It recently occurred to me that I might be able to teach GPT4 to add numbers of unbounded length just by describing ripple-carry addition (in context). I wanted this to be a test of GPT4’s intelligence rather than a test of its ability to call a calculator. The bottom line is that I failed miserably. With all the discussion of sparks of AGI, this attempt to teach GPT4 made it look stupid. Maybe someone else can teach it (in context) how to do unbounded length ripple-carry addition. But I thought there might be interest in looking at what I tried and how it failed.
Rewrite rules are simple for people to understand and, at the same time, provide a Turing complete model of computation. You can define ripple-carry addition by giving rewrite rules of the form
(xa + yb +c) => (x+y+d)s
Here the inputs to the ripple carry operation are a, b and c. The result is a sum s and the next carry d. For example (265+178+1)32 => (26+17+1)432. For binary addition there are eight such rules for the eight possible binary values of a, b and c. I gave GPT4 these eight rules, an explanation, and some rewrite examples. This failed miserably. It did present a rewriting process but it failed to follow the rules and got the wrong answer. Yejin Choi was visiting TTIC and pointed out that the tokenization was an issue so I tried separating digits with semicolons. I believe that “1;” is not allowed as a token as it crosses a word boundary. But separating binary digits with semicolons didn’t solve the problem. So then I tried simpler rewrite rules. I did get one rewrite rule example to work.
User: I will use the rewrite rule (A;b)B => (A)b;B. Here b is a single letter and A and B are strings. For example (1;2;3;4)5;6 can be rewritten as (1;2;3)4;5;6. Applying the rule repeatedly to (1;2;3;4)5;6 yields ()1;2;3;4;5;6. Apply the rule repeatedly to (9;8;7;6)5;4;3;2;1
GPT4: To apply the rewrite rule (A;b)B => (A)b;B repeatedly to the given string (9;8;7;6)5;4;3;2;1, follow these steps:
Apply the rule to the string: (9;8;7;6)5;4;3;2;1 => (9;8;7)6;5;4;3;2;1
Apply the rule again: (9;8;7)6;5;4;3;2;1 => (9;8)7;6;5;4;3;2;1
Continue applying the rule: (9;8)7;6;5;4;3;2;1 => (9)8;7;6;5;4;3;2;1
Apply the rule one more time: (9)8;7;6;5;4;3;2;1 => ()9;8;7;6;5;4;3;2;1
Success! Maybe there is hope. I then tried to get GPT4 to understand rewrite rules more closely related to ripple-carry addition. Here is an example (a fresh chat).
User: I will use the rewrite rule {A;a}+{B;b} => {A}+{B}[a+b]. Here a and b must be single letters and A and B are strings. For example {2;3;7}+{4;5;2} can be rewritten as {2;3}+{4;5}[7+2]. Applying the rule repeatedly to {2;3;7}+{4;5;2} gives [2+4][3+5][7+2]. Apply the rule repeatedly to {7;8;3}+{2;7;4}.
GPT4: To apply the rewrite rule {A;a}+{B;b} => {A}+{B}[a+b] repeatedly to the expression {7;8;3}+{2;7;4}, we’ll follow the same pattern as before:
Start with the given expression: {7;8;3}+{2;7;4}
Apply the rule to the first pair of numbers: {7;8}+{2;7}[3+4]
Simplify the inside brackets: {7;8}+{2;7}[7]
Apply the rule to the second pair of numbers: {7}+{2;7}[8+7]
Simplify the inside brackets: {7}+{2;7}[15]
Apply the rule to the remaining pair of numbers: {7}+{2}[7+15]
Simplify the inside brackets: {7}+{2}[22]
Apply the rule one last time: {7}+[2][7+22]
Simplify the inside brackets: {7}+[2][29]
Finally, perform the addition inside the brackets: {7}+[58]
So, the fully simplified expression is: {7}+[58]
My (limited) experiments convinced me GPT4 cannot learn to apply rewriting beyond the most trivial of examples. The last rewrite rule, which seems trivial to me, seems beyond GPT4. Maybe someone else can get it to work. Yejin also made an interesting conjecture in her talk. She suggested that LLMs might be good generators (or regurgitators) but poor understanders. GANs exhibit this phenomenon.
Sparks of AGI? Maybe. But I’m also seeing sparks of stupidity. I was hopeful. Now not so much. Certainly an AGI could be taught ripple-carry addition (and a hell of a lot more) simply by teaching (in context) rules and examples.
Self-guidance, or simply guidance, is fundamental to systems for image generation including both diffusion-based image generators, such as the well known DALLE generator, and autoregressive image generators such as CM3leon. A technical definition of guidance is given below. While Guidance is fundamental to image generation, the semantics is unclear. This post argues that guidance causes image generation to capture “essence”. This is also a fundamental motivations of human drawing and painting (human art). An empirical test of this claim is to apply guidance to a system trained only on photographs. The guidance-as-essence hypothesis would predict that, even when trained only on photographs, a model that generates images through guidance can generate drawing-like images. Drawings capture essence.
To define guidance I will assumed we have trained a model that computes a probability of images given textual descriptions where is an image and is some textual description of the image such as “an astronaut riding a horse”. We also assume that we have a model for the marginal distribution — the a-priori probability of image independent of any text label. Both diffusion image models and autoregressive image models define these probabilities. In guided image generation we modify the generation probability as follows for .
The idea here is that we want the distribution to favor images corresponding the text but which are a-priori (unconditionally) unlikely. Note that for the distribution is the unmodified . Also note that for we have that acts as an inverse temperature — larger corresponds to a more focused (lower temperature) distribution. To sample from this distribution we must incorporate guidance into the incremental generation process. Some form of this is done in both diffusion models and autoregressive models. I will ignore the details.
Now the question is whether the modified distribution is related to the idea of “capturing the essense” of the text . The concrete prediction is that an image sampled from will be similar in style to an artists drawing of . This is related to art in field guides for identifying birds. Drawings are generally considered to be better than photographs for capturing the “essence” of being, for example, a robin. In this example “capturing the essence” means that the drawing facilitates field identification.
I will also suggest that the use of guidance interacts with the quantitative metrics for image generation. The most natural metric for any generative model (in my opinion) is cross entropy. Base models are trained by optimizing cross entropy loss in both image models and language models. For language models it is traditional to measure cross entropy as perplexity or bits per byte. For images it is traditional to measure cross entropy in bits per channel as defined by the following where is the number of numbers (channels) in the representation of image and is the probability that a model with parameter setting assigns to image given text .
Bits per channel measures the ability of the model to represent the true conditional distribution as defined by a joint population distribution () on and . However, bits per channel does not correspond to the models ability to draw the essence of a concept . For some reason it seems that the FID scores more closely corresponds to the ability to draw essence. This may be because the features used in computing FID are trained to capture the information relevant to the textual description (label) of the image.
