| CARVIEW |
Dynamic, crash-proof AI orchestration
Orchestrate durable, flexible, k8s-native workflows. Trusted by 3,000+ teams to create and deploy pipelines at scale.
import pandas as pd
from flytekit import Resources, task, workflow
from sklearn.datasets import load_wine
from sklearn.linear_model import LogisticRegression
@task(requests=Resources(mem="700Mi"))
def get_data() -> pd.DataFrame:
"""Get the wine dataset."""
return load_wine(as_frame=True).frame
@task
def process_data(data: pd.DataFrame) -> pd.DataFrame:
"""Simplify the task from a 3-class to a binary classification problem."""
return data.assign(target=lambda x: x["target"].where(x["target"] == 0, 1))
@task
def train_model(data: pd.DataFrame, hyperparameters: dict) -> LogisticRegression:
"""Train a model on the wine dataset."""
features = data.drop("target", axis="columns")
target = data["target"]
return LogisticRegression(**hyperparameters).fit(features, target)
@workflow
def training_workflow(hyperparameters: dict) -> LogisticRegression:
"""Put all of the steps together into a single workflow."""
data = get_data()
processed_data = process_data(data=data)
return train_model(
data=processed_data,
hyperparameters=hyperparameters,
)import os
import flytekit
import pandas as pd
from flytekit import Resources, kwtypes, task, workflow
from flytekit.types.file import CSVFile, FlyteFile
from flytekitplugins.sqlalchemy import SQLAlchemyConfig, SQLAlchemyTask
DATABASE_URI = (
"postgresql://reader:NWDMCE5xdipIjRrp@hh-pgsql-public.ebi.ac.uk:5432/pfmegrnargs"
)
extract_task = SQLAlchemyTask(
"extract_rna",
query_template="""select len as sequence_length, timestamp from rna where len >= {{ .inputs.min_length }} and len <= {{ .inputs.max_length }} limit {{ .inputs.limit }}""",
inputs=kwtypes(min_length=int, max_length=int, limit=int),
output_schema_type=pd.DataFrame,
task_config=SQLAlchemyConfig(uri=DATABASE_URI),
)
@task(requests=Resources(mem="700Mi"))
def transform(df: pd.DataFrame) -> pd.DataFrame:
"""Add date and time columns; drop timestamp column."""
timestamp = pd.to_datetime(df["timestamp"])
df["date"] = timestamp.dt.date
df["time"] = timestamp.dt.time
df.drop("timestamp", axis=1, inplace=True)
return df
@task(requests=Resources(mem="700Mi"))
def load(df: pd.DataFrame) -> CSVFile:
"""Load the dataframe to a csv file."""
csv_file = os.path.join(flytekit.current_context().working_directory, "rna_df.csv")
df.to_csv(csv_file)
return FlyteFile(path=csv_file)
@workflow
def etl_workflow(
min_length: int = 50, max_length: int = 200, limit: int = 10
) -> CSVFile:
"""Build an extract, transform and load pipeline."""
return load(
df=transform(
df=extract_task(min_length=min_length, max_length=max_length, limit=limit)
)
)import pandas as pd
import plotly
import plotly.graph_objects as go
import pycountry
from flytekit import Deck, task, workflow, Resources
@task(requests=Resources(mem="1Gi"))
def clean_data() -> pd.DataFrame:
"""Clean the dataset."""
df = pd.read_csv("https://covid.ourworldindata.org/data/owid-covid-data.csv")
filled_df = (
df.sort_values(["people_vaccinated"], ascending=False)
.groupby("location")
.first()
.reset_index()
)[["location", "people_vaccinated", "date"]]
filled_df = filled_df.dropna()
countries = [country.name for country in list(pycountry.countries)]
country_df = filled_df[filled_df["location"].isin(countries)]
return country_df
@task(disable_deck=False)
def plot(df: pd.DataFrame):
"""Render a Choropleth map."""
