| CARVIEW |
Select Language
HTTP/1.1 200 OK
Date: Wed, 31 Dec 2025 23:52:41 GMT
Server: Apache
Last-Modified: Fri, 01 May 2020 20:17:13 GMT
ETag: "39b6-5a49bdded7eb4-gzip"
Accept-Ranges: bytes
Vary: Accept-Encoding
Content-Encoding: gzip
Content-Length: 3929
Content-Type: text/html
ICLR: A Closer Look at Deep Policy Gradients

A Closer Look at Deep Policy Gradients
Andrew Ilyas, Logan Engstrom, Shibani Santurkar, Dimitris Tsipras, Firdaus Janoos, Larry Rudolph, Aleksander Madry
Keywords: optimization, policy gradient, reinforcement learning
Monday: Reliable RL
Abstract:
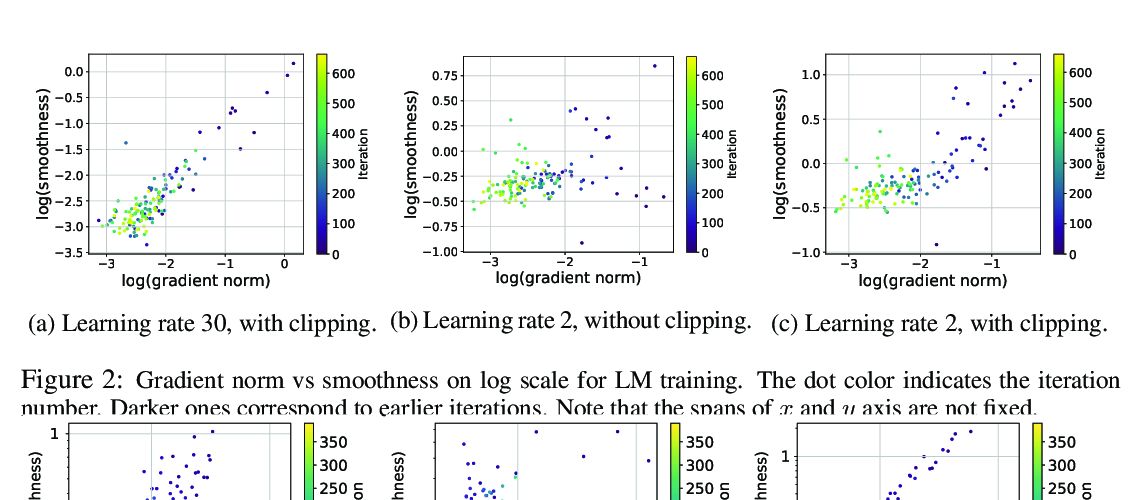
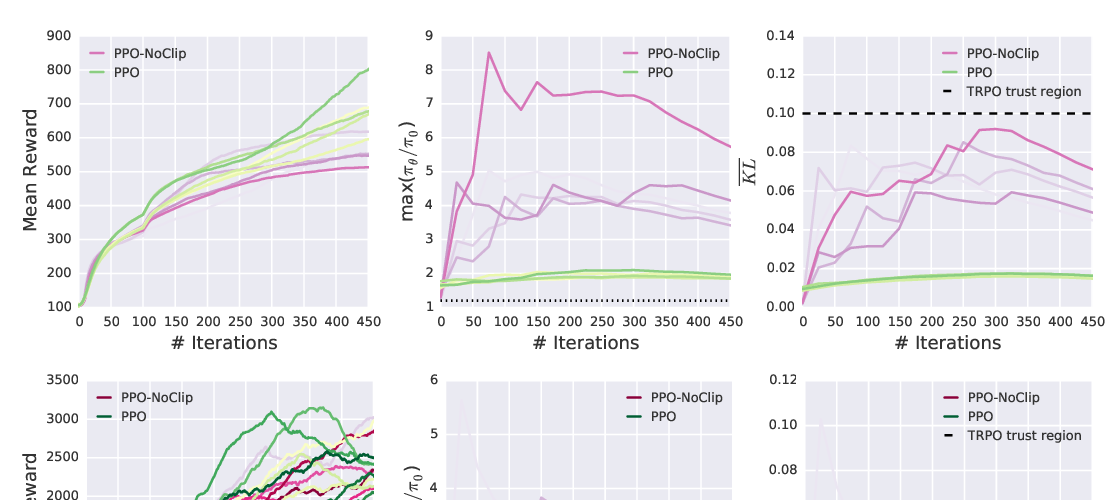
We study how the behavior of deep policy gradient algorithms reflects the conceptual framework motivating their development. To this end, we propose a fine-grained analysis of state-of-the-art methods based on key elements of this framework: gradient estimation, value prediction, and optimization landscapes. Our results show that the behavior of deep policy gradient algorithms often deviates from what their motivating framework would predict: surrogate rewards do not match the true reward landscape, learned value estimators fail to fit the true value function, and gradient estimates poorly correlate with the "true" gradient. The mismatch between predicted and empirical behavior we uncover highlights our poor understanding of current methods, and indicates the need to move beyond current benchmark-centric evaluation methods.
Similar Papers
Why Gradient Clipping Accelerates Training: A Theoretical Justification for Adaptivity
Jingzhao Zhang, Tianxing He, Suvrit Sra, Ali Jadbabaie,
Implementation Matters in Deep RL: A Case Study on PPO and TRPO
Logan Engstrom, Andrew Ilyas, Shibani Santurkar, Dimitris Tsipras, Firdaus Janoos, Larry Rudolph, Aleksander Madry,
Neural Policy Gradient Methods: Global Optimality and Rates of Convergence
Lingxiao Wang, Qi Cai, Zhuoran Yang, Zhaoran Wang,