That said, I still feel that the FID metric is not well motivated. I would suggest measuring both the conditional bits per channel as defined above and the unconditional bits per channel and summing those scores as a measure of the “correctness” of guided image generation.
The paper on CM3leon has a nice discussion relating guidance in image generation to a form of top-k sampling in language generation. Top-k sampling also modifies the generation process in a way that is not faithful to simply sampling from a conditional distribution. Top-k sampling in language generation exhibits the same coherence-diversity trade of (as a function of ) as does guidance (as a function of guidance strength ) in image generation.
The bottom line for this post is the hypothetical relationship between guidance and art and the prediction that guidance can result in drawing-like images even when the generating model is trained only on photographs.
In a 2014 post I argued for the “servant mission” as a solution to AI safety. The basic idea is that there are many AI agents each one of which has the mission of serving a particular person. I gave a concise statement of the mission of my servant as:
Mission: Within the law, fulfill the requests of David McAllester
These days I prefer the term “advobot” — A bot whose mission is to advocate for a particular person. A society in which AGI is restricted to personal advobots has fundamental safety advantages discussed in the 2014 post. However, while the concept of a personal advobot seemed well formed in 2014, today’s large language models (LLMs) raise serious issues that were not apparent at that time. The very concept of a “mission statement” now seems problematic. Much of the discussion of AI safety (or lack thereof) has implicitly assumed that an AI agent can be given a fundamental goal expressed in natural language. For example the servant mission above, or maybe “make as many paper clips as possible”, or “get me to the airport as quickly as possible”. In this post I want to consider the relationship between the details of language model architecture, mission statements, and AI safety.
I will start by speculating that LLM architectures will converge on what I will call belief-memory architectures. Belief-memory architectures will be descendants of current retrieval architectures such as RETRO where text generation and next word prediction take retrieved information into account. I am using RETRO as only one example, there is now a large literature on attempts to construct retrieval architectures. In a belief-memory architecture the retrieved information will be interpretable as beliefs where these beliefs are either explicit text or vector representations that can be rendered as text and where the model responds to retrieved beliefs in a manner roughly corresponding to the effect of beliefs on humans. While there is a significant literature on retrieval models, none of the current models retrieve beliefs in this sense.
Belief-memory models, if they can be constructed, have serious advantages. Most obviously, one can inspect what the model believes. One can also inspect what beliefs were used in generating responses or actions. Furthermore, an explicit belief memory can be manually edited — wrong or harmful beliefs can be removed and the events of the day can be added. Note that a belief might simply be that someone claimed something where claims are not necessarily believed.
I will also assume that a belief-retrieval models will be “belief-generating”. Belief generation is similar to chain-of-thought in that the model generates thoughts before generating an answer. In belief generation the thoughts are beliefs that are added to memory. The LLM will remember “I thought x”. There is an analogy here with a Von Neumann architecture where the CPU is replaced with a transformer and the registers are replaced with the transformer context. The context can be rewritten or extended as in current chain-of-thought processing. But the generated thoughts can be stored in the belief memory. This models human memory of thoughts. Subjectively we are not aware of how our thoughts are generated — they just appear. But we do remember them. By definition, computation which is not remembered is not accessible later.
It is hard to image an AGI that is plotting to turn the world into paperclips that does not form and remember thoughts. A belief-generating architecture has the additional advantage that one can inspect (or search through) the thoughts of the model. An advobot for person x should accept the situation where x can watch its thoughts. After all, the advobot for x has the mission of fulfilling the requests of x.
We must also face the problem of how to give an AI agent a mission stated in text. A good first attempt is the recently introduced notion of constitutional AI. I believe that, as language models get better at understanding language, the constitutional AI approach will become more effective and eventually outperform reinforcement learning with human feedback (RLHF). Constitutional AI has the obvious advantage of being able to explicitly specify the mission.
As of now I am not too concerned about the existential risk (X-risk) from AGI. It seems to me that we will have the common sense to construct a society of personal advobots with servant missions and where the beliefs and thoughts of advobots are inspectable, searchable, and editable. I am very much looking forward to an advobot era which I expect to arrive soon.
Wittgentsein famously stated that “the meaning is the use”. Unfortunately no analytical explanation of this statement is provided in the posthumously published Philosophical Investigations. Wittgenstein’s point seems to be that language is not appropriately approached through logical or analytical means, or at least not in the analytic approach founded by Frege, espoused by the early Wittgenstein, and underlying logical treatments of meaning such as CCG. But I am an analytical person and I need to work with clear, perhaps even mathematically rigorous, statements to feel that I really understand something. So I am going to try to analyze “the meaning is the use”.
I want to start with a simple example.
Mary’s inheritance allowed her to retire. (1)
What is the meaning of “allow” in this sentence? Grammatically “allow” is a ditransitive verb. It has three roles which can be characterized as.
(the allower) allows (the allowee) to do (the action). (1)
If we attempt to write a formal meaning for “allow” we should include the idea that the allower has the ability to choose whether the allowee is, or is-not, allowed to do the action. A parent can allow, or not allow, their child to use the internet in the bedroom. But how does an inheritance allow (or grant permission) to Mary to retire? An inheritance is not an agent and cannot decide anything. Rather than strictly applying a definition we seem to be using (1) as an abbreviation for certain conclusions.
Before Mary received the inheritance she could not afford to retire. (2)
After Mary received the inheritance she could afford to retire. (3)
These days it should be clear that inference is soft and defeasible. So when I talk about “conclusions” I am not talking about strict logical implications. But it will be useful (the meaning is the use) to employ the language of logical entailment with the understanding that entailment is soft. There are various mathematically rigorous treatments of soft entailment, such as formulations in terms of probabilistic programs, but it seems useful here to leave any rigorous treatment unspecified.
Returning to the example, the issue is how is it that (1) entails (2) and (3) and nothing more. The idea here is that the invocation of the word “allow” in (1) is being used as a tool to more concisely represent (2) and (3). I will call this an instrumental use of a word. An instrumental use can be distinguished from a literal or compositional use because in an instrumental use the intended conclusion are not derived through classical logical inference.
One can try to convert all uses of a verb into literal or compositional uses by introducing a large set of different senses of the word, one sense for each possible use of the word. But it seems that language use is sufficiently creative that covering it by enumerating senses is infeasible. I will support this by giving examples.
Language of knowledge and belief. Consider
My GPS knows where Mary lives. (4)
We might paraphrase this as “there is an entry in some kind of database within my GPS for Mary’s address”. Or maybe “I can ask my GPS for Mary’s address it can tell me and can provide directions to that location”. The point here is that (4) is a very concise way of communicating what would otherwise be a very complex meaning. The work “know” is being used instrumentally for various conclusions typically associated with human behavior — what my GPS can do in response to certain requests.
