoid a significant epidemic
Predicting how epidemics spread in the real world is a tricky business. However, the general conclusion of the simple model, I think, will stand. While 100% immunization rate is not strictly required to stem epidemics, as the extent of long distance travel increases, we will need a higher immunization rate. It would be unwise to be lax about immunization requirements to discover one day that not enough of the population is immunized.
The real issue, I think, is that the small fraction of people who refuse to be immunized are shielded from infection by those who took the risk of immunization (albeit a small risk). But that is a can of worms, I don’t really want to open…
The waiting game.

When two buses can take you where you need to go should you let the slow bus pass and wait for the fast bus?
The Metro has changed the bus schedule this morning with no prior notice whatsoever. The 9 am J1 bus, I usually take, did not come. As I found out later, it was dropped from the schedule altogether. For about 20 minutes I was assuming (with diminishing conviction) that the J1 was merely late. While waiting for the J1, I let two J2’s go by. The J2’s take about 15 minutes longer to reach my destination. While I was waiting, I began to wonder what the best waiting strategy would be if there were two modes of transport with different travel times and different service frequencies. There is a math problem in there with a clear cut answer.
It is simpler to consider the situation in which buses do not have a fixed schedule but arrive at a fixed rate per unit time 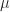

In what follows I will present a few results without much derivation. If you are interested in the nitty-gritty, contact me for details.
Suppose there are two buses A and B that arrive at a stop with rates 


The mean waiting time for bus A provided that A has arrived first is

Now if the travel times to destination on buses A and B are 
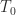

We can interpret this formula as follows. The total bus arrival rate is 





It is a only marginally trickier to derive the mean trip duration (will call it 

The explanation of the second term in the above formula is that if A arrives first, we let it pass and we are back to the “let zero buses pass” strategy. The rest of the terms in the equation for
In general, for any 

We can now start asking questions like: “Under what conditions does letting the slow bus pass make sense (i.e. results in a shorter expected trip)?” What about letting two buses pass? When does that strategy pay off?
When does 

For example, if the slow bus takes 30 minutes and the fast bus takes 20 minutes to arrive at the destination, it makes sense to let the slow bus pass if the fast bus arrives more frequently than once in 10 minutes. No big surprise there, anybody with a modicum of common sense could tell you that.
What is surprising is that the condition (1) does not depend on the arrival rate of the slow bus. Did I make a mistake? It turns out that when 
Therefore, since it does not matter how frequently the slow bus comes, if the fast bus comes frequently enough (condition (1) is satisfied), it makes sense to wait for the fast bus no matter how many slow buses pass.
Speed bested by agility

The rabbit relies on superior maneuverability to escape predators.
The flight behavior of a prey is instinctual and highly sophisticated–after all, predation is a major selective pressure in a Darwinian universe. The variation of escape strategies reflects the intrinsic abilities of the prey. Some prey, like the antelope, rely on superior speed and safety in numbers. Others, like the rabbit, or the squirrel, rely on superior maneuverability. In this post I will illustrate how superior maneuverability can be used to escape from a faster predator.
What is maneuverability? We will define it in a narrow sense as the ability to quickly change the course or direction of motion. The rate of change of the direction of motion is also known as acceleration. The word acceleration is used colloquially when the rate of change of velocity is in the same direction as velocity. More generally, the vector of acceleration could point in any direction. If the acceleration vector points in the direction opposite to velocity, we would say that the moving object decelerates. Circular motion is sustained by a centripetal acceleration which points toward the center of the circle, perpendicular to the velocity vector.
To illustrate how a slower animal can successfully evade a faster one let us consider a simple model of the predator-prey pursuit. Suppose, the only constraint on the motion is the velocity and acceleration caps. The predator’s maximum velocity is greater than that of the prey. Vice versa, the prey can accelerate faster (in any direction) which means, among other things, that it can make sharper turns.
Here are the model pursuit strategies:
Predator:
- If traveling slower than the maximum speed, accelerate in the instantaneous direction of the prey at maximum acceleration.
- When traveling at maximum velocity, project the acceleration vector on the direction perpendicular to the instantaneous velocity. This will insure that speed does not exceed the maximum.
Prey:
- If traveling slower than the maximum speed, accelerate away from the predator at maximum acceleration.
- If traveling at maximum velocity and the predator is a certain distance D away, stay the course.
- If traveling at maximum speed and the predator is within striking distance, execute a turn away from the predator at the tightest turning radius possible.
Even without doing the simulations of this model we can foresee the qualitative features of the trajectories it yields. When the prey is further than D away from the predator, it will run along a straight trajectory which means that the speedier predator will eventually catch up with it and draw within the distance of caution D. At that point the prey will commence a sharp turn away from the predator. The predator, being less agile, will not be able to turn as sharply and will overshoot the prey and the distance between them will grow and might exceed D. When that happens, the prey will stop turning and run along a straight line again. The cycle will repeat ad infinitum the predator not being able to get closer to the prey than some finite fraction of D.
The movie below shows the trajectories of the prey (green) and predator (red) produced by the simple model when the predator is 50% faster, but the prey is able to achieve twice the acceleration.
Finally, let me point out that the strategies in the simple model are far from optimal. For example, one can imagine that if the predator could anticipate the direction of the prey’s turn (which is possible in the above scenario in which the prey always turns away from the predator), it could potentially intercept the prey. The optimality of a particular escape — pursuit strategies is usually hard to prove and the methods of such proofs are still subject of current research.
Search my blog
Subscribe to the blog

Admin
-
Subscribe
Subscribed
Already have a WordPress.com account? Log in now.

leave a comment