Peter Kulits*, Haiwen Feng*, Weiyang Liu, Victoria Abrevaya, Michael J. Black
We present the Inverse-Graphics Large Language Model (IG-LLM) framework, a general approach to solving inverse-graphics problems. We instruction-tune an LLM to decode a visual (CLIP) embedding into graphics code that can be used to reproduce the observed scene using a standard graphics engine. Leveraging the broad reasoning abilities of LLMs, we demonstrate that our framework exhibits natural generalization across a variety of distribution shifts without the use of special inductive biases.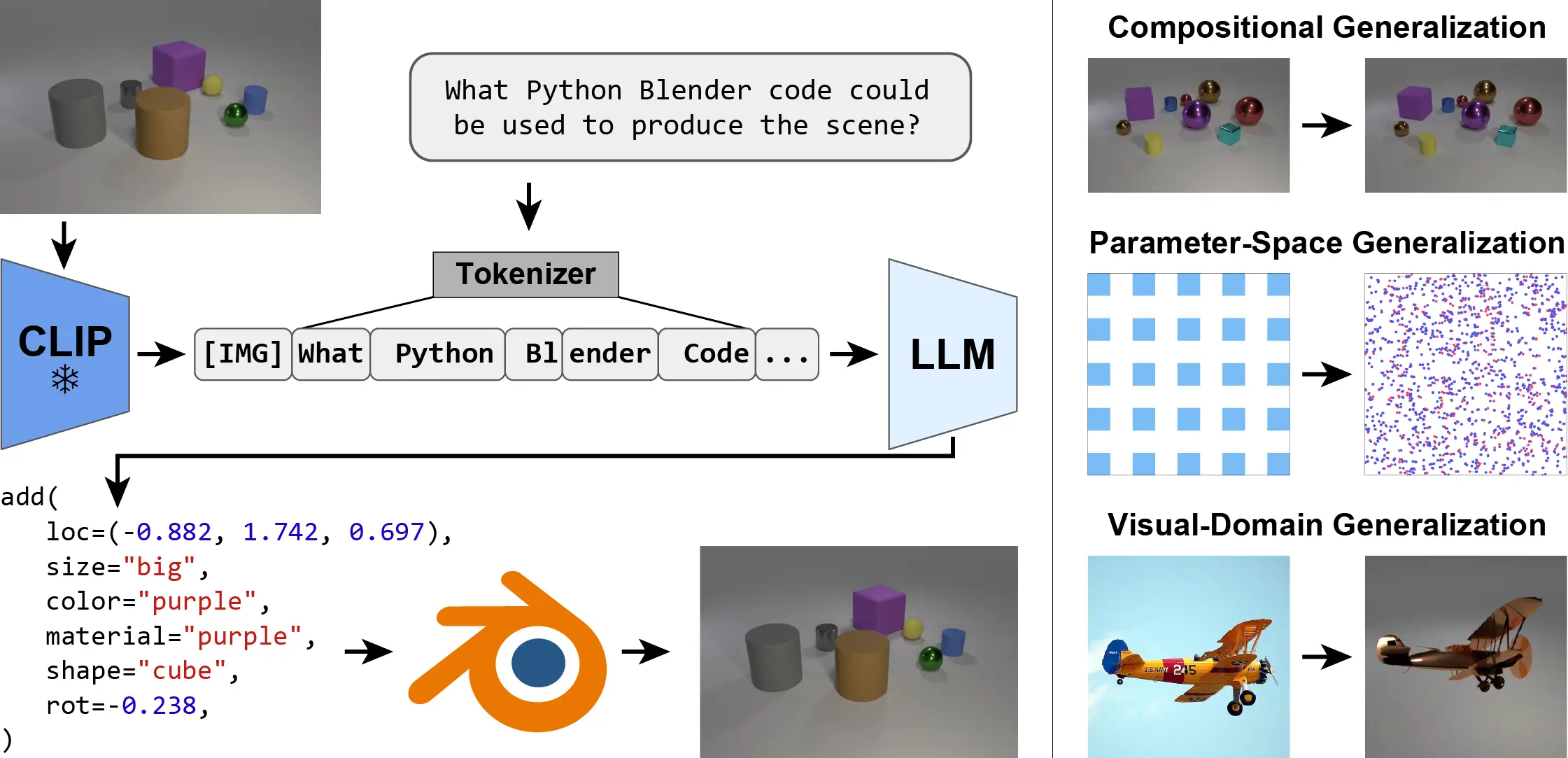
Details
├── CLEVR
│ ├── images
│ │ ├── train.tar
│ │ ├── val_ID.tar
│ │ └── val_OOD.tar
│ └── labels
│ ├── train.json
│ ├── val_ID.json
│ └── val_OOD.json
├── 2D
│ └── 2d.npz
├── SO3
│ ├── images
│ │ ├── train.tar
│ │ ├── val_ID.tar
│ │ └── val_OOD.tar
│ └── labels
│ ├── train.json
│ ├── val_ID.json
│ └── val_OOD.json
├── 6DoF
│ ├── images
│ │ ├── train.tar
│ │ └── val_ID.tar
│ └── labels
│ ├── train.json
│ └── val_ID.json
└── ShapeNet
├── images
│ ├── train.tar
│ ├── val_ID.tar
│ ├── val_OOD_texture.tar
│ └── val_OOD_shape.tar
└── labels
├── train.json
├── val_ID.json
├── val_OOD_texture.json
└── val_OOD_shape.jsonconda/micromamba from environment.yml or using the Dockerfile.
After the data has been downloaded, training can be initiated with the following:
- CLEVR
Details
python train.py \ --images_tar data/CLEVR/images/train.tar \ --data_path data/CLEVR/images/train.json \ --images_val_tar data/CLEVR/images/val_OOD.tar \ --data_path_val data/CLEVR/labels/val_OOD.json \ --per_device_train_batch_size X \ --output_dir ./checkpoints/clevr-Y \ --max_steps 40000 \ --float_head_type (none|tanh_mlp_gelu) \ --image_aspect_ratio pad \ --num_samples 4000 - 2D