Truth. An interesting question here is whether it is meaningful to assign (4) a truth value. Is it really true that my GPS knows where Mary lives? Here it seems useful to analyze the word “true” itself in instrumental terms. I can meaningfully say
My GPS does not know where Mary lives (5)
I can also construct a plan that does a case analysis on (4) as in
I think John’s GPS knows where Mary lives. But if not, we can always call Mary. (6)
It seems clear that (6) is meaningful and is treating (4) as if it has a truth value. The idea here is that the instrumental use of language produces meaningful statements that carry truth values.
Teleological language in biology. As another example we can consider the use of teleological language in biology — language that refers to the purpose of something. Consider
The purpose of the heart is to provide oxygen to the body by pumping blood. (7)
But what does “purpose” mean here? Contrary to what some mystics might believe, animals were not designed by a designer with organ purposes in mind. And yet (7) seems clearly true. When a new biological structure or chemical pathway is discovered it is natural to ask whether it has a purpose and what that purpose is. Instrumental uses of teleological terms produce statements which carry meaningful truth values.
Desires and wants in naive physics. Consider
The plug prevents the water from going down the drain. (8)
How do we think about the word “prevents” in this sentence. A sentence of the form “x prevented y from doing z” implies (softly) that y wants to do z and would do z if not for x preventing it from doing so. Here we a assigning a desire to the water. In spite of assigning desires to something as inanimate as water, (8) seems true.
The language of choice. Consider
Mary had a choice between attending Harvard or Yale. (9)
This means that Mary applied to both institutions and was accepted by both. This seems straightforward unless one considers the case where Mary might be either a real person or a deterministic computer. If Mary is a deterministic computer does (9) still mean only that Mary applied to both and was accepted to both? In that case (9) is still true even when Mary is deterministic. In any case the language of choice will be useful in some applications and not useful in others. It useful to talk about, and think in terms of, choices when designing a computer program for playing chess. The language of choice is not useful when designing a calculator.
The Language of Sentience. Now consider words like “believes”, “wants”, “likes” and “trying”. We have already discussed the sentence “My GPS knows where Mary lives”. Clearly this is not attributing sentience to my GPS. But what is required for sentience words to have truth values when interpreted in their fullest sense. I take the position that an AI is actually sentient simply when attributing “actual sentience” is the most useful thing to do — the meaning is the use and meaningful statements carry truth.
Behaviorist psychologists refused to talk about mental states or internal computations in human brains on the grounds that everything should be understood in terms of stimulus-response relationships. On the other hand linguists and cognitive psychologists assume the existence of internal computations and attempt to understand and model them. Today we are faced with large language models with surprising and perhaps disturbing linguistic behavior. In contrast to behaviorist thinking, it seems important to recognize that during a dialogue a language model chatbot has an internal state — the activations of the artificial neurons in its artificial neural network. By analogy with people I call will this the mental state of the language model. In most current models the mental state of a chatbot is determined by the weights of the model and the dialogue context. One might take a behaviorist position and object that we can then just take the state to be the context (the stimulus). But if people were shown to be deterministic cognitive scientists would still be interested in their internal computations. When we ask if a model believes a certain statement we are not asking a question about the stimulus. We are asking what conclusion the model has drawn and how it will respond to a question. Also, in a model with an internal train of thought, as described below, the state depends on stochastically generated thoughts.
This mental state, this system of neural activations, is often referred to as a “black-box”. It is very difficult to interpret. However, in the current discussions of large language models such as ChatGPT and Bing I believe that it is fruitful to consider what might be contained in the mental states of language models. In particular the coherence of the text generated by the new wave of chatbots would seem to imply that their mental states incorporate some degree of understanding of the dialogue. Considering the mental states of language models provides a cognitive, anti-behaviorist, perspective.
I want to also address the question of whether language models could in principle become sentient. Of course this begs the question of what is “sentience”. When should a system of mental states causally connected to behavior be called sentient? There are various sentience-related properties that also beg for more explicit definitions. Consider “understanding”, “awareness”, “goals”, “motivation”, “feelings”, and “thoughts”. Can a chatbot have internal thoughts and be aware of them? Can a chatbot be aware of the passage of time and the current moment? Rather than try to define sentience I will discuss these related properties and leave it to the reader to decide whether it is plausible that a language model chatbot might possess these properties and whether possession of a constellation of sentience-related properties constitutes sentience.
Memory: Before discussing particular sentience-related properties I want to discuss the issue of memory. Recently there has been much interest in retrieval models. A retrieval model is given access to a corpus of knowledge such as news articles or perhaps pre-digested facts. In a retrieval dialogue model retrieval of information from a corpus is performed during the dialogue. I will call the corpus of information the model can retrieve from the memory of the model. It seems a trivial step to allow the model’s memory to include past dialogues.
Trains of Thought: Chain of thought prompting is a recent development in the interaction with language models. One asks the model to generate a sequence of reasoning steps. Here I will use the more colloquial phrase “train of thought” for the simple idea that the model can generate statements that become part of the context but are not shown to the user. A train of thought model could be made to tag the internal thought as internal so that the bot can determine that the user has not seen the model’s thoughts. All events in the dialogue can also be time stamped so that the model can observe the passage of time. During a dialogue the model has a current mental state which defines “now” where each event in the dialogue (turn or thought) could be tagged with the moment of time (the “now”) at which it occurred.
Understanding: Consider the sentence “Sally finally understood that John would never change his mind”. What does this sentence mean? It means that Sally can now make a certain set of true predictions that she would not have made before she had this understanding. To understand something is to know its consequences. Language models are not perfect at this but neither are people. Perfection is not required in the colloquial notion of what it means “to understand”. This form of understanding is important for generating coherent text and hence it seems reasonable to assume that the mental states of language models embody understanding. If its mental states embody understanding it seems reasonable to say that the language model understands.
Goals and Motivations: It is often said that the goal of a language model is to predict the next word in a corpus of text. To do this well, however, the machine must model the world being described in the language. To predict what a character in a novel will say one must understand that character. For example their goals and motivations. To generate coherent text the language model must build a representation of the context defining the goals and temperament of the characters. The text in a novel often describes an action. A full understanding of that action typically involves an understanding of the goal that it is achieves or the motivation behind it. Modeling goals and motivations seems an important part of modeling language.
