| CARVIEW |
Efficient AI Computing,
Transforming the Future.
Who We Are
Welcome to MIT HAN Lab! We specialize in efficient generative AI, including large language models (LLMs), multi-modal models (VLMs/VLAs), and diffusion models. Today’s foundation models are remarkably powerful but prohibitively costly in terms of computation, energy, and scalability. At MIT HAN Lab, we integrate algorithm–system co-design to push the frontier of AI efficiency and performance. Our research spans the entire AI stack—from pre-training and post-training to model compression and deployment—bridging fundamental breakthroughs with real-world applications. By rethinking how AI is designed with GPU efficiency in mind, we aim to make generative AI faster, greener, and more accessible.
Alumni: Ji Lin (OpenAI), Hanrui Wang (Co-Founder @Eigen AI), Zhijian Liu (assistant professor @UCSD), Han Cai (NVIDIA Research), Haotian Tang (Google Deepmind->Meta), Yujun Lin (NVIDIA Research), Wei-Chen Wang (Co-Founder @Eigen AI), Wei-Ming Chen (NVIDIA).
Highlights
Accelerating LLM and Generative AI [slides]:
- LLM Quantization: AWQ, TinyChat enables on-device LLM inference with 4bit quantization (best paper award at MLSys'24), with 19 million downloads on HuggingFace. SmoothQuant is a training-free and accuracy-preserving 8-bit post-training quantization (PTQ) solution for LLMs. QServe speeds up the large scale LLM serving with W4A8KV4 quantization (4-bit weights, 8-bit activations, and 4-bit KV cache). COAT enables memory efficient FP8 training.
- Long Context LLM: StreamingLLM enables LLMs to generate infinite-length texts with a fixed memory budget by preserving the "attention sinks" in the KV-cache. StreamingVLM introduceda streaming-aware KV cache with attention sinks to enable real-time understanding of infinite video streams.Quest leverages query-aware sparsity in long-context KV cache to boost inference throughput. DuoAttention reduces both LLM's decoding and pre-filling memory and latency with retrieval and streaming heads. LServe accelerates long-context LLM serving with hardware-aware unified sparse attention framework.
- Sparse Attention: SpAtten invented cascade KV cache pruning and head pruning. XAttention accelerate long-context prefilling with block sparse attention and anti-diagnol scoring. Sparse VideoGen introduced an online profiling strategy to identify spatial-temporal sparsity and a hardware-efficient layout transformation. Radial Attention identified the Spatiotemporal Energy Decay phenomenon and proposed a corresponding O(n log n) sparse attention mechanism. Sparse VideoGen2 introduced semantic-aware permutation and efficient dynamic block size attention kernels.
- Efficient Visual Generation: HART is an autoregressive visual generation model capable of directly generating 1024×1024 images on a laptop. SANA enables 4K image synthesis under low computation, using deep compression auto-encoder (DC-AE) and linear diffusion transformer. SANA-1.5 explores efficient training scaling and inference scaling for diffusion models. SANA-Sprint is a one-step distilled diffusion model enabling real-time generation. SVDQuant further enables 4-bit diffusion models (W4A4) by absorbing the outliers with low-rank components. SANA-Video introduced the Linear Diffusion Transformer and a constant-memory KV cache. DC-VideoGen introduced a chunk-causal Deep Compression Video Autoencoder and the AE-Adapt-V adaptation strategy.
- Efficient Visual Language Models: VILA, VILA-U, LongVILA are a family of efficient visual language models for both understanding and generation. LongVILA efficiently scales to 6K frames of video.
We Work On
The incredible potential of large models in Artificial Intelligence Generated Content (AIGC), including cutting-edge technologies like Large Language Models (LLMs) and Diffusion Models, have revolutionized a wide range of applications, spanning natural language processing, content generation, creative arts, and more. However, large model size, and high memory and computational requirements present formidable challenges. We aim to tackle these hurdles head-on and make these advanced AI technologies more practical, democratizing access to these future-changing technologies for everyone.


