| CARVIEW |
🙋 Why?
I don’t have analytics for this blog. I have no idea how many people read it or why they read it. As I care about backwards compatibility, a blog post is the only reliable way to communicate changes to subscribers.
🧑💻 What Changed?
As a result of leaning more into POSSE, on this site I’ve made a few changes:
- Built my own mini Twitter/Bluesky/Mastodon/Threads equivalent called “Thoughts” at
/thoughts - Moved the homepage at
mikemcquaid.comto be all recent Articles, Thoughts, Talks and Interviews. - Added a dedicated
/articlesfor all Articles instead. - Kept the original Atom/RSS feed at
/atom.xmljust for Articles (backwards-compatibility and all that) - Added new dedicated Atom/RSS feeds:
- All Feed (all homepage content, excluding Thoughts)
- Talks Feed
- Interviews Feed
- Thoughts Feed
- Wired these up to POSSE Party and my newsletter to send relevant content elsewhere to my Twitter/Bluesky/Mastodon/Threads/email subscribers.
If you’re interested in the technical side, you can see what I did on GitHub. Given we’re in 2025, yes, I leaned pretty heavily on OpenAI Codex and ChatGPT for a lot of this. In the spirit of “vibe engineering” rather than “vibe coding”, I reviewed and edited all the code by hand.
🫵 What Do You Need To Do?
TL;DR: If you’re subscribed to /atom.xml, nothing changes.
If you want additional content: subscribe to one or more of the new feeds above.
Thanks for reading this blog ❤️. It will be 20 years old in 2026 and it’s nice to see the current blogging resurgence.
]]>The short answer is the project management triangle, commonly summarised as:
Good, fast, cheap. Choose two.
My software version is slightly different. Instead I’d say:
High quality, full scope, delivery date. Choose two.
Let’s break this down:
⭐ High Quality
This is normally the first to get compromised when engineers are pushed to “work faster”. The compromise is often silent because any bugs or declining code quality are not immediately obvious to the consumer. Constant compromise on quality results in bad software that eventually kills software companies.
Of course, the flip side is that some software engineers will endlessly polish code if given the chance. This is why “high quality” has to be the goal, not perfection.
📦 Full Scope
The “scope” of a software project is generally “how many different use cases do we build this for”. For a feature to be everything to everyone: that will take longer.
This can be seen as a “product (manager) decision” instead of a “software (engineer) decision” but it must be a negotiation. There may be things the product manager or customer added to the scope thinking they would take a day but actually take a month. With open, supportive and respectful communication, a lot of scope can often be cut and a lot of time saved.
📅 Delivery Date
Software engineers hate inflexible “deadlines”. This is because there are many hidden complexities of software estimation. Most of the time, though, organisations need to know when they can rely on some software being delivered. This becomes a problem only when there’s no wiggle room on quality or scope.
This is also why engineers pad their estimates. “Estimates” are too often treated as “deadlines”. Padding estimates actually makes a lot of sense in low trust/high stakes environments, or with a lot of uncertainty around the work. Good engineers will use the “extra time”, if they have any, to improve quality or scope.
High quality, full scope, delivery date. Choose two.
Remember and quote this when asked to deliver all three.
The only way to not have two is demanding all three (and usually ending up with one or zero).
Good luck!
]]>Most people overestimate what they can do in one year and underestimate what they can do in ten years.
Bill Gates wrote this in 1996 but it’s been attributed to many others before him.
Build health habits today that lead to a great body in 10 years.
Build social habits today that lead to great relationships in 10 years.
Build learning habits today that lead to great knowledge in 10 years.
Long-term thinking is a secret weapon.
“Aim to be great in 10 years”, James Clear.
I’ve lived in Scotland for 39 years. Most of my education was here; my friends and family are here too.
I’ve been friends with my best friend for 30 years. He comes around to my house weekly to watch sci-fi with me (that my wife would rather not).
I’ve been with my wife for 23 years. We have, in my opinion, a perfect marriage.
I’ve maintained Homebrew for 16 years. It’s still fun and used by millions.
I spent 10 years working for GitHub, from “engineer” to “principal engineer”. I left with lots of knowledge, friends, fun and, frankly, money.
I’ve been powerlifting for 7 years. I’m the “Scottish Masters 1” Champion (out of an admittedly small pool) and continue to improve.
That doesn’t mean sticking with everything.
I quit Christianity after 20 years when it stopped fitting my values.
I quit GitHub after 10 years when I stopped learning.
I used to practice music for hours daily and play in public weekly, but have barely played in years.
I’ve quit jobs, projects and friendships that stopped making me or those around me happy.
Long-term thinking matters, but so does quitting at the right time.
None of the above was easy. There was sadness along the way, as there is for everyone. All of it enriched my life and the lives of the people around me.
None of the above would have happened if I’d been obsessed with finding the perfect option. My choices will not be the right ones for you. I’ve been lucky, have different preferences and needs.
You could decide tomorrow to try one of the above (and you might love it). Good luck finding what your happy long time looks like, wherever you are today. I hope to see you still enjoying it 10 or 20 years from now.
]]>I think it speaks well of the gem.coop maintainers that they brought me on board given I’ve:
- never contributed to RubyGems (or even created my own gem)
- been publicly critical of André’s leadership
- previously tried to act as a neutral mediator between RubyCentral and RubyGems maintainers
Unfortunately, how things went down initially with RubyCentral signalled the need for two things:
- a written, democratic and formal governance process (to provide a clear decision-making framework)
- financial transparency (to provide accountability on where money comes from and goes to)
To help ensure decisions are community-led and finances transparent, gem.coop now has gem.coop/governance and gem.coop’s OpenCollective. I was an administrator on both to bootstrap these structures and have now stepped back.
I had planned to stay involved through the first round of community voting, but given the wider situation I felt it was best to withdraw earlier.
I remain proud of the governance work completed so far. More community-driven governance and financial transparency in open source can only be a good thing.
I wish everyone involved the best in finding a constructive path forward for, and this time with, the wider Ruby community.
]]>I’ve been working with Administrate, the world’s best Training Management System as their CTO for a few months now. When I joined, there was a similar problem: it wasn’t clear how much management was too much or too little, so I wrote an internal document. It has been lightly modified for public consumption and turned into this post.
At companies without a current need for full-time, non-coding engineering management, there is often still a need for some engineers to take on extra leadership responsibilities. It’s a hybrid of what other companies may call “Engineering Manager” and “Staff Engineer”. This role provides “minimum viable engineering management”: just enough to ensure everyone can get their job done.
The responsibilities are:
1️⃣ Regular 1:1s
You should meet each member of your team once every 1-2 weeks in a synchronous face-to-face conversation (e.g. in person, Zoom or Google Meet with cameras on) planned for 30-60 minutes. If you run out of topics to talk about: finish early. If you regularly run long: consider how you’re spending your time and plan an agenda to keep the conversation on topic. 1:1s are the cornerstone of your management.
In 1:1s you should be:
📥 Getting Context
Figure out how the person is doing in their personal life (if they wish to share anything that might affect work) and with the company.
Prompt questions:
- Learn about any potential issues outside work e.g. “How are you doing?” or “Anything I should know about going on outside of work right now?”
- “What’s going well for you at work?”
- “What’s not going so well for you at work?”
You should also gain additional context by reading async standup (Geekbot is a good tool for this) reports for your team.
📤 Providing Context
A manager is responsible for continually ensuring their team members understand what they’re doing, why they’re doing it and what is expected of them.
🎤 Delivering Feedback
1:1s are the best time to deliver non-urgent positive and critical feedback. If it’s urgent or another reason dictates giving feedback outside of 1:1s, that’s fine too; just ensure you keep consistent notes in one place. You need to regularly praise good behaviour and critique poor performance. Do not leave poor performance unaddressed just because it’s awkward to deliver. It will feel worse if you have to deliver bad news, for example about missed promotions or static compensation, due to unaddressed performance issues.
Prompt statements:
- “This week I liked that you…”
- “Last week you did…, what I would have liked to have seen was…”
Deliver positive feedback in public channels (e.g. Slack) and critical feedback privately, in a Slack DM if urgent (e.g. stopping a risky PR being merged) or in a 1:1 if not. You should consider how to deliver the feedback when making this decision. Is this something better done face-to-face, or is it something simple and easy to communicate over text?
🧈 Unblocking
From async standups (e.g. Geekbot), Slack messages and 1:1s, it’s your job as manager to spot when people are blocked and help unblock them. This may involve reviewing PRs, messaging someone on their behalf or assigning new work. Prompt question:
- “Anything you’re blocked on right now?”
📣 Receiving Feedback
1:1s are also a good time to get feedback from your team. Ensuring that feedback delivery is two-way builds trust and two-way accountability.
Prompt question:
- “Do you have any feedback for me based on our interactions this week?”
🏖️ Approving Holidays
As a manager, you’re responsible for approving holidays for your team. You are responsible for ensuring that no more than half the team is out during a normal working week. Ideally, give a week’s notice for a day off, a month for a week off and multiple months for multiple weeks off. No holiday can be for longer than 2 weeks without higher-level approval.
📝 Taking Notes
Everything discussed above should be noted in a permanent written form, for example Google Docs or an AI transcriber/note-taker (reviewed by a human for accuracy). This supports rewarding good performance and addressing poor performance.
🧑🎤 Individual Contribution
The above should take only a minority of your week. You should still have the majority of your time to spend on your own individual engineering contributions. If this is not the case: shout loudly to Mike and he will fix it.
If you’d like to help with similar problems in your organisation through my consulting business, please reach out 💌.
Thanks to Nora McKinnell, Jen Anderson (and ChatGPT5 🤖) for reviewing multiple drafts of this post.
Inspired by this post, I’ve launched a podcast and a GitHub Repository about these topics with Neha Batra, the best manager I’ve ever had in my career.
]]>🍺 Homebrew Contributions
Hi, I’m Mike McQuaid 👋. I’ve spent most of the last 13 years working on Ruby on Rails applications you may have used such as GitHub, AllTrails, Workbrew, and Strap. I’ve maintained Homebrew (mostly written in Ruby) for 16 years and have been the Project Leader since the position was created in 2019. Some of my responsibilities include assessing whether Homebrew maintainers’ contributions make them eligible for:
- retaining commit access and membership in the Homebrew GitHub organisation
- receiving the $300/month maintainer stipend (paid quarterly)
- receiving other payments, e.g. hardware grant, travel expenses to the AGM, lunch with other maintainers
This is partly a matter of security (principle of least privilege), partly a matter of responsible use of our funds and partly a matter of fair recognition, making “Homebrew maintainer” reflect those doing the actual work.
We built a command for this in Homebrew:
brew contributions.
If you’re trying it yourself to replicate these results, it uses the GitHub token from HOMEBREW_GITHUB_API_TOKEN or your keychain.
If I run it on myself for the last year, I get this output:
$ brew contributions --user=mikemcquaid --from=2024-09-24 --organisation=Homebrew --csv
mikemcquaid contributed >=100 times (merged PR author), >=100 times (approved PR reviewer), 1787 times (commit author or committer), 35 times (commit coauthor) and >=2022 times (total) after 2024-09-24.
user,repository,merged_pr_author,approved_pr_review,committer,coauthor,total
mikemcquaid,all,100,100,1787,35,2022
This means that in the last year I:
- authored >=100 merged PRs
- ✅ reviewed >=100 merged PRs
- authored (I created it) or committed (I modified/rebased/committed it) 1,787 commits
- co-authored (someone accepted my GitHub suggestion) 35 commits
Note: the >=100 or >=1000 in the output is to make things quicker and avoid hitting GitHub API rate limits.
This excludes actions like commenting on issues, which don’t require write access. Remember: principle of least privilege.
These are the core metrics that I use to evaluate whether someone is maintaining Homebrew. The tools and data are open. Also, because we use OpenCollective, the money coming into and out of Homebrew is open.
💎 RubyGems Contributions
Ok Mike, that’s a lot about Homebrew: what about RubyGems? Sorry, I’m getting to that.
Homebrew has open tooling to analyse GitHub contributions. RubyGems has a GitHub organisation. Let’s combine the two.
First, who are the owners, maintainers, contributors and members of the RubyGems organisation?
It’s not an easy question to answer, so I’ve built a list based on the people who either participated or were CCd by indirect on the
Proposal for RubyGems Organizational Governance.
I’ve also included the current members of the RubyGems organisation
Let’s look at contributions for the year preceding the removals:
$ brew contributions --csv --from 2024-08-18 --org=rubygems --user=aellispierce,amatsuda,andremedeiros,arthurnn,arunagw,bai,bronzdoc,colby-swandale,deivid-rodriguez,djberg96,drbrain,duckinator,dwradcliffe,ecnelises,evanphx,farukaydin,hsbt,indirect,jenshenny,ktheory,landongrindheim,lauragift21,luislavena,martinemde,mensfeld,mghaught,olleolleolle,qrush,segiddins,sferik,simi,skottler,sonalkr132
...
| User | Merged PRs | Approved PRs | Commits | Total |
|---|---|---|---|---|
| deivid-rodriguez | 100 | 13 | 1303 | 1416 |
| hsbt | 57 | 3 | 379 | 439 |
| simi | 36 | 100 | 254 | 390 |
| segiddins | 93 | 77 | 194 | 364 |
| colby-swandale | 45 | 55 | 77 | 177 |
| martinemde | 49 | 59 | 64 | 172 |
| landongrindheim | 48 | 55 | 54 | 157 |
| lauragift21 | 14 | 4 | 32 | 50 |
| duckinator | 12 | 0 | 36 | 48 |
| olleolleolle | 2 | 18 | 7 | 27 |
| mghaught | 7 | 8 | 12 | 27 |
| indirect | 1 | 7 | 3 | 11 |
| qrush | 0 | 1 | 1 | 2 |
| mensfeld | 0 | 1 | 0 | 1 |
| ktheory | 0 | 0 | 0 | 0 |
| luislavena | 0 | 0 | 0 | 0 |
| sferik | 0 | 0 | 0 | 0 |
| skottler | 0 | 0 | 0 | 0 |
| sonalkr132 | 0 | 0 | 0 | 0 |
| jenshenny | 0 | 0 | 0 | 0 |
| farukaydin | 0 | 0 | 0 | 0 |
| evanphx | 0 | 0 | 0 | 0 |
| ecnelises | 0 | 0 | 0 | 0 |
| dwradcliffe | 0 | 0 | 0 | 0 |
| drbrain | 0 | 0 | 0 | 0 |
| djberg96 | 0 | 0 | 0 | 0 |
| bronzdoc | 0 | 0 | 0 | 0 |
| bai | 0 | 0 | 0 | 0 |
| arunagw | 0 | 0 | 0 | 0 |
| arthurnn | 0 | 0 | 0 | 0 |
| andremedeiros | 0 | 0 | 0 | 0 |
| amatsuda | 0 | 0 | 0 | 0 |
| aellispierce | 0 | 0 | 0 | 0 |
Full brew contributions Output
$ brew contributions --csv --from 2024-08-18 --org=rubygems --user=aellispierce,amatsuda,andremedeiros,arthurnn,arunagw,bai,bronzdoc,colby-swandale,deivid-rodriguez,djberg96,drbrain,duckinator,dwradcliffe,ecnelises,evanphx,farukaydin,hsbt,indirect,jenshenny,ktheory,landongrindheim,lauragift21,luislavena,martinemde,mensfeld,mghaught,olleolleolle,qrush,segiddins,sferik,simi,skottler,sonalkr132 aellispierce contributed 0 times (total) after 2024-08-18. amatsuda contributed 0 times (total) after 2024-08-18. andremedeiros contributed 0 times (total) after 2024-08-18. arthurnn contributed 0 times (total) after 2024-08-18. arunagw contributed 0 times (total) after 2024-08-18. bai contributed 0 times (total) after 2024-08-18. bronzdoc contributed 0 times (total) after 2024-08-18. colby-swandale contributed 45 times (merged PR author), 55 times (approved PR reviewer), 77 times (commit author or committer) and 177 times (total) after 2024-08-18. deivid-rodriguez contributed >=100 times (merged PR author), 13 times (approved PR reviewer), 1303 times (commit author or committer) and >=1416 times (total) after 2024-08-18. djberg96 contributed 0 times (total) after 2024-08-18. drbrain contributed 0 times (total) after 2024-08-18. duckinator contributed 12 times (merged PR author), 36 times (commit author or committer) and 48 times (total) after 2024-08-18. dwradcliffe contributed 0 times (total) after 2024-08-18. ecnelises contributed 0 times (total) after 2024-08-18. evanphx contributed 0 times (total) after 2024-08-18. farukaydin contributed 0 times (total) after 2024-08-18. hsbt contributed 57 times (merged PR author), 3 times (approved PR reviewer), 379 times (commit author or committer) and 439 times (total) after 2024-08-18. indirect contributed 1 time (merged PR author), 7 times (approved PR reviewer), 3 times (commit author or committer) and 11 times (total) after 2024-08-18. jenshenny contributed 0 times (total) after 2024-08-18. ktheory contributed 0 times (total) after 2024-08-18. landongrindheim contributed 48 times (merged PR author), 55 times (approved PR reviewer), 54 times (commit author or committer) and 157 times (total) after 2024-08-18. lauragift21 contributed 14 times (merged PR author), 4 times (approved PR reviewer), 32 times (commit author or committer) and 50 times (total) after 2024-08-18. luislavena contributed 0 times (total) after 2024-08-18. martinemde contributed 49 times (merged PR author), 59 times (approved PR reviewer), 64 times (commit author or committer) and 172 times (total) after 2024-08-18. mensfeld contributed 1 time (approved PR reviewer) and 1 time (total) after 2024-08-18. mghaught contributed 7 times (merged PR author), 8 times (approved PR reviewer), 12 times (commit author or committer) and 27 times (total) after 2024-08-18. olleolleolle contributed 2 times (merged PR author), 18 times (approved PR reviewer), 7 times (commit author or committer) and 27 times (total) after 2024-08-18. qrush contributed 1 time (approved PR reviewer), 1 time (commit author or committer) and 2 times (total) after 2024-08-18. segiddins contributed 93 times (merged PR author), 77 times (approved PR reviewer), 194 times (commit author or committer) and 364 times (total) after 2024-08-18. sferik contributed 0 times (total) after 2024-08-18. simi contributed 36 times (merged PR author), >=100 times (approved PR reviewer), 254 times (commit author or committer) and >=390 times (total) after 2024-08-18. skottler contributed 0 times (total) after 2024-08-18. sonalkr132 contributed 0 times (total) after 2024-08-18. user,repository,merged_pr_author,approved_pr_review,committer,coauthor,total deivid-rodriguez,all,100,13,1303,0,1416 hsbt,all,57,3,379,0,439 simi,all,36,100,254,0,390 segiddins,all,93,77,194,0,364 colby-swandale,all,45,55,77,0,177 martinemde,all,49,59,64,0,172 landongrindheim,all,48,55,54,0,157 lauragift21,all,14,4,32,0,50 duckinator,all,12,0,36,0,48 olleolleolle,all,2,18,7,0,27 mghaught,all,7,8,12,0,27 indirect,all,1,7,3,0,11 qrush,all,0,1,1,0,2 mensfeld,all,0,1,0,0,1 ktheory,all,0,0,0,0,0 luislavena,all,0,0,0,0,0 sferik,all,0,0,0,0,0 skottler,all,0,0,0,0,0 sonalkr132,all,0,0,0,0,0 jenshenny,all,0,0,0,0,0 farukaydin,all,0,0,0,0,0 evanphx,all,0,0,0,0,0 ecnelises,all,0,0,0,0,0 dwradcliffe,all,0,0,0,0,0 drbrain,all,0,0,0,0,0 djberg96,all,0,0,0,0,0 bronzdoc,all,0,0,0,0,0 bai,all,0,0,0,0,0 arunagw,all,0,0,0,0,0 arthurnn,all,0,0,0,0,0 andremedeiros,all,0,0,0,0,0 amatsuda,all,0,0,0,0,0 aellispierce,all,0,0,0,0,0
The month preceding the removals:
$ brew contributions --csv --from 2025-08-18 --org=rubygems --user=aellispierce,amatsuda,andremedeiros,arthurnn,arunagw,bai,bronzdoc,colby-swandale,deivid-rodriguez,djberg96,drbrain,duckinator,
...
| User | Merged PRs | Approved PRs | Commits | Total |
|---|---|---|---|---|
| deivid-rodriguez | 22 | 0 | 99 | 121 |
| landongrindheim | 7 | 27 | 10 | 44 |
| hsbt | 5 | 0 | 31 | 36 |
| simi | 2 | 8 | 17 | 27 |
| colby-swandale | 4 | 5 | 6 | 15 |
| martinemde | 1 | 2 | 6 | 9 |
| segiddins | 0 | 4 | 2 | 6 |
| lauragift21 | 1 | 0 | 2 | 3 |
| duckinator | 1 | 0 | 1 | 2 |
| olleolleolle | 0 | 0 | 1 | 1 |
| mghaught | 0 | 0 | 1 | 1 |
| jenshenny | 0 | 0 | 0 | 0 |
| ktheory | 0 | 0 | 0 | 0 |
| luislavena | 0 | 0 | 0 | 0 |
| mensfeld | 0 | 0 | 0 | 0 |
| qrush | 0 | 0 | 0 | 0 |
| sferik | 0 | 0 | 0 | 0 |
| skottler | 0 | 0 | 0 | 0 |
| sonalkr132 | 0 | 0 | 0 | 0 |
| indirect | 0 | 0 | 0 | 0 |
| farukaydin | 0 | 0 | 0 | 0 |
| evanphx | 0 | 0 | 0 | 0 |
| ecnelises | 0 | 0 | 0 | 0 |
| dwradcliffe | 0 | 0 | 0 | 0 |
| drbrain | 0 | 0 | 0 | 0 |
| djberg96 | 0 | 0 | 0 | 0 |
| bronzdoc | 0 | 0 | 0 | 0 |
| bai | 0 | 0 | 0 | 0 |
| arunagw | 0 | 0 | 0 | 0 |
| arthurnn | 0 | 0 | 0 | 0 |
| andremedeiros | 0 | 0 | 0 | 0 |
| amatsuda | 0 | 0 | 0 | 0 |
| aellispierce | 0 | 0 | 0 | 0 |
Full brew contributions Output
$ brew contributions --csv --from 2025-08-18 --org=rubygems --user=aellispierce,amatsuda,andremedeiros,arthurnn,arunagw,bai,bronzdoc,colby-swandale,deivid-rodriguez,djberg96,drbrain,duckinator,dwradcliffe,ecnelises,evanphx,farukaydin,hsbt,indirect,jenshenny,ktheory,landongrindheim,lauragift21,luislavena,martinemde,mensfeld,mghaught,olleolleolle,qrush,segiddins,sferik,simi,skottler,sonalkr132 aellispierce contributed 0 times (total) after 2025-08-18. amatsuda contributed 0 times (total) after 2025-08-18. andremedeiros contributed 0 times (total) after 2025-08-18. arthurnn contributed 0 times (total) after 2025-08-18. arunagw contributed 0 times (total) after 2025-08-18. bai contributed 0 times (total) after 2025-08-18. bronzdoc contributed 0 times (total) after 2025-08-18. colby-swandale contributed 4 times (merged PR author), 5 times (approved PR reviewer), 6 times (commit author or committer) and 15 times (total) after 2025-08-18. deivid-rodriguez contributed 22 times (merged PR author), 99 times (commit author or committer) and 121 times (total) after 2025-08-18. djberg96 contributed 0 times (total) after 2025-08-18. drbrain contributed 0 times (total) after 2025-08-18. duckinator contributed 1 time (merged PR author), 1 time (commit author or committer) and 2 times (total) after 2025-08-18. dwradcliffe contributed 0 times (total) after 2025-08-18. ecnelises contributed 0 times (total) after 2025-08-18. evanphx contributed 0 times (total) after 2025-08-18. farukaydin contributed 0 times (total) after 2025-08-18. hsbt contributed 5 times (merged PR author), 31 times (commit author or committer) and 36 times (total) after 2025-08-18. indirect contributed 0 times (total) after 2025-08-18. jenshenny contributed 0 times (total) after 2025-08-18. ktheory contributed 0 times (total) after 2025-08-18. landongrindheim contributed 7 times (merged PR author), 27 times (approved PR reviewer), 10 times (commit author or committer) and 44 times (total) after 2025-08-18. lauragift21 contributed 1 time (merged PR author), 2 times (commit author or committer) and 3 times (total) after 2025-08-18. luislavena contributed 0 times (total) after 2025-08-18. martinemde contributed 1 time (merged PR author), 2 times (approved PR reviewer), 6 times (commit author or committer) and 9 times (total) after 2025-08-18. mensfeld contributed 0 times (total) after 2025-08-18. mghaught contributed 1 time (commit author or committer) and 1 time (total) after 2025-08-18. olleolleolle contributed 1 time (commit author or committer) and 1 time (total) after 2025-08-18. qrush contributed 0 times (total) after 2025-08-18. segiddins contributed 4 times (approved PR reviewer), 2 times (commit author or committer) and 6 times (total) after 2025-08-18. sferik contributed 0 times (total) after 2025-08-18. simi contributed 2 times (merged PR author), 8 times (approved PR reviewer), 17 times (commit author or committer) and 27 times (total) after 2025-08-18. skottler contributed 0 times (total) after 2025-08-18. sonalkr132 contributed 0 times (total) after 2025-08-18. user,repository,merged_pr_author,approved_pr_review,committer,coauthor,total deivid-rodriguez,all,22,0,99,0,121 landongrindheim,all,7,27,10,0,44 hsbt,all,5,0,31,0,36 simi,all,2,8,17,0,27 colby-swandale,all,4,5,6,0,15 martinemde,all,1,2,6,0,9 segiddins,all,0,4,2,0,6 lauragift21,all,1,0,2,0,3 duckinator,all,1,0,1,0,2 olleolleolle,all,0,0,1,0,1 mghaught,all,0,0,1,0,1 jenshenny,all,0,0,0,0,0 ktheory,all,0,0,0,0,0 luislavena,all,0,0,0,0,0 mensfeld,all,0,0,0,0,0 qrush,all,0,0,0,0,0 sferik,all,0,0,0,0,0 skottler,all,0,0,0,0,0 sonalkr132,all,0,0,0,0,0 indirect,all,0,0,0,0,0 farukaydin,all,0,0,0,0,0 evanphx,all,0,0,0,0,0 ecnelises,all,0,0,0,0,0 dwradcliffe,all,0,0,0,0,0 drbrain,all,0,0,0,0,0 djberg96,all,0,0,0,0,0 bronzdoc,all,0,0,0,0,0 bai,all,0,0,0,0,0 arunagw,all,0,0,0,0,0 arthurnn,all,0,0,0,0,0 andremedeiros,all,0,0,0,0,0 amatsuda,all,0,0,0,0,0 aellispierce,all,0,0,0,0,0
Added on request of Nate Berkopec: all the contributors to rubygems/rubygems in the last ~1.5 years for the same timescales as above:
$ brew contributions --csv --from 2024-08-18 --org=rubygems --user=deivid-rodriguez,hsbt,segiddins,martinemde,simi,duckinator,nobu,tangrufus,Edouard-chin,voxik,soda92,technicalpickles,jenshenny,jeromedalbert,ccutrer,nevinera,indirect,tenderlove,Maumagnaguagno,MSP-Greg,ntkme,mame,byroot,composerinteralia,flavorjones,johnnyshields,olleolleolle,jeremyevans,amatsuda,ko1,junaruga,kddnewton,koic,rhenium,larskanis,ntl,matsadler
...
| User | Merged PRs | Approved PRs | Commits | Total |
|---|---|---|---|---|
