DualDiff is a novel dual-branch conditional diffusion framework tailored for realistic and temporally consistent driving scene generation, capable of integrating multi-view semantics and video dynamics for high-fidelity outputs.
- [2025-01-28] ✨ DualDiff accepted to ICRA 2025.
- [2025-03-07] 🚀 DualDiff+ under review with extended video-level consistency modeling.
- [2025-05-07] 📂 DualDiff image generation code officially open-sourced.
Autonomous driving requires photorealistic, semantically consistent, and temporally coherent simulation of driving scenes. Existing diffusion-based generation models typically rely on coarse inputs such as 3D bounding boxes or BEV maps, which fail to capture fine-grained geometry and semantics, limiting controllability and realism.
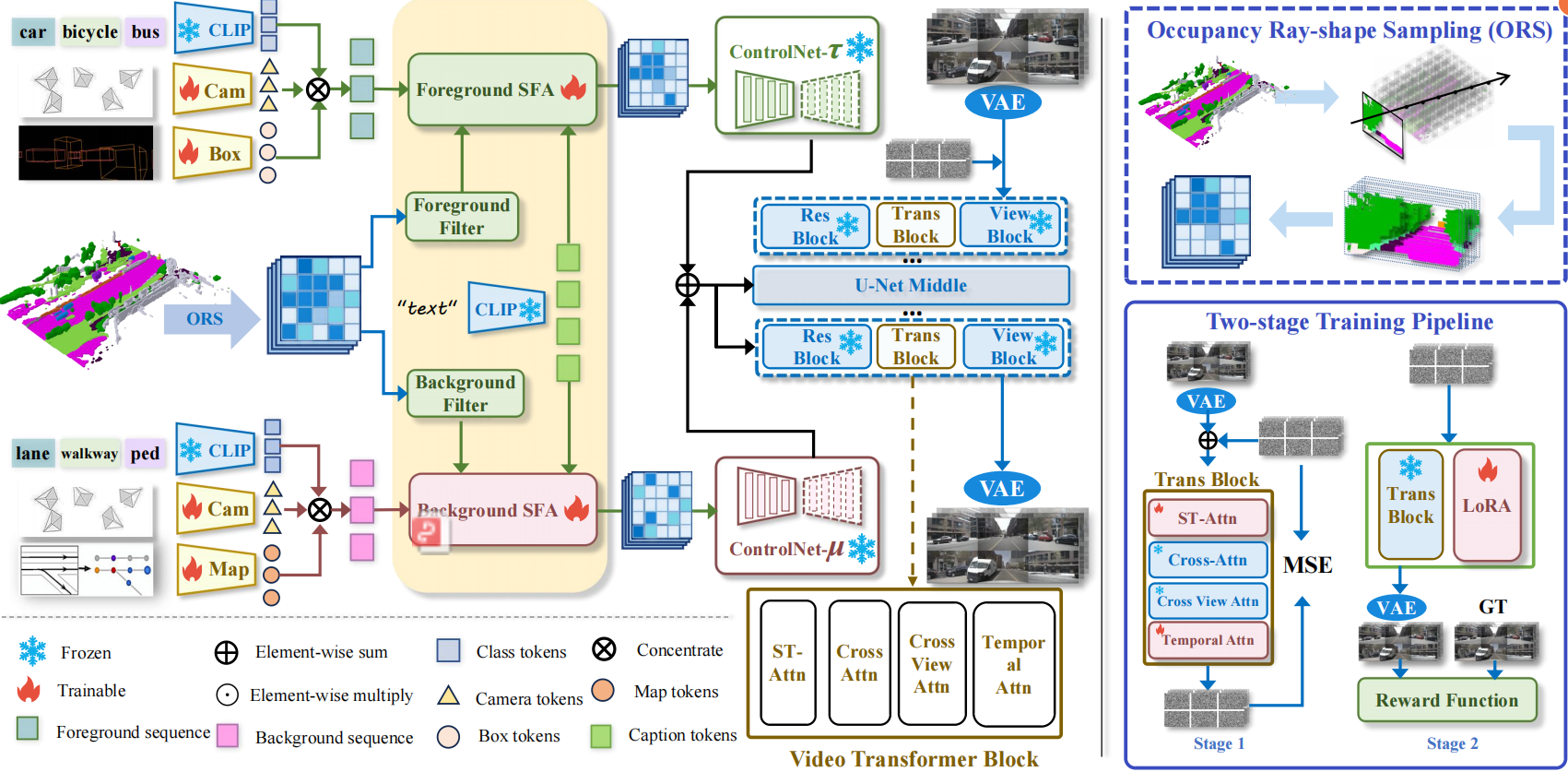
We introduce DualDiff, a dual-branch conditional diffusion model designed to enhance both spatial and temporal fidelity across multiple camera views. Our framework is characterized by the following contributions:
- Occupancy Ray-shape Sampling (ORS): A geometry-aware conditional input that encodes both foreground and background spatial context in 3D, providing dense and structured guidance.