Efficiency improvements in deep learning often start with refining algorithms, but these theoretical gains, like reducing FLOPs and model size, don't always easily lead to practical speed and energy savings. The demand arises for specialized hardware and software systems to bridge this gap. These specialized software and hardware systems create a fresh design dimension independent of the algorithm space. This opens up opportunities for holistic optimization by co-designing both the algorithm and the software/hardware systems.



News
- Oct 202610/1/2026SANA-Video: Efficient Video Generation with Block Linear Diffusion Transformerappears atto appear atIn Submission.SANA-Video is a fast, efficient diffusion model that generates high-quality, minute-long videos upto 720×1280 resolution. It uses linear attention and a constant-memory KV cache to handle long videos with fixed memory, enabling real-time (27PFS) 1 mintue video generation.
- Mar 20263/23/2026Taming the Long-Tail: Efficient Reasoning RL Training with Adaptive Drafterappears atto appear atASPLOS 2026.TLT is a lossless acceleration framework for reasoning-oriented LLM RL training, introducing adaptive speculative decoding to eliminate long-tail generation bottlenecks. It achieves over 1.7× end-to-end speedup while fully preserving model quality and producing a high-quality draft model for efficient deployment.
- Oct 202510/10/2025StreamingVLM: Real-Time Understanding for Infinite Video Streamsappears atto appear atarXiv 2025.StreamingVLM enables real-time understanding of infinite videos with low, stable latency. By aligning training on overlapped video chunks with an efficient KV cache, it runs at 8 FPS on a single H100. It achieves a 66.18% win rate vs. GPT-4o mini on a new benchmark with videos averaging over 2 hours long.
- Sep 20269/30/2026DC-VideoGen: Efficient Video Generation with Deep Compression Video Autoencoderappears atto appear atArxiv.We introduce DC-VideoGen, a post-training acceleration framework for efficient video generation with a Deep Compression Video Autoencoder and a robust adapation strategy AE-Adapt-V.
- Oct 202510/23/2025SANA-Sprint: One-Step Diffusion with Continuous-Time Consistency Distillationappears atto appear atICCV 2025.SANA-Sprint is a one-step distilled diffusion model enabling real-time generation; Deployable on laptop GPU; Top-notch GenEval & DPGBench results.
- Jul 20257/13/2025SANA-1.5: Efficient Scaling of Training-Time and Inference-Time Compute in Linear Diffusion Transformerappears atto appear atICML 2025.SANA-1.5 explores efficient training scaling and inference scaling for diffusion models; Deployable on laptop GPU; Top-notch GenEval & DPGBench results.
- Aug 20258/21/2025Jet-Nemotron: Efficient Language Model with Post Neural Architecture Searchappears atto appear atNeurIPS 2025.Jet-Nemotron is a family of hybrid models leveraging both full and linear attention, offering accuracy on par with leading full-attention LMs like Qwen3, LLama3.2, and Gemma3n. Jet-Nemotron-2B provides a 47x generation throughput speedup under a 64K context length compared to Qwen3-1.7B-Base, achieving top-tier accuracy with exceptional efficiency.
- Jul 20257/19/2025XAttention: Block Sparse Attention with Antidiagonal Scoringappears atto appear atICML 2025.A plug-and-play method that uses antidiagonal sums to efficiently identify important parts of the attention matrix, achieving up to 13.5x speedup on long-context tasks with comparable accuracy to full attention.
- Dec 202512/7/2025Radial Attention: O(nlogn) Sparse Attention with Energy Decay for Long Video Generationappears atto appear atNeurIPS 2025.A O(nlogn) Sparse Attention Mask for Long Video Generation
- Mar 20253/21/2025HART
HART has been highlighted by MIT news: AI tool generates high-quality images faster than state-of-the-art approaches!
- Dec 202412/15/2024AWQ
🔥⚡ We release TinyChat 2.0, the latest version with significant advancements in prefilling speed of Edge LLMs and VLMs, 1.5-1.7x faster than the previous version of TinyChat. Please refer to our blog for more details.