| deivid-rodriguez | 100 | 13 | 1303 | 1416 |
| hsbt | 58 | 4 | 392 | 454 |
| simi | 37 | 100 | 255 | 392 |
| segiddins | 93 | 77 | 194 | 364 |
| martinemde | 49 | 59 | 64 | 172 |
| duckinator | 12 | 0 | 36 | 48 |
| olleolleolle | 2 | 18 | 7 | 27 |
| Edouard-chin | 7 | 0 | 20 | 27 |
| soda92 | 10 | 0 | 16 | 26 |
| tangrufus | 2 | 0 | 21 | 23 |
| jeromedalbert | 6 | 0 | 7 | 13 |
| tenderlove | 6 | 0 | 6 | 12 |
| nobu | 2 | 0 | 9 | 11 |
| indirect | 1 | 7 | 3 | 11 |
| technicalpickles | 2 | 0 | 6 | 8 |
| composerinteralia | 2 | 0 | 2 | 4 |
| MSP-Greg | 2 | 0 | 2 | 4 |
| jeremyevans | 1 | 0 | 1 | 2 |
| johnnyshields | 1 | 0 | 1 | 2 |
| rhenium | 1 | 0 | 1 | 2 |
| mame | 1 | 0 | 1 | 2 |
| ntkme | 1 | 0 | 1 | 2 |
| larskanis | 1 | 0 | 1 | 2 |
| ntl | 1 | 0 | 1 | 2 |
| ccutrer | 1 | 0 | 1 | 2 |
| voxik | 1 | 0 | 1 | 2 |
| koic | 0 | 0 | 0 | 0 |
| matsadler | 0 | 0 | 0 | 0 |
| kddnewton | 0 | 0 | 0 | 0 |
| junaruga | 0 | 0 | 0 | 0 |
| ko1 | 0 | 0 | 0 | 0 |
| amatsuda | 0 | 0 | 0 | 0 |
| flavorjones | 0 | 0 | 0 | 0 |
| byroot | 0 | 0 | 0 | 0 |
| Maumagnaguagno | 0 | 0 | 0 | 0 |
| nevinera | 0 | 0 | 0 | 0 |
| jenshenny | 0 | 0 | 0 | 0 |
Full brew contributions Output
$ brew contributions --csv --from 2024-08-18 --org=rubygems --user=deivid-rodriguez,hsbt,segiddins,martinemde,simi,duckinator,nobu,tangrufus,Edouard-chin,voxik,soda92,technicalpickles,jenshenny,jeromedalbert,ccutrer,nevinera,indirect,tenderlove,Maumagnaguagno,MSP-Greg,ntkme,mame,byroot,composerinteralia,flavorjones,johnnyshields,olleolleolle,jeremyevans,amatsuda,ko1,junaruga,kddnewton,koic,rhenium,larskanis,ntl,matsadler deivid-rodriguez contributed >=100 times (merged PR author), 13 times (approved PR reviewer), 1303 times (commit author or committer) and >=1416 times (total) after 2024-08-18. hsbt contributed 58 times (merged PR author), 4 times (approved PR reviewer), 392 times (commit author or committer) and 454 times (total) after 2024-08-18. segiddins contributed 93 times (merged PR author), 77 times (approved PR reviewer), 194 times (commit author or committer) and 364 times (total) after 2024-08-18. martinemde contributed 49 times (merged PR author), 59 times (approved PR reviewer), 64 times (commit author or committer) and 172 times (total) after 2024-08-18. simi contributed 37 times (merged PR author), >=100 times (approved PR reviewer), 255 times (commit author or committer) and >=392 times (total) after 2024-08-18. duckinator contributed 12 times (merged PR author), 36 times (commit author or committer) and 48 times (total) after 2024-08-18. nobu contributed 2 times (merged PR author), 9 times (commit author or committer) and 11 times (total) after 2024-08-18. tangrufus contributed 2 times (merged PR author), 21 times (commit author or committer) and 23 times (total) after 2024-08-18. Edouard-chin contributed 7 times (merged PR author), 20 times (commit author or committer) and 27 times (total) after 2024-08-18. voxik contributed 1 time (merged PR author), 1 time (commit author or committer) and 2 times (total) after 2024-08-18. soda92 contributed 10 times (merged PR author), 16 times (commit author or committer) and 26 times (total) after 2024-08-18. technicalpickles contributed 2 times (merged PR author), 6 times (commit author or committer) and 8 times (total) after 2024-08-18. jenshenny contributed 0 times (total) after 2024-08-18. jeromedalbert contributed 6 times (merged PR author), 7 times (commit author or committer) and 13 times (total) after 2024-08-18. ccutrer contributed 1 time (merged PR author), 1 time (commit author or committer) and 2 times (total) after 2024-08-18. nevinera contributed 0 times (total) after 2024-08-18. indirect contributed 1 time (merged PR author), 7 times (approved PR reviewer), 3 times (commit author or committer) and 11 times (total) after 2024-08-18. tenderlove contributed 6 times (merged PR author), 6 times (commit author or committer) and 12 times (total) after 2024-08-18. Maumagnaguagno contributed 0 times (total) after 2024-08-18. MSP-Greg contributed 2 times (merged PR author), 2 times (commit author or committer) and 4 times (total) after 2024-08-18. ntkme contributed 1 time (merged PR author), 1 time (commit author or committer) and 2 times (total) after 2024-08-18. mame contributed 1 time (merged PR author), 1 time (commit author or committer) and 2 times (total) after 2024-08-18. byroot contributed 0 times (total) after 2024-08-18. composerinteralia contributed 2 times (merged PR author), 2 times (commit author or committer) and 4 times (total) after 2024-08-18. flavorjones contributed 0 times (total) after 2024-08-18. johnnyshields contributed 1 time (merged PR author), 1 time (commit author or committer) and 2 times (total) after 2024-08-18. olleolleolle contributed 2 times (merged PR author), 18 times (approved PR reviewer), 7 times (commit author or committer) and 27 times (total) after 2024-08-18. jeremyevans contributed 1 time (merged PR author), 1 time (commit author or committer) and 2 times (total) after 2024-08-18. amatsuda contributed 0 times (total) after 2024-08-18. ko1 contributed 0 times (total) after 2024-08-18. junaruga contributed 0 times (total) after 2024-08-18. kddnewton contributed 0 times (total) after 2024-08-18. koic contributed 0 times (total) after 2024-08-18. rhenium contributed 1 time (merged PR author), 1 time (commit author or committer) and 2 times (total) after 2024-08-18. larskanis contributed 1 time (merged PR author), 1 time (commit author or committer) and 2 times (total) after 2024-08-18. ntl contributed 1 time (merged PR author), 1 time (commit author or committer) and 2 times (total) after 2024-08-18. matsadler contributed 0 times (total) after 2024-08-18. user,repository,merged_pr_author,approved_pr_review,committer,coauthor,total deivid-rodriguez,all,100,13,1303,0,1416 hsbt,all,58,4,392,0,454 simi,all,37,100,255,0,392 segiddins,all,93,77,194,0,364 martinemde,all,49,59,64,0,172 duckinator,all,12,0,36,0,48 olleolleolle,all,2,18,7,0,27 Edouard-chin,all,7,0,20,0,27 soda92,all,10,0,16,0,26 tangrufus,all,2,0,21,0,23 jeromedalbert,all,6,0,7,0,13 tenderlove,all,6,0,6,0,12 nobu,all,2,0,9,0,11 indirect,all,1,7,3,0,11 technicalpickles,all,2,0,6,0,8 composerinteralia,all,2,0,2,0,4 MSP-Greg,all,2,0,2,0,4 jeremyevans,all,1,0,1,0,2 johnnyshields,all,1,0,1,0,2 rhenium,all,1,0,1,0,2 mame,all,1,0,1,0,2 ntkme,all,1,0,1,0,2 larskanis,all,1,0,1,0,2 ntl,all,1,0,1,0,2 ccutrer,all,1,0,1,0,2 voxik,all,1,0,1,0,2 koic,all,0,0,0,0,0 matsadler,all,0,0,0,0,0 kddnewton,all,0,0,0,0,0 junaruga,all,0,0,0,0,0 ko1,all,0,0,0,0,0 amatsuda,all,0,0,0,0,0 flavorjones,all,0,0,0,0,0 byroot,all,0,0,0,0,0 Maumagnaguagno,all,0,0,0,0,0 nevinera,all,0,0,0,0,0 jenshenny,all,0,0,0,0,0
I’m not going to make any value judgements about these data. Remember that open source maintainers owe you nothing.
My only observation is that, if I were deciding based on the principle of least privilege for access control in the Homebrew organisation, based only on this data and our process, there would be people in all the groups of:
- appear they should have been removed, were removed
- appear they should have been removed, were not removed
- appear they should not have been removed, were removed
- appear they should not have been removed, were not removed
As Homebrew’s Governance has been cited as a good basis, I “stress tested” it here. I wanted to contribute data to a conversation that currently lacks it. That’s not to say who should or shouldn’t be in the RubyGems or any other GitHub organisation.
I wish we had data like Homebrew’s OpenCollective budget to similarly analyse finances, but it doesn’t seem to be public.
This situation also highlights how funding and transparency can shape open source dynamics. I’ve long believed that money is not the solution to every problem in open source. In some cases, it can create problems that wouldn’t exist otherwise.
]]>
🎨 Background
I’ve been in open source for 20 years and in tech professionally since 2007. My primary languages evolved from Java to C++ to Ruby, with production work in many others along the way. Across the years and these various ecosystems, I’ve seen many different ways of building software. Some ecosystems lean heavily into static checking, types and linting. Others rely on high levels of test coverage, pairing or microservices. While these approaches seem disparate, at various times, each has been championed as “The One True Path” to perfect software.
Modern LLMs, however, are perhaps the first technological shift in my entire career that truly feels likely to change everything.
🐣 Early LLMs
My first experience with LLMs was reviewing an early, internal alpha of GitHub Copilot for VS Code. At GitHub, I was often tapped for such reviews, largely due to my dual role as an active open-source maintainer and an internal feature contributor. Probably most importantly, though: even when it was politically inadvisable to say something was total shit: I would give that feedback were it the case.
I was very quickly and pleasantly surprised by GitHub Copilot. When I used Eclipse for writing Java in the ~2005-7 era, it was joked that you could “Ctrl-Space your code into existence”. Given the hellish amount of boilerplate Java required in those days, that was much appreciated. Copilot finally offered that same magic for Ruby: a decent autocompletion engine, something I hadn’t found across many Ruby IDEs or plugins. It immediately felt like it was saving me a bunch of typing and reminding me of APIs that I had forgotten.
The obvious downside of this early Copilot and ChatGPT 3 era was the regularity and sometimes subtlety of its hallucinations. If you carefully reviewed everything it spat out, this wasn’t a big problem. I still found it to be faster than doing things entirely manually and missed Copilot in environments where I couldn’t use it. At this stage, ChatGPT felt more like a toy; I didn’t trust its output over Google, and it couldn’t provide (non-hallucinated) citations for verification.
Digging In
By the time ChatGPT 4 was rolling out, I was still a regular GitHub Copilot in VSCode user but had been mostly ignoring other AI developments. I’m always keen to stay up-to-date and started hearing more engineers I respected finding value in these tools. I decided to dive in: paying for ChatGPT, trying (and then paying for) Cursor, and defaulting to ChatGPT over Google.
Fast forward to 2025: paid-tier LLM hallucination rates are dramatically lower. Genuinely useful agents are emerging, and I can now leverage citations to “trust but verify” LLM output effectively. I now rarely use Google, defaulting to ChatGPT, especially for deep dives into niche technical topics.
🧐 Philosophy
There’s a wide array in the degree of trust people give to LLMs. Some argue that any possibility of hallucination renders them unworthy of attention. Others “vibe-code” entire applications without reviewing any of the generated code.
The analogy that has resonated with me comes from open source: the “first time contributor”. It’s fairly common on a project like Homebrew that you’ll get a non-trivial pull request from someone you’ve never seen on the project before. This contributor might have no prior open-source activity, no GitHub bio, or even an avatar. How do you assess the trustworthiness of such a person’s pull request? By thoroughly reading, discussing, linting, and testing the code as required.
LLM code (or, to a lesser extent, prose) output is similar. It might be absolutely perfect the first time. It might be irredeemably terrible or wrong. The only way to find out is to review the output.
Open-source maintainers, especially on projects like Homebrew, have honed the skill of rapidly reviewing large volumes of unfamiliar or newly contributed code. This skill is useful, perhaps even essential, for effectively leveraging LLM output. I suspect at least some of the loud LLM skeptics are actually just very poor at code review and have no interest or desire to get better. AI code review tools (e.g. Copilot, CodeRabbit) are good companions to human code reviewers, particularly for pedantry, but not replacements.
Similar to managing open-source contributions, a few strategies can optimise both human and LLM-generated work.
First, consider giving up when it’s clear the amount of back-and-forth is actually slower than you just manually doing it yourself.
Second, heavily leverage linting, testing, and other automated tooling to establish robust guardrails.
With LLM agents, you can even instruct them to self-verify their output by executing relevant commands or tests.
For example, when working on Homebrew, I’ll ask agents to run brew style (for RuboCop code linting), brew typecheck (for static type checking) and brew tests (for unit tests) to automatically verify behaviour.
📵 LLM Modes
Based on these learnings, I’ve developed a few distinct “LLM modes” in my workflow:
- Constantly: I’m writing code, my editor of choice (Cursor, today) is just providing a nice autocomplete and quick, inline lookup for stuff I’ve forgotten.
- Regularly: I’m blocked and would normally be Googling or looking at Stack Overflow for a solution. Instead, I’ll now ask the LLM in my editor or ChatGPT for a solution or ideas. This excels at rapidly deciphering confusing error messages or sifting through large log dumps to pinpoint the source of issues.
- Rarely: I get the LLM to generate a large amount of boring and fairly trivial code based on a lot of initial research I’ve done.
An example would be in the MCP Server for Homebrew where I got Cursor to generate a first pass for a couple of methods.
I then edited this extensively and made it look and work how I wanted through manual edits and LLM refactoring.
After this, I used it to similarly generate most of the first versions of the unit tests to hit decent code coverage.
Throughout this process, I maintain frequent local
gitcommits, enabling me to usegit difffor careful review of each generated change. - Rarest: I haven’t decided how I want something to work yet, so I get LLM to generate all of the code, don’t even look at the code and repeatedly change prompts based on the generated UI or CLI output. Once the functionality is achieved, I then step away, and the following day, conduct a thorough line-by-line review and editing pass. This was similar to the writing workflow I took when writing Git in Practice where I’d write until I hit a page count without reading things back and then do an edit pass the next day. Similarly to writing, there’s limit as to how much code you can effectively review like this so you need to avoid things ballooning out of control.
I would say I do 1) hourly, 2) daily, 3) weekly and 4) monthly at this point. This pattern emerged from a continuous assessment of what maximises my personal and team productivity, balancing rapid development while minimising bugs for users.
🪩 Reflection
I’ve found LLM tooling like Cursor and ChatGPT to be an essential part of my workflow. Depending on the task, I’d say they provide anywhere between a 1% to 100% speedup. For me, ChatGPT has replaced 99% of my prior Google usage.
I’m genuinely curious to see what the future holds for LLMs. I suspect with AI hype, we’re seeing a certain amount of the Gell-Mann amnesia effect i.e. people find AI the most impressive when performing tasks they are the least familiar with. Similarly, as much as people talk about “exponential progress” with AI and imminent AGI (whatever that means today), it’s feeling more like asymptotic progress on the underlying technology. I expect the remaining large user-facing improvements of this generation of AI to be primarily be around UI and UX. The belief that we’ll “any day now” achieve deterministic results from fundamentally stochastic systems seems to stem from either a technological misunderstanding or wishful thinking.
All that said, I’d rather hire someone today who overuses LLM tooling over someone who refuses to use any. Ultimately, as technologists in a for-profit company within a capitalist economy, we are hired to generate business value. LLM tools allow businesses to do more (features, tests, automation, etc.) with less (employees, hours, budget). Lean into that. The LLMs aren’t going to take your software job, but they will let you be better at it.
Many promising engineers end up descending into masturbatory levels of obsession with how code looks rather than how value is generated. Ultimately, the business may decide it wants a shitty, vibe-coded app tomorrow rather than your perfect code in 6 months. Yes, ChatGPT may generate “junior engineer”-level code, but it’s also a wee bit cheaper than any junior engineer I’ve found.
The optimal path in 2025 is to embrace LLM tools, balancing pragmatic optimism with healthy skepticism regarding dramatic claims from either side. Build your app with guardrails to protect both human and AIs from stupid mistakes.
Let’s build some cool shit (and faster than we could in 2020). I’ve helped companies dramatically boost developer velocity and PR throughput (e.g. by 40%) through smart automation and AI integration. If you’re looking to optimise your team’s workflow in the LLM era, email me and let’s talk.
Thanks to Luke Hefson, Justin Searls, Gemini 2.5 Flash and ChatGPT o3 (I also tried but didn’t like the feedback from ChatGPT 4.5, ChatGPT 4o and Claude Sonnet 4) for reviewing drafts of this post.
]]>🎨 Background
I had designed the initial engineering hiring process at Mendeley and interviewed the first ~5 engineers there. At GitHub, I was involved in screening, interviewing and tweaking hiring processes for around ~50 engineers. Through these processes, and being interviewed myself ~15 times for engineering jobs over the years, I had a pretty good idea of what I loved and hated.
What I’d loved:
-
💕 Pairing on real code. Shout-out to AllTrails for my first interview where we actually paired together on a real bug in the Rails codebase I’d be working on. Felt the best representation of my actual skills in an interview setting, nerves aside.
-
🩳 Short, predictable interview processes. At Mendeley, as first employee, I went from having never heard of them to being interviewed and accepting an offer in a week. Huge companies can’t do this. Startups can (if they can be bothered). No-one wants to wait three months to find out if they got the job.
-
🔓 Valuing my open-source contributions. I’ve maintained a very widely used open-source project when interviewing for my last 3 gigs. If you think I’ve done a good job doing this, it’s appreciated when your interview process reflects this.
What I’d hated:
-
📚 Factual recall or gotcha questions. Don’t ask me anything I can trivially get the answer from Google or ChatGPT. It’s a waste of everyone’s time for me to just memorise a bunch of facts for your interview. If you have to look up the answers to your own interview questions for a job you’re not in the process of being fired from: you’re doing it wrong. Even if I don’t know today: I can probably learn it on the job. Relatedly, requiring specific technology experience for senior+ engineers
-
📟 Not considering relevant prior experience. Moving back from marketing to engineering in GitHub I was put through the external senior engineer interview loop. I failed. This was after shipping the “archive repository” feature while still in the marketing organisation (almost) single-handedly. A few months later, I was moved over anyway to work on GitHub Sponsors. One year later, I was a staff engineer. Three years later, I was a principal engineer.
-
🙋 Assuming one-way interview. I’ve had several interviews who clearly took pleasure in seeing people squirm when jumping through hoops. They assumed, sometimes rightly, that they could treat people how they liked as they have enough applicants for it to not matter. Interviews are always two-way. If you are exploiting the power dynamic in the interview process: it’s a pretty good sign you’ll be a shitty person to work for or with.
So, given all this, how did we decide to do it at Workbrew?
🎭 Stages
We split the interview process into a few stages. If you passed one: you moved onto the next one as soon as possible (usually within a few days). If you failed one: I let you know as soon as possible (ideally the same day).
For each stage when we’re evaluating the candidate, we have a numeric rubric for each question or criteria. This helps avoid biases where you “love” a candidate but, objectively, they scored lower than another.
Here’s the breakdown of our hiring stages:
-
✍️ Writing the job posting. I spent a pretty decent amount of time and got a bunch of feedback to ensure it conveys our values at Workbrew. We slimmed “requirements” down to the bare minimum (i.e. no-one would get a job who didn’t 100% meet every one). We kept the “nice-to-haves” minimal but indicative of what would differentiate a good from great candidate. Rather than implicit (“unlimited holiday/vacation”) we tried to be explicit (“less than 20 days is too few, more than 40 is too many”). We decided to share it in various semi-public locations (e.g. various networks we’re part of) rather than get a million applications from the entire public internet. We also directly reached out to some people who seemed like they’d be a good fit and were already in our network
-
💌 Application. We asked people to send in their CV/resume so we could do an initial screen to ensure they met requirements. For example, if we said we wanted 10 years industry experience and you were still in high school then: sorry, it’s a pass. I did all this myself because we’re a small company and I wanted to ensure I got it right first before I eventually delegate/outsource it. We also asked people to clarify that the salary range in the job posting worked for them. This helped ensure alignment between experience, expectations and our budget. At this stage as a company, we’re careful about balancing expectations with experience. This also provides a screening process for people who link out to their social media on e.g. their CV and it’s full of them being unkind to others. If your linked social media openly showcases behaviour clearly misaligned with our values: it’ll be a pass.
-
📺 Technical Screening Questions. Next, we asked people to reply to the email with answers to a few technical screening questions. Could people just feed these into ChatGPT and get some half-decent answers out? Yup. While ChatGPT might produce passable answers, genuinely excellent, nuanced answers stand out immediately. If you’re skilled enough to leverage AI to produce that kind of clarity: good for you (more to follow on that in another post).
-
🍐 Live Pairing Interview. Riffing off my favourite experience at AllTrails, we did a live pairing interview. Because we’re remote-first: it was done over Zoom. I get it: no-one loves live technical interviews/pairing so we factor in nervousness. To avoid unfairness, I screen-shared my environment and let them connect remotely with Zoom and/or VS Code. This enabled us to work together on the same real problem in our actual codebase. Everyone worked on the same problem and had the same amount of time for a fair comparison. This was “open book”; it was fine to use Google, ChatGPT, Copilot, Cursor, etc. I’m fine with AI tool usage as long as it’s disclosed. Some folks asked to skip this stage in favour of a take-home interview. We’re not willing to do that; there’s just too much cheating that happens with this now and it’s more fair to compare all candidates in the same environment.
-
🧫 Cultural Cofounders Interview. We’re a small and new company but we identified strong, shared cultural values early on. If someone strongly prefers to never travel to meet coworkers in person, that’s not a good cultural fit with us. To ensure all three founders were aligned: we all interview every candidate. This ensures that we’re actively excited about each new person who joins and sets everyone up for success. It also allows the candidate to ask different (or the same) questions to different founders and get different perspectives.
-
💸 Offer. We move to making offers ASAP. There might be further discussion and salary/equity/etc. We make clear that the higher the compensation: the higher the expectations. Ultimately, what value you bring is evaluated against how much you cost the company. If maximising salary is your primary goal, you’re very early career and/or in a particularly expensive city: it’s a mutually poor fit for our current state.
-
🛬 Onboarding. Despite working remotely for 16 years, I still find face-to-face working tremendously valuable. As a result, in the first week, we fly the new employee over to co-work with me in Edinburgh, Scotland. This helps with engineering and product onboarding and setting 7/30/90 day expectations. Most importantly, though, it helps us both get to know each other a bit better. It means when we read some text in Slack, we hear the human side. If we’re hiring more than one person around the same time: we build a “cohort” and onboard them together. This means they can get to know each other, too.
⏭️ Exceptions
The above sounds great (and has been) but: sometimes there are exceptions. We’ve hired people without going through every step of the process because I’ve worked with them on Homebrew for years and have extensively reviewed much of their code. For this situation, putting them through a live coding exercise is pointless.
🪩 Reflections
Reflecting on the process so far, I’m really happy with the outcomes. We’ve hired universally excellent candidates so far which makes me delighted with our process. In fact, we’ve had more excellent candidates than we’ve had headcount/budget to hire them.
Doing this process (almost) entirely by myself is tiring but worthwhile. I’ve never had such a high level of confidence in people before we’ve hired them.
We’ve seen particularly good results from hiring from shared employer backgrounds. 2 of our engineers were hired from Homebrew. 2 of our engineers (and our EM/PM hybrid and all 3 founders) had previously worked at GitHub. 1 was a (paid) referral from a respected Scottish founder.
Surprisingly, we’re yet to hire a “cold inbound” engineering hire. Several of these folks reached the pairing and cultural interviews and did well but everyone we ended up hiring did incredibly. This has indicated to me that, at least when we’re small, leaning on our networks is incredibly valuable and time-efficient. It also helps a lot with “cultural onboarding” to have shared context.
]]>Leaving GitHub

