| CARVIEW |
See part 1 (creating a working aarch64 env on Mac) and part 2 (building Glean for ARM).
In the last post we got a working Glean installation built on aarch64 with native emulation on the ARM-based M1 MacBook Air. To be useful, we need to “index” some code and store the code facts in Glean. See (What is Glean?).
Indexing is the process of analysing source code and logging the things we find. Indexers look a lot like parsers or compiler front-ends: they take source code and build up semantic information, then record it to files for ingestion into Glean, or write directly to the database.
Almost all linters, static analysis tools, compilers, transpilers, formatters parse the code, analyse and write out transformed results, usually throwing away what they learned in the process. What Glean lets us do is efficiently persist the semantic information the compiler discovered, in a way that can be very efficiently queried. We turn compilers into data sources for a distributed cache.
This splits up the usual compiler frontend <-> backend coupling, with Glean as a cache between the two phases.This lets us scale: we can index a repo frequently, and share the results with thousands of engineers, or support millions of concurrent queries to a Glean database, with very low latency. It’s like the compiler AST and type environment are now in memcache, and our IDEs and code analysis tools can hit the cache instead of painfully reconstructing the frontend themselves.
What makes a good index?
What we index is described by a Glean schema written in Angle. The schema describes the types, predicates (tables) and references between facts, as well as how they are represented. It’s broadly “pay as you go” — you don’t need to capture everything about the language, but just what you need for specific tasks. There are schemas for most common languages, as well as many mini-languages (like GraphQL, Thrift, Buck). (But n.b. there aren’t _indexers_ for most languages, just schemas. The indexers a quite a bit more work as they usually hook into custom compiler toolchains).
Common examples of things we would capture are:
- file names
- declarations, definition locations
- uses of definitions (“xrefs”)
- language elements: module names, type names, functions, methods, classes, ..
That’s usually enough to get a working navigation service up (e.g. jump-to-definition or find-references). For more sophisticated static analysis you will need to capture more of the compiler environment. It’s a good idea to float out strings and values that are repeated a lot into their own predicates, so as to maximise sharing. And to have a sense of the queries you need to write when constructing the index schema.
Once you have a schema, you can store data in that format. Indexers are standalone programs, often with no dependency on Glean itself, that parse code (and add other type information, resolve names, resolve packages), before writing out lines and lines of JSON in the schema format you specified (or writing directly to the Glean db over binary thrift).
Ok, let’s index some JavaScript
Let’s see if we can index the React codebase. React is written in JavaScript, and uses the Flow type system. Flow knows about Glean, and can be run directly as an indexer. My aim here is to use the aarch64 VM as the glean server, but the indexer can run anywhere we want — on any box. We just have to write the data into Glean on the VM. Let’s have a go at installing Flow on aarch64/Debian though, for fun, as arm64/Linux is supported by Flow.
We can build from source (needs opam/OCaml) or install a pre-built binary from https://github.com/facebook/flow/releases . I installed the binary into my aarch64 VM and we are in business:
$ flow/flow --version
Flow, a static type checker for JavaScript, version 0.169.0
We’ll need the React source , so get that. This will be our source code to index:
git clone https://github.com/facebook/react.gitInitialize flow and process the source using flow glean:
$ flow glean packages --output-dir=/tmp/flow-out/ --write-root="react"
>>> Launching report...
Wrote facts about 787 JavaScript files.And we are in business! What did we index? Have a look in /tmp/flow-out at the raw JSON. The index is in textual JSON format, and are just arrays of predicates + fact pairs. Each predicate has a set of facts associated (and facts are unique in Glean, any duplicates will be de-duped when ingested).

The whole React index is about 58M of JSON, while the raw source code was 17M. We have a few predicates defined with facts:
$ sed 's/"predicate":"\([^"]*\)",/\n\1\n/g' * | grep '^flow.' | sort | uniq
flow.DeclarationInfo.3
flow.FileOfStringModule.3
flow.ImportDeclaration.3
flow.LocalDeclarationReference.3
flow.MemberDeclarationInfo.3
flow.MemberDeclarationReference.3
flow.SourceOfExport.3
flow.SourceOfTypeExport.3
flow.TypeDeclarationInfo.3
flow.TypeDeclarationReference.3
flow.TypeImportDeclaration.3The definitions of these predicates are in flow.angle, which define all the possible predicates we might have facts for in Flow/JavaScript. Looking at the first entry in the first file:
[{"predicate":"flow.LocalDeclarationReference.3"
,"facts":[{"key":{"declaration":{"key":{"name":{"key":"ownerDocument"},"loc":{"key":{"module":{"key":{"file":{"key":"react/packages/react-devtools-shared/src/devtools/views/SearchInput.js"}}},"span":{"start":1849,"length":13}}}}},"loc":{"key":{"module":{"key":{"file":{"key":"react/packages/react-devtools-shared/src/devtools/views/SearchInput.js"}}},"span":{"start":1901,"length":13}}}}}
,{"key":{"declaration":{"key":{"name":{"key":"ownerDocument"},"loc":{"key":{"module":{"key":{"file":{"key":"react/packages/react-devtools-shared/src/devtools/views/SearchInput.js"}}},"span":{"start":1849,"length":13}}}}},"loc":{"key":{"module":{"key":{"file":{"key":"react/packages/react-devtools-sha..We can parse this fact as:
There is a “LocalDeclarationReference” of “ownerDocument’ in react/packages/react-devtools-shared/src/devtools/views/SearchInput.js at bytespan 1849, length 13. which has a reference at offset 1901.
Seems plausible. The structure of schema tells us the shape of the JSON we need to generate. E.g. LocalDeclarationReferences are bytespans associated with the use of a Declaration. Represented in Angle as::
predicate Range: {
module : Module,
span: src.ByteSpan,
}
predicate Name: string
predicate Declaration: {
name: Name,
loc: Range,
}
# connects a variable to its declaration within the same file
predicate LocalDeclarationReference: {
declaration: Declaration,
loc: Range,
}Write the data to Glean
Now let’s ingest that into Glean to query. I’ll make a directory in $HOME/gleandbs to store the Glean db images. We can install the standard schema, or just point Glean at the source. Now load all that JSON in. You can do this in parallel on multiple cores to speed things up — +RTS -N8 -A32m -RTS if it is a very, very big DB, but this is fine to run single threaded.
Our first db will be called “react” with tag “main”, but in a production setting you would probably use the commit hash as the tag to identify the data set. Glean data is immutable once the DB is finished, so its fine to use the commit hash if it is also immutable.
$ mkdir ~/gleandbs
$ glean --db-root $HOME/gleandbs --schema $HOME/Glean/glean/schema/source/ create --repo react/main /tmp/flow-out/*.json
And the Glean RTS does some work:
We can look at the DB in the glean shell:
$ glean shell --db-root $HOME/gleandbs --schema $HOME/Glean/glean/schema/source/
Glean Shell, built on 2022-01-08 07:22:56.472585205 UTC, from rev 9adc5e80b7f6f7fb9b556fbf3d7a8774fa77d254
type :help for help.
> :list
react/main (incomplete)
Created: 2022-01-12 02:01:04 UTC (3 minutes ago)
> :pager on
> :db react/main
> :statUse :stat to see a summary of the data we have stored. It’s already a basic form of code analysis:
flow.Declaration.3
count: 33527
size: 1111222 (1.06 MB) 7.1861%
flow.DeclarationInfo.3
count: 33610
size: 1177304 (1.12 MB) 7.6135%
flow.Documentation.3
count: 2215
size: 61615 (60.17 kB) 0.3985%
flow.Export.3
count: 1803
size: 53050 (51.81 kB) 0.3431%
flow.ImportDeclaration.3
count: 5504
size: 196000 (191.41 kB) 1.2675%
flow.LocalDeclarationReference.3
count: 86297
size: 2922952 (2.79 MB) 18.9024%So just basic info but the React project has 33k unique declarations, 5,500 import declarations, 86k local variable uses, 3,600 type declarations, 1,117 modules, and 904 files. You can use these summaries over time to understand code complexity growth. Things may be missing here — its up to the indexer owner to run the indexer and capture all the things that need capturing. Glean is just reporting what was actually found.
The DB is in “incomplete” state, meaning we could write more data to it (e.g. if the indexer failed part way through we could restart it and resume safely, or we could shard analysis of very large projects). But before we “finish” the DB to freeze it, we need to derive additional predicates.
Note there are some limitations here: the Glean index need to know about the JavaScript and Flow modules system (in particular, names of modules to strings, and module string names to filepaths), so that imports like ‘react’ resolve to the correct module filepath.
import {useDebugValue, useEffect, useState} from 'react';
However, if we look closely at our default Flow index, the string to file facts are all empty. This will limit our ability to see through file names imported via string names (e.g. “React.js” gets imported as ‘react’).
"predicate":"flow.FileOfStringModuleExport.3","facts":[]}
which I think means I haven’t configured Flow correctly or set up the module maps properly (halp Flow folks?).
Derived predicates in Glean
A bit like stored procedures, we can write Angle predicates that are defined in terms of other, existing predicates. This is how we do abstraction. It’s morally equivalent to defining SQL tables on the fly in terms of other tables, with some different guarantees as Glean is more like datalog than a relational system. Derived predicates can be computed on the fly, or fully generated and stored. A very common use case is to compute inverse indices (e.g. find-references is the inverse of jump-to-definition). We can index all uses of definitions, then compute the inverse by deriving.
An example is the “FileXRef” predicate in Flow, which builds an index of File name facts to cross-references in those files. You would do this to quickly discover all outbound references from a file.