- Dec 202412/1/2024DistriFusion
DistriFusion is integrated in NVIDIA's TensorRT-LLM for distributed inference on high-resolution image generation.
- Aug 20248/1/2024AWQ
🔥 NVIDIA TensorRT-LLM, AMD, Google Vertex AI, Amazon Sagemaker, Intel Neural Compressor, FastChat, vLLM, HuggingFace TGI, and LMDeploy adopt AWQ to improve LLM serving efficiency. Our AWQ models on HuggingFace has received over 6 million downloads.
- May 20245/30/2024
Congrats on graduation! Cheers on the next move: Zhijian Liu: assistant professor at UCSD, Hanrui Wang: assistant professor at UCLA, Ji Lin: OpenAI, Han Cai: NVIDIA Research, Wei-Chen Wang (postdoc): Amazon, Wei-Ming Chen (postdoc): NVIDIA.
- Mar 20243/29/2024SmoothQuant
We show SmoothQuant can enable W8A8 quantization for Llama-1/2, Falcon, Mistral, and Mixtral models with negligible loss.
- Feb 20242/1/2024AWQ
We supported VILA Vision Languague Models in AWQ & TinyChat! Check our latest demos with multi-image inputs!
- Jan 20241/7/2024StreamingLLM
StreamingLLM is integrated by HPC-AI Tech SwiftInfer to support infinite input length for LLM inference.
- Dec 202312/15/2023StreamingLLM
StreamingLLM is integrated by CMU, UW, and OctoAI, enabling endless and efficient LLM generation on iPhone!
- Dec 202312/15/2023
Congrats Ji Lin completed and defended his PhD thesis: "Efficient Deep Learning Computing: From TinyML to Large Language Model". Ji joined OpenAI after graduation.
- Dec 202312/5/2023AWQ
AWQ is integrate by NVIDIA TensorRT-LLM, can fit Falcon-180B on a single H200GPU with INT4 AWQ, and 6.7x faster Llama-70B over A100.
- Nov 202311/1/2023AWQ
🔥 AWQ is now integrated natively in Hugging Face transformers through
from_pretrained. You can either load quantized models from the Hub or your own HF quantized models.
- Oct 202310/29/2023
- Oct 202310/9/2023StreamingLLM
Attention Sinks, an library from community enables StreamingLLM on more Huggingface LLMs. blog.
- Jul 20237/9/2023
- Jan 20231/31/2023
- Oct 202310/29/2023QuantumNASCongratsQuantumNASteam on1st Place AwardofACM Quantum Computing for Drug Discovery Conteston@ICCAD 20232023.
- Jun 20196/1/2019ProxylessNASCongratsProxylessNASteam onFirst PlaceofVisual Wake Words ChallengeonTF-lite track@CVPR2019.
- Jun 20196/9/2019CongratsHanrui WangParkteamonBest Paper AwardofICML 2019 Reinforcement Learning for Real Life Workshop.Park
- Apr 20234/29/2023CongratsHanrui WangQuantumNATteamonBest Poster Awardof2023 NSF Athena AI Institute.QuantumNAT
- Sep 20229/17/2022CongratsHanrui WangteamonBest Paper AwardofIEEE International Conference on Quantum Computing and Engineering (QCE).
- Jun 20236/15/2023CongratsSong HanEIE RetrospectiveteamonTop 5 cited papers in 50 years of ISCAof.EIE Retrospective
- May 20225/3/2022CongratsHanrui WangQuantumNASteamonBest Poster Awardof2022 NSF Athena AI Institute.QuantumNAS
- Nov 202511/24/2025A new blog postInfinite Context Length with Global but Constant Attention Memoryis published.By reducing complexity from O(N^2) to O(N), Linear Attention is the key to processing ultra-long sequences. This post explores its mathematical core—"state accumulation"—and how it unlocks infinite context for LLMs and long video generation.
- Aug 20258/22/2025A new blog postStatistics behind Block Sparse Attentionis published.A statistical model revealing how block sparse attention achieves efficiency and accuracy through learned similarity gaps.