GitHub was a good ride. I got my dream of working for a “Big Tech” US tech company through an acquisition while working entirely remotely from Scotland. When we were acquired by Microsoft in 2018 I predicted to my wife that at some point the bureaucracy would be so stifling that I’d quit. To Microsoft’s credit, this took 4.5 years, much longer than I would have predicted.
When I joined GitHub as employee #232, it was already the second-largest company I’d ever worked for. No longer having Neha Batra, the best manager I’ve ever had in my career, as my manager was the straw that broke the camel’s back. When I’d mentioned this was part of my reasoning for leaving, I was told it could be fixed instantly but: that’s not really how I roll. I’d also previously told myself if I get to 10 years with any employer: I should quit to avoid stagnation, even if I loved it.
I still enjoyed it but: I no longer loved it. It just took too long to get anything meaningful done any more and I’m primarily motivated by making developers more productive, not meeting OKRs while achieving the opposite. The money was good but, at least for me, feeling like you’re actually having individual impact has to take priority.
Raise.dev
The startup I joined as a CTO and cofounder on March 1st 2023 was named “Raise.dev”. It had been started in 2019 by John Britton, my friend and former manager at GitHub. In 2021 Vanessa Gennarelli, another friend and former teammate joined him there. I almost joined him in February 2020 but my youngest child’s refusal to sleep and the prospect of a staff engineer promotion changed my mind.