This is a stored predicate. The indexer doesn’t write facts of this sort — they are defined in terms of other facts: LocalDeclarationReferences etc. To populate this index we need to derive it first. Let’s do that:
$ glean --db-root $HOME/gleandbs --schema $HOME/Glean/glean/schema/source/ derive --repo react/main flow.FileXRef
I0112 12:20:10.484172 241107 Open.hs:344] react/main: opening
I0112 12:20:10.526576 241107 rocksdb.cpp:605] loadOwnershipSets loaded 0 sets, 0 bytes
I0112 12:20:10.526618 241107 Open.hs:350] react/main: opened
I0112 12:20:10.749966 241107 Open.hs:352] react/main: schema has 799 predicates
flow.FileXRef : 0 facts
I0112 12:20:11.119634 241107 Stats.hs:223] mut_lat: 59ms [59ms] mut_thp: - [-] ded_thp: - [-] dup_thp: - [-] rnm_thp: - [-] cmt_thp: - [-] ibk_mis: - [-] tbi_mis: - [-] fbi_mis: - [-] lch_mem: 0B lch_cnt: 0
I0112 12:20:11.547000 241108 rocksdb.cpp:605] loadOwnershipSets loaded 0 sets, 0 bytes
flow.FileXRef : 112662 factsWe generated 112,662 facts about cross-references. Taking a peek at the DB now with :stat
flow.FileXRef.3
count: 112662
size: 4043028 (3.86 MB) 20.7266%
We’ve increased the DB size by 3.8M. We can derive the rest of the stored predicates now and finalize the DB. Note we have to derive in dependency order, as some stored predicates depend on the results of others. I just do this in two phases:
$ glean --db-root $HOME/gleandbs --schema $HOME/Glean/glean/schema/source/ derive --repo react/main flow.NameLowerCase flow.FileDeclaration flow.FileXRef flow.FlowEntityImportUses flow.FlowTypeEntityImportUses
I0112 12:43:12.098162 241911 Open.hs:344] react/main: opening
I0112 12:43:12.141024 241911 rocksdb.cpp:605] loadOwnershipSets loaded 0 sets, 0 bytes
I0112 12:43:12.141064 241911 Open.hs:350] react/main: opened
I0112 12:43:12.322456 241911 Open.hs:352] react/main: schema has 799 predicates
I0112 12:43:12.367130 242084 Stats.hs:223] mut_lat: 112us [112us] mut_thp: - [-] ded_thp: - [-] dup_thp: - [-] rnm_thp: - [-] cmt_thp: - [-] ibk_mis: - [-] tbi_mis: - [-] fbi_mis: - [-] lch_mem: 0B lch_cnt: 0
flow.FileDeclaration : 46594 facts
flow.FileXRef : 112662 facts
flow.FlowEntityImportUses : 3022 facts
flow.NameLowerCase : 9621 facts
flow.FlowTypeEntityImportUses : 692 facts
And freeze the data.
$ glean --db-root $HOME/gleandbs --schema $HOME/Glean/glean/schema/source finish --repo react/mainI0112 12:45:54.415550 242274 Open.hs:344] react/main: openingI0112 12:45:54.451892 242274 Open.hs:350] react/main: opened I0112 12:45:54.671070 242274 Open.hs:352] react/main: schema has 799 predicates I0112 12:45:54.701830 242270 Work.hs:506] workFinished Work {work_repo = Repo {repo_name = "react", repo_hash = "main"}, work_task = "", work_parcelIndex = 0, work_parcelCount = 0, work_handle = "glean@9adc5e80b7f6f7fb9b556fbf3d7a8774fa77d254"} I0112 12:45:54.707198 242274 Backup.hs:334] thinned schema for react/main contains src.1, flow.3 I0112 12:45:54.707224 242274 Open.hs:287] updating schema for: react/main I0112 12:45:54.824131 242274 Open.hs:299] done updating schema for open DBs I0112 12:45:54.824172 242274 Backup.hs:299] react/main: finalize: finished
The db is now frozen and cannot be changed.
> :list
react/main (complete)
Created: 2022-01-12 02:01:04 UTC (45 minutes ago)
Completed: 2022-01-12 02:45:55 UTC (51 seconds ago)Poking around a Glean database
We can look at this data by querying in the Glean shell. E.g. to count all xrefs in ReactHooks.js.,
react> :limit 0
react> :count flow.FileXRef { file = "react/packages/react/src/ReactHooks.js" }
134 results, 605 facts, 2.84ms, 310224 bytes, 1032 compiled bytesTo see say, only local references, and just the names of the definitions they point at:
react> N where flow.FileXRef { file = "react/packages/react/src/ReactHooks.js", ref = { localRef = { declaration = { name = N } } } }
{ "id": 14052, "key": "deps" }
{ "id": 4327, "key": "callback" }
{ "id": 13980, "key": "dispatcher" }
{ "id": 9459, "key": "create" }
{ "id": 5957, "key": "ReactCurrentDispatcher" }
{ "id": 1353, "key": "getServerSnapshot" }
{ "id": 1266, "key": "getSnapshot" }
{ "id": 1279, "key": "subscribe" }
{ "id": 14130, "key": "initialValue" }
{ "id": 3073, "key": "init" }
{ "id": 5465, "key": "source" }...Or we could query for types used in the file:
react> N where flow.FileXRef { file = "react/packages/react/src/ReactHooks.js", ref = { typeRef = { typeDeclaration = { name = N } } } }
{ "id": 1416, "key": "T" }
{ "id": 3728, "key": "A" }
{ "id": 14493, "key": "Dispatch" }
{ "id": 14498, "key": "S" }
{ "id": 14505, "key": "I" }
{ "id": 14522, "key": "BasicStateAction" }
{ "id": 3318, "key": "ReactContext" }
{ "id": 2363, "key": "Snapshot" }
{ "id": 14551, "key": "AbortSignal" }
{ "id": 6196, "key": "Source" }
{ "id": 8059, "key": "Dispatcher" }
{ "id": 7362, "key": "MutableSourceSubscribeFn" }
{ "id": 7357, "key": "MutableSourceGetSnapshotFn" }
{ "id": 7369, "key": "MutableSource" }Ok this is starting to get useful.
We’re doing some basic code analysis on the fly in the shell. But I had to know / explore the flow schema to make these queries. That doesn’t really scale if we have a client that needs to look at multiple languages — we can’t reasonably expect the client to know how declarations and definitions etc are defined in every single language. Luckily, Glean defines abstractions for us in code.angle and codemarkup.angle to generically query for common code structures.
Querying generically
Entities are an Angle abstraction for “things that have definitions” in programming languages — like types, modules, classes etc. There are some common queries we need across any language:
- files to their cross-references , of any entity sort
- references to definitions
- definitions in this file
- entity to its definition location and file
For these common operations, a language-agnostic layer is defined in codemarkup.angle, taking care of all the subtleties resolving imports/headers/ .. for each language. E.g. for find-references, there’s a derived “EntityUses” predicate for a bunch of languages here: https://github.com/facebookincubator/Glean/blob/main/glean/schema/source/codemarkup.angle#L259
We can use this to query Flow too E.g. how many known entities are defined or declared in ReactHooks.js? 99.
react> :count codemarkup.FileEntityLocations { file = "react/packages/react/src/ReactHooks.js" }
99 results, 354 facts, 13.15ms, 9297888 bytes, 54232 compiled bytesAnd how many uses (xrefs) are in that file? 132.
:count codemarkup.FileEntityXRefLocations { file = "react/packages/react/src/ReactHooks.js" }
132 results, 329 facts, 40.44ms, 27210432 bytes, 160552 compiled bytesQuick and dirty find-references for JavaScript
So we probably have enough now to do some basic semantic code search. i.e. not just textual search like grep, but semantically precise search as the compiler would see it. Let’s pick an entity and find its references. Since React is basically purely functional programming for UIs, let’s look for how often state is used — find-references to useState.
First, we get the entity. This tells us the definition site. The Glean key of the entity is $575875. and its structure is as below. Note the compound query here (the semicolon), where I name the entity ‘E’, then filter on its body for only those ‘Es’ with the name “useState”
react> E where codemarkup.FileEntityLocations { file = "react/packages/react/src/ReactHooks.js", entity = E } ; { flow = { decl = { localDecl = { name = "useState" } } } } = E
{
"id": 575875,
"key": {
"flow": {
"decl": {
"localDecl": {
"id": 14269,
"key": {
"name": { "id": 1317, "key": "useState" },
"loc": {
"id": 14268,
"key": {
"module": {
"id": 12232,
"key": {
"file": { "id": 12231, "key": "react/packages/react/src/ReactHooks.js" }
}
},
"span": { "start": 2841, "length": 8 }Now to direct references to this elsewhere in React, we add codemarkup.EntityUses { target = E, file = F } to the query and return the files F:
react> F where codemarkup.FileEntityLocations { file = "react/packages/react/src/ReactHooks.js", entity = E } ; { flow = { decl = { localDecl = { name = "useState" } } } } = E ; codemarkup.EntityUses { target = E, file = F }
{ "id": 10971, "key": "react/packages/react/src/React.js" }
1 results, 1 facts, 9.19ms, 5460072 bytes, 8140 compiled bytes
So that finds the first-order direct reference to useState from ReactHooks.js to React.js.. To find the actual uses in the rest of the react package, we need a proper index for module names to strings, so that an import of ‘react’ can be resolved to ‘React.js’ and thus to the origin. Glean knows about this, but my indexer doesn’t have StringToModule facts — I need the flow indexer to generate these somehow.
For now, this is enough. We are alive.
In the next part I’ll look at writing a simple code search client to the Glean server running on the VM.
]]>I want to develop and use Glean on ARM as I have a MacBook Air (road warrior mode) and I’m interested in making Glean more useful for local developer IDE backends. (c.f What is Glean?)