- Aug 20258/25/2025A new blog postWhy Stacking Sliding Windows Can't See Very Faris published.A mathematical explanation of why sliding window attention's effective receptive field is O(W) rather than the theoretical O(LW), regardless of depth, due to information dilution and exponential decay from residual connections.
- Aug 20258/7/2025A new blog postHow Attention Sinks Keep Language Models Stableis published.We discovered why language models catastrophically fail on long conversations: when old tokens are removed to save memory, models produce complete gibberish. We found models dump massive attention onto the first few tokens as "attention sinks"—places to park unused attention since softmax requires weights to sum to 1. Our solution, StreamingLLM, simply keeps these first 4 tokens permanently while sliding the window for everything else, enabling stable processing of 4 million+ tokens instead of just thousands. This mechanism is now in HuggingFace, NVIDIA TensorRT-LLM, and OpenAI's latest models.
- Jul 20257/3/2025A new blog postRadial Attention: O(nlogn) Sparse Attention for Long Video Generation with 2–4× Speedups in Training and Inferenceis published.A sparse attention mechanism with O(nlogn) computational complexity for long video generation. It can speed up both training and inference by 2–4×. The code is available at https://github.com/mit-han-lab/radial-attention
- Feb 20252/21/2025A new blog postSVDQuant Meets NVFP4: 4× Smaller and 3× Faster FLUX with 16-bit Quality on NVIDIA Blackwell GPUsis published.SVDQuant supports NVFP4 on NVIDIA Blackwell GPUs with 3× speedup over BF16 and better image quality than INT4. Try our interactive demo below or at https://svdquant.mit.edu/! Our code is all available at https://github.com/mit-han-lab/nunchaku.
- Feb 20252/10/2025A new blog postRTX 5090 Workstation Configuration Journeyis published.With the arrival of the RTX 5090, we built a high-performance workstation to maximize its AI computing potential. In this blog post, we share our experience—from overcoming setup challenges to testing its performance.
- Dec 202412/12/2024A new blog postTinyChat 2.0: Accelerating Edge AI with Efficient LLM and VLM Deploymentis published.Explore the latest advancement in TinyChat – the 2.0 version with significant advancements in prefilling speed of Edge LLMs and VLMs. Apart from the 3-4x decoding speedups achieved with AWQ quantization, TinyChat 2.0 now delivers state-of-the-art Time-To-First-Token, which is 1.5-1.7x faster than the legacy version of TinyChat.
- Nov 202411/7/2024A new blog postSVDQuant: Accurate 4-Bit Quantization Powers 12B FLUX on a 16GB 4090 Laptop with 3x Speedupis published.A new post-training training quantization paradigm for diffusion models, which quantize both the weights and activations of FLUX.1 to 4 bits, achieving 3.5× memory and 8.7× latency reduction on a 16GB laptop 4090 GPU. Code: https://www.github.com/mit-han-lab/nunchaku
- Oct 202410/10/2024A new blog postBlock Sparse Attentionis published.We introduce Block Sparse Attention, a library of sparse attention kernels that supports various sparse patterns, including streaming attention with token granularity, streaming attention with block granularity, and block-sparse attention. By incorporating these patterns, Block Sparse Attention can significantly reduce the computational costs of LLMs, thereby enhancing their efficiency and scalability. We release the implementation of Block Sparse Attention, which is modified based on FlashAttention 2.4.2.
- Mar 20243/10/2024A new blog postPatch Conv: Patch Convolution to Avoid Large GPU Memory Usage of Conv2Dis published.In this blog, we introduce Patch Conv to reduce memory footprint when generating high-resolution images. PatchConv significantly cuts down the memory usage by over 2.4× compared to existing PyTorch implementation. Code: https://github.com/mit-han-lab/patch_conv
- Feb 20242/29/2024A new blog postDistriFusion: Distributed Parallel Inference for High-Resolution Diffusion Modelsis published.In this blog, we introduce DistriFusion, a training-free algorithm to harness multiple GPUs to accelerate diffusion model inference without sacrificing image quality. It can reduce SDXL latency by up to 6.1× on 8 A100s. Our work has been accepted by CVPR 2024 as a highlight. Code: https://github.com/mit-han-lab/distrifusion
- Mar 20243/3/2024A new blog postTinyChat: Visual Language Models & Edge AI 2.0is published.Explore the latest advancement in TinyChat and AWQ – the integration of Visual Language Models (VLM) on the edge! The exciting advancements in VLM allows LLMs to comprehend visual inputs, enabling seamless image understanding tasks like caption generation, question answering, and more. With the latest release, TinyChat now supports leading VLMs such as VILA, which can be easily quantized with AWQ, empowering users with seamless experience for image understanding tasks.