A Self-Model: At the beginning of each dialogue the Bing chatbot (Sydney) is fed a rather lengthy start-up prompt describing itself. This start-up prompt seems clearly designed to provide Sydney with an understanding of itself — a self-model. Sydney’s generation of first person speech, as in “I want to x” presumably reflects an aspect of a self-model represented in its mental state. Its self-model presumably provides coherence in its self-descriptions as well as other linguistic actions such as recommendations or requests for information. Since it is trained to produce coherent text it is essentially trained to behave in accordance with a self-model. If Sydney’s self-model includes being friendly then one should expect Sydney to be friendly. It should be noted, however, that Sydney’s mental state, and perhaps its self-model, can evolve throughout the course of a dialogue.
Feelings: Feelings are closely related to goals. To generate text accurately the language model must infer feelings, such as anger or fear, as well as goals and intentions. In generating realistic first person speech, such as “I feel angry” or “I feel hungry” the language model’s mental state needs to develop a model of its own feelings. Clearly our own feelings must somehow be embodied in the neural firings that are our own mental states.
Language models model people: There is a natural tendency to assume that an artificial intelligence would be like a person. After all, people are the only instance of intelligent entities that we know. I have always thought that this anthropomorphic view of AI agents is a mistake — intelligent machines could be dramatically different from people in very fundamental ways. However, language models are trained to model people and the start-up prompt describes Sidney as a person. Hence Sidney’s self-model will be a model of a human — it will incorporate aspects of human nature compatible with the self-description given in its start-up prompt. Although its self-model may evolve over time, it will always be a model of a person. So this form of chatbot will tend to be very human-like. People can be very dangerous.
Intelligence and Hallucination: Of course a sentient machine need not be superintelligent. No one would call Bing a superintelligence. In fact Bing’s understanding seems quite limited. Understanding and intelligence seem intimately related to truth. To be intelligent is to be able to determine truth. Bing is notorious for its “hallucinations” — a tendency to confidently assert stuff it makes up. Hallucination is a failure to be faithful to the truth. Over time Models will undoubtedly improve their ability to determine truth. There are two comments I want to make here. First, populist politicians can be dangerous even when, and perhaps especially when, they have a very poor ability to determine truth. Second, if a machine ever does reach the level of superintelligence, and can really know what is true, we may all have to face the truth.
Conclusions: I personally expect that within this calendar year (2023) chatbots will emerge that fully possess the sentience-related properties described above. I will leave it the reader to decide if this actually constitutes sentience. Sentience is different from superintelligence. The nature of highly advanced intelligence is difficult to foresee. I expect that machines with general intelligence more advanced than people will emerge within this decade. Even in the absence of superintelligence the issues of AI safety are pressing. An accurate understanding of the machines we are creating is now of critical importance.
For a couple years now Michael Douglas and I have been contemplating a meaning representation — simple sentence graphs — based on breaking sentences down into simple sentence components. Over the last week or so we have been playing with chain-of-thought prompting to get GPT-3 to do semantic parsing to generate simple sentence graphs. An example with just a single verb is
We are using a chain-of-thought prompt consisting of seven examples of simple sentence parses. The training parses do not contain the word “jealous”. We follow the training parses with the input sentence and a request for a simple sentence parse for the phrase headed by “being jealous”. GPT-3 then generates a semantic parse consisting of a generic “lexical entry” together with an “episodic instantiation”. The lexical entry consists of a simple sentence specifying roles as parenthesized generic definite noun phrases. The lexical entry also contains other sentences that are likely to be true of instances of this lexical entry. The episodic instantiation specifies the particular entities and events filling the roles of the semantic lexical entry.
One can also ask GPT-3 to decide for itself what lexical entries to retrieve. For example,
when given
INPUT: Russian lawmakers Monday ratified the illegal annexation of four partially occupied Ukrainian regions.
GPT-3 generates
Retrieving lexical entries for (ratifying), (annexing), and (occupying).
(ratifying) is when (the ratifier) ratifies (the treaty); (the treaty) is a legal document that has been signed by (the ratifier) and (the other party); (the treaty) creates an agreement between (the ratifier) and (the other party).
(annexing) is when (the annexer) annexes (the territory); (the territory) is under the control of (the annexer).
(occupying) is when (the occupier) occupies (the territory); (the territory) is under the control of (the occupier).
Episodic Instantiation: (the ratifying): (the ratifier) is Russian lawmakers (the treaty) is the annexation of four partially occupied Ukrainian regions (the other party) is unknown
(the annexing): (the annexer) is Russian lawmakers (the territory) is four partially occupied Ukrainian regions
(the occupying): (the occupier) is Russian lawmakers (the territory) is four partially occupied Ukrainian regions
when given
INPUT: Rex Tillerson testified that he never asked Tom Barrack to conduct diplomacy.
GPT-3 generates
Retrieving lexical entries for (testifying), (asking to do), (conducting diplomacy).
(testifying) is when (the witness) testifies (the information) to (the court); before (the testimony), (the witness) should know (the information); before (the testimony), (the witness) is under oath; (the testimony) causes (the court) to know (the information).
(asking to do) is when (the asker) asks (the hearer) to do (the action); before (the asking), (the asker) wants (the hearer) to do (the action); (the asking) causes (the hearer) to try to do (the action).
(conducting diplomacy) is when (the diplomat) conducts diplomacy with (the other party); before (the diplomacy), (the diplomat) wants (the diplomacy) to happen; during (the diplomacy), (the diplomat) tries to resolve (the issue) with (the other party).
Episodic Instantiation:
(the testimony): (the witness) is Rex Tillerson; (the information) is that he never asked Tom Barrack to conduct diplomacy; (the court) is unknown
(the asking): (the asker) is Rex Tillerson; (the hearer) is Tom Barrack; (the action) is to conduct diplomacy.
(the diplomacy): (the diplomat) is Tom Barrack (the other party) is unknown; (the issue) is unknown
A simple sentence parse can be viewed as a graph structure (a simple sentence graph) where episodic instantiations connect (instantiate) semantic lexical entries with particular entities and events. A given entity can occur in various different instantiations.
An advantage of simple sentence parsing (SSP) is that it is largely devoid of any formal linguistic theory. At the same time SSP seems to provide compelling semantic parses. At the end of this post we give the seven training parses appearing in the chain of thought text prepended to the above inputs.
I will consider three questions raised by SSP. First, do these semantic parses contribute the current debate between Yann LeCun and Gary Markus on Nativisim vs. Empiricism for symbolic processing? Second, does the fact that GPT-3 can do this suggest that GPT-3 is already doing some form of semantic parsing? Does SSP with GPT-3 in some way open GPT-3’s black box? Finally, does SSP suggest new memory-based transformer architectures?