To build Glean just read the fine instructions and fix any compilation errors, right? Actually, we need a few patches to disable Intel-specific things, but otherwise the instructions are the same. It’s a fairly normal-ish Haskell set of projects with an FFI into some moderately bespoke C++ runtime relying on folly and a few other C++ libs.
Thankfully, all the non-portable parts of Glean are easily isolated to the rts/ownership parts of the Glean database runtime. In this case “ownership” is only used for incremental updates to the database and other semi-advanced things I don’t need right now.
The only real bits of non-portable code are:
- Flags to tell folly and thrift to use haswell or corei7 (we will ignore this on non-x86_64)
- An implementation of 256-bit bitsets (via AVX).
- Use of folly/Elias-Fano coding, for efficient compression of sorted integer list or sets as offsets (how we represent ownership of facts to things they depend on).
Why is this stuff in Glean? Well, Glean is a database for storing and querying very large scale code information, represented as 64 bit keys into “tables” (predicates) which represent facts. These facts relate to each other forming DAGs. Facts are named by 64 bit key. A Glean db is millions (or billions) of facts across hundreds of predicates. I.e. lots of 64 bit values.
So we’re in classic information retrieval territory – hence the focus on efficient bit and word encodings and operations. Generally, you flatten AST information (or other code facts) into tables, then write those tables into Glean. Glean then goes to a lot of work to store that efficiently. That’s how we get the sub-millisecond query times.
What is a “fact about code”? A single true statement about the code. E.g. for a method M in file F we might have quite a lot of information:
M is a method
M is located at file F
M is located at span 102-105
M has parent P
F is a file
M has type signature T
M is referred to by file/spans (G, 107-110) and (H, 23-26)Real code bases have millions of such facts, all relating things in the code to each other – types to methods, methods to container modules, declarations to uses, definitions to declarations etc. We want that to be efficient, hence all the bit fiddling.
So let’s try to build this on non-x86 and see what breaks.
Building Glean from scratch
The normal way to build Glean is from source. There are two repos:
- Glean itself, https://github.com/facebookincubator/Glean
- hsthrift and its dependencies (i.e. folly) , https://github.com/facebookincubator/hsthrift
I’ve put some PRs up for the non-x86_64 builds, so if you’re building for ARM or something else, you’ll need these from here:
git clonehttps://github.com/donsbot/Glean.gitcd Gleangit clonehttps://github.com/donsbot/hsthrift.git
Worth doing a cabal update as well, just in case you never built Haskell stuff before.
Now we can build the dependent libraries and the thrift compiler (n.b. we need some stuff installed in /usr/local (needs sudo).
export LD_LIBRARY_PATH=/usr/local/lib:$LD_LIBRARY_PATH
export PKG_CONFIG_PATH=/usr/local/lib/pkgconfigSo let’s build thrift and folly:
cd hsthrift
./install-deps –sudoI’m doing this on the aarch64 Debian 11 image running in UTM on a Macbook Air.
Now… first time build I seem to reliably get a gcc segfault on both x86 and aarch64, which I will conveniently sidestep by running it again. This seems mildly concerning as open source thrift might be miscompiled with gcc. I should likely be using clang here.
[ 57%] Building CXX object thrift/lib/cpp2/CMakeFiles/thriftprotocol.dir/protocol/TableBasedSerializer.cpp.o
In file included from :
/usr/include/stdc-predef.h: In substitution of ‘template constexpr T apache::thrift::detail::identity(T) [with T = ]’:
/home/dons/Glean/hsthrift/fbthrift/thrift/lib/cpp2/protocol/TableBasedSerializer.cpp:37:1: required from here
/usr/include/stdc-predef.h:32:92: internal compiler error: Segmentation fault
32 | whether the overall intent is to support these features; otherwise,
| ^
Please submit a full bug report,
with preprocessed source if appropriate.
See for instructions.
make[2]: *** [thrift/lib/cpp2/CMakeFiles/thriftprotocol.dir/build.make:173: thrift/lib/cpp2/CMakeFiles/thriftprotocol.dir/protocol/TableBasedSerializer.cpp.o] Error 1
Vanilla Debian gcc.
$ gcc --version
gcc (Debian 10.2.1-6) 10.2.1 20210110
That really looks like a gcc bug and probably other things lurking there. Urk. Re-run the command and it seems to make progress. Hmm. Compilers in memory-unsafe languages eh? Moving along quickly…
Build the Glean rts and Haskell bits
Once hsthrift is built installed, we have all the various C++ deps (folly, xxhash etc). So we can try building Glean itself now. Glean is a mixture of Haskell tools over a C++ runtime. There’s a ton of schemas, bytecode generators, thrift mungers. Glean is sort of an ecosystem of indexers (analyzing code and spitting out facts as logs), a database runtime coupled to a Thrift server (“Glean” itself) and tooling for building up distributed systems around this (for restoring/ migrating/ monitoring / administering clusters of Glean services).
Building Glean .. if you get an error about missing HUnit, that means we haven’t synced the cabal package list. I got this on the first go with a blank Debian iso as the initial cabal package list is a basic one.
Resolving dependencies…
cabal: Could not resolve dependencies:
[__0] trying: fb-stubs-0.1.0.0 (user goal)
[__1] unknown package: HUnit (dependency of fb-stubs)
[__1] fail (backjumping, conflict set: HUnit, fb-stubs)
That’s fixable with a cabal update.
If you’re not using my branch, and building on non-x86 you’ll fail at the first AVX header.
Preprocessing library 'rts' for glean-0.1.0.0..
Building library 'rts' for glean-0.1.0.0..
In file included from ./glean/rts/ownership/uset.h:11,
from ./glean/rts/ownership.h:12, from glean/rts/ffi.cpp:18:0: error:glean/rts/ownership/setu32.h:11:10: error:
fatal error: immintrin.h: No such file or directory
11 | #include
Similarly, hsthrift needed some patches where the intel arch was baked in, otherwise you’ll get:
cc1plus: error: unknown value ‘haswell’ for ‘-march’
cc1plus: note: valid arguments are: armv8-a armv8.1-a armv8.2-a armv8.3-a armv8.4-a
I fixed up all the .cabal files and other bits:
$ find . -type f -exec grep -hl haswell {} \;
./hsthrift/server/thrift-server.cabal
./hsthrift/cpp-channel/thrift-cpp-channel.cabal
./hsthrift/common/util/fb-util.cabal
./glean.cabal
See this PR for the tweaks for hsthrift https://github.com/facebookincubator/hsthrift/pull/53/commits
AVX instructions
Now, Glean itself uses a whole set of AVX instructions for different things. To see what’s actually needed I added a define to conditionally compile immintrin.h on arm, and then sub out each of the methods until the compiler was happy.
$ find . -type f -exec grep -hl immintrin.h {} \;
./glean/rts/ownership/setu32.h
./glean/rts/ownership.cpp
The methods we need to stub out are:
int _mm256_testc_si256(__m256i __M, __m256i __V);int _mm256_testz_si256(__m256i __M, __m256i __V);__m256i _mm256_setzero_si256();__m256i _mm256_set1_epi32(int __A);__m256i _mm256_sllv_epi32(__m256i __X, __m256i __Y);__m256i _mm256_sub_epi32(__m256i __A, __m256i __B);__m256i _mm256_set_epi32(int __A, int __B, int __C, int __D, int __E, int __F, int __G, int __H);
Ooh AV512
long long _mm_popcnt_u64(unsigned long long __X);Also
unsigned long long _lzcnt_u64(unsigned long long __X);
__m256i _mm256_or_si256(__m256i __A, __m256i __B);__m256i _mm256_and_si256(__m256i __A, __m256i __B);
__m256i _mm256_xor_si256(__m256i __A, __m256i __B);
Figuring out what these are all used for is interesting. We have 256-bit bitsets everywhere, and e.g. 4 64 bit popcnts to count things (fact counts?).
size_t count() const {
const uint64_t* p = reinterpret_cast(&value);
// _mm256_popcnt instructions require AVX512
return
_mm_popcnt_u64(p[0]) +
_mm_popcnt_u64(p[1]) +
_mm_popcnt_u64(p[2]) +
_mm_popcnt_u64(p[3]);
}
Anyway, its relatively trivial to stub these out, match the types and we have a mocked AVX layer. Left to the reader to write a portable shim for 256 bitsets that does these things on vectors of words.
Elias Fano
So the other bit is a little more hairy. Glean uses Elias Fano to compress all these sets of 64 bit keys we have floating around. Tons of sets indicating facts are owned or related to other facts. The folly implementation of Elias Fano is x86_64 only, so just falls over on aarch64:
/usr/local/include/folly/experimental/EliasFanoCoding.h:43:2: error:
error: #error EliasFanoCoding.h requires x86_64
43 | #error EliasFanoCoding.h requires x86_64
| ^~~~~
|
43 | #error EliasFanoCoding.h requires x86_64
So hmm. Reimplement? No its Saturday so I’m going to sub this out as well, just enough to get it to compile. My guess is we don’t use many methods here, read/write/iterate and some constructors. So I copy just enough of the canonical implementation declarations and dummy bodies to get it all to go through. Hsthrift under aarch64 emulation on UMT on an arm64 M1 takes about 10 mins to build with no custom flags.
Build and test
So we should be good to go now. Compile the big thing: Glean. Some of these generated bits of schema are pretty big too.