- Nov 202211/28/2022A new blog postOn-Device Training Under 256KB Memoryis published.In MCUNetV3, we enable on-device training under 256KB SRAM and 1MB Flash, using less than 1/1000 memory of PyTorch while matching the accuracy on the visual wake words application. It enables the model to adapt to newly collected sensor data and users can enjoy customized services without uploading the data to the cloud thus protecting privacy.
- May 20205/22/2020A new blog postEfficiently Understanding Videos, Point Cloud and Natural Language on NVIDIA Jetson Xavier NXis published.Thanks to NVIDIA’s amazing deep learning eco-system, we are able to deploy three applications on Jetson Xavier NX soon after we receive the kit, including efficient video understanding with Temporal Shift Module (TSM, ICCV’19), efficient 3D deep learning with Point-Voxel CNN (PVCNN, NeurIPS’19), and efficient machine translation with hardware-aware transformer (HAT, ACL’20).
- Jul 20207/2/2020A new blog postAuto Hardware-Aware Neural Network Specialization on ImageNet in Minutesis published.This tutorial introduces how to use the Once-for-All (OFA) Network to get specialized ImageNet models for the target hardware in minutes with only your laptop.
- Jul 20207/3/2020A new blog postReducing the carbon footprint of AI using the Once-for-All networkis published.“The aim is smaller, greener neural networks,” says Song Han, an assistant professor in the Department of Electrical Engineering and Computer Science. “Searching efficient neural network architectures has until now had a huge carbon footprint. But we reduced that footprint by orders of magnitude with these new methods.”
- Sep 20239/6/2023A new blog postTinyChat: Large Language Model on the Edgeis published.Running large language models (LLMs) on the edge is of great importance. In this blog, we introduce TinyChat, an efficient and lightweight system for LLM deployment on the edge. It runs Meta's latest LLaMA-2 model at 30 tokens / second on NVIDIA Jetson Orin and can easily support different models and hardware.
- Jun 20236/1/2023Zhijian Liupresented "Efficient 3D Perception for Autonomous Vehicles" atCVPR Workshop on Efficient Computer Vision.VideoSlidesMediaEvent
- Nov 202411/9/2024
- Jan 20251/15/2025
- Feb 20212/10/2021
- May 20205/29/2020
- Feb 20242/13/2024
- Sep 20239/15/2023
- Nov 202311/16/2023
- Oct 202310/5/2023
- Dec 202112/8/2021
- Dec 202012/13/2020
- Nov 202011/13/2020
- Sep 20239/13/2023
- Apr 20204/23/2020
- Jun 20206/8/2020
- Apr 20204/23/2020
- Mar 20193/21/2019
- Aug 20238/7/2023
- Mar 20203/25/2020
Our Full-Stack Projects

SANA-Video: Efficient Video Generation with Block Linear Diffusion Transformer
We introduce SANA-Video, a small diffusion model that can efficiently generate videos up to 720×1280 resolution and minute-length duration. SANA-Video synthesizes high-resolution, high-quality and long videos with strong text-video alignment at a remarkably fast speed, deployable on RTX 5090 GPU. Two core designs ensure our efficient, effective and long video generation: (1) Linear DiT: We leverage linear attention as the core operation, which is more efficient than vanilla attention given the large number of tokens processed in video generation. (2) Constant-Memory KV cache for Block Linear Attention: we design block-wise autoregressive approach for long video generation by employing a constant-memory state, derived from the cumulative properties of linear attention. This KV cache provides the Linear DiT with global context at a fixed memory cost, eliminating the need for a traditional KV cache and enabling efficient, minute-long video generation. In addition, we explore effective data filters and model training strategies, narrowing the training cost to 12 days on 64 H100 GPUs, which is only 1% of the cost of MovieGen. Given its low cost, SANA-Video achieves competitive performance compared to modern state-of-the-art small diffusion models (e.g., Wan 2.1-1.3B and SkyReel-V2-1.3B) while being 16× faster in measured latency. Moreover, SANA-Video can be deployed on RTX 5090 GPUs with NVFP4 precision, accelerating the inference speed of generating a 5-second 720p video from 71s to 29s (2.4× speedup). In summary, SANA-Video enables low-cost, high-quality video generation. Code and model will be publicly released.