John, the classy guy that he is, didn’t do a “hard sell” for me to join him at Raise.dev. If anything, it was the opposite. He introduced me to various other founders and actively encouraged me to interview elsewhere and think about it. He also said he was looking for a cofounder rather than an employee; something that was initially intimidating for me.
A person who helped swing it for me was Brian Corcoran, friend and lynchpin of the Scottish tech scene. I described my various options I was weighing up and he said “oh, so you’re cofounding the startup then?”. When I said I hadn’t decided, he told me that it was obviously the option I was most excited about.
ESP32s

When I joined John and Vanessa, they had done a bunch of market research and figured out that there was an opening for developer tools in the IoT space. In true startup style, for my first week John flew over to Edinburgh and stayed in my guest room while we figured out what we were going to build. We zoomed in on shipping something for ESP32s that would enable a GitHub-like deployment flow.
~12 weeks later, we had it in the hands of some potential users. Things did not go well: the onboarding proved punishing and not always successful. The rough edges were things that we did not have control over (e.g. GitHub Actions, C++).
When we next met up as a three to discuss what features to build next: I proposed we pivot. I didn’t know what to, just that what we were doing didn’t seem to match our strengths.
John had been trying to convince me for literally about 10 years at this point to make “a Homebrew startup”. If you haven’t heard of it, Homebrew is an open-source package manager I’ve been working on since 2009. He (and others) had intro’d me to VCs several times and I’d always gone “where’s the business here, though?” and declined to take it any further. It also felt, in that era of open-source, that most “open-source startups” were a bait-and-switch where a free, liberally licensed project was inevitably yanked away from the community for “commercial reasons” later. I wanted no part in helping someone make a quick buck out of the Homebrew community I’d worked so hard to cultivate.
John said: “well, if we’re going to play to our strengths: that’s the Homebrew startup”. I left the meeting, had dinner with my kids and thought: shit. He’s right. We couldn’t play more to our strengths than this. Homebrew now has solid finances and governance, meaning it’s resilient against negative disruption from any organisation. John, Vanessa and I all have most of our background in developer tools and open source. It just made sense.
Of course, minutes into the next meeting discussing it, John comes up with the perfect name: “Workbrew”.
Workbrew
A major advantage of being open-source was having more than a decade’s worth of public requests from large companies that Homebrew decided not to build. Many of these people were told “no” by me. Apparently I’m good at that.
With a bit of digging, the main things that jumped out were:
- Homebrew’s inability to play nicely with MDM tools
- A need to restrict access to Homebrew packages that violate compliance or regulatory requirements
- Security concerns around Homebrew’s filesystem permissions model
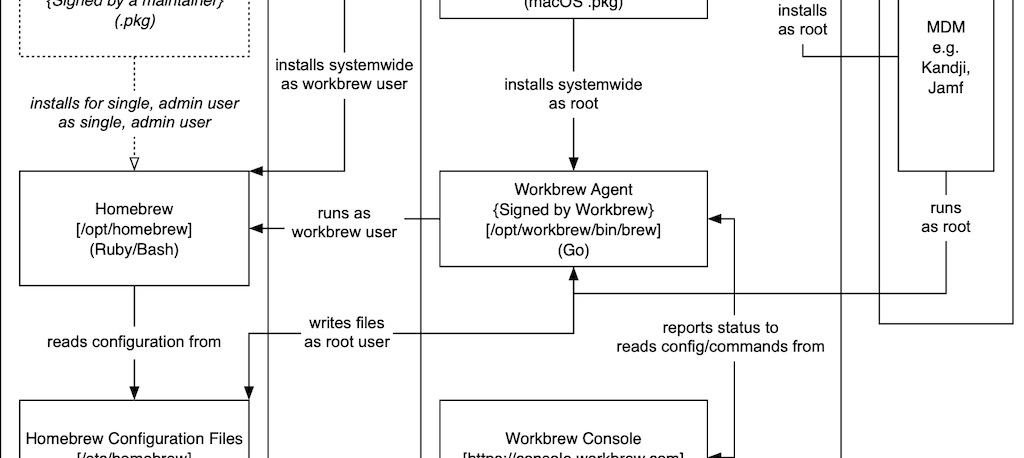
I realised fairly quickly this would necessitate the:
- Workbrew Installer: install Homebrew and Workbrew, play nicely with MDMs (written in macOS
.pkgand Bash) - Workbrew Agent: send state/receive commands to Console, provide security-enhanced wrapper for Homebrew (written in Go)
- Workbrew Console: used by administrators to send commands/receive state from devices (written in Ruby on (Guard)Rails)
I built the basic architecture solo, dogfooded it with myself, John and Vanessa and showed it to some people. This would make the open-source Homebrew project better and allow us to build an independent commercial product, Workbrew, to handle enterprise needs that Homebrew wouldn’t or couldn’t. We got a better response than I anticipated. I guess it was time to go raise some funding.
VCs
Raise.dev already had some money in the bank from an existing round that was sustaining the three of us. With Workbrew gaining momentum, we knew it was time to raise more funding to grow the team.

The TL;DR is we spoke to many VCs, I learned to be less Scottish in terms of both self-deprecation and swearing and raised a round. In true remote-first fashion, we got our first offer before the three of us had even been in the same room together as cofounders. HeavyBit were our lead investor and have proved to be a great partner and source of wisdom for us. They were (pleasantly) starting to badger me to go and hire a team so: it was time.
Hiring
I left GitHub as a “Principal Engineer”: lots of technical mentoring, but no formal management or hiring responsibilities.

I’ve written a longer post on exactly what my interview process was but, suffice to say, it worked out pretty well. We’ve got an incredible, world-class remote-first team with strong cultural alignment. Today, ~63% of us are ex-GitHub employees. Only the cofounders came directly from there. Our shipping velocity is absurdly fast (with guardrails). We help each other, we improve each other and we prioritise kindness and empathy. We work mainly async together across 7 countries and 3 continents. I love it.
Customer Feedback
So far, we have managed to get a decent number of happy, paying customers. Customer feedback is a beautiful and valuable thing. We’re following our tweaked versions of a few great existing processes:
- Shape Up for 6 week “sprints” on feature work, 2 week “cooldowns” for less structured work
- the “First Responder” pattern for managing engineering support escalations and other unplanned work
- shipping “minimum loveable products” of our features with the goal of getting something useful out to customers ASAP and iterate based on their feedback
In the words of Level:
We’re happy to have integrated Workbrew into our stack. We also wanted to mention that the Workbrew team has been very responsive to even the silliest of questions and it’s been a real delight conversing with them.
The Future

Things are going well and everything is trending in the right direction. We’re working with our sales and GTM folks to delight existing and new customers.
Reflections
I’d read a lot about cofounding a company before doing it. I swore I’d never do it. Whoops. The only thing I knew for sure was that I didn’t want to do this alone (and I’m glad I didn’t). John and Vanessa and I all love, help, praise, improve and irritate each other in equal measure. It’s an incredibly intense relationship and experience. Vaguely similarly to being a parent: the highs are higher and the lows are lower than I expected. I’ve never felt like I’ve been growing more and faster than I am now, though. It’s incredibly motivating to be learning so much and building a company of people who love being here.
Advice
I feel like I have almost zero actual advice to give other founders but I feel obligated to try some:
- Starting a company requires ignoring just the right amount of conventional wisdom. Not all of it, definitely not none of it.
- You’ll get lots of (unsolicited) advice from lots of people. Listen to all of it. A broken clock is right twice a day. Ignore most of it, particularly strong opinions from those who’ve never been near a startup.
- Play to your strengths. It might be that you, as a CTO, are ok at management but still very productive with coding. Stopping all coding and fixating on management, even if wiser minds nudge you in that direction, seems like a mistake with that in mind. “Minimum viable management” is helpful. Zero management is not.
Thanks for reading!
]]>- Homebrew (2009-present): created 2009, I started working on it ~5 months in and was maintainer #3.
- AllTrails (2012-2013): created 2010, I was employee ~#8 and worked on their (smallish) Ruby on Rails application for ~1.5 years.
- GitHub (2013-2023): created 2007, I was employee ~#232 and worked on their (huge) Ruby on Rails application for ~10 years.
- Workbrew (2023-present): I cofounded Workbrew in 2023 and built the Workbrew Console Ruby on Rails application from scratch.
Over all of these Ruby codebases, there’s been a consistent theme:
- Ruby is great for moving fast
- Ruby is great for breaking things
What do I mean by “breaking things”?
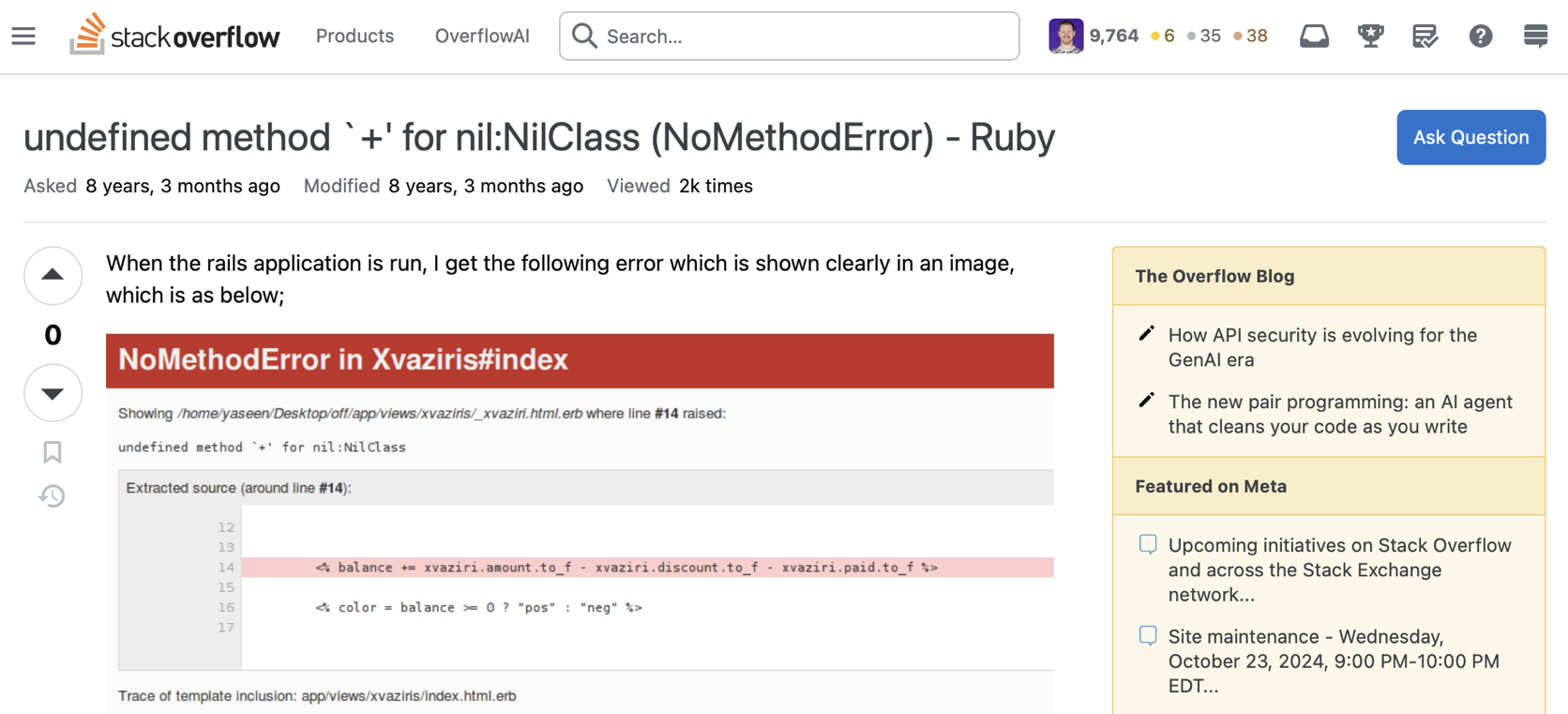
If you’ve been a Ruby developer for any non-trivial amount of time, you’ve lost a non-trivial amount of your soul through the number of times you’ve seen this error. If you’ve worked with a reasonably strict compiled language (e.g. Go, Rust, C++, etc.) this sort of issue would be caught by the compiler and never make it into production. The Ruby interpreter, however, makes it very hard to actually catch these errors at runtime (so they often do make it into production).
This is when, of course, you’ll jump in with “well, of course you just need to…” but: chill, we’ll get to that. I’m setting the scene for:
🤨 The Solution
The solution to these problems is simple, just …
Actually, no, the solution is never simple and, like almost anything in engineering: it depends entirely on what you’re optimising for.
What I’m optimising for (in descending priority):
- 👩💻 developer happiness: well, this is why we’re using Ruby. Ruby is optimised for developer happiness and productivity. There’s a reason many Ruby developers love it and have stuck with it even when it is no longer “cool”. Also, we need to keep developers happy because otherwise they’ll all quit and I’ll have to do it all myself. That said, there’s more we can do here (and I’ll get to that).
- 🕺 customer/user happiness: they don’t care about Ruby or developers being happy. They care about having software that works. This means software where bugs are caught by the developers (or their tools) and not by customers/users. This means bugs that are found by customers/users are fixed quickly.
- 🚄 velocity/quality balance: this is hard. It requires accepting that, to ship fast, there will be bugs. Attempting to ship with zero bugs means shipping incredibly slowly (or not at all). Prioritising only velocity means sloppy hacks, lots of customer/user bugs and quickly ramping up tech debt.
- 🤖 robot pedantry, human empathy: check out the post on this topic. TL;DR: you want to try to automate everything that doesn’t benefit from the human touch.
The Specifics
Ok, enough about principles, what about specifics?
👮♀️ linters
I define “linters” as anything that’s going to help catch issues in either local development or automated test environments. They are good at screaming at you so humans don’t have to.
- 👮♀️
rubocop: the best Ruby linter. I generally try to enable as much as possible in Rubocop and disable rules locally when necessary. - 🪴
erb_lint: like Rubocop, but for ERB. Helps keep your view templates a bit more consistent. - 💐
better_html: helps keep your HTML a bit more consistent through development-time checks. - 🖖
prosopite: avoids N+1 queries in development and test environments. - 🪪
licensed: ensures that all of your dependencies are licensed correctly. - 🤖
actionlint: ensures that your GitHub Actions workflows are correct. - 📇
eslint: when you inevitably have to write some JavaScript: lint that too.
I add these linters to my Gemfile with something like this:
group :development do
gem "better_html"
gem "erb_lint"
gem "licensed"
gem "rubocop-capybara"
gem "rubocop-performance"
gem "rubocop-rails"
gem "rubocop-rspec"
gem "rubocop-rspec_rails"
end
If you want to enable/disable more Rubocop rules, remember to do something like this:
require:
- rubocop-performance
- rubocop-rails
- rubocop-rspec
- rubocop-rspec_rails
- rubocop-capybara
AllCops:
TargetRubyVersion: 3.3
ActiveSupportExtensionsEnabled: true
NewCops: enable
EnabledByDefault: true
Layout:
Exclude:
- "db/migrate/*.rb"
Note, this will almost certainly enable things you don’t want.
That’s fine, disable them manually.
Here you can see we’ve disabled all Layout cops on database migrations (as they are generated by Rails).
My approach for using linters in Homebrew/Workbrew/the parts of GitHub where I had enough influence was:
- enable all linters/rules
- adjust the linter/rule configuration to better match the existing code style
- disable rules that you fundamentally disagree with
- use safe autocorrects to get everything consistent with minimal/zero review
- use unsafe autocorrects and manual corrections to fix up the rest with careful review and testing
When disabling linters, consider doing so on a per-line basis when possible:
# Bulk create BrewCommandRuns for each Device.
# Since there are no callbacks or validations on
# BrewCommandRun, we can safely use insert_all!
#
# rubocop:disable Rails/SkipsModelValidations
BrewCommandRun.insert_all!(new_brew_command_runs)
# rubocop:enable Rails/SkipsModelValidations
I also always recommend a comment explaining why you’re disabling the linter in this particular case.
🧪 tests
I define “tests” as anything that requires the developer to actually write additional, non-production code to catch problems. In my opinion, you want as few of these as you can to maximally exercise your codebase.
- 🧪
rspec: the Ruby testing framework used by most Ruby projects I’ve worked on. Minitest is fine, too. - 🙈
simplecov: the standard Ruby code coverage tool. Integrates with other tools (like CodeCov) and allows you to enforce code coverage. - 🎭
playwright: dramatically better than Selenium for Rails system tests with JavaScript. If you haven’t already read Justin Searls’ post explaining why you should use Playwright: go do so now. - 📼
vcr: record and replay HTTP requests. Nicer than mocking because they test actual requests. Nicer than calling out to external services because they are less flaky and work offline. - 🪂
parallel_tests: run your tests in parallel. You’ll almost certainly get a huge speed-up on your multi-core local development machine. - 📐 CodeCov: integrates with SimpleCov and allows you to enforce and view code coverage. Particularly nice to have it e.g. comment inline on PRs with code that wasn’t covered.
- 🤖 GitHub Actions: run your tests and any other automation for (mostly) free on GitHub.
I love it because I always try to test and automate as much as possible.
Check out Homebrew’s
sponsors-maintainers-man-completions.ymlfor an example of a complex GitHub Actions workflow that opens pull requests to updates files. Here’s a recent automated pull request updating GitHub Sponsors in Homebrew’sREADME.md.
I add these tests to my Gemfile with something like this:
group :test do
gem "capybara-playwright-driver"
gem "parallel_tests"
gem "rspec-github"
gem "rspec-rails"
gem "rspec-sorbet"
gem "simplecov"
gem "simplecov-cobertura"
gem "vcr"
end
In Workbrew, running our tests looks like this:
$ bin/parallel_rspec
Using recorded test runtime
10 processes for 80 specs, ~ 8 specs per process
....................................................................
....................................................................
....................................................................
....................................................................
....................................................................
....................................................................
....................................................................
......................
Coverage report generated to /Users/mike/Workbrew/console/coverage.
Line Coverage: 100.0% (6371 / 6371)
Branch Coverage: 89.6% (1240 / 1384)
Took 15 seconds
I’m sure it’ll get slower over time but: it’s nice and fast just now and it’s at 100% line coverage.
There has been (and will continue to be) many arguments over line coverage and what you should aim for. I don’t really care enough to get involved in this argument but I will state that working on a codebase with (required) 100% line coverage is magical. It forces you to write tests that actually cover the code. It forces you to remove dead code (either that’s no longer used or cannot actually be reached by a user). It encourages you to lean into a type system (more on that, later).
🖥️ monitoring
I define “monitoring” as anything that’s going to help catch issues in production environments.
- 💂♀️ Sentry (or your error/performance monitoring tool of choice): catches errors and performance issues in production.
- 🪡 Logtail (or your logging tool of choice): logs everything to an easily queryable location for analysis and debugging.
- 🥞 Better Stack (or your alerting/monitoring/on-call tool of choice): alerts you, waking you up if needed, when things are broken.
I’m less passionate about these specific tools than others. They are all paid products with free tiers. It doesn’t really matter which ones you use, as long as you’re using something.
I add this monitoring to my Gemfile with something like this:
group :production do
gem "sentry-rails"
gem "logtail-rails"
end
🍧 types
Well, in Ruby, this means “pick a type system”. My type system of choice is Sorbet. I’ve used this at GitHub, Homebrew and Workbrew and it works great for all cases. Note that it was incrementally adopted on both Homebrew and GitHub.
I add Sorbet to my Gemfile with something like this:
gem "sorbet-runtime"
group :development do
gem "rubocop-sorbet"
gem "sorbet"
gem "tapioca"
end
group :test do
gem "rspec-sorbet"
end
A Rails view component using Sorbet in strict mode might look like this:
class AvatarComponent < ViewComponent::Base
sig { params(user: User).void }
def initialize(user:)
super
@user = user
end
sig { returns(User) }
attr_reader :user
sig { returns(String) }
def src
if user.github_id.present?
"https://avatars.githubusercontent.com/u/#{user.github_id}"
else
...
end
end
In this case, we don’t need to check the types or nil of user because we know from Sorbet it will always be a non-nil User.
This means, at both runtime and whenever we run bin/srb tc (done in the VSCode extension and in GitHub Actions), we’ll catch any type issues.
These are fatal in development/test environments.
In the production environment, they are non-fatal but reported to Sentry.
Note: Sorbet will take a bit of getting used to.
To get the full benefits, you’ll need to change the way that you write Ruby and “lean into the type system”.
This means preferring e.g. raising exceptions over raising nil (or similar) and using T.nilable types.
It may also include not using certain Ruby/Rails methods/features or adjusting your typical code style.
You may hate it for this at first (I and many others did) but: stick with it.
It’s worth it for the sheer number of errors that you’ll never encounter in production again.
It’ll also make it easier for you to write fewer tests.
TL;DR: if you use Sorbet in this way: you will essentially never see another nil:NilClass (NoMethodError) error in production again.
That said, if you’re on a single-developer, non-critical project, have been writing for a really long time and would rather die than change how you do so: don’t use Sorbet.
😌 Ad Hominem
Well, I hear you cry, “that’s very easy for you to say, you’re working on a greenfield project with no legacy code”. Yes, that’s true, it does make things easier.
That said, I also worked on large, legacy codebases like GitHub and Homebrew that, when I started, were doing very few of these things and now are doing many of them. I can’t take credit for most of that but I can promise you that adopting these things was easier than you would expect. Most of these tools are built with incrementalism in mind.
Perfect is the enemy of good. Better linting/testing/monitoring and/or types in a single file is better than none.
🤥 Cheating
You may feel like the above sounds overwhelming and oppressive. It’s not. Cheating is fine. Set yourself strict guardrails and then cheat all you want to comply with them. You’ll still end up with dramatically better code and it’ll make you, your team and your customers/users happier. The key to success is knowing when to break your own rules. Just don’t tell the robots that.
]]>Perhaps surprisingly: I don’t actually give the tiniest shit whether he was ignorant, malicious or a “good person” and: you shouldn’t either.
Imagine you have two radically different coworkers: Bob and Alice.
- Bob’s daily ritual includes a heartfelt plea to himself: “Today I’m going to try so hard and, for once, make sure everything goes well and that I don’t upset anyone!”. Alas, Bob, as usual, fucks it all up. He starts the day strong, bringing the team doughnuts. It’s all downhill from there, though: he breaks the CI build, offends several teammates, baptises his boss with hot coffee and orchestrates a massive colossal system outage affecting all paying customers. He apologises profusely but everyone knows: he’ll do it all again tomorrow.
- Alice starts her day with a sigh: “Work is hard right now and I can’t really be bothered but: gotta pay the bills somehow.”. Alice, as usual, has a sensational day. She completes her project weeks ahead of the deadlines, spends an hour helping the new hire open their first PR, saves the day on Bob’s site outage and fixes his broken CI build. At lunchtime, though, she’s tired so listens to a podcast sitting by herself. She’s invited to a party with a few coworkers at the weekend: she politely passes, her friends are outside of work. She’ll go to the next one but it irks people that she doesn’t seem to care enough about being liked. From this description: Bob is a lovely, if very unlucky, person and Alice is a high-performing antisocial person.
The problem is, though: people like Bob seem to never quite get fired and, too often, people like Alice are labelled as “difficult”, “unfriendly” or, most disgustingly, a “poor culture fit”. We cut Bobs far too much Slack and Alices get insufficient credit.
A brief tangent: I used to be somewhat religious. One thing that struck me in those days was the hostility towards post-modern claims of the absence of “universal truth”. It always seemed a funny thing to get annoyed about; particularly when those who would get annoyed could not confidently state what the “universal truth” was. I could never see much of a difference between:
- “There is an absolute truth (but I don’t know for sure what it is)”
- “There is no absolute truth”
It feels like there’s a similar thing going on with judging people’s intentions. Despite my best attempts, I cannot draw a meaningful distinction between:
- “Bob’s and Alice’s intentions are important (but don’t know for sure what they are)”
- “Bob’s and Alice’s intentions do not matter (only their outcomes)”
As a result: I no longer care about intentions.
I’ve decided I love working with Alices and have developed an aversion to Bobs. If their actions are incompetent, hurtful and disruptive: that’s what I care about. I don’t care about whether they are trying their best or not. The people they hurt or help certainly don’t. Whether they’re in my personal life, open-source community or at work: I no longer have room for the repeatedly hurtful, even if their hearts are in the right place. If they are over 25 years old, chances are they should have figured out by now how people are hurt and how they can be helped.
Intentions be damned: it’s about doing good work and helping people.
]]>My favourite procrastination time sinks have been, in chronological order:
- playing too many computer games (I have Counterstrike to thank for my paltry initial lecture attendance)
- desktop Linux (the waste of time that felt most like actual work)
- social networking (aka. arguing about pointless shit on the internet)
- reading about politics and news
- Reddit, Hacker News, etc.
Most of these have been conquered by tools providing child-like parental limits rather than abstinence None of these could have been improved through willpower alone as I don’t seem to have any.
Playing too many games
This was the easiest to solve. In increasing order of effectiveness I:
- forced myself to go to bed by making my computer automatically turn itself off at bedtime, rudely killing any game
- did all my gaming on a different machine/device to my “work computer” (macOS for work, Windows for play)
- got several jobs which would fire me if I just played games instead
- married someone who doesn’t like games
- spawned offspring who are not (yet) interested in the sort of games I play
I still play a fair few games, though. It’s a great source of relaxation for me that I can do in short bursts, at home, for a relative pittance.
Desktop Linux
I wrote a post about this at the time but, TL;DR, I spent way too much time fucking around with my setup. Repeatedly refucking and defucking my Linux system was not a good use of my time. I still grew some neckbeard skills along the way, though, that proved very useful later when doing Linux server work and maintaining Homebrew.
I am effectively “abstinent” on desktop Linux, though. My innate urge to tinker makes it a terrible idea to do otherwise.
Social networking
I wrote previously about nuking my old content from Facebook and Twitter. I still use some social networks to a small extent but no longer allow social networks are allowed as apps or logged-in websites on my phone. Ultimately, I don’t find Mastodon (my primary social network nowadays) to be too much of a mind virus on my work computer. I learn useful things and have positive interactions with people that I’d miss if I went full abstinence.
Politics and news
I’m highly privileged enough to be mostly unaffected by most political changes and most news stories. I was also “lucky” enough to lose touch with good, real-life friends in early social networking days over stupid political arguments. As a result, I’ll still occasionally talk and think about politics and news but I try to only argue about it in meatspace, ideally: over a pint. I use an iOS app, ScreenZen, which uses Apple’s ScreenTime API (more on that later) to make it as unpleasant as possible to read it on my phone without fully blocking it.
Reddit and Hacker News
These are a tricky pair because they are useful to me sometimes but I get massively diminishing returns the more time I spent spiralling into their bullshit.
Hacker News has a nice server-side “procrastination mode” (noprocrast in your user settings): this lets you limit how long I can spend pissing around before you are blocked from doing so.