Glean storage is described via “schemas” for languages. Schemas represent what predicates (tables and their types) we want to capture. Uniquely, Glean’s Angle language is rich enough to support abstracting over types and predicates, building up layers of API that let you hide language complexity. You can paper over differences between languages while also providing precise language-specific captur
To see an example, look at the mulit-language find-references layer in codemarkup.angle:
- One abstract (“derived”) method for fast find-references across a dozen languages: https://github.com/facebookincubator/Glean/blob/main/glean/schema/source/codemarkup.angle#L231
- Built up from language-specific queries: https://github.com/facebookincubator/Glean/blob/main/glean/schema/source/codemarkup.angle#L557
The joy of this is that a client only has to know to query codemarkup:find-references and the right query will be issued for the right language. Client doesn’t have to know language-specific stuff, its all hidden in the database engine.
But .. that does end up meaning we generate quite a lot of code. With some trial and error I needed something under 16G to compile the “codemarkup” abstraction layer (this is a language-angostic navigation layer over the Glean schemas).
make
make test
That should pass and we are in business. We can run the little hello world demo.
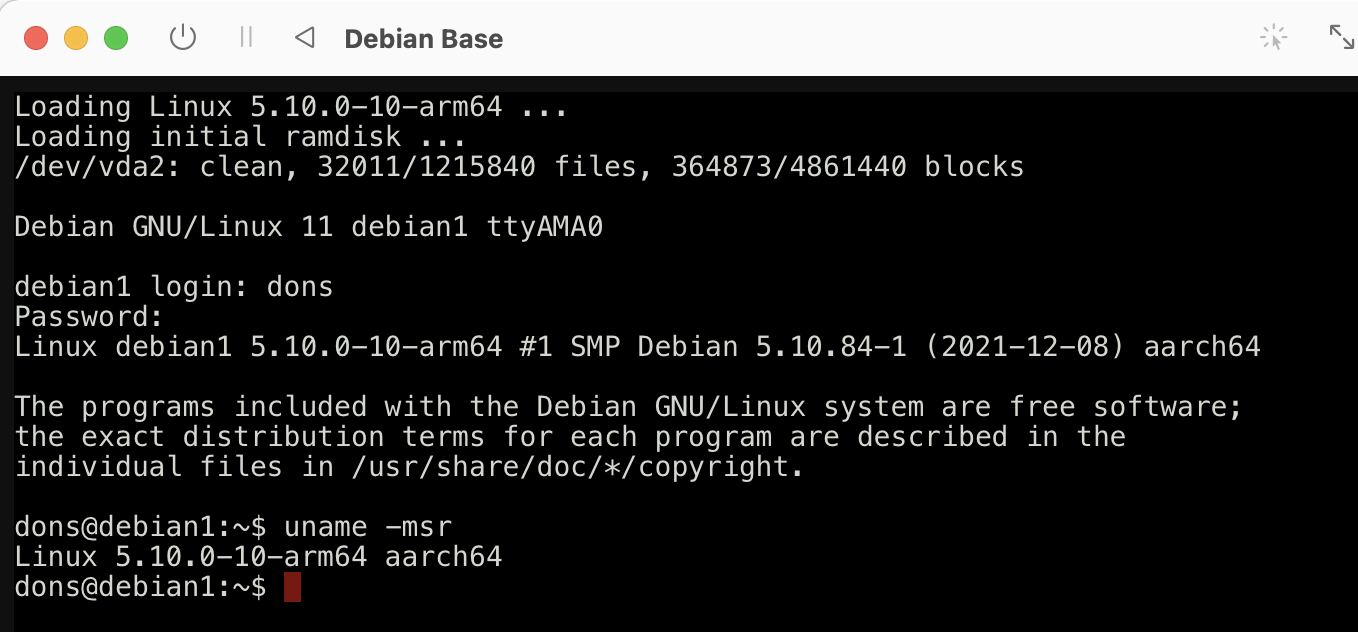
$ uname -msr
Linux 5.10.0-10-arm64 aarch64
$ glean shell --db-root /tmp/glean/db/ --schema /tmp/glean/schema/
Glean Shell, built on 2022-01-08 07:22:56.472585205 UTC, from rev 9adc5e80b7f6f7fb9b556fbf3d7a8774fa77d254
type :help for help.
Check our little db created from the walkthrough:
:list
facts/0 (complete)
Created: 2022-01-08 10:59:17 UTC (1 day, 18 hours ago)
Completed: 2022-01-08 10:59:18 UTC (1 day, 18 hours ago)
What predicates does it have?
facts> :schema
predicate example.Member.1 :
{ method : { name : string, doc : maybe string } | variable : { name : string } | }
predicate example.FileClasses.1 : { file : string, classes : [example.Class.1]
predicate example.Reference.1 :
{ file : string, line : nat, column : nat }
-> example.Class.1
predicate example.Class.1 : { name : string, line : nat }
predicate example.Parent.1 : { child : example.Class.1, parent : example.Class.1 }
predicate example.Has.1 :
{ class_ : example.Class.1, has : example.Member.1, access : enum { Public | Private | } }
predicate example.Child.1 : { parent : example.Class.1, child : example.Class.1 }
Try a query or two: e.g. “How many classes do we have?”
facts> example.Class _
{ "id": 1026, "key": { "name": "Fish", "line": 30 } }
{ "id": 1027, "key": { "name": "Goldfish", "line": 40 } }
{ "id": 1025, "key": { "name": "Lizard", "line": 20 } }
{ "id": 1024, "key": { "name": "Pet", "line": 10 } }
What is the parent of the Fish class?
facts> example.Parent { child = { name = "Fish" } }
{
"id": 1029,
"key": {
"child": { "id": 1026, "key": { "name": "Fish", "line": 30 } },
"parent": { "id": 1024, "key": { "name": "Pet", "line": 10 } }
1 results, 3 facts, 5.59ms, 172320 bytes, 1014 compiled bytes
Ok we have a working ARM64 port of Glean. In the next post I’ll look at indexing some real code and serving up queries.
]]>This post show how to get a working aarch64 env on the MacBook Air (M1) for Haskell.
I’m working on the road at the moment, so picked up a MacBook Air with the M1 chip, to travel light. I wanted to use it as a development environment for Glean (c.f. what is Glean), the code search system I work on. But Glean is a Linux/x86_64 only at the moment due to use of some fancy AVX extensions deep down in the runtime. Let’s fix that.
Motivation: getting Glean working on Apple ARM chips could be useful for a few reasons. Apple Silicon is becoming really common, and a lot of devs have MacBooks as their primary development environment (essentially expensive dumb terminals to run VS Code). Glean is/could be the core of a lot of developer environments, as it indexes source code and serves up queries extremely efficiently, so it could be killer as a local language server backend for your Mac IDE. (e.g. a common backend for all your languages, with unified search, jump-to-def, find-refs etc).
Setup up UTM
Glean is still very Linux-focused. So we need a VM. I’m building on an M1 MacBook Air (ARM64). So I install UTM from the app store or internet – this will be our fancy iOS QEMU virtualization layer.
Configure the OS image as per https://medium.com/@lizrice/linux-vms-on-an-m1-based-mac-with-vscode-and-utm-d73e7cb06133 for aarch64 debian, using https://mac.getutm.app/gallery/ubuntu-20-04 for the basic configuration.
In particular, I set up the following.
- Information -> Style: Operating system
- System -> Hardware -> Architecture: aarch64
- System -> Memory -> 16G (compiling stuff!)
- Drives -> VirtIO at least 20G, this will be the install drive and build artifacts
- Drives -> Removable USB , for the installation .iso
- Display -> console only (we’ll use ssh)
- Network -> Mode: Emulated VLAN
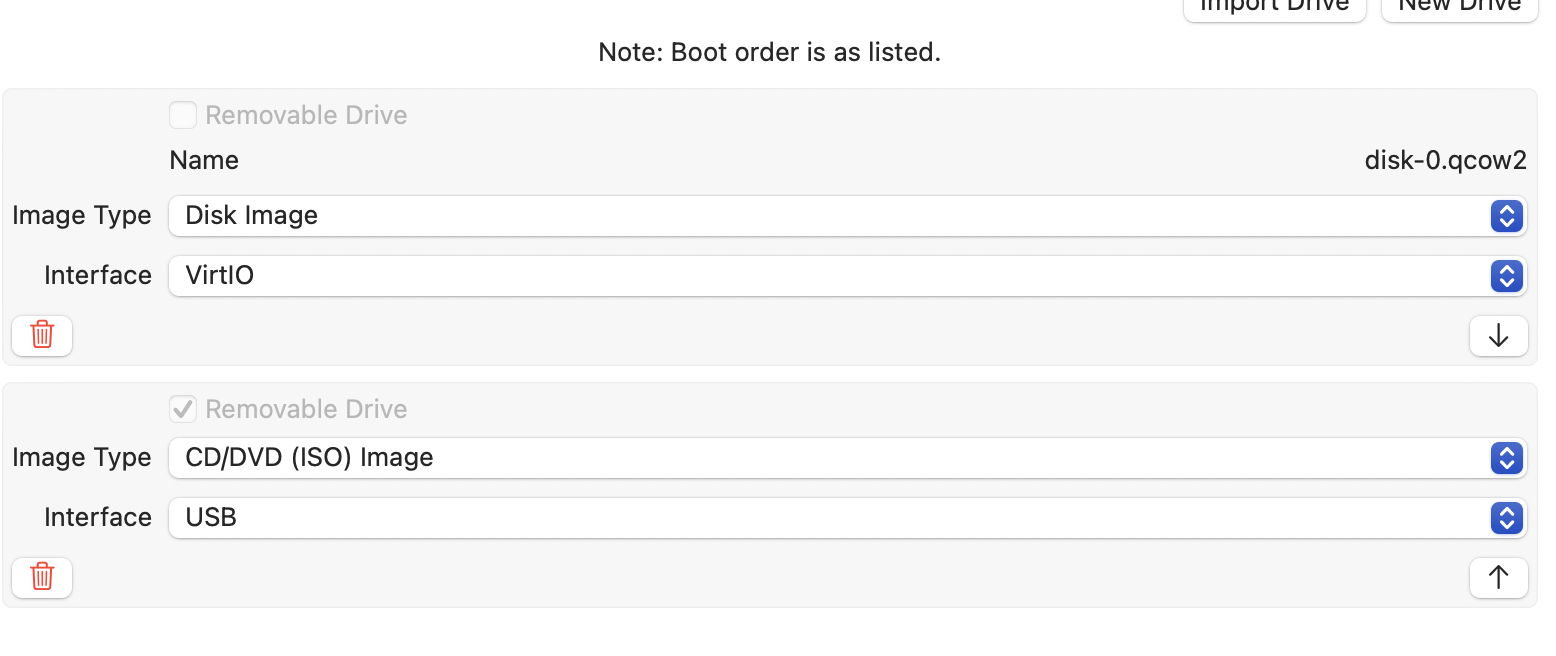
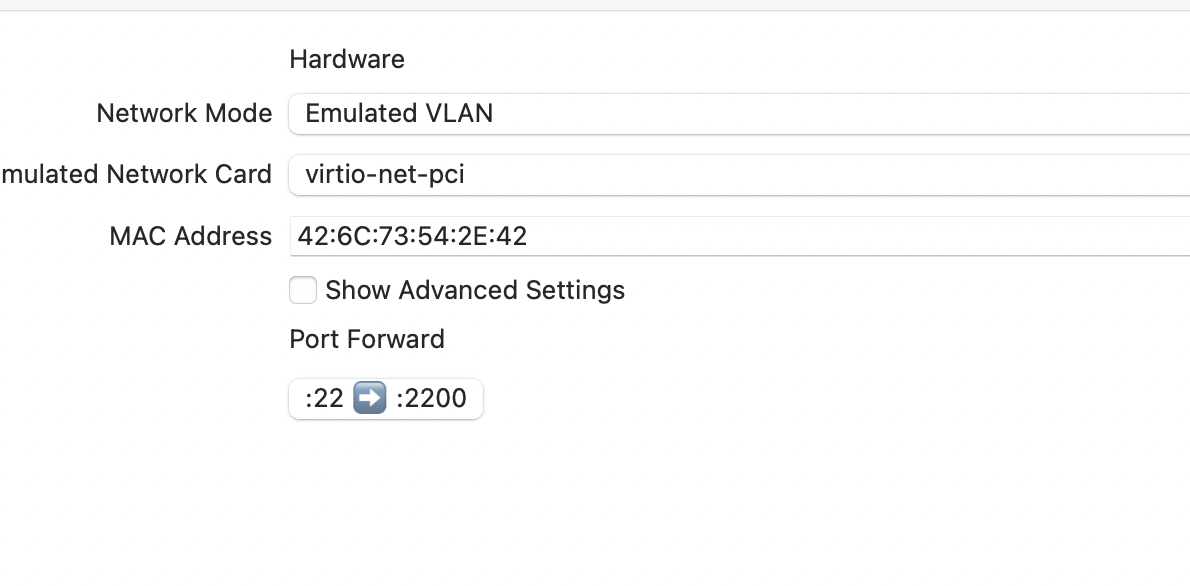
I’ll point VS Code and other things at this VM, so I’m going to forward port 2200 on the Mac to port 22 on the Debian VM.
Choose OS installer and boot
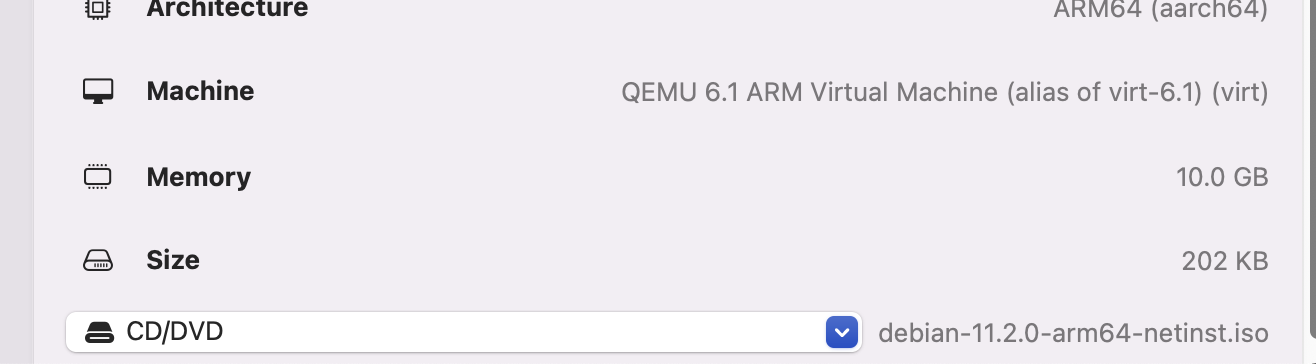
Set the CD/DVD to the Debian ISO file path. I used the arm64 netinst iso for Debian 11 from https://cdimage.debian.org/debian-cd/current/arm64/iso-cd/
Boot the machine and run the Debian install. It’s like 1999 here. (So much nostalgia when I used to scavenge x86 boxes from dumpsters in the Sydney CBD 20 years ago to put Linux on them).
Boot the image and log in. Now we have a working Linux aarch64 box on the M1, running very close to native speed (arm on arm virtualization).
You can ssh into this from the Mac OS side, or set it up as a remote host for VS Code just fine, which is shockingly convenient (on port 2200).
Install the dev env
This is a really basic Debian image, so you need a couple of things to get started with a barebones Haskell env:
apt install sudo curl cabal-install
We have a basic dev env now.
$ uname -msr
Linux 5.10.0-10-arm64 aarch64
$ ghci
GHCi, version 8.8.4: https://www.haskell.org/ghc/ :? for help
Prelude> System.Info.arch
"aarch64"
Prelude> let s = 1 : 1 : zipWith (+) s (tail s) in take 20 s
[1,1,2,3,5,8,13,21,34,55,89,144,233,377,610,987,1597,2584,4181,6765]To build Glean a la https://glean.software/docs/building/ we need to update Cabal to the 3.6.x or greater, as Glean uses some fancy Cabal configuration features..
Update cabal
We need cabal > 3.6.x which isn’t in Debian stable, so I’ll just use the pre-built binary from https://www.haskell.org/cabal/download.html
Choose: Binary download for Debian 10 (aarch64, requires glibc 2.12 or later): cabal-install-3.6.0.0-aarch64-linux-deb10.tar.xz
Unpack that. You’ll also need apt-get libnuma-dev if you use that binary.
$ tar xvfJ cabal-install-3.6.0.0-aarch64-linux-deb10.tar.xz
$ ./cabal --version
cabal-install version 3.6.0.0
compiled using version 3.6.1.0 of the Cabal libraryI just copy that over the system cabal for great good. It’s a good idea now to sync the package list for Hackage, before we start trying to build anything Haskell. with a cabal update.
Install the Glean dependencies
To build Glean we need a bunch C++ things. Glean itself will bootstrap the Haskell parts. The Debian packages needed are identical to those for Ubuntu on the Glean install instructions : https://glean.software/docs/building/#ubuntu except you might see “Package ‘libmysqlclient-dev’ has no installation candidate”. We will instead need default-libmysqlclient-dev. We also need libfmt-dev.
So the full set of Debian Glean dependencies are:
> apt install g++ \
cmake \
bison flex \
git cmake \
libzstd-dev \
libboost-all-dev \
libevent-dev \
libdouble-conversion-dev \
libgoogle-glog-dev \
libgflags-dev \
libiberty-dev \
liblz4-dev \
liblzma-dev \
libsnappy-dev \
make \
zlib1g-dev \
binutils-dev \
libjemalloc-dev \
default-libmysqlclient-dev \
libssl-dev \
pkg-config \
libunwind-dev \
libsodium-dev \
curl \
libpcre3-dev \
libfftw3-dev \
librocksdb-dev \
libxxhash-dev \
libfmt-devNow we have a machine ready to build Glean. We’ll do the ARM port of Glean in the next post and get something running.
]]>Prior to the launch of cabal and hackage the Haskell development experience was “choose a compiler” and “use fptools” as the core library. There were very few 3rd party libraries (< 20 ?) , only a barebones package system and no centralized distribution of packages.
It was really clear by 2005 that we needed to invest in tooling: build system, package management and package distribution. But without corporate funding for infrastructure, who would do the work? We needed to bootstrap an open source package infrastucture team. Enter the hackathons.
In 2007 we met in Oxford to hack for 3 days to launch Hackage, and make it possible to upload and share packages for Haskell. To do this we wanted to link the build system (cabal) to the package management, upload and download (hackage), leading to the modern world of packages for Haskell, which rapidly accelerated into 10s of thousands of libraries.