SANA-Video: Efficient Video Generation with Block Linear Diffusion Transformer
SANA-Video is a fast, efficient diffusion model that generates high-quality, minute-long videos upto 720×1280 resolution. It uses linear attention and a constant-memory KV cache to handle long videos with fixed memory, enabling real-time (27PFS) 1 mintue video generation.
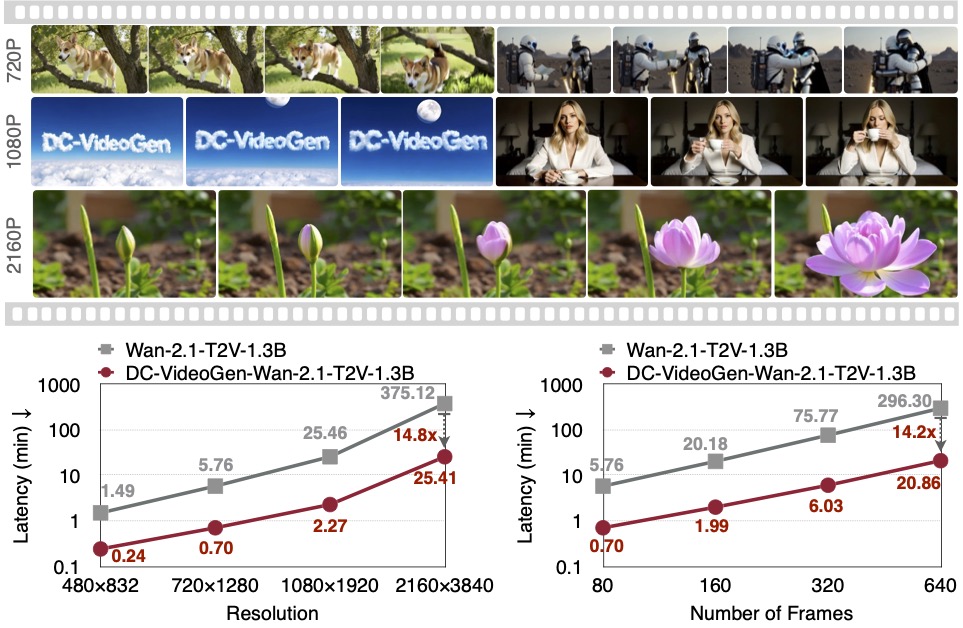
DC-VideoGen: Efficient Video Generation with Deep Compression Video Autoencoder
We introduce DC-VideoGen, a post-training acceleration framework for efficient video generation. DC-VideoGen can be applied to any pre-trained video diffusion model, improving efficiency by adapting it to a deep compression latent space with lightweight fine-tuning. The framework builds on two key innovations: (i) a Deep Compression Video Autoencoder with a novel chunk-causal temporal design that achieves 32x/64x spatial and 4x temporal compression while preserving reconstruction quality and generalization to longer videos; and (ii) AE-Adapt-V, a robust adaptation strategy that enables rapid and stable transfer of pre-trained models into the new latent space. Adapting the pre-trained Wan-2.1-14B model with DC-VideoGen requires only 10 GPU days on the NVIDIA H100 GPU. The accelerated models achieve up to 14.8x lower inference latency than their base counterparts without compromising quality, and further enable 2160x3840 video generation on a single GPU.