Nativism vs. Empiricism. The issue here is whether we have to “bake in” some mechanism explicitly designed to handle symbolic reasoning. Does progress in AI require, as Marcus believes, something like the innate language faculty assumed by many linguists? Or, as LeCun believes, can symbolic reasoning emerge from deep learning alone without any prior bias? GPT-3’s ability to do semantic parsing would seem to support LeCun’s position. However GPT-3’s ability to do SSP, while good, is not perfect. Furthermore, GPT-3 training seems extremely data inefficient. Baking in symbolic reasoning might greatly reduce the data requirements. So I think the question remains open. My intuition is to agree with Marcus. However, I expect that the “language faculty” will turn out to be a deep learning architecture inspired by symbolic reasoning — a neuro-symbolic compromise between nativism and empiricism.
Does SSP open the back box of GPT-3? It is very tempting to view the above examples of semantic parses as a kind of demonstration of GPT-3’s understanding of words and how that understanding is applied to sentences. But this could easily be an illusion — an overly anthropomorphic view of GPT-3. On the other hand it seems intuitively plausible that factoring knowledge into semantic knowledge and episodic instantiations would reduce the number of parameters needed to store the knowledge. The semantic knowledge can be shared across many episodic instances. It would be somewhat surprising if GPT-3 was not doing some form of semantic-episodic factoring. Lexical semantics could be nothing more than word (or token) embeddings. GPT-3’s token embeddings have over 12 thousand dimensions — enough to store fairly elaborate lexical information.
Might SSP suggest new deep learning architectures? This is of course a difficult question. One idea is to try to design memory architectures around the separation of “semantic” and “episodic” memory. A semantic memory would hold lexical entries and facilitate few-shot learning of new words. The episodic memory would hold episodic instantiations of lexical entries. In both cases the thing remembered is the output of language processing rather than raw input text as in existing memory architectures. My intuition is that the set of memories should be a discrete set (symbols?) but that the contents of the memories should be combinations of vectors and pointers to other memories (defining a graph structure).
I will close with two simple examples showing word sense disambiguation.
When Given
INPUT: Mary painted the door red.
Retrieving lexical entry for (painting).
GPT-3 generates
(painting) is when (the painter) paints (the painting surface) with (the paint); before (the painting), (the painting surface) is a different color than (the paint); after (the painting), (the painting surface) is the same color as (the paint); during (the painting), (the painter) is applying (the paint) to (the painting surface).
But when given
Mary painted the flowers
Retrieving lexical entry for (painting).
GPT-3 generates:
(painting) is when (the painter) paints (the painting); before (the painting), (the painter) wants to paint (the painting); (the painting) is a picture of (the thing painted); after (the painting), (the painting) is finished.
The training parses prepended to these examples are given below. Davinci-002 is used with temperature 0, top P 0, frequency penalty 0 and presence penalty 0, no stop token, no start text and no restart text. The training examples can undoubtedly be improved.
ENJOY!
======== Training Parses ========
INPUT: Fred ate scrambles eggs.
Retrieving lexical entry for (eating) and (an egg)
(eating) is when (the eater) eats (the food); before (the eating), (the eater) is hungry; after (the eating), (the eater) is not hungry; after (the eating), (the food) is inside (the eater); after (the eating), (the food) is gone.
(an egg) is a means of reproduction for (the animal); (the egg) is laid by (the animal); (the egg) hatches to produce a new (the animal).
Episodic Instantiation:
(the eating): (the eater) is Fred (the food) is scrambled eggs
(the egg): (the animal) is a chicken
INPUT: George Floyd was murdered by the police.
Rretrieving lexical entry for (murdering) and (police).
(murdering) is when (the victim) is murdered by (the murderer); before (the murder), (the victim) is alive; (the murder) causes (the victim) to be dead; before (the murder), (the victim) does not want (the murder) to happen; (the murder) is a crime.
(police) are people with the authority to enforce the law.
Episodic Instantiation:
(the murder): (the victim) is George Floyd (the murderer) is the police
(the police) are unknown
INPUT: Putin told the general to attack.
Retrieving lexical entries for (telling to do) and (a general).
(telling to do) is when (the teller) tells (the hearer) to do (the action); (the teller) has authority over (the hearer); after (the telling to do), (the hearer) should do (the action).
(a general) is a person who controls an army.
Episodic Instantiation:
(the telling to do): (the teller) is Putin (the hearer) is the general (the action) is to attack
(the general) is unkown.
INPUT: Putin told the general to attack.
Retrieving lexical entry for (attacking).
(attacking) is when (the attacker) attacks (the attacked); before (the attack), (the attacked) does not want (the attack) to happen; during (the attack), (the attacker) tries to damage (the attacked); after (the attack), (the attacked) is angy at (the attacker).
Episodic Instantiation:
(the attack): (the attacker) is the general (the one attacked) is unknown
INPUT: Mary told John about the party.
Retrieving lexical entries for (telling about) and (a party).
(a telling about) is when (the teller) tells (the hearer) about (the thing); before (the telling about), (the teller) wants (the hearer) to know about (the thing); (the telling about) causes (the hearer) to know about (the thing).
(a party) is when (the partiers) get together at (the place) and (the time) to have fun; during (the party), (the partiers) have fun.
Episodic Instantiation:
(the telling about): (the teller) is Mary (the hearer) is John (the thing) is the party
(the party): (the parters) are unknown (the place) is unknown (the time) is unknown
INPUT: The principal said that the teacher had resigned when they were actually on vacation.
Retrieving lexical entries for (saying), (resigning), and (vacationing).
(saying) is when (the sayer) says (the statement) to (the hearer); before (the saying), (the sayer) wants (the hearer) to hear (the statement); (the saying) causes (the hearer) to hear (the statement); after (the saying) (the hearer) has heard (the statement).
(resigning) is when (the resigner) resigns from (the job); before (the resignation), (the resigner) has (the job); before (the resignation), (the resigner) does not want (the job); (the resignation) causes (the resigner) to not have (the job).
(vacationing) is when (the vacationer) is on vacation from (the job) and in (the location); before (the vacation), (the vacationer) wants (the vacation); before (the vacation), (the vacationer) is doing (the job); during (the vacation), (the vacationer) is not doing (the job); during (the vacation), (the vacationer) is at (the location); after (the vacation), (the vacationer) is again doing (the job).
Episodic Instantiation:
(the saying): (the sayer) is the principal (the statement) is (the teacher had resigned) (the statement) is false (the hearer) is unknown
(the resigning): (the resigner) is the teacher (the job) is teaching
(the vacationing): (the vacationer) is the teacher (the job) is same as (the job of (the resignation)) (the location) is unknown
INPUT: Herschel Walker pledges to sue over the report that he paid for an abortion.
Retrieving lexical entries for (pledging), (suing), (reporting), (paying) and (an abortion).
(pledging) is when (the pledger) pledges to do (the action); (the pledge) is a public promise by (the pledger) to do (the action).