Looking back this was a pivotal moment: after Hackage , the open source community rapidly became the primary producer of new Haskell code. Corporate sponsorship of the community increased and a wave of corporate adoption was enabled due to the package distribution system. A research community became a (much larger) open source and then commercial software engineering community. And the key steps were Hackage and Cabal, and some polished core libraries that worked together.
You can see the lessons learned echoed in systems like the Rust cargo and crate system, now. Good languages become sustainable when they become viable open source communities around packages.
You can listen to the interview here: https://youtu.be/Dho7XXoakvY?t=1053
]]>As a warm up I thought I’d try porting the stream fusion core from Haskell to Rust. This was code I was working on more than a decade ago. How much of it would work or even make sense in today’s Rust?
Footnote: this is the first code I’ve attempted to seriously write for more than 2 years, as I’m diving back into software engineering after an extended sojourn in team building and eng management. I was feeling a bit .. rusty. Let me know if I got anything confused.
TLDR
- Two versions of the basic stream/list/vector APIs: a data structure with boxed closure-passing and pure state
- And a more closure-avoiding trait encoding that uses types to index all the code statically
Fun things to discover:
- most of the typeclass ‘way of seeing’ works pretty much the same in Rust. You index/dispatch/use similar mental model to program generically. I was able to start guessing the syntax after a couple of days
- it’s actually easier to get first class dictionaries and play with them
- compared to the hard work we do in GHC to make everything strict, unboxed and not heap-allocated, this is the default in Rust which makes the optimization story a lot simpler
- Rust has no GC , instead using a nested-region like allocation strategy by default. I have to commit to specific sharing and linear memory use up front. This feels a lot like an ST-monad-like state threading system. Borrowing and move semantics take a bit of practice to get used to.
- the trait version looks pretty similar to the core of the standard Rust iterators, and the performance in toy examples is very good for the amount of effort I put in
- Rust seems to push towards method/trait/data structure-per-generic-function programming, which is interesting. Encoding things in types does good things, just as it does in Haskell.
- Non-fancy Haskell, including type class designs, can basically be ported directly to Rust, though you now annotate allocation behavior explicitly.
- cargo is a highly polished ‘cabal’ with lots of sensible defaults and way more constraints on what is allowed. And a focus on good UX.
As a meta point, it’s amazing to wander into a fresh programming language, 15 years after the original “associated types with class” paper, and find basically all the original concepts available, and extended in some interesting ways. There’s a lot of feeling of deja vu for someone who worked on GHC optimizations/unboxing/streams when writing in Rust.
Version 1: direct Haskell translation
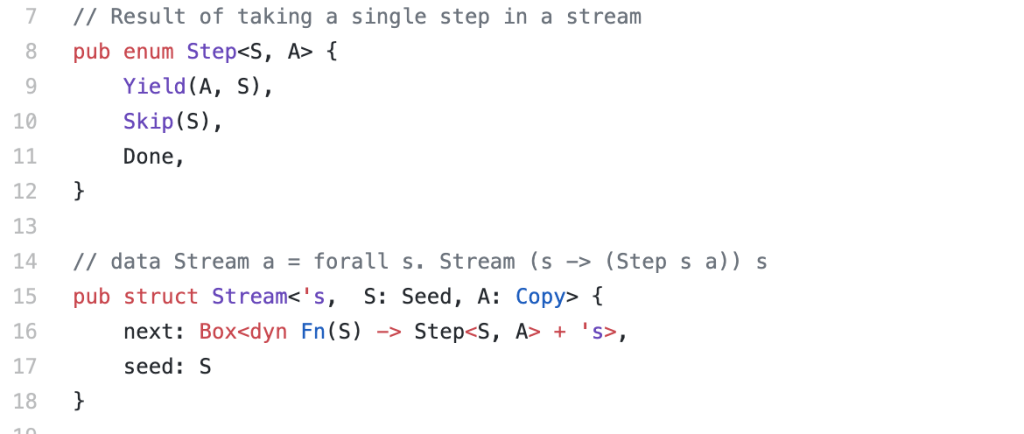
https://github.com/donsbot/experiments-rust/blob/master/stream-fusion/src/closure.rs
First, a direct port of the original paper. A data type for stepping through elements of stream, including ‘Skip’ so we can filter things. And a struct holding the stream stepper function, and the state. Compared to the Haskell version (in the comment) there’s more rituals to declare what goes on the heap, and linking the lifetime of objects together. My reward for doing this is not needing a garbage collector. There’s quite an enjoyable serotonin reward when a borrow checking program type checks :-)
You can probably infer from the syntax this will be operationally expensive: a closure boxed up onto the heap. Rust’s explicit control of where things are stored and for how long feels a lot like a type system for scripting allocators, and compared to Haskell you’re certainly exactly aware of what you’re asking the machine to do.
Overall, its a fairly pleasing translation and even though I’m putting the closure on the heap I’m still having it de-allocated when the stream is dropped. Look mum, closure passing without a GC.
We can create empty streams, or streams with a single element in them. Remember a stream is just a function from going from one value to the next, and a state to kick it off:

The lambda syntax feels a bit heavy at first, but you get used to it. The hardest part of these definitions were:
- being explicit about whether my closure was going to borrow or own the lifetime of values it captures. Stuff you never think about in Haskell, with a GC to take care of all that thinking (for a price). You end up with a unique type per closure showing what is captured, which feels _very_ explicit and controlled.
- no rank-2 type to hide the stream state type behind. The closest I could get was the ‘impl Seed’ opaque return type, but it doesn’t behave much like a proper existential type and tends to leak through the implementation. I’d love to see the canonical way to hide this state value at the type level without being forced to box it up.
- a la vector ‘Prim’ types in Haskell, we use Copy to say something about when we want the values to be cheap to move (at least, that’s my early mental model)
I can generate a stream of values, a la replicate:

As long as I’m careful threading lifetime parameters around I can box values and generate streams without using a GC. This is sort of amazing. (And the unique lifetime token-passing discipline feels very like the ST monad and its extensions into regions/nesting). Again , you can sort of “feel” how expensive this is going to be, with the capturing and boxing to the heap explict. That boxed closure dynamically invoked will have a cost.
Let’s consume a stream, via a fold:

Not too bad. The lack of tail recursion shows up here, so while I’d normally write this as a ‘go’ local work function with a stack parameter, to get a loop, instead in Rust we just write a loop and peek and poke the memory directly via a ‘mut’ binding. Sigh, fine, but I promise I’m still thinking in recursion.
Now I can do real functional programming:

What about something a bit more generic: enumFromTo to fill a range with consecutive integer values, of any type supporting addition?

The trait parameters feel a lot like a super layered version of the Haskell Num class, where I’m really picking and choosing which methods I want to dispatch to. The numeric overloading is also a bit different (A::one()) instead of an overloaded literal. Again, is almost identical to the Haskell version, but with explicit memory annotations, and more structured type class/trait hierarchy. Other operations, like map, filter, etc all fall out fairly straight forward. Nice: starting to feel like I can definitely be productive in this language.
Now I can even write a functional pipeline — equivalent to:
sum . map (*2) . filter (\n -> n`mod`2 == 1) $ [1..1000000::Int]
=> 500000000000
As barebones Rust:

It actually runs and does roughly what I’d expect, for N=1_000_000:
$ cargo run
500000000000
Another moment of deja vu, installing Criterion to benchmark the thing. “cargo bench” integration is pretty sweet:
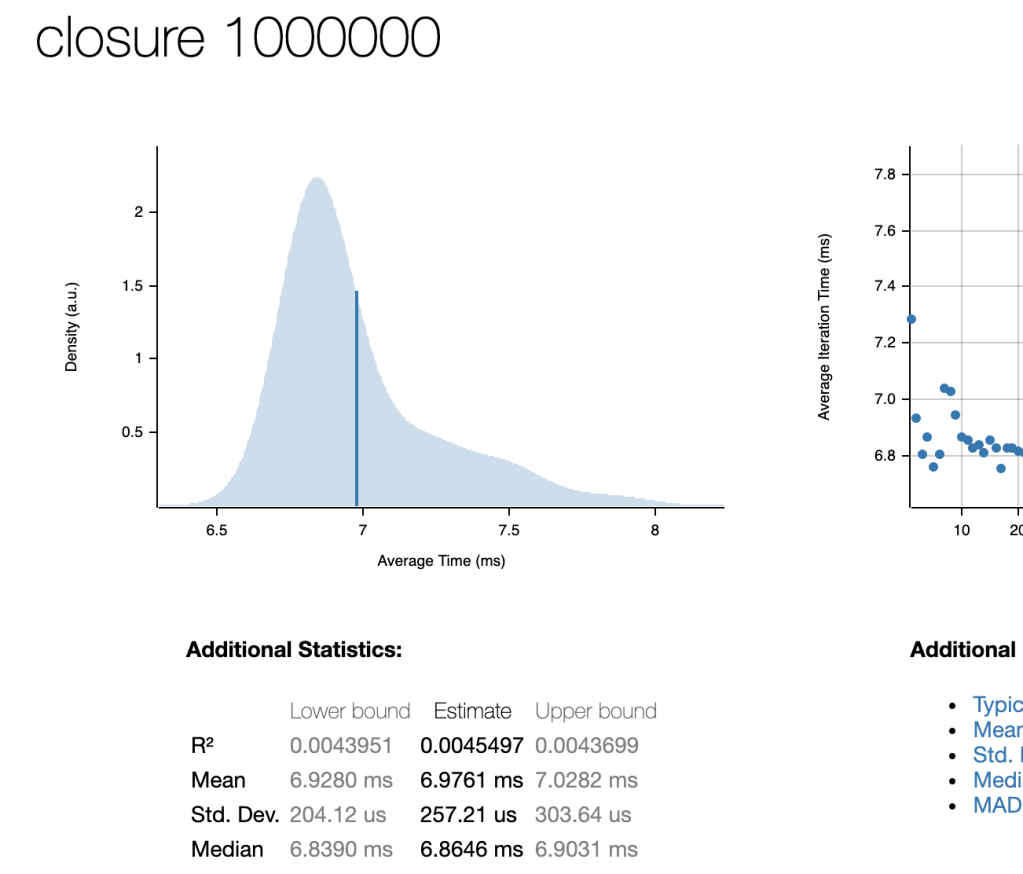
So about 7 ms for four logical loops over 1M i64 elements. That’s sort of plausible and actually not to bad considering I don’t know what I’m doing.