df["text"] = df["location"] + "<br>" + "Last updated on: " + df["date"]
fig = go.Figure(
data=go.Choropleth(
locations=df["location"],
z=df["people_vaccinated"].astype(float),
text=df["text"],
locationmode="country names",
colorscale="Blues",
autocolorscale=False,
reversescale=True,
colorbar_title="Population",
marker_line_color="darkgray",
marker_line_width=0.5,
)
)
fig.update_layout(
title_text="Share of people who recieved at least one dose of COVID-19 vaccine",
geo_scope="world",
geo=dict(
showframe=False, showcoastlines=False, projection_type="equirectangular"
),
)
Deck("Bar Plot", plotly.io.to_html(fig))
@workflow
def analytics_workflow():
"""Prepare a data analytics workflow."""
plot(df=clean_data())Announcing Flyte 2.0
For building reliable AI/ML pipelines and agents with OSS.
Flyte 1 is available today
Get Flyte 1For building scalable, mission-critical AI systems and agents in your cloud.
Are you part of a startup?
Ask us about startup pricing.

Trusted by 3,000+ teams










Bridge the gap between scalability and ease of use

Scale compute on-demand
Scale tasks dynamically with native Kubernetes-based execution. No idle costs. No wasted cycles. Just efficient, elastic execution.
Crash-proof reliability
Automatic retries, checkpointing, and failure recovery ensure your workflows stay resilient. Stop babysitting pipelines. Flyte handles failures so you don’t have to.
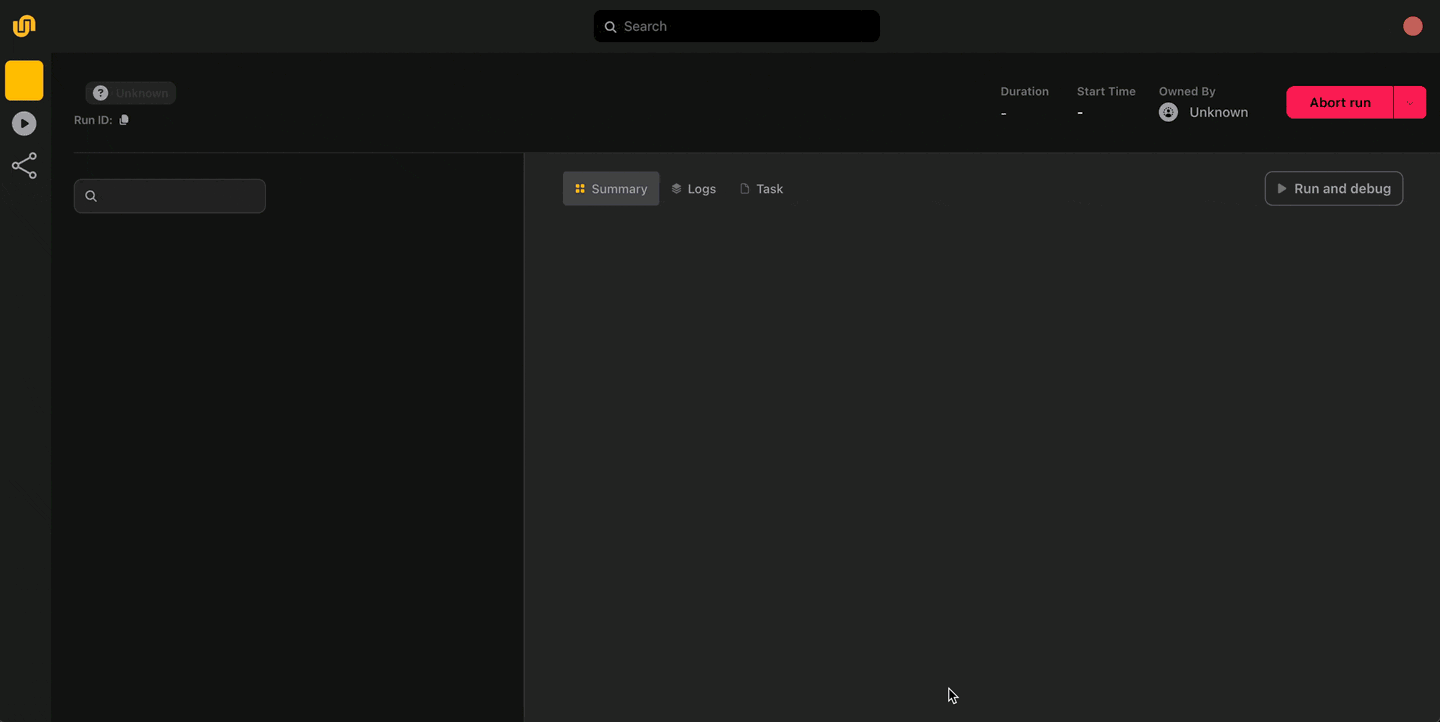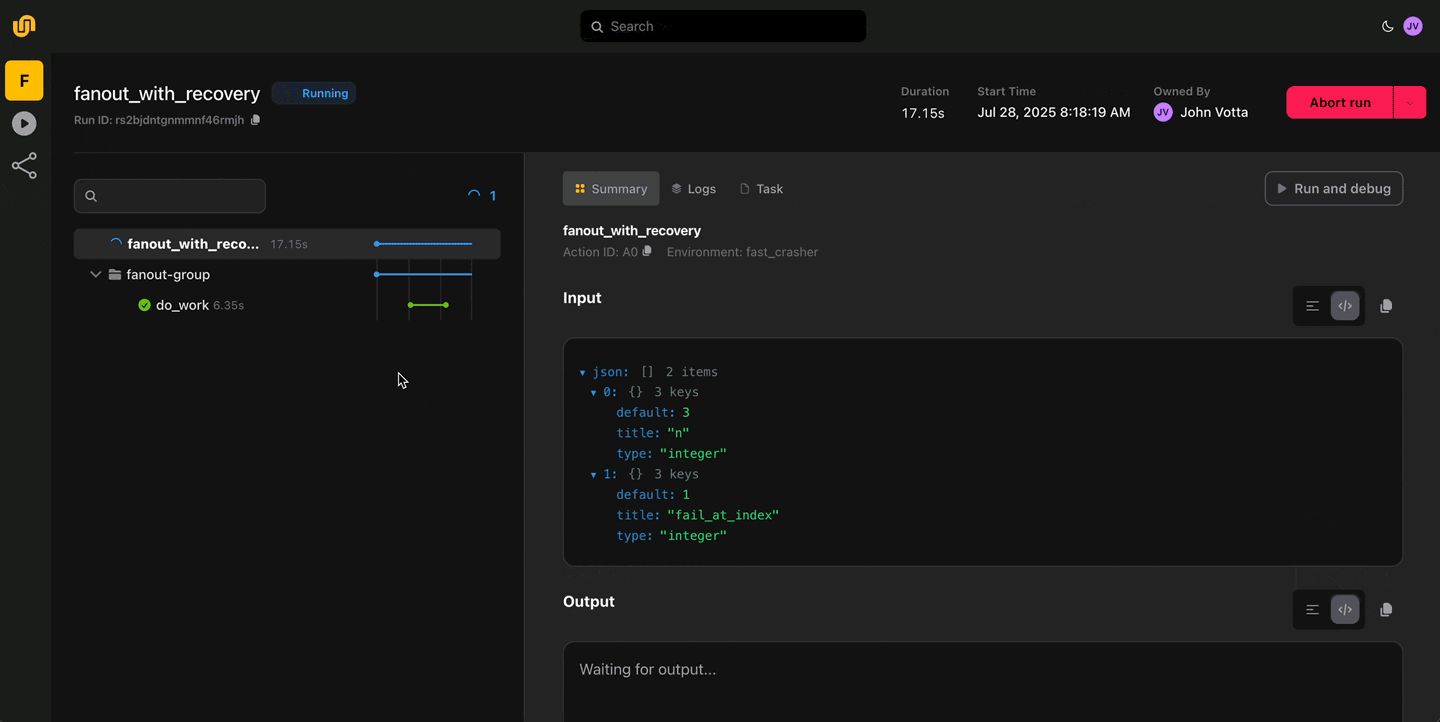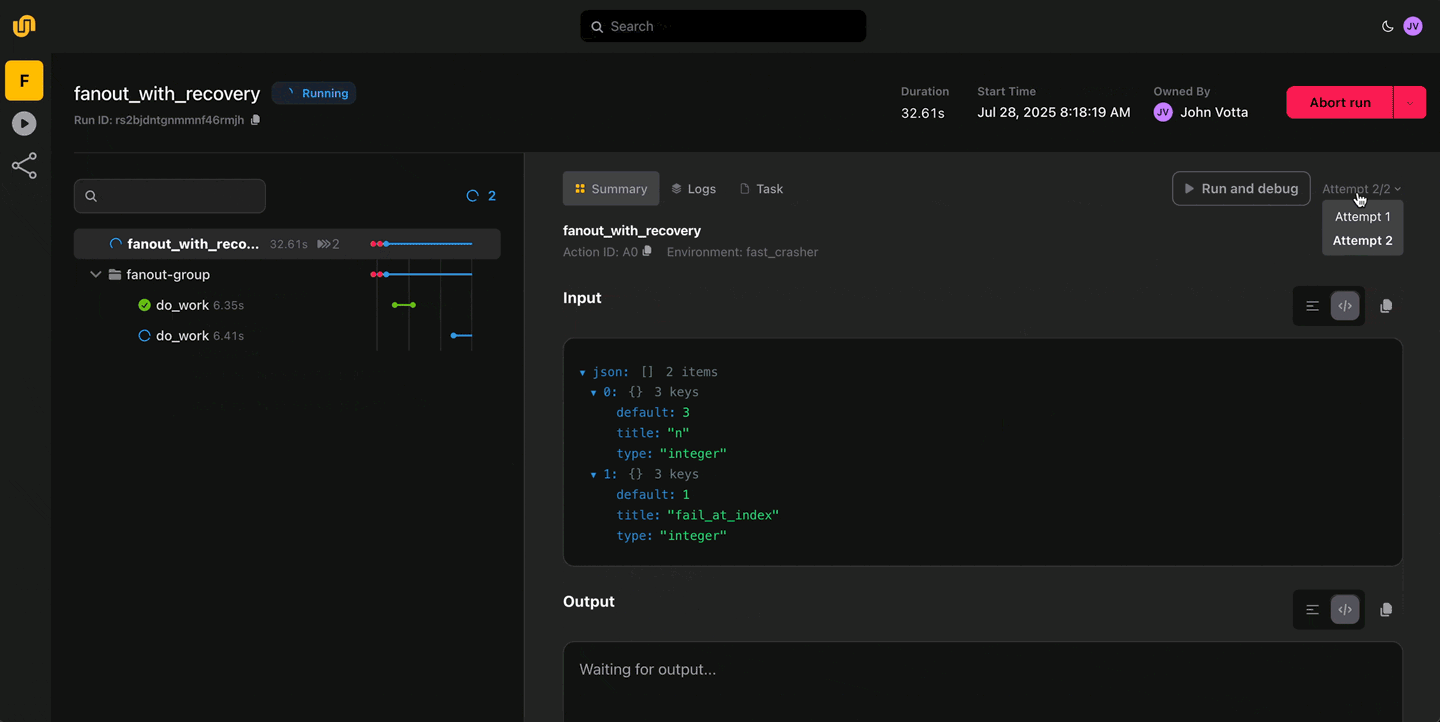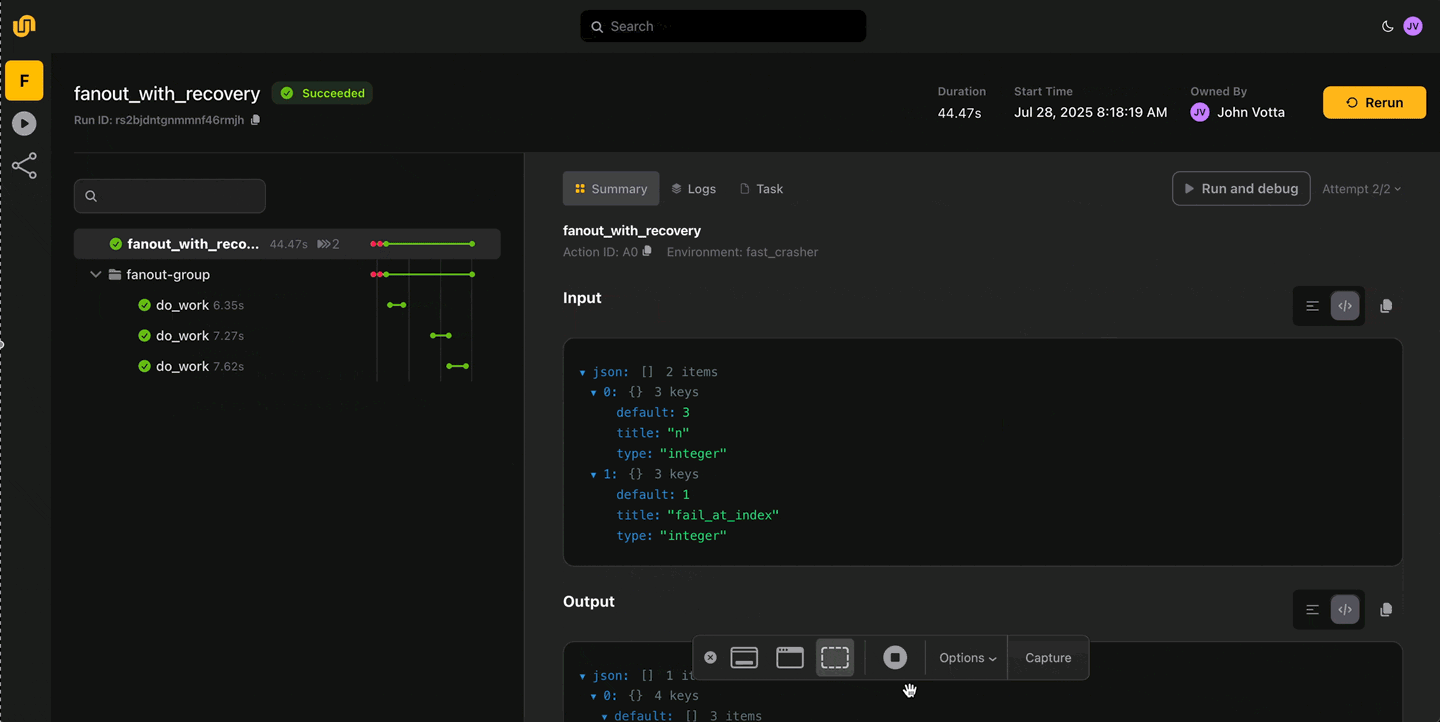


Write locally, execute remotely
Debug and iterate locally with instant feedback, then deploy the exact same code to production.
Create extremely flexible data and ML workflows
End-to-end data lineage