Details
2d.npzis expected to be atdata/2d.npzprior to runningtrain.py.python train.py \ --data_path checkerboard_sparse \ --data_path_val random \ --per_device_train_batch_size X \ --output_dir ./checkpoints/2d-Y \ --max_steps 40000 \ --float_head_type (none|tanh_mlp_gelu) \ --image_aspect_ratio pad \ --is_2d True - SO(3)
Details
python train.py \ --images_tar data/SO3/images/train.tar \ --data_path data/SO3/images/train.json \ --images_val_tar data/SO3/images/val_OOD.tar \ --data_path_val data/SO3/labels/val_OOD.json \ --per_device_train_batch_size X \ --output_dir ./checkpoints/so3-Y \ --max_steps 40000 \ --float_head_type (none|tanh_mlp_gelu) \ --image_aspect_ratio pad \ --rotation_rep (euler_int|euler|aa|6d) - 6-DoF
Details
python train.py \ --images_tar data/6DoF/images/train.tar \ --data_path data/6DoF/images/train.json \ --images_val_tar data/6DoF/images/val_ID.tar \ --data_path_val data/6DoF/labels/val_ID.json \ --per_device_train_batch_size X \ --output_dir ./checkpoints/6dof-Y \ --max_steps 200000 \ --float_head_type (none|tanh_mlp_gelu) \ --image_aspect_ratio pad \ --rotation_rep (euler_int|euler|aa|6d) - ShapeNet
Details
python train.py \ --images_tar data/ShapeNet/images/train.tar \ --data_path data/ShapeNet/images/train.json \ --images_val_tar data/ShapeNet/images/val_OOD_texture.tar \ --data_path_val data/ShapeNet/labels/val_OOD_texture.json \ --per_device_train_batch_size X \ --output_dir ./checkpoints/shapenet-Y \ --max_steps 500000 \ --float_head_type (none|tanh_mlp_gelu) \ --image_aspect_ratio pad \ --rotation_rep (euler_int|euler|aa|6d)
python inference.py \
--model-path ./checkpoints/clevr-Y \
--images_tar data/CLEVR/images/val_OOD.tar \
--out_path ./out/clevr-Y-val_OOD.json \
--image_aspect_ratio padLICENSE.