The overhead of the dynamic dispatch to the boxed closure is almost certainly going to dominate, and and then likely breaks inlining and arithmetic optimization, so while we do get a fused loop, we get all the steps of the loop in sequence. I fiddled a bit with the inlining the consuming loop, which shaved 1ms off, but that’s about it.
A quick peek at the assembly f–release mode, which I assume does good things, and yeah, this isn’t going to be fast. Tons of registers, allocs and dispatching everywhere. Urk.
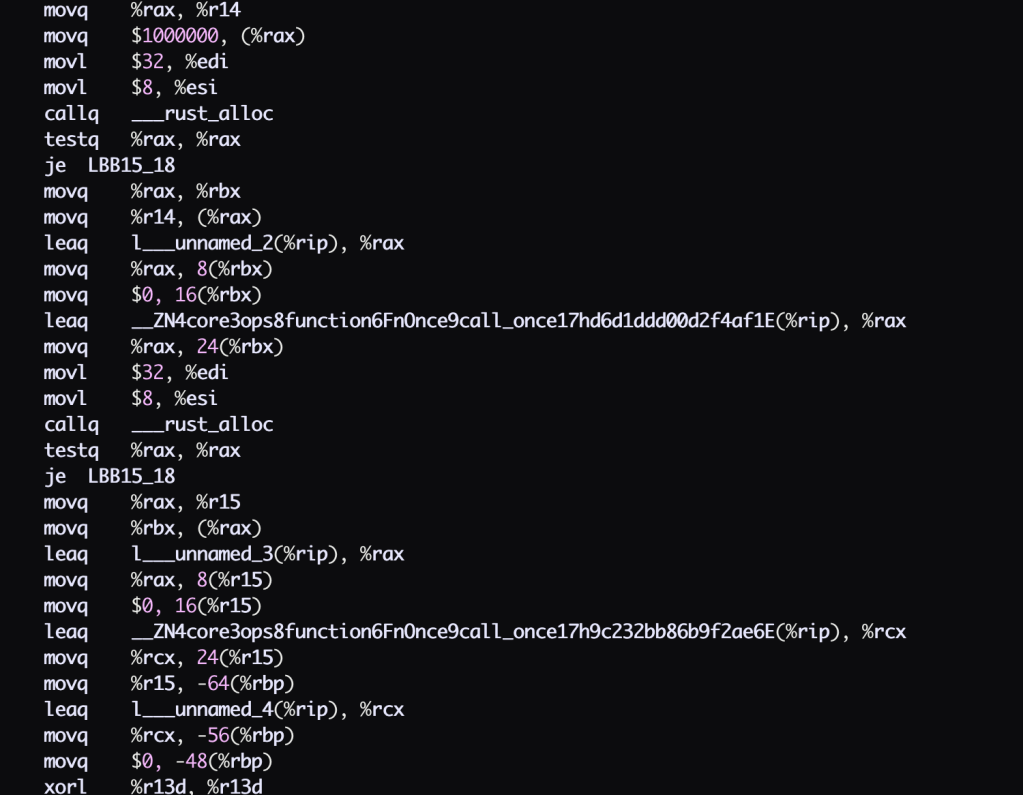
But it works! The first thing directly translated works, and it has basically the behavior you’d expect with explict closure calls. Not bad!
A trait API
https://github.com/donsbot/experiments-rust/blob/master/stream-fusion/src/trait.rs
That boxed closure bothers me a bit. Dispatching to something that’s known statically. The usual trick for resolving things statically is to move the work to the type system. In this case, we want to lookup the right ‘step’ function by type. So I’ll need a type for each generator and transformer function in the stream API. We can take this approach in Rust too.
Basic idea:
- move the type of the ‘step’ function of streams into a Stream trait
- create a data type for each generator or transformer function, then impl that for Stream. This is the key to removing the overhead resolving the step functions
- stream elem types can be generic parameters, or specialized associated types
- the seed state can be associated type-indexed
I banged my head against this a few different ways, and settled on putting the state data into the ‘API key’ type. This actually looks really like something we already knew how to do – streams as Rust iterators – Snoyman already wrote about it 3 years ago! — I’ve basically adapted his approach here after a bit of n00b trial and error.
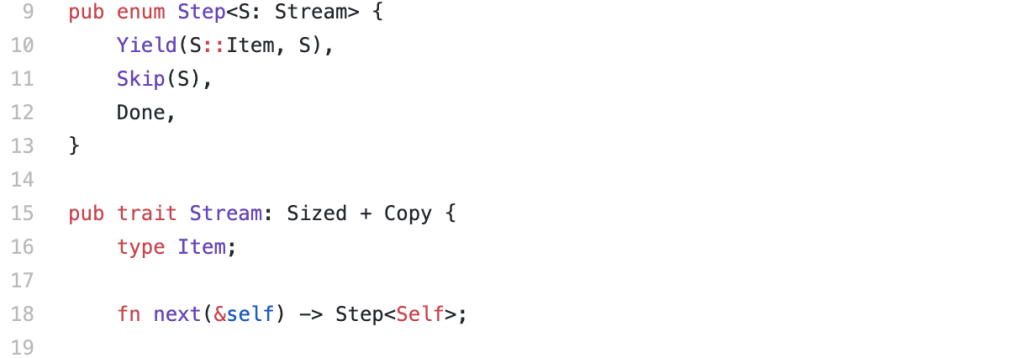
The ‘Step’ type is almost the same, and the polymorphic ‘Stream’ type with its existential seed becomes a trait definition:
What’s a bit different now is how we’re going to resolve the function to generate each step of the stream. That’s now a trait method associated with some instance and element type.
So e.g. if I want to generate an empty stream, I need a type, and instance and a wrapper:

Ok not too bad. My closure for stepping over streams is now a ‘next’ method. What would have been a Stream ‘object’ with an embedded closure is now a trait instance where the ‘next’ function can be resolved statically.
I can convert all the generator functions like this. For example, to replicate a stream I need to know how many elements, and what the element is. Instead of capturing the element in a closure, it’s in an explicit data type:

The step function is still basically the same as in the Haskell version, but to get the nice Rust method syntax we have it all talk to ‘self’.
We also need a type for each stream transformer: so a ‘map’ is now a struct with the mapper function, paired with the underlying stream object it maps over.

This part is a bit more involved — when a map is applied to a stream element, we return f(x) of the element, and lift the stream state into a Map stream state for the next step.
I can implement Stream-generic folds now — again, since I have no tail recursion to consume the stream I’m looping explicitly. This is our real ‘driver’ of work , the actual loop pulling on a chain of ‘stream.next()’s we’ve built up.

Ok so with the method syntax this looks pretty nice:

I had to write out the types here to understand how the method resolving works. We build up a nice chain of type information about exactly what function we want to use at what type. The whole pipeline is a Map<Filter<Range < … type> , all an instance of Stream.

So this should do ok right? No boxing of closures, there could be some lookups and dispatch but there’s enough type information here to know all calls statically. I don’t have much intuition for how Rust will optimize the chain of nested Yield/Skip constructors.. but I’m hopeful given the tags fit in 2 bits, and I don’t use