Track the health of your data and ML workflows at every stage of execution. Analyze data passages to identify the source of errors with ease.
Collaborate with reusable components
Reuse tasks and workflows present in any project and domain using the reference_task and reference_launch_plan decorators. Share your work across teams to test it out in separate environments.
Integrate at the platform level
Your orchestration platform should integrate smoothly with the tools and services your teams use. Flyte offers both platform- and SDK-level integrations, making it easy to incorporate into your data/ML workflows as a plug-and-play service.
Allocate resources dynamically
Resource allocation shouldn’t require complex infrastructure changes or decisions at compile time. Flyte lets you fine-tune resources from within your code — at runtime or with real-time resource calculations — without having to tinker with the underlying infrastructure.




One platform for your workflow orchestration needs
Manage the lifecycle of your workflows on a centralized platform with ease and at scale without fragmentation of tooling across your data, ML & analytics stacks.
Minimal maintenance overhead
Set up once and revisit only if you need to make Flyte more extensible.
Robust and scalable like never before
Deploy your data and ML workflows with confidence. Focus on what matters most — the business logic of your workflows.
Vibrant community
Receive timely responses to your questions on Slack, with an average response time of 6–8 hours or less.
From data processing to distributed model training, Flyte streamlines the entire data & ML workflow development process







Begin your Flyte journey today
“It’s not an understatement to say that Flyte is really a workhorse at Freenome!”
— Jeev Balakrishnan, Software Engineer at Freenome