DC-VideoGen: Efficient Video Generation with Deep Compression Video Autoencoder
We introduce DC-VideoGen, a post-training acceleration framework for efficient video generation with a Deep Compression Video Autoencoder and a robust adapation strategy AE-Adapt-V.
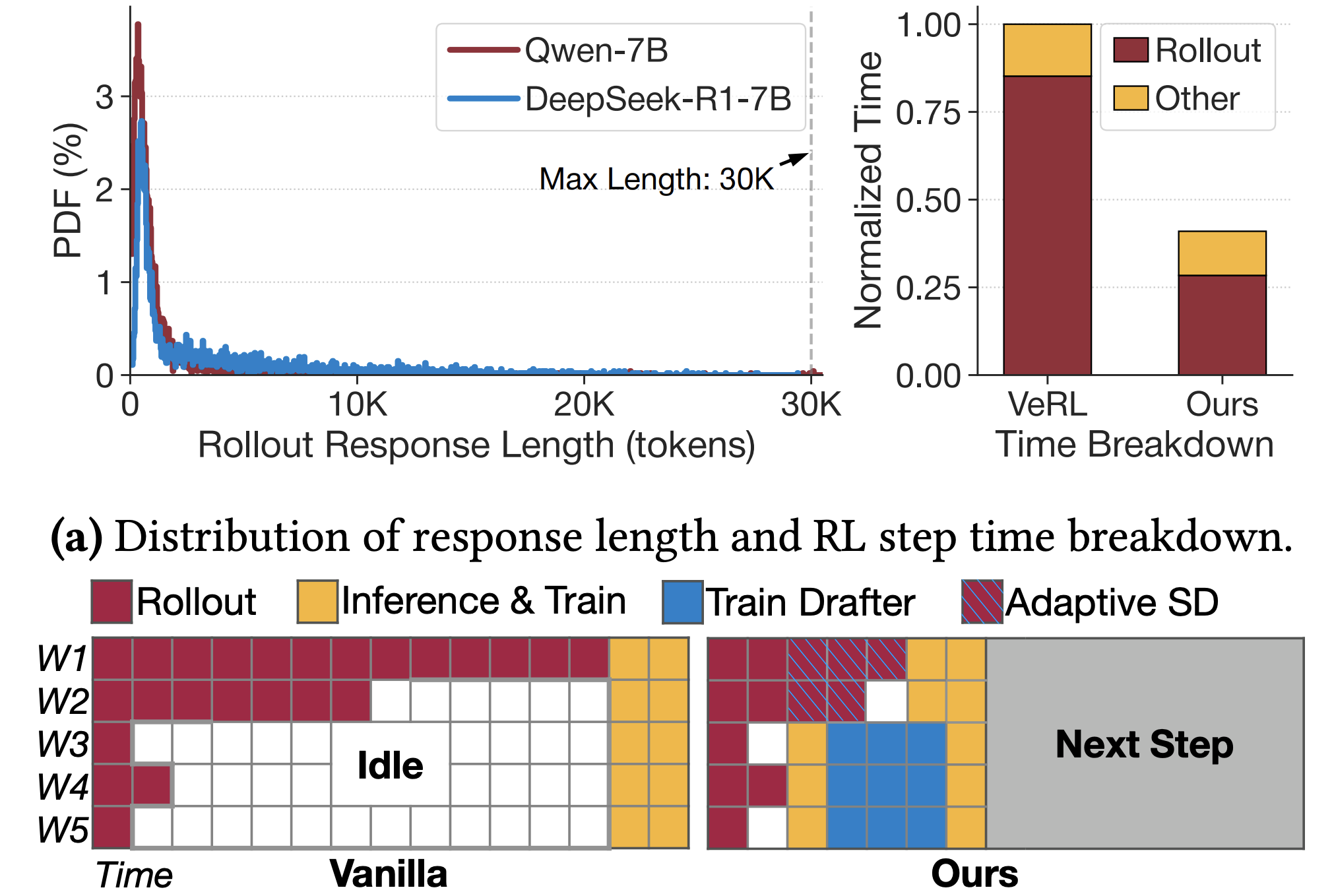
Taming the Long-Tail: Efficient Reasoning RL Training with Adaptive Drafter
The emergence of Large Language Models (LLMs) with strong reasoning capabilities marks a significant milestone, unlocking new frontiers in complex problem-solving. However, training these reasoning models, typically using Reinforcement Learning (RL), encounters critical efficiency bottlenecks: response generation during RL training exhibits a persistent long-tail distribution, where a few very long responses dominate execution time, wasting resources and inflating costs. To address this, we propose TLT, a system that accelerates reasoning RL training losslessly by integrating adaptive speculative decoding. Applying speculative decoding in RL is challenging due to the dynamic workloads, evolving target model, and draft model training overhead. TLT overcomes these obstacles with two synergistic components: (1) Adaptive Drafter, a lightweight draft model trained continuously on idle GPUs during long-tail generation to maintain alignment with the target model at no extra cost; and (2) Adaptive Rollout Engine, which maintains a memory efficient pool of pre-captured CUDAGraphs and adaptively select suitable SD strategies for each input batch. Evaluations demonstrate that TLT achieves over 1.7× end-to-end RL training speedup over state-of-the-art systems, preserves the model accuracy, and yields a high-quality draft model as a free byproduct suitable for efficient deployment.
Taming the Long-Tail: Efficient Reasoning RL Training with Adaptive Drafter
TLT is a lossless acceleration framework for reasoning-oriented LLM RL training, introducing adaptive speculative decoding to eliminate long-tail generation bottlenecks. It achieves over 1.7× end-to-end speedup while fully preserving model quality and producing a high-quality draft model for efficient deployment.

Radial Attention: O(nlogn) Sparse Attention with Energy Decay for Long Video Generation