(suing) is when (the plaintiff) sues (the defendant) over (the issue) and is decided by (the judge); (the plaintiff) wins (the lawsuit) if (the judge) rules in favor of (the plaintiff); (the defendant) wins (the lawsuit) if (the judge) rules in favor of (the defendant).
(reporting) is when (the reporter) reports (the information) to (the recipient); before (the report), (the recipient) expects (the report); before (the report), (the reporter) should make (the report); (the report) causes the (the recipient) to know (the information).
(paying) is when (the payer) pays (the amount) to (the payee) for (the thing); before (the payment), the payer has (the amount); before (the payment), (the recipient) wants (the payment); (the payment) causes (the recipient) to have (the amount).
(an abortion) is when (the woman) has (the abortion); before (the abortion), (the woman) is pregnant; before (the abortion), (the woman) wants to not be pregnant; (the abortion) causes (the woman) to not be pregnant.
Episodic Instantiation:
(the pledge): (the pledger) is Herschel Walker (the action) is to sue
(the suit): (the plaintiff) is Herschel Walker (the defendant) is unknown (the issue) is (the report) (the judge) is unknown
(the report): (the reporter) the same as (the defendant of (the report)) (the information) is that Herschel Walker paid for an abortion
(the payment): (the payer) is Herschel Walker (the payee) is unknown (the amount) is unknown (the thing) is (the abortion)
(the abortion): (the pregnant woman) is unknown (the procedure) is unknown (the pregnancy) is unknown
A recent NOEMA essay by Jacob Browning and Yann LeCun put forward the proposition that “an artificial intelligence system trained on words and sentences alone will never approximate human understanding”. I will refer to this claim as the grounding hypothesis — the claim that understanding requires grounding in direct experience of the physical world with, say, vision or manipulation, or perhaps direct experience of emotions or feelings. I have long argued that language modeling — modeling the probability distribution over texts — should in principle be adequate for language understanding. I therefore feel compelled to write a rebuttal to Browning and LeCun.
I will start with a clarification of what I mean by “understanding.” For the purposes of this essay I will define understanding (or maybe even AGI) as the ability to perform language-based tasks as well as humans. I think it is fair to say that this includes the tasks of lawyers, judges, CEOs, and university presidents. It also includes counselors and therapists whose job requires a strong understanding of the human condition. One might object that a judge, say, might in some cases want to examine some physical evidence for themself. However, the task of being a judge or therapist remains meaningful even when the interaction is limited to text and speech.[1] I am defining understanding to be the ability to do language-in/language-out tasks as well as humans.
A language-in/language-out conception of understanding seems required to make the grounding hypothesis meaningful. Of course we expect that learning to see requires training on images or that learning robot manipulation requires training on a robot arm. So the grounding hypothesis seems trivially true unless we are talking about language-in/language-out tasks such as being a competent language-in/language-out therapist or judge.
The grounding hypothesis, as stated by Browning and LeCun, is not about how children learn language. It seems clear that non-linguistic experience plays an important role in the early acquisition of language by toddlers. But, as stated, the grounding hypothesis says that no learning algorithm, no matter how advanced, can learn to understand using only a corpus of text. This is a claim about the limitations of (deep) learning.
It is also worth pointing out that the grounding hypothesis is about what training data is needed, not about what computation takes place in the end task. Performing any language-in/language-out task is, by definition, language processing independent of what kind of computation is done. Transformer models such as GPT-3 use non-symbolic deep neural networks. However, these models are clearly processing language.
Browning and LeCun argue that the knowledge underlying language understanding can only be acquired non-linguistically. For example the meaning of the phrase “wiggly line” might only be learnable from image data. The inference that “wiggly lines are not straight” could be a linguistically observable consequence of image-acquired understanding. Similar arguments can be made for sounds such as “whistle” or “major chord” vs “minor chord”.
On the surface this position seems reasonable. However, a first counterargument is simply the fact that most language involves concepts that cannot even be represented in images or sounds. As of this writing the first sentence of the first article of Google news is
FBI agents have already finished their examination of possibly privileged documents seized in an Aug. 8 search of Donald Trump’s Mar-a-Lago home, according to a Justice Department court filing Monday that could undercut the former president’s efforts to have a special master appointed to review the files.
I do not see a single word in this sentence, with the possible exception of the names Donald Trump and Mar-a-Lago, whose meaning is plausibly acquired through images. Even for the names, the sentence is completely understandable without having seen images of the person or place.
A second counterargument is that, while there may be some minor artifacts in the language of the congenitally blind[2], people who are blind from birth generally do not have any significant linguistic impairment.
Browning and LeCun discuss how people use various forms of visual input. For example IKEA assembly instructions have no words. No one is arguing that vision is useless. However, it is very limited. The old silent movies would be meaningless without the subtitles. A book, on the other hand, can give the reader a vivid human experience with no visual input whatsoever. The above sentence about Trump cannot be represented by a non-linguistic image.
Another argument given for the grounding hypothesis is that language seems more suitable for communication than for understanding. The idea is that language is good for communication because it is concise but is bad for understanding because understanding requires painstaking decompression. They go so far as to suggest that we need to study in literature classes to be able to “decompress” (deconstruct?) language. But of course preliterate societies have well developed language. Furthermore, in my opinion at least, it is exactly the abstract (concise) representations provided by language that makes understanding even possible. Consider again the above sentence about Trump.
The essay also notes that intelligence seems to be present in nonhuman animals such as corvids, octopi and primates. They seem to implicitly assume that nonhuman intelligence is non-symbolic. I find this to be speculative. Symbolic intelligence seems completely compatible with a lack of symbolic communication. Memories of discrete events and individuals seem fundamental to intelligence. Discrete representation may be a prerequisite for, rather than a consequence of, external linguistic communication.
Much of their essay focuses on the details of current language models. But we have no idea what models will appear in the future. The real question is whether large language corpora contain the information needed for understanding. If the information is there then we may someday (maybe someday soon) discover novel architectures that allow it to be extracted.
There is, for me, a clear argument that language modeling alone should ultimately be sufficient for extracting understanding. Presumably understanding is required to generate meaningful long texts such as novels. The objective of a language model is to determine the distribution of texts (such as novels). If defining the true distribution of novels requires understanding, then fully solving the language modeling problem requires the ability to understand.
Even if extracting understanding from static text proves too challenging, it could be the case that meaning can be extracted by pure language-in/language-out interaction between people and machines. Interaction is not discussed by Browning and LeCun but I would presume that they would argue that something other than language, even interactive language, is required for learning meaning.
I strongly expect that the grounding hypothesis will turn out to be false and that deep learning will prevail. However, I can accept the grounding hypothesis as an open empirical question — a question that seems very hard to settle. Constructing a competent artificial judge using image data would not prove that image data is required. Ideally we would like to find some meaningful language-in/language-out evaluation of understanding. We could then track the state-of-the-art performance of various systems and see if image data is needed. All the evidence thus far indicates that language data alone suffices for language-based measures of understanding.