- Foreground-Aware Masking (FGM): A denoising strategy that explicitly attends to the generation of small, complex, or distant objects in the scene.
- Semantic Fusion Attention (SFA): A dynamic attention mechanism that fuses multi-source semantic conditions, filtering irrelevant signals and enhancing scene consistency.
- Reward-Guided Diffusion (RGD): A video-level optimization framework that leverages task-specific reward signals to guide generation toward temporal and semantic coherence.
Results: DualDiff outperforms prior methods on the nuScenes dataset, achieving:
- A 4.09% FID improvement over the best previous method.
- A 4.50% gain in vehicle mIoU and 1.70% in road mIoU for downstream BEV segmentation.
- A 1.46% improvement in foreground mAP for BEV 3D object detection.
Generated scenes by DualDiff+:




DualDiff consists of a dual-stream conditional UNet where foreground and background features are processed independently and merged through residual learning.
Key architectural components:
- ORS Module: Injects fine-grained 3D-aware condition priors derived from occupancy ray-shape projections.
- SFA Mechanism: Enhances multimodal fusion using cross-attention and semantic importance weighting.
- Two-Stage Training Strategy:
- Stage 1: Spatio-temporal learning via ST-Attn and temporal attention.
- Stage 2: Fine-tuning using Reward-Guided Diffusion (RGD) and LoRA to optimize for generation quality and efficiency.
git clone --recursive https://github.com/yangzhaojason/DualDiff.gitconda create -n dualdiff python=3.8
conda activate dualdiff
pip install torch==1.10.2+cu113 torchvision==0.11.3+cu113 --extra-index-url https://download.pytorch.org/whl/cu113
pip install -r requirements/dev.txtAdditional setups:
cd third_party/xformers && pip install -e .
cd ../diffusers && pip install -e .
cd ../bevfusion && python setup.py develop- Download nuScenes dataset: link
- Structure:
data/nuscenes/
├── maps
├── mini
├── samples
├── sweeps
├── v1.0-mini
└── v1.0-trainval- Generate annotations:
python tools/create_data.py nuscenes --root-path ./data/nuscenes --out-dir ./data/nuscenes_mmdet3d_2 --extra-tag nuscenes-
Place all
.pklannotation files as instructed (see README). -
Download occ projection from Google Driver and extract the file to the root directory.
- Obtain SDv1.5 weights from Huggingface
- Follow MagicDrive setup instructions.
accelerate launch --mixed_precision fp16 --gpu_ids all --num_processes {num_gpu} tools/train.py +exp={exp_config_name} runner=8gpus runner.train_batch_size={train_batch_size} runner.checkpointing_steps=4000 runner.validation_steps=2000accelerate launch --mixed_precision fp16 --gpu_ids all --num_processes {num_gpu} perception/data_prepare/val_set_gen.py resume_from_checkpoint=magicdrive-log/{generated_folder} task_id=dualdiff_gen fid.img_gen_dir=./tmp/dualdiff_gen +fid=data_gen +exp={exp_config_name} runner.validation_batch_size=8python tools/fid_score.py cfg resume_from_checkpoint=./pretrained/SDv1.5mv-rawbox_2023-09-07_18-39_224x400 fid.rootb=tmp/dualdiff_genVisual and numerical evaluation of DualDiff on nuScenes:

@article{yang2025dualdiff+,
title={DualDiff+: Dual-Branch Diffusion for High-Fidelity Video Generation with Reward Guidance},
author={Yang, Zhao and Qian, Zezhong and Li, Xiaofan and Xu, Weixiang and Zhao, Gongpeng and Yu, Ruohong and Zhu, Lingsi and Liu, Longjun},
journal={arXiv preprint arXiv:2503.03689},
year={2025}
}@inproceedings{li2025dualdiffdualbranchdiffusionmodel,
title={DualDiff: Dual-branch Diffusion Model for Autonomous Driving with Semantic Fusion},
author={Haoteng Li and Zhao Yang and Zezhong Qian and Gongpeng Zhao and Yuqi Huang and Jun Yu and Huazheng Zhou and Longjun Liu},
booktitle={IEEE International Conference on Robotics and Automation (ICRA)},
year={2025},
pages={},
organization={IEEE},
address={},
url={https://arxiv.org/abs/2505.01857 },
}For full details, visit the project page or the GitHub repository.