Recent advances in diffusion models have enabled high-quality video generation, but the additional temporal dimension significantly increases computational costs, making training and inference on long videos prohibitively expensive. In this paper, we identify a phenomenon we term Spatiotemporal Energy Decay in video diffusion models: post-softmax attention scores diminish as spatial and temporal distance between tokens increase, akin to the physical decay of signal or waves over space and time in nature. Motivated by this, we propose Radial Attention, a scalable sparse attention mechanism with O(nlogn) complexity that translates energy decay into exponentially decaying compute density, which is significantly more efficient than standard O(n2) dense attention and more expressive than linear attention. Specifically, Radial Attention employs a simple, static attention mask where each token attends to spatially nearby tokens, with the attention window size shrinking with temporal distance. Moreover, it allows pre-trained video diffusion models to extend their generation length with efficient LoRA-based fine-tuning. Extensive experiments show that Radial Attention maintains video quality across Wan2.1-14B, HunyuanVideo, and Mochi 1, achieving up to a 1.9× speedup over the original dense attention. With minimal tuning, it enables video generation up to 4× longer while reducing training costs by up to 4.4× compared to direct fine-tuning and accelerating inference by up to 3.7× compared to dense attention inference.
Radial Attention: O(nlogn) Sparse Attention with Energy Decay for Long Video Generation
A O(nlogn) Sparse Attention Mask for Long Video Generation
Our Impacts
We actively collaborate with industry partners on efficient AI, model compression and acceleration. Our research has influenced and landed in many industrial products: Intel OpenVino, Intel Neural Network Distiller, Intel Neural Compressor, Apple Neural Engine, NVIDIA Sparse Tensor Core, NVIDIA TensorRT LLM, AMD-Xilinx Vitis AI, Qualcomm AI Model Efficiency Toolkit (AIMET), Amazon AutoGluon, Facebook PyTorch, Microsoft NNI, SONY Neural Architecture Search Library, SONY Model Compression Toolkit, ADI MAX78000/MAX78002 Model Training and Synthesis Tool.






