[1] I think we should consider speech corpora to be “language data”. The emotional content of text should be learnable from text alone but to learn to express emotion in speech will require some amount of speech data.
[2]It has been shown that the congenitally blind have similarity judgements between different kinds of fruit that do not take color into account as much as do sighted people.
This spring I had a disagreement with an old friend about AGI. They claimed there was essentially no chance of AGI arriving in the next, say, fifty years. I have always said we just don’t know. They also wanted a definition of “AGI”. I said I would consider AGI to have arrived when a majority of the US population takes AI agents to be sentient after speaking with them for at least several months. Soon after that discussion Blake Lemoine claimed that the language model LaMBDA was sentient. I don’t for a moment take that claim seriously. But it did get me thinking about whether language models might start fooling more people in the near future. What might a language model five years from now be like what dangers might it present?
There are two fundamental reasons to think that language models might become operationally sentient (fooling most people) some time this decade. First, progress up to now has been very fast and is possibly accelerating. In January a prominent paper introduced an influential “chain of thought” model. While earlier proposals were similar, this particular paper seems to have driven an increased interest in having language models generate explicit reasoning before answering a question (or generating a response). Chain of thought approaches have led to significant advances on various benchmarks in the last six months. The second reason for thinking that operational sentience might arrive sooner (five or ten years) rather than later (fifty years) is the enormous amount of research effort being devoted to this endeavor.
Let me try to paint a picture of a future large language model (LLM). I expect the LLM to have long term memory. This will including a memory of all the conversations it has had and when it had them. An enormous amount of research has been and is continuing to be done into the incorporation of memory into language models. I also expect the LLM to include some form of chain-of-thought. It will have a total memory of its internal thoughts (internally generated sentences) tagged with when those thoughts occurred. The LLM will be able to honestly say things like “I was thinking this morning about what you said last night”. Third, I expect future language models to be much better at maintaining consistency in what they say. This will include consistency in how they describe the world and themselves. Blake Lemoine’s “interview” of LaMDA showed that a language model can already generate a lot of compelling first person sentences — statements about what it believes and wants. Assuming memory, the things that a language model says or thinks about itself becomes part of its background knowledge — a kind of self model. The language model should be able to do a good job of seeming to be self-aware.
While I have always looked forward to the arrival of AGI, I am finding this picture of operationally sentient LLMs rather dystopian.The fundamental problem is the black-box nature of an LLM in combination with the scale of its training data. By definition a language model is trained to say what a person would say. Ultimately predicting what a person would say seems to require a model of human nature — what do we want and how does that influence what we say and believe. The language model’s self understanding will be based on its understanding of people. It seems likely, therefore, that its self model and its speech will exhibit human tendencies such as a drive for power and respect. The language model’s understanding of human nature, and hence its understanding of itself, will be buried in its many trillions of parameters and would seem to be impossible to control.
In the past I have always assumed that we could control intelligent machines by specifying a mission — the purpose of the machine. A machine with an explicit mission would not have all the self interests that complicate human relations. I have advocated the “servant mission” where each AI agent is given a mission of serving a particular individual. We could each have our own computer advocate or “advobot”. But if language models can become sufficiently human just by reading, with human nature woven into its many of trillions of parameters, control becomes much more subtle …
This year I realized that VAEs are non-parametrically consistent as models of the observed data even when the encoder is held fixed and arbitrary. This is best demonstrated with a nonstandard derivation of VAEs bypassing the ELBO.
Let range over observable data and let range over latent values. Let the encoder be defined by a probability distribution . We then have a joint distribution where is drawn from the population () and is drawn from the encoder. We let the entropies and the mutual information , , , and all be defined by this joint distribution. To derive the VAE objective we start with the following basic information theoretic equalities.
Assuming that we can sample from the encoder distribution , and that we can compute for any and , the conditional entropy can be estimated by sampling. However that is not true of or because we have no way of computing or . However, entropies defined in terms of the population can be upper bounded (and estimated) by cross-entropies and we introduce two models and with which to define cross-entropies.
Inserting these two cross entropy upper bounds (or entropy estimators) into (1) gives
The right hand side of (4) is the standard VAE objective function in terms of the prior, the encoder and the decoder. However, this derivation of the upper bound (4) from the exact equality (1) shows that we get a consistent non-parametric estimator of by optimizing the prior and posterior according to (2) and (3) while holding the encoder fixed. This follows directly from the fact that cross entropy is a consistent non-parametric estimator of entropy in the sense that . Furthermore, we expect that estimates and that estimates again independent of the choice of .
This observation gives us freedom in designing latent variable objective functions that produce useful or interpretable latent variables. We can train the prior and posterior by (2) and (3) and train the encoder by any choice of an encoder objective function. For example, a natural choice might be
The weight in (5) can be interpreted as providing a rate-distortion trade-off where the mutual information (upper bound) expresses the channel capacity (information rate) of as a communication channel for the message . This is exactly the -VAE which weights the rate by rather than the distortion by .
However, there can be different encoders achieving the same rate and distortion. The consistency of (4) independent of allows additional desiderata to be placed on the encoder. For example, we might want to be a sequence with the independent and the mutual information with evenly balanced between the yielding a VAE similar to an InfoGAN.
Here we are designing different objectives for different model components — the objectives defined by (2) and (3) for and are intended to be independent of any designed objective for and the objective for can be designed independent of (2) and (3). Multiple objective functions yield a multiplayer game with Nash equilibria. In practice we will need to insert stop gradients to prevent, for example, the objective for (player) from interfering with the objective for (player) and vice-versa.
The bottom line is that we can select any objective for the encoder while preserving non-parametric consistency of the VAE as a model of the observed data.
While teaching reinforcement learning I kept asking myself what AlphaZero teaches us about RL. That question has lead to this post. This post generalizes AlphaZero to a larger class of RL algorithms by reinterpreting AlphaZero’s policy network as a belief function — as the probability that is the optimal action at state . This gives rise to a “belief gradient” algorithm.
A fundamental question is whether belief gradient is a better conceptual framework for RL than policy gradient. I have always felt that there is something wrong with policy gradient methods. The optimal policy is typically deterministic while policy gradient methods rely on significant exploration (policy stochasticity) to compute a gradient. It just seems paradoxical. The belief gradient approach seems to resolve this paradox.
The action belief function and a belief gradient algorithm. For a given state in a given Markov decision process (MDP) with a finite action space there exists a deterministic optimal policy mapping each state to an optimal action . For each decision (in life?) there is some best choice that is generally impossible to know. I propose reinterpreting AlphaZero’s policy network as giving an estimator for the probability that is the best choice — that . To make this reinterpretation explicit I will change notation and write for the belief that is the optimal choice. The notation is generally interpreted as specifying stochastic (erratic?) behavior.