Reddit is like eating crisps for me: mostly bad for me but sometimes I need to trust my more-intense-than-usual need for it and indulge myself. As a result, I have heavily limited it by:
- using ScreenZen, as for politics/news above, on my phone to add friction
- give myself one minute a day on Apple’s ScreenTime (which I do not have the PIN for, I have to ask my wife if I need more time so: I don’t)
- keep it unblocked on my physically separate gaming machine so I can read about games stuff and indulge myself if I’m going to be wasting time gaming anyway
This all might sound like a lot and you may think I have great self-control as a result. Wrong. I have to put all these policies and restrictions in place because I have zero self-control.
I am glad for these changes overall, though. The result has been a better mood, being more productive at work and being more present with family.
You’ll still see me glued to my phone sometimes, though, but I’m probably just reading a new science fiction novel; a hobby nearly driven to extinction by the omnipresence of technology.
Good luck and happy procrastination-battling!
]]>- ⚙️ Evaluate performance on output, not on working hours: When everyone’s not colocated in the same place for meetings, pair programming, etc.: you don’t need everyone to work the same schedules. As long as there’s enough overlap for some synchronous meetings, most work should be done asynchronously at the times and places that are most productive for that individual. 40 hours spent “working” unproductively can be worse for the business than 20 focused hours spent working at maximum efficiency. Introspect when and how you are most productive and encourage your teams to do so too.
- ✍️ Write more, meet less: A one-hour meeting can technically be recorded but passing around a recording is rarely the best way of transferring information. Instead, consider writing documents which can be linked, shared, edited and kept evergreen for discussion. Keep synchronous meetings to a minimum in terms of regularity and attendance, and save them for tasks which cannot be done asynchronously or individually.
- 📧 Slack and email are async, not sync, tools: Email and, increasingly, Slack are not well-loved tools because they are often ineffectively used as synchronous, interrupt-driven tools requiring an immediate response. This destroys focus, concentration and individual productivity. Don’t send messages saying “Have you got a minute?” unless it’s incredibly urgent that you schedule a sync call now. Instead, ask “Hey, about the meeting yesterday, can I grab your thoughts on the migration when you have a minute?” and expect it may take 24 hours to get a response. Getting Slack and work email off your phone will also help with work-life balance. If it’s critical you can be contactable 24/7: have a more focused tool for that purpose e.g. iMessage, WhatsApp, PagerDuty.
- 🤪 Use emoji to convey emotion: I have been told, particularly when my profile picture looked a bit grumpy, that I can “write like an arsehole”. People can read brevity (combined with a grumpy profile picture) and assume anger, irritation or disappointment when it’s unintended. Emojis can help with this. Regular use of 😂😍🎉 etc. can be used to explicitly convey your emotion and gratitude.
- 🛬 Meet in person (sometimes): Even if distributed around the globe, like GitHub and Homebrew are, it’s important to have as many people as possible meet in person once a year or more. Technology is wonderful but it’s hard to “get” people to the same extent when you aren’t able to read body language and other signals. Try to make the best use of this colocated time together to do things you can’t do normally e.g. synchronous brainstorming. Primarily focus on getting to know each other better and improving human relationships, particularly across traditional organisational boundaries (yes: sales and engineering can be friends!). Hopefully, this has given you some ideas of how your distributed, remote, hybrid or even colocated culture can operate a little more effectively.
- 1) Go to the Psychology Today “Find Counselling” page for your location e.g. Edinburgh, London, Dublin, New York, etc.
- 2) Filter by “Issues” relevant to you or that you want to address, process or seek help with.
- 3) Filter by “Types of Therapy” if you know enough already to have an opinion. In my case, my free work sessions were Cognitive Behavioral Therapy (CBT) and, through my research, I thought psychotherapy would be a better fit to explore some childhood issues.
- 4) Filter by “Gender” if you have a preference. I struggle with talking to men about some issues so picked “Show Me Women”.
- 5) Filter by “Insurance” if you have health/medical insurance that you want to use to pay for your therapist. I have never had health insurance so paid directly.
- 6) After exploring their profiles, select 3-8 therapists that align with your requirements.
- 7) Email them to ask about availability. Bear in mind that not all of them might have immediate openings.
- 8) Arrange one-off meetings (which may be paid or free, depending on the therapist) with 2-4 of them. Let them know you are trying to find a therapist, are meeting multiple and the first session is a mutual evaluation for fit.
- 9) Pick one, email them arranging a first session, and email all the others thanking them but letting them know you’re going with someone else. If you didn’t find someone: go back to Step 6 and see if anyone else fits. If you still didn’t find someone: go back to Step 2 and consider loosening your filters.
- 10) All your problems in life will be instantly fixed. Ok, not really but: some of them will get better, I promise!
If you’re still on the fence about seeing a therapist at all, you might find these anonymous therapy podcasts to be informative and interesting:
- Esther Perel’s “Where Should We Begin” podcast and “How’s Work?” podcast
- Lori Gottlieb’s and Guy Winch’s Dear Therapists podcast
If you’re still on the fence: try it and see if it helps.
Good luck!
]]>The Design of Everyday Things
Don Norman

I was introduced to this book in a Human-Computer Interaction course at university but most of it barely mentions computers at all. It radically changed the way I thought about design of all everything, including all the software I have written since, to aim to be as intuitive and natural as possible. Tip: read this on paper or on an iPad rather than a iPhone or Kindle as the pictures as essential.
Working in Public
Nadia Asparouhova (formerly Nadia Eghbal)

I was lucky enough to read an early draft of this book and it’s simply the best analysis of the open-source software ecosystem around today. The writing style is friendly and not formal despite the academic-level research that went into this book. It made me think differently about the open source projects I maintain and how I interact and chose those I use.
Peopleware: Productive Projects and Teams
Timothy Lister and Tom DeMarco

This is the oldest book on my list and is the most underrated. It describes, with serious rigour and detail, how to run more effective software projects and teams. Most of this advice has been ignored my most of the industry for most of the time but it’s a big part of the reason I’ve worked from home for 14 years and am as productive as I am today.
Producing Open Source Software
Karl Fogel

This is from an older generation of open source development, pre-GitHub, but much of the advice here is still incredibly relevant and astute today, helping provide advice on the interpersonal as well as technical sides to open source development. Many of the underlying principals from this book are what form my grounding as an open source maintainer for the last 15 years.
Ship It! A Practical Guide to Successful Software Projects
Jared Richardson, Will Gwaltney, Jr

Another book that predates GitHub but provides a lot of actionable advice today that’s been mostly ignored across much of our industry. Hard problems like “why isn’t my software project reliable?” are tackled head on and addressed here. It was an early nudge for me to automate as much as possible in software projects and not ignore difficult problems with project organisation in favour of “fun” technical tasks.
Originally posted on Shepherd.com as “The best books for becoming a great open source software engineer”.
]]>Personal
- Spend less than you earn, and spend significantly less if you earn a lot.
- Build an “emergency fund” that covers several months of unexpected unemployment while paying all your bills and living costs.
- Avoid debt (even interest-free) for anything except appreciating assets (e.g. mortgage). If you can’t buy it outright: you can’t afford it (yet).
- Have all your personal accounts in a single app on your phone, and check them regularly to avoid overdrafts.
- Build up a credit rating by having a credit card where you pay off the total balance with a direct debit every month. If you miss a single payment: you negatively affect your credit rating.
- Prefer fixed costs over variable costs, e.g. buy your phone or car outright instead of on contract. This allows you to stop paying for things immediately and usually saves money long-term.
- Charitable giving can be claimed back on your tax return or by contacting HMRC directly. The more you earn and give: the more you’ll get back.
- Buy cheap first, and only expensive when the cheap version breaks and you use it often.
- No matter how much money you have: weigh up the price difference vs the practical difference. A Land Rover is much more expensive than my Mitsubishi Outlander. Is it much more effective at the job? No.
- If you’re married, both work and have kids: pool your finances. Put all your income into one account and distribute some “luxury money” to personal accounts to spend how you choose. You will be happier this way.
- Use multiple bank accounts for better organisation of your money and to help manage different financial goals. I don’t carry a card for my “Auto” account; it’s only for subscriptions, direct debits and standing orders. My “Both” account is most of my daily spending and doesn’t have subscriptions, direct debits and standing orders.
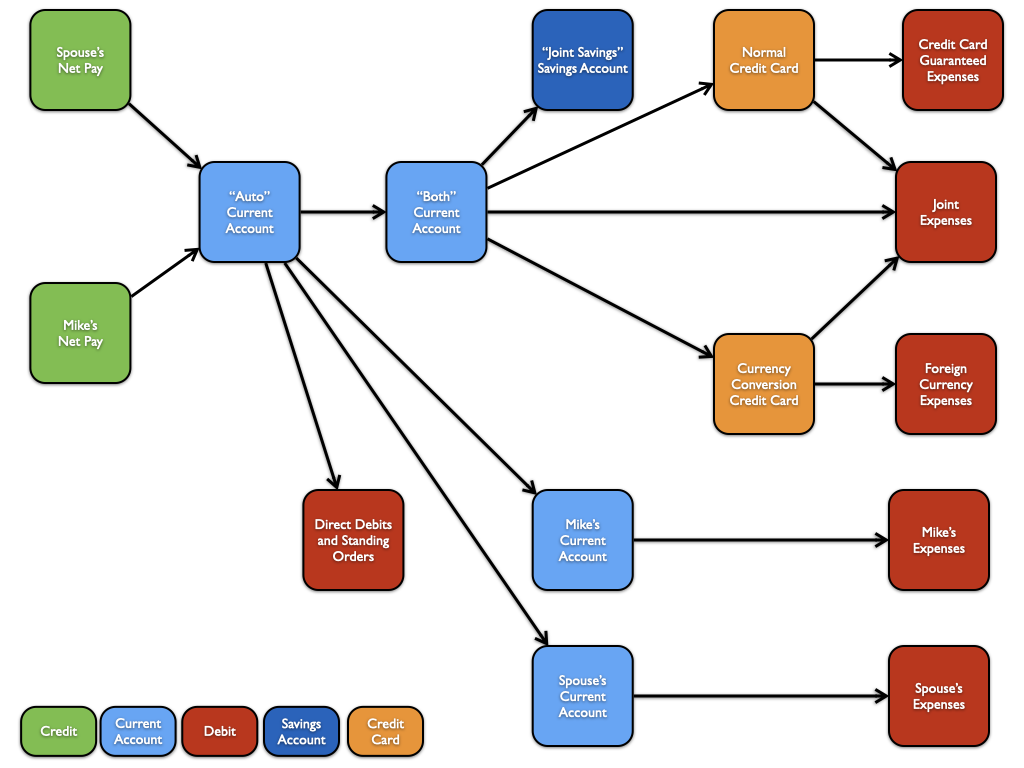
Self-employment
- Separate all your personal and business finances with different bank accounts.
- If you’re transferring money from the business to personal (or vice versa), do so with a bank transfer. Don’t just use the business card for personal purchases (or vice versa).
- Calculate your rough tax rate for this year (overestimate rather than underestimate) and automatically transfer this money into a business savings account for tax payments. Anything left over after paying your tax bill: you can pay yourself as a “bonus”.
- Use business accounting software (I loved Freeagent) to track all incoming/outgoing payments from all your business bank accounts, all your income and all your expenses. Do this work consistently, and doing your tax return at the end of the tax year will be very easy (FreeAgent makes it almost a single click).
- Do your own accounting and tax return. It’s not hard; ultimately, it’s on you to do most of the hard work anyway. A tool like FreeAgent will make this much more straightforward.
- The more you earn/tax you pay, the more money you “save” by putting (legitimate) expenses through your business.
Small business
- Prefer recurring monthly payments from customers over one-off payments. This should be set up with standing orders, direct debits or automated credit card billing.
- Inversely, choose one-off business expenses rather than recurring ones. Your cash flow can be badly harmed by too many recurring expenses.
- Raise your prices a small amount every year. People respond better to frequent, small price increases than large ones. If you don’t raise prices: inflation means you charge less yearly.
- You must charge more if you have more demand/customers than supply/time.
- All big business has different pricing for different customers getting the same service. It’s okay for you to do it too.
- Generic “business coaching” is often a scam. Getting your finances sorted is much more impactful than changing how you target customers (if you already have plenty).
General
- All financial advice, including the above, is situational, based on personal experience and may be entirely wrong for you. Use your best judgement.
log4j vulnerability about whether or not open source is broken or sustainable, what we can do to improve the sustainability of the open source ecosystem moving forwards, and the entitlement of users and companies in expecting maintainers to fix their problems.
As the project leader of Homebrew, a macOS and Linux package manager with millions of users, I have experienced, and continue to experience, a lot of entitled behaviour from contributors and users of Homebrew. Ironically, this is often worse coming from employed developers’ large tech companies with fantastic profit margins. Similarly, being a staff engineer based in Scotland at GitHub and working in a very different time zone to my peers, I have learned that setting consistent, clear and firm boundaries with people in my open source and professional work results in a better experience for (almost) everyone.
Let’s start with a few definitions of terms I’ll use in this article so we’re all on the same page:
- open source project: a software project where the source code is freely released under an open source license (e.g. MIT, Apache, GPL). Often on GitHub, GitLab or a similar hosting platform.
- user: someone who uses open source software but has not yet been or become a contributor or maintainer
- contributor: someone who has submitted code to an open source project which was accepted and merged into this project but does not have write access to merge their own changes
- maintainer: someone with write access to an open source project who is able to merge changes from contributors, other maintainers or themselves
A story of open source entitlement
To understand entitlement in open source, let’s use a fictional case study based on my experiences.
Bob works for TechCorp and discovered a few years ago that using a tool installed from Homebrew results in a 90% speedup on an otherwise boring, manual task he has to perform regularly. This tool is increasingly integrated into tooling, documentation and process at TechCorp and everyone is happy, particularly Bob. Bob receives a good performance review for improving the process at TechCorp.
Fast-forward a few years, one of Bob’s coworkers runs the tool that Bob built and it doesn’t work as expected, throwing a weird error no one has seen before. They go to Bob and ask what the problem is. Bob is in the middle of another project with a tight deadline so doesn’t really have time to help but feels some responsibility and jumps in and checks it out.
Bob discovers that a change in Homebrew has meant that the tooling will no longer work the way it used to. As he digs in, he realises this was announced by Homebrew a few months ago but he never saw the messages.
Frustrated and stressed, Bob opens an issue on Homebrew where he makes clear how disruptive this change has been to him and his organisation, who are heavy users of Homebrew, and that it needs a fix ASAP so they can deliver what they have promised to customers. His open issue awaits a response.
Reem is a Homebrew maintainer. Most of the time, she works on Homebrew in the evenings and weekends when she’s finished with her day job. She enjoys working on it and has been getting more and more confidence to make bigger changes.
Reem noticed that the tool Bob was using was badly outdated and the upstream software providers no longer supported the versions that Homebrew was distributing. She’s concerned that this may expose Homebrew users to a security vulnerability so she posts an announcement in the Homebrew issue tracker, discussion forum, Slack and Twitter to let all Homebrew users of the tool Bob was using know that there are going to be some breaking changes coming up.
Fast-forward a few months and Reem has made these breaking changes and, until today, there had been no issues reported with it. The other Homebrew maintainers said “well done” on her work but no users have commented positively or negatively on the 10 hours of evenings and weekends she’s spent working on this issue.
She sees the new issue opened by Bob. She expresses sympathy with Bob’s position but closes the issue pointing to the deprecation notice and upstream changes and said that Homebrew cannot revert this change now without breaking things for even more users.
Bob is incredibly frustrated with Reem’s response. He is already stressed at work and can’t believe that she has been so dismissive of his needs. He insists the issue be reopened and someone fix these problems.
The issue is not reopened. The behaviour remains unchanged. Bob and others at his workplace make the necessary changes to adapt to the changes in the tool.
What went wrong?
The above example has played out hundreds of times in my time working on Homebrew. Hopefully, I’ve made it nuanced enough to make clear that I don’t think either Bob or Reem are bad people or are coming from an unreasonable place.
Unfortunately, Bob’s entitlement is very detrimental to the Homebrew project, Reem and the open source ecosystem as a whole.
Bob and TechCorp are benefitting from the work done in Reem’s free time and from the fact that they’re able to use Homebrew, and the tool installed from it, free of charge in a way that works for them 99% of the time. Additionally, Homebrew’s MIT open source license, like almost all open source licenses, clearly states that Homebrew provides no promises of support, warranties or guarantees that the software will work as expected.
The lifeblood of volunteer-run open source projects, which is most of them, is ultimately the motivation of the maintainers who work on them. Some are doing it in their free time outside of full-time employment or education, some are doing it as part of their full-time employment and some may receive sponsorship for their work. Regardless of their status: they can generally choose what they work on, when they work on it and which issues they decide to fix.
The general state of the open source ecosystem is that most maintainers are building software they want other people to use and find useful. When they break the software in a way that makes it no longer usable, they will generally try to fix this breakage. When users have complaints, they will generally try to alleviate these.
The problem is that these generalities turn into expectations of behaviour, those expectations turn into entitlement and entitlement turns into toxic behaviour that makes maintainers quit open source.
How could these problems have been avoided?
With examples like the above, I have had the (dubious) benefit of being on both Bob’s and Reem’s end of this story multiple times. Many things could have been done differently, so I’ll spell them out separately. Bob in leadership could have:
- set up the initial tool inside TechCorp he could have noted in the tool documentation, for the benefit of his coworkers and himself, that it relies on a volunteer-maintained open source project, so may break or require updates in future.
- ensured there was a team staffed to keep an eye on dependencies (like this tool and Homebrew) and prioritised and performed the necessary work based on the deprecation notice before the breaking change occurred.
- ensured there was a team staffed to fix issues with open source tools when they crop up so it didn’t fall on Bob to do so.
- entered a consulting relationship with one or more Homebrew maintainers or contributors to make the changes they needed in Homebrew or the tool to support their needs.
- ensured that their use of Homebrew or this tool were isolated so they were not affected by auto-updates breaking their workflows.
- relied on a fork of Homebrew and/or this tool to ensure that they can manage exactly how these tools are rolled out on their systems.
There are probably more options here that could resolve the issues with these interactions in different ways. The thread that links them all is that the maintainer is offering a free gift of the open source software to Bob and TechCorp but actually keeping that software efficiently running is up to them, not Reem or Homebrew.
How else does this go wrong?
The story I provided above is one where Bob’s, and indirectly TechCorp’s, entitlement to Homebrew and the unnamed tool results in demands on the time and emotional energy of Reem and the other Homebrew maintainers. I would be happy if a maintainer I was mentoring responded how Reem did above, that’s one of the best-case scenarios. She was under no obligation to offer a deprecation period, fix issues or express sympathy but did so anyway.
Sadly, maintainers like Reem are often pushed into a situation where they feel obligated to sacrifice their time and mental health to satisfy folks like Bob and TechCorp because they “feel bad”. I want to be very careful to avoid victim-blaming in this situation but there are some resources I’ve personally found helpful dealing with being in a leadership or maintainer position in a widely used open source project for over a decade.
Coping strategies
Firstly, you should only be maintaining open source software you use yourself. This is partly because you can’t be a good maintainer unless you can empathise with your users but also because your open source work should be enjoyable and you’re unlikely to enjoy satisfying the demands only of others and not yourself.
Secondly, remember and really deeply internalise the fact that you can stop working on any open source project at any time. Open source maintenance is a job and, like a job, when it stops working for you and you have better options, you can go elsewhere. You should not feel bad about this; instead, you should feel good about the fact that every contribution you continue to make or made in the past were good deeds given freely to others. When your life or the project means it no longer feels good to work on it anymore — stop.
Third, your time as a maintainer is simply more valuable than that of your users. In Homebrew’s case, there’s 30 maintainers and millions of users. It does not scale to prioritise user time over maintainer time. In many, perhaps most open source projects there’s a single maintainer. As a result, this maintainer should only be doing the tasks that users and other contributors cannot do. Alternatively, this maintainer should only be doing the tasks that they want to do.
Finally, maintainers need to learn to say “no” again and again. No to new features. No to breaking changes. No to working on holiday. No to fixing issues or merging pull requests from people who are being unpleasant. No to demands that something has to be fixed right now.
Open source software is a wonderful thing that many individuals and organisations are heavily reliant upon. Much of it is built on the backs of volunteers, though, and all the folks involved with its creation could decide to walk away. As a result, we need to be careful to ensure that maintainers in open source projects maintain boundaries to avoid burnout and users of open source projects avoid entitlement and learned helplessness to solve their own problems.
This article was originally published on WTF is Cloud Native.
]]>Ignorance 🤨
We knew everything that needed doing, and we did it. It turns out, whenever you think you know everything: you actually know nothing. If you believe you have a great memory, you probably forget to do things all the time. Any project that assumes a perfect understanding of the existing systems or your superiority over those that built legacy systems will fail.
 (G.K.) Chesterton’s Fence provides a great way of thinking about this.
If you see no reason why a legacy system works the way it does: you are not allowed to change or remove it.
Until you can explain why something was once necessary: you are not in a place to say it is not needed today.
If you can’t explain why but need to change or remove it: tread carefully and remember your ignorance.
(G.K.) Chesterton’s Fence provides a great way of thinking about this.
If you see no reason why a legacy system works the way it does: you are not allowed to change or remove it.
Until you can explain why something was once necessary: you are not in a place to say it is not needed today.
If you can’t explain why but need to change or remove it: tread carefully and remember your ignorance.
Incompetence 😫
We did things right the first time without making mistakes like those idiots before. It turns out that when you aren’t willing to make mistakes: they will be more severe and public.
 The Cautionary Tales podcast used two great examples to illustrate this.
The Billy Joel musical was a disaster in previews, but: they learned from this, and it was a sensation on Broadway.
The MacCready Gossamer Condor was the first human-powered aircraft capable of the criteria for the Kremer prize.
The Condor did not win from a perfect first attempt.
The Condor won because it repeatedly failed, iterating and improving each time.
The Cautionary Tales podcast used two great examples to illustrate this.
The Billy Joel musical was a disaster in previews, but: they learned from this, and it was a sensation on Broadway.
The MacCready Gossamer Condor was the first human-powered aircraft capable of the criteria for the Kremer prize.
The Condor did not win from a perfect first attempt.
The Condor won because it repeatedly failed, iterating and improving each time.
Building software is the same. Don’t try to avoid failing. Try to fail faster and improve faster. Try to fail earlier when it’s just personal embarrassment in front of your coworkers and not your company’s embarrassment in front of customers and competitors.
Remember that some failures will only happen at production levels of system load. Try to get a high system load without customers relying on it. Even after all this: things will fail. You are incompetent, but know you are and plan accordingly.
Insignificance 😕
We had all the needed resources and more; we had complete buy-in from leadership. It turns out that this made the team unwieldy, and the scope exploded to justify the headcount. Instead of trying to get more and make things better, we should have kept things smaller.
Tiny ships get to production quicker where actual customers can test them. Tiny teams build closer bonds, have more shared context and cannot silo. Tiny scope forces you to think about only what’s essential.
You’re calling that a MVP? It’s not minimal at all. Not being minimal means it might not get released in any form, to anyone, ever. An insignificant project is a project set up for success.
The Worst Project 🎉
This project was the worst.
The timelines were aggressive from the outset.
Compromises were necessary everywhere.
We had to use that existing system that was unstaffed and in maintenance mode.
We didn’t know how the existing systems worked, so we had to rely on trial and error.
Failures kept happening, and we didn’t know why.
We didn’t have as many engineers, designers or product managers as we needed.
We delivered something.
Customers loved it.