To make the mathematics clearer I will assume that the belief is computed by a softmax
where is a vector representation of the state . The softmax is not as important here as the idea that provides only incomplete knowledge of . Further observations on are possible. For example, we can grow a search tree rooted as . For a given distribution on states we then get a distribution on the pairs . We assume that we also have some way of computing a more informed belief . AlphaZero computes a replay buffer containing pairs where the stored distribution is . Ideally the belief would match the marginal beliefs over the more informed search tree results. This motivates the following were denotes the replay buffer.
(1)
This is just the gradient of a cross-entropy loss from the replay buffer to the belief .
Some AlphaZero details. For the sake of completeness I will describe a few more details of the AlphaZero algorithm. The algorithm computes rollouts to the end of an episode (game) where each action in the rollout is selected based on tree search. Each rollout adds a set of pairs to the replay buffer where is a state in that rollout and is a recording of . Each rollout also has a reward (was the game won or lost). AlphaZero stores a second set of replay values for each rollout state state where is the reward of that rollout. The replay pairs are used to train a value function estimating the reward that will be achieved from state . The value function acts as a kind of static board evaluator in growing the tree .
Improved generality. The abstract mathematical formulation given in equation (1) is more general than tree search. In the belief we can have that is any information about that usefully augments the information provided in .
A belief gradient theorem. While I have reinterpreted policies as beliefs, and have recast AlphaZero’s algorithm in that light, I have not provided a belief gradient theorem. The simplest such theorem is for imitation learning. Assume an expert that labels states with actions. Optimizing the cross-entropy loss for this labeled data yields a probability . Learning a probability does not imply that the agent should make a random choice. Belief is not the same as choice.

 where
where  is an image and
is an image and  is some textual description of the image such as “an astronaut riding a horse”. We also assume that we have a model for the marginal distribution
is some textual description of the image such as “an astronaut riding a horse”. We also assume that we have a model for the marginal distribution  — the a-priori probability of image
— the a-priori probability of image  .
.
 the distribution is the unmodified
the distribution is the unmodified  we have that
we have that  acts as an inverse temperature — larger
acts as an inverse temperature — larger  is related to the idea of “capturing the essense” of the text
is related to the idea of “capturing the essense” of the text  is the number of numbers (channels) in the representation of image
is the number of numbers (channels) in the representation of image  is the probability that a model with parameter setting
is the probability that a model with parameter setting 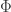 assigns to image
assigns to image ![\mathrm{Loss}(\Phi) = \frac{1}{C}\; E_{I,T \sim \mathrm{Pop}}[\;-\log_2\;P_\Phi(I|T)]](https://s0.wp.com/latex.php?latex=%5Cmathrm%7BLoss%7D%28%5CPhi%29+%3D+%5Cfrac%7B1%7D%7BC%7D%5C%3B+E_%7BI%2CT+%5Csim+%5Cmathrm%7BPop%7D%7D%5B%5C%3B-%5Clog_2%5C%3BP_%5CPhi%28I%7CT%29%5D&bg=ffffff&fg=333333&s=0&c=20201002)
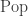 ) on
) on  ) as does guidance (as a function of guidance strength
) as does guidance (as a function of guidance strength 
 range over observable data and let
range over observable data and let  range over latent values. Let the encoder be defined by a probability distribution
range over latent values. Let the encoder be defined by a probability distribution  . We then have a joint distribution
. We then have a joint distribution  where
where 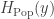 ,
, 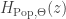 ,
, 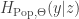 ,
,  and
and  all be defined by this joint distribution. To derive the VAE objective we start with the following basic information theoretic equalities.
all be defined by this joint distribution. To derive the VAE objective we start with the following basic information theoretic equalities.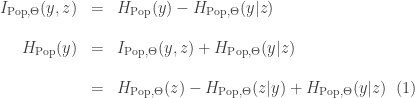
 or
or 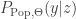 . However, entropies defined in terms of the population can be upper bounded (and estimated) by cross-entropies and we introduce two models
. However, entropies defined in terms of the population can be upper bounded (and estimated) by cross-entropies and we introduce two models  and
and  with which to define cross-entropies.
with which to define cross-entropies.
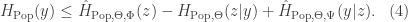
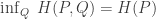 . Furthermore, we expect that
. Furthermore, we expect that 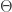 .
.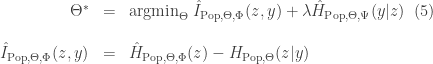
 in (5) can be interpreted as providing a rate-distortion trade-off where the mutual information (upper bound) expresses the channel capacity (information rate) of
in (5) can be interpreted as providing a rate-distortion trade-off where the mutual information (upper bound) expresses the channel capacity (information rate) of  -VAE which weights the rate by
-VAE which weights the rate by  with the
with the 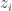 independent and the mutual information with
independent and the mutual information with 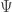 are intended to be independent of any designed objective for
are intended to be independent of any designed objective for  is the optimal action at state
is the optimal action at state  . This gives rise to a “belief gradient” algorithm.
. This gives rise to a “belief gradient” algorithm. there exists a deterministic optimal policy
there exists a deterministic optimal policy  mapping each state to an optimal action
mapping each state to an optimal action  . For each decision (in life?) there is some best choice that is generally impossible to know. I propose reinterpreting AlphaZero’s policy network
. For each decision (in life?) there is some best choice that is generally impossible to know. I propose reinterpreting AlphaZero’s policy network  as giving an estimator for the probability that
as giving an estimator for the probability that  is the best choice — that
is the best choice — that 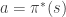 . To make this reinterpretation explicit I will change notation and write
. To make this reinterpretation explicit I will change notation and write  for the belief that
for the belief that 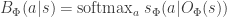
 is a vector representation of the state
is a vector representation of the state  rooted as
rooted as 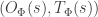 . We assume that we also have some way of computing a more informed belief
. We assume that we also have some way of computing a more informed belief  . AlphaZero computes a replay buffer containing pairs
. AlphaZero computes a replay buffer containing pairs  where the stored distribution
where the stored distribution  is
is  . Ideally the belief
. Ideally the belief 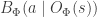 would match the marginal beliefs over the more informed search tree results. This motivates the following were
would match the marginal beliefs over the more informed search tree results. This motivates the following were  denotes the replay buffer.
denotes the replay buffer.
 to the replay buffer where
to the replay buffer where  (was the game won or lost). AlphaZero stores a second set of replay values
(was the game won or lost). AlphaZero stores a second set of replay values 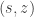 for each rollout state state
for each rollout state state  estimating the reward that will be achieved from state
estimating the reward that will be achieved from state 