Why say “no”?
I’ve been consuming a lot of Brené Brown’s podcasts and read one of her books recently, and they’ve got me thinking about what’s at the root of being able to say “no” regularly and well.

Brown uses the BRAVING acronym to refer to the elements of Trust. Out of these, the ones that jump out to me for saying no are boundaries, reliability and integrity. To meaningfully trust others on these axes, you cannot be someone who says yes to every request. In doing so, you maintain no boundaries, professionally or personally, and will not be a reliable coworker.
To the software engineers reading this, I’m sure we’ve all worked with some APIs that have been great and some that have been terrible. An API with inconsistent and unpredictable behaviour with the same inputs is terrible. A poorly documented API is terrible. An API that attempts to accommodate your request and consistently times out rather than failing immediately is terrible.
Human relationships are like APIs: consistent and predictable responses make them more pleasant. A bad API for your coworkers is when you’re someone who gives radically different estimates for the same work based on whether you want to impress the person or not. A bad API for your coworkers is when you state you’re on holiday or sick but still appear in conversations and meetings anyway. A bad API for your coworkers is when you tell them a 19:00 meeting is fine, but you’re hangry and irritable because you’ve missed dinner and your children’s bedtime.
A previous performance review of mine from a great manager started with the sentence “Mike is very strict with his boundaries”. “Oh no”, I thought to myself, “I’m going to get criticised for always prioritising being there for my children’s dinner and bedtimes four nights of the week”. Instead, he went on to say that this made me easier to work with, set an excellent example for other members of the team to not overwork and set expectations for new parents on the team. Ironically, in this case, being a little more selfish with my time and strict with my boundaries produced an outcome that benefitted the entire team.
Having these boundaries clear and upfront is more complex but crucial for unexpected tasks. If when asked for an estimate, you can tell there’s a bunch of complexity that the requester did not consider and know that your realistic one will disappoint them: you should give them the realistic estimate. If you already feel overwhelmed or have too much to do when asked to do something new: you should say “no” regardless.
I call this “front-loading disappointment”. It’s better to have a conversation about your full workload or longer estimate now when people can prepare for it. Making them happy now and then disappointing them in a few months when you don’t deliver what they planned for you is worse. I’ve also found it less disruptive in my workplaces to ship a project earlier than planned rather than later than planned. If you’re the type of person who hates disappointing others: you’ll need to take my word for it that there’s reduced disappointment overall when it’s pushed earlier. Similarly, you’re not responsible for others disappointment with the facts they didn’t know before you (nicely) revealed them.
When to say “no”
Ok, we’ve touched upon why you should say “no”, so let’s discuss when it’s appropriate to do so.
What’s your current workload right now? How are your stress levels outside work? Do you have many commitments you need to meet soon to coworkers, family or friends? What are your goals for the next 3-12 months and what’s the best use of your time to achieve them? What tasks do you have on your plate that are “essential” rather than “nice to have”? Regularly asking yourself these questions can help prime you to remind you of them when receiving a request.
When a new request comes in, and you’ve asked yourself the questions above, you’ll probably have a good sense of whether you can meet the needs and expectations of the requester or not. If you think you cannot right now: say “no”. Every “yes” is implicitly a “no” to something else you might not know yet.
Don’t worry about if you’ve been saying “no” a lot recently; this is not necessarily a problem. Of course, if you’re saying no to every request from coworkers, friends and family, this could be a symptom of a broader problem. At work, though, it’s expected that there will be more demands on your time than your available time. If you’re saying “no” a lot, but you’re still delivering great work, and your coworkers and manager are happy with you: you’re doing enough.
How to say “no”
There’s still a little bit of art involved in saying “no”. It may be that your “no” actually means “no because …, “no unless you …” or “no if this …”. These “no”s may be conditional on you as an individual, the timing of the request, the scope of the request or many other reasons. Try to share your reasoning with the person who has requested this of you; it may be that something you understood as critical to the task is actually optional and can be removed given the extra context of a “no because …” or “no unless …” provides.
At least in software engineering, one word to avoid is “impossible”. There are very few things that are genuinely “impossible” (e.g. the halting problem) and avoid it unless it’s one of those. If you’re saying you cannot do a task now, avoiding “impossible” ensures that you don’t try to generalise that to state that no one can do it ever.
If you’re feeling like you’re saying “no” a lot and this is dragging you down, you can ask others to help you. The engineering/project/product manager or a staff-plus engineer on your project may be able to say no on your behalf. It may also be if you repeatedly state “no” to the same person that they are asking the wrong layer of the organisation, i.e. an individual contributor rather than their engineering manager or product manager.
Finally, a “no” is generally a disagreement in either values or information. Figuring out which one applies now may help you figure out how best to communicate or get past the “no”. For example, my current GitHub organisation (Communities) has tight values alignment. When we need to communicate a “no” in Communities, it’s a matter of sharing missing information rather than resolving a values difference. In open source, my “no”s are often due to a misunderstanding about what my obligations are (not) to those people who use my projects.
Thanks to @nerdneha for talking through this post with me and to my long-suffering coworkers and contributors to the open-source projects I maintain for all my “no”s over the years. Thanks to @kenyonj and @katestud for providing excellent feedback on this post.
]]>When estimating a software project you should not:
- refuse to estimate because of any of the reasons below
- plan things to go as you expect
- ignore testing, code review, deployment and integration takes time, often longer than writing the code
- present exact dates or times without ranges
- be pressured into different estimates for the same scope based on “business needs”
- be unwilling to pad estimates based on them “feeling” too long
- estimate the entire project without splitting it up individually ranged, estimated sub-projects
- be unwilling to adjust estimates after or during a project based on sub-project completion
- have a non-engineer produce the estimate
- have an engineer who will not be doing the work produce the estimate, without discussion with the engineer that will be doing the work
- assume that engineers will do the work in the same amount of time, even if they are the same “level”. Individuals matter.
- assume that other individuals/teams/departments will always be as responsive as you need them to be and never block progress
- estimate assuming that you will not reduce technical debt, leaving things better than you found them
- ignore Hofstadter’s law: “it always takes longer than you expect, even when you take into account Hofstadter’s Law.”
- ignore the sporadic relevance of Parkinson’s law: “work expands so as to fill the time available for its completion”
- ignore the project management triangle and discussions of which corner to prioritise
- ignore that context-switching has a cost, particularly between different projects
- ignore that re-orgs, team changes and internal or external controversies will distract engineers and cause projects to take longer
- ignore that the more novel the work, the less accurate the estimate
- ignore that cutting scope often results in both a better estimate and the ability to get user feedback earlier
- ignore that how work is grouped on a project can affect the overall estimate
- ignore that engineers work faster on work they are excited about
- ignore that happy teams work faster
You cannot increase all your estimates due to all the above. They won’t all be relevant every time. You should ask yourself which of these are most likely to be relevant when you do your estimations. If things change during or after your estimations, e.g. a team change or re-org, you should communicate that the estimates will be affected to whomever you communicated these estimates to.
Of course this article bears a huge debt to the many decades of writing on software estimation such as The Mythical Man Month, which I’ve never actually read, and Peopleware, which I read and enjoyed.
Thanks to @bigkevmcd and @DW-DW-DW for reviewing this article.
]]>You: “I’m looking to hire a senior engineer. Know anyone good?”
Me: “Oh great, I know some good people! How about
$A?”You: “They won’t do. We need someone with at least
$Xyears in$TECHNOLOGY.Me: “Why?”
You: “They need to be able to get up to speed quickly.”
Me: ☹️
There’s many assumptions being made here that may or may not apply in your organisation:
- having written
$TECHNOLOGYfor$Xyears means new hires will be able to get up to speed with your codebase using$TECHNOLOGYbecause they won’t have to learn$TECHNOLOGYon the job - all your existing use of
$TECHNOLOGYis so perfectly idiomatic that it will be trivial for anyone with$Xyears experience in$TECHNOLOGYto understand the code - the main blocker in getting up to speed quickly will be learning
$TECHNOLOGYrather than learning your version control system, deployment system, company engineering culture, etc. - there is a sufficient supply of engineers with at least
$Xyears in$TECHNOLOGYthat will want to work at your organisation for the compensation you’re willing to pay and loosening these constraints will not get you a better hire - the short-term optimisation for new hires getting up to speed quickly will be a good decision in the medium/long-term
You also may or may not have thought about the following:
- much of the job of a senior-plus engineer involves tasks unrelated to writing
$TECHNOLOGYe.g. databases, on-call, deployment, mentoring, breaking down issues, collaborating with management/product/design/sales etc. - engineers who already have experience in more than one
$TECHNOLOGYcan often pick up new ones extremely quickly - experience with more than one
$TECHNOLOGYand different$TECHNOLOGYparadigms can often make engineer better at writing all languages - your choice of
$TECHNOLOGYmay not be the best fit for the problem and an engineer with experience in other languages may help you consider future alternatives - you may not be using
$TECHNOLOGYin the medium/long-term $TECHNOLOGYmay not be something that many people have$Xyears experience of (but are willing to learn)
In my experience, the combination of those assumptions and not thinking about all the above (and more!) mean that I consider it to be an anti-pattern to require experience with a specific technology from engineers. You can factor it into a hiring decision: given two otherwise identical candidates the one with more experience in this language may be more desirable.
If you reword your job advertisements to remove this $TECHNOLOGY as a “requirement” and replace it with a “desirable” (or just mention you use it) you will find yourself able to get more, better candidates into your hiring pipeline (particularly from underrepresented groups in technology that will often not bother to apply when they don’t meet “requirements”).
This may require changing your interview process. If the majority (or entirety) of your process assumes working familiarity in a given language and you expect the candidate to be able to write that language without any help: the candidate and interviewer are going to have a terrible experience. Ideally, your process allows the candidate to bring a language they are comfortable with and/or is an “open book” pairing process on the technology you use internally. Additionally, the more experienced the candidate or more senior the position: the more of the interview process should be dedicated to communication, engineering best practises, architecture, etc. rather than just programming.
This can be a hard adjustment to make but it’s one the best engineering interviewers made years ago (and you can too).
By “a senior-plus experience” I mean e.g. senior, staff, principal engineers etc. Never heard of staff or principal engineers? Check out my “What is a Staff (or Staff-Plus or Principal) Engineer?” article .
]]>👎 What aren’t “Open Source Economics”?
When most people hear the term “economics” they tend to think about how 💵💶💷💴 flows around an economy and, particularly in a capitalist economy, how the allocation of capital affects the throughput of businesses operating in a free market.
As a result, when people hear the term “open source economics” they tend to jump to the same conclusions: it’s about how 💵💶💷💴 flows between and is invested in open source projects. This is not a bad conclusion, it results in the creation of tools such as GitHub Sponsors that benefit many open source maintainers but it’s not the whole picture.
When you look just at the financial side of open source projects you tend to assume any problems they suffer are due to a lack of investment and can be solved by adding more 💵💶💷💴. For example, if a project struggles to make releases, review and merge pull requests, close issues or answer discussions: if they had more money they could pay someone to do that work and more of it will get done.
Unfortunately, money alone will not always fix any of these problems. Money can help but it needs correct investment and understanding of what the real problem is.
👍 What are “Open Source Economics”?
An “economic problem” is one which requires the allocation of limited resources in order to solve a problem. In modern, capitalist economies: the limited resources are usually 💵💶💷💴. Where there is a labour constraint, this is solved by paying enough money to compensate or attract the right candidates to solve the problem.
Open source software is a little different because of small pool of “labour” (maintainers) with knowledge of a project (perhaps single person) most of whom do their work voluntarily for no direct financial compensation. Many widely used open source projects are built by a single maintainer and, if so, this maintainer is the only person who can make all releases, review and merge all pull requests. Even with multiple maintainers, a widely used project will have a much smaller number of people doing this work than consuming the results. This means that domain knowledge and access control is limited to this one person or limited group of people.
The Open Source Contributor Funnel is pretty stark. In Homebrew’s case: there’s millions of users, thousands of contributors and tens of maintainers.
Relatedly, the time that these maintainers spend on the project may not be optimally allocated for the continued progress of the project. It’s easy for their time to become monopolised by niche problems from a few users that require a lot of individual attention at the detriment of writing code to improve the project for the majority of users. This makes sense from the incentives of each user to just get their problem solved but not for the project as a whole (and may not even be the best for the user if it slows or halts feature development).
Relatedly, this is why you should stop mentoring first-time contributors.

A tragedy of the commons occurs not from consumers over-appropriating the content itself, but from consumers over-appropriating a creator’s attention.
Nadia Eghbal, Working in Public
As a result, the “open source economic problem” is solving how to have sufficient labour that is allocated efficiently. Money can be part of this by e.g. increasing the ability or motivation of a maintainer to spend more of their time on the project but unless this is allocated effectively the project may not be any better off.
There’s also some thresholds effects for a project’s income. For a project run by a single maintainer with a day job, if they are paid enough to quit and work full-time on open source that may hugely increase the throughput of the project. However, even at 5% less than the amount they require to quit, they may not be able to dedicate any more time to the project. In some situations they may be able to pay others to take work off their plate but not always.
👩🔧 What are some solutions?
Viewed through a labour-centric rather than money-centric lens, the “more money invested in a open source project translates directly to a more effective project” obviously falls short. However, there is a place for maintainers and sponsors of open source projects to solve these problems.
🧘♀️ How to Focus
There are some aspects of running an open source project that can only be done by maintainers (or their automation). These include merging pull requests, making releases and closing issues. Without new commits, merged pull requests or releases: a project is effectively dead.
As a result, maintainers should focus their time on what only they can do and delegate as much as possible to automation and community members.
For some (GitHub-centric, it’s where I’ve done all of my open source work for years before I worked there) examples:
- instead of manually correcting style issues on pull requests, use a GitHub Actions workflow to automatically run style checks
- instead of manually closing our stale issues, consider using the GitHub Actions stale workflow to do so
- instead of walking individual community members through the solutions to their problems, enable GitHub Discussions (which maintainers that should not feel obligated to respond can unwatch) so community members where they can help each other
- instead of asking the same questions for every new issue that is opened, enable Issue Forms to make answering these questions a requirement to open a new issue
Finally, and most importantly, maintainers should primarily focus on what they most enjoy doing. In all open source projects (and particularly those that are mostly volunteer run): the motivation of the maintainers is what keeps the project running. Remember: open source maintainers owe you nothing! If the maintainers spend most of their time doing things they don’t enjoy, this motivation will deplete and eventually expire and the maintainer will abandon the project, perhaps with no-one to replace them.
💷 How to Spend Money
As mentioned above, when a sufficient threshold is reached, a maintainer may be able to go full-time to work on their open source project(s). If the maintainer has stated this as a goal publicly, helping them to reach it by spreading the word may be tremendously valuable to the project.
This may not be their goal, though, many maintainers are happy with their day jobs and would rather top-up their existing income or spend the money elsewhere. Sponsorship of open source projects is particularly useful when it helps to save time for the maintainers e.g. software tools, infrastructure, etc.
Although it requires a non-trivial investment of time from the maintainer, spending money by bringing more maintainers into the project through programs such as Google Summer of Code, Outreachy or Major League Hacking Fellowship can help add more contributors (and hopefully maintainers) to the project and reduce the burden on the current maintainers.
🎬 Conclusion
Money is an important ingredient into improving the open source ecosystem but it must come along with prioritising the motivation of maintainers, how their time is spent and realising that it does not solve all problems.
Thanks to Ron McQuaid, Denise Yu, Neha Batra and Alan Donovan for reviewing this post and providing helpful feedback.
]]>The Engineering Career Track(s)
Before GitHub, the engineering career track I have been most familiar with looked something like this:

At GitHub in 2021, the 1st to 3rd is the same, with different terminology I’ll gloss over, but there are three possible choices:
- you stay as a Senior Engineer forever (this is supported and encouraged)
- you continue on the Engineering Manager (EM) track
- you progress on the Individual Contributor (IC)/Staff+ track
The EM and IC tracks run in parallel, so you have something like:

Generally, the reporting structures are across a level so that you can expect a Senior Engineer to report to an Engineering Manager, Staff Engineer to a Director of Engineering, etc.
The compensation scales and expected areas of influence for each level are the same. For example:
- Senior Engineers and Engineering Managers primarily focus on the engineering output of a single team
- Staff Engineers and Directors of Engineering primarily focus on the engineering output of a single group of teams/organisation/department (i.e. more than one team)
- Principal Engineers and Senior Directors of Engineering primarily focus on the engineering output of multiple groups of teams/organisations/departments (i.e. many teams)
- Distinguished Engineer and Vice Presidents (VPs) of Engineering focus on the engineering output of the entire company
Similarly, Principal Engineers’ output is expected to affect the entire company and Distinguished Engineers’ output across more than just the company (i.e. the industry).
Differences between EM and IC tracks
The difference in responsibilities between an Engineering Manager and Senior Engineer is generally well understood. An EM should have regular 1:1s with their direct reports, will provide their performance reviews and, depending on the organisation, may provide some technical leadership, product management, project management, or even coding beyond their primary people management responsibilities.
A Staff/Principal/Distinguished Engineer should have no people management responsibilities whereas their EM/Director/VP counterpart will find that taking up a significant part of their role. The Staff/Principal/Distinguished Engineer will take responsibility for technical leadership, mentorship and is likely to still code and, in some cases, spend the majority of their time still doing so.
My Role
My staff engineer role changed from primarily feature coding work to engineering-wide work and feature non-coding work (e.g. scope adjustment, review, architecture). Increasing non-feature, time-critical commitments (e.g. mentoring, code review outside of the feature’s area, on-call, support existing staff projects, performing low-context fixes for my manager) caused me to be slow to complete feature coding work. After discussions with my manager, we agreed it was better for me to no longer be on the critical path for features.
As I embraced my staff engineer role, I found myself fitting into the “Solver” (and somewhat “Right Hand”) archetype. I am more useful as a value multiplier for other engineers rather than coding in areas where I have less context than other engineers.
I now optimise for unblocking others, being a “💩 umbrella” for other ICs, taking on high-urgency but low-context work and focusing on development experience for engineers at GitHub.
As I’m not part of a specific feature team, I fill out a weekly Geekbot report in Slack and keep track of my work in my GitHub project board. This increases the visibility of my work to others, stops things falling between the cracks and makes it easier to write my self-review, part of our performance review process.
When I became a staff engineer, I expected that I’d be doing less feature work and less coding. I probably code a little less than I expected to but I am happier with this than I expected to be.
I’ve been consistently and passionately disinterested in going into engineering management because I still like doing non-trivial amounts of coding and being evaluated based on that sort of work. Being a staff engineer has been a significant improvement for me for where I’m at in my career, family life and geographical location/timezone.
Resources
Despite it being a relatively well-trodden path in the technology industry at this point, there are limited resources to learn more about being a Staff+ engineer. Those I’d recommend are:
- The most important thing I’d consumed is Tanya Reilly’s Being Glue talk. It’s a great way of thinking about the sort of work that effective Staff+ engineers can do (and all engineers, really) that is often undervalued. Find more from her at her LeadDev blog, personal blog and talks.
- Staff Engineer: Leadership beyond the management track book by Will Larson
- Staff Engineer stories/blog on Will’s staffeng.com site
- StaffEng podcast (also on staffeng.com). Check out my episode if you’re interested.
- Rands Leadership Slack’s
#staff-principal-engineeringchannel
Thanks to Graeme Arthur, Sarah Vessels, Keith Duncan and Luke Hefson for reviewing this post and providing helpful feedback.
]]>On the mentee side, I did most of my mentorship initially outside GitHub through mentoring new Homebrew maintainers informally and then more formally through Google Summer of Code. I’ve been lucky enough to work with folks such as @itsbagpack and @gallexi through their promotions to staff and senior engineer respectively; helping them figure out their role, strengths and weaknesses, review work and documents for them and generally have fun hanging out with inspiring engineers like them.
My situation shouldn’t be special, though!
Everyone can have mentors (and mentees)
For almost everyone in our industry: there is someone around who has more experience than you. That person will have some things you can learn from them.
Additionally, there’s lots of people in our industry who you may have more overall experience than but they have more experience in a particular subject or skill that you wish to learn more about.
For almost everyone in our industry: there is someone around who has less experience than you. If you’re new to the industry, you could mentor someone who is e.g. in a bootcamp, studying at college or high school.
You should have more contact with your peers than with mentors or mentees
The mentor and mentee relationship is important but to remain grounded and better understand yourself and what skills your team most needs right now you also need to remain connected to your peers. Doing so may already happen organically through pre-existing relationships, video calls, group chat channels etc. If it isn’t, though, or if you wish to supercharge this process: having regular 1:1 video conversations with your peers (structured or unstructured depending on your preferences) can help you improve this.
Mentorship Diamond
The above approach to mentors, peers and mentees can be summarised by this “mentorship diamond”:

How important is mentorship to my current role?
Let’s look at a few job titles as examples:
Junior Software Engineer
- Experience: Relatively new to software industry
- Non-manager Mentors 1:1s: 1+
- Mentor Location: In (and optionally outside) your employer
- Mentees 1:1s: Optional (but worth considering)
- Mentee Location: Outside your employer e.g. open-source, bootcamps, education
- Peer 1:1s: 1+
Senior Software Engineer
- Experience: Moderately experienced
- Non-manager Mentors 1:1s: 1+
- Mentor Location: In your employer
- Mentees 1:1s: 1+
- Mentee Location: In or outside your employer
- Peer 1:1s: 2+
Principal Software Engineer
- Experience: Very experienced
- Non-manager Mentors 1:1s: 1+
- Mentor Location: In or outside your employer
- Mentees 1:1s: 2+
- Mentee Location: In (and optionally outside) your employer
- Peer 1:1s: 3+
How can I get started as a mentor?
If you’ve already got someone who wants to be mentored by you: great! Discuss with them what cadence would work best for you both (weekly, fortnightly, monthly), whether you’d like it to be a structured or unstructured conversation, whether you’d like to pair together, etc.
If you haven’t already got someone who wants to be mentored: ask around. Ask your manager and other managers around the company if they have someone that can benefit from your skills. Consider looking outside the company for less experienced people you may have relationships with that you can offer mentoring too. If this is too intimidating, consider a structured program like e.g. Google Summer of Code.
Mentoring relationships also aren’t always “official”. They may be informal conversations with someone you’re regularly chatting and sharing knowledge with.
If you don’t have the inclination or bandwidth to take on a(nother) mentee right now: that’s ok! You can politely decline and, if you’re feeling extra nice, help them figure out someone more suitable.
How can I get started as a mentee?
This is a bit easier: figure out who you’d like to work with as a mentor and ask them if they can spare the time to be your mentor. Not everyone I’ve asked has said yes but I’m always glad I asked.
If you’re not sure yet who would be the best person to work with or you’ve asked people and they’ve turned you down: ask your manager for suggestions.
You can also start with having just informal one-off conversations with someone you would like to be a mentor and, if it goes well, arrange them to occur regularly.
This article written by @nerdneha is a great resource when searching for a mentor.
Thanks
Thanks to @nerdneha for suggesting, reviewing and generally inspiring much of this post. Thanks to @seejohnrun and @eileencodes for being great mentors and @itsbagpack, @gallexi and many others in and outside GitHub over the years for being great mentees and reviewing this post.
Additional Reading
- https://leaddev.com/mentoring-coaching-feedback/maximize-your-mentorship-establish-absorb-and-connect
- https://larahogan.me/blog/what-sponsorship-looks-like/
- https://blog.pragmaticengineer.com/developers-mentoring-other-developers/
- https://opensource.com/life/14/12/mentoring-open-source-and-everywhere-else
Firstly, when someone asks me to do something I immediately write it down in my Apple’s Notes app. This doesn’t have any mechanism for storing dates or times but just lets me enter text. This is good because it’s available and synced everywhere. If I have time (or when I next do) I then sort into lists based on topic matter. Some of my long-running lists are: GitHub (my current employer), Open Source (encompassing Homebrew and open-source projects I work on) and Random (a short dump for other tasks). Every time I do work for GitHub, open-source or myself I look on the relevant location to see what I should do.
I try my long-running notes structured into sections headed:
- Urgent - tasks that need done soon
- Don’t Do - the sort of tasks I shouldn’t be doing
- Todo - tasks that need to be done eventually
- Blocked - tasks I can’t do until something happens
- Notes - a dumping ground for anything that doesn’t fit above
When there’s a task with a time or date I put it into either Apple’s Reminders or Calendar app. Reminders gets anything that needs done on a particular date or repeatedly but doesn’t require me to go anywhere. Calendar is generally when I need to go somewhere or if it’s e.g. an online meeting that has a specific start and end time. These apps will pop up alerts on my Apple devices with a noise or vibration so I actually remember them.
The above was sufficient in 2015 when I first wrote this post but since I got promoted to Staff Engineer at GitHub I’ve had to get a lot better at keeping track of what I plan to work on in future, am working on right now and have completed. I’ve found a personal GitHub Projects board to be a good fit for this. I have columns headed:
- Backlog - tasks I may or may not ever do but want to keep track of
- Up Next - tasks I plan to work on in the near future
- WIP (Work In Progress) - tasks I’m working on right now
- Blocked - tasks I can’t do until something happens
- Done This Week - tasks I’ve completed this week; I’ll report on these and archive

If you have any familiarity with Getting Things Done then some of the above may seem familiar. I tried to follow it strictly in the past but found the structure overkill for me personally. I tend to keep my various TODO lists short enough that I can quickly scan and mentally prioritise them daily.
So far it’s relatively straightforward but I’ve omitted the most common productivity nightmare: email. I’ve heard the main problem with email being that it’s basically a TODO list that anyone can add to at any time. This is a problem.
First thing to do with your email is trying to keep Inbox Zero. In short: the default state of your inbox should be to have no emails in it and when you check your email you should end up with an empty inbox afterwards. This sounds like a bit of a pipe dream so let me tell you how I try to do this.
You probably get a bunch of email that you expect. Someone commented on your GitHub issue. Your company’s weekly newsletter got sent round. That person in your office who sends you only junk. These all patterns and patterns are good because a computer can handle them trivially for us. What I do is set up filters (in Gmail, iCloud, Outlook, etc.) which sorts each type of email into a folder (“label and archive” in Gmail). My long-running personal email folders are Bills, GitHub, News, Social (all social media notifications) and Software. This immediately let’s me prioritise these groups. Anything in these folders is never urgent during work time. If I’m emailed by someone I didn’t expect (e.g. my dog) it may be urgent so it ends up in the inbox instead of a folder.

I also keep my personal, Homebrew and GitHub emails in separate email accounts with different filtering rules. This makes it easier for me to ignore Homebrew and GitHub emails when I’m not working or on my phone. If you’re interested in my GitHub filtering rules, I wrote a post on the GitHub blog about managing large numbers of notifications.
It’s important to ask yourself when you get a new email: was this expected, somewhat urgent/important or even desirable? If not, filter it into a folder, unsubscribe from the mailing list, tweak your social media notifications or setup a filter to just automatically mark it as read and archive/delete it. Stop wasting your time repeatedly ignoring the same emails.
The tricky thing with the above system: what do you do if you don’t have the time to reply immediately to an email or it’s generally something you want to deal with later? I used to enjoy the Mailbox (an email client from DropBox) “Later” feature which could remind me of an email at a later point. Mailbox is no longer around and I’ve been burned too many times by my email clients going away that I feel I can no longer rely on this functionality (until it’s in Apple Mail or Gmail).
I now have returned to will leaving email in my inbox if it needs actioned imminently (i.e. this month) or flag (“star” in Gmail) if I need it at some point in future. Both Apple’s Mail app and particularly Gmail provide good enough search that I can always find what I need (as I always archive and never delete emails).

Slack has become a bigger part of my life for GitHub and Homebrew since I originally wrote this post in 2015. I tend to treat it pretty similarly to email: it can be a bit of a TODO list but I don’t want others to control it. Thankfully, it does have a pretty decent reminders feature that gets me back what I lost from Mailbox.
I hope you found this post to be useful. To summarise: immediately write down tasks you need to do on your phone/computer, triage them regularly, assign times/dates when possible and automate your email for easier prioritisation.
Finally, a pet hate: if you commit to doing something for someone please immediately make a note of this and actually do it in a timely fashion or let the person know if you can’t. This alone will make you seem like A Productive Person. Don’t try to just remember (because you won’t) or write it on a scrap of paper because you’ll lose it.
Good luck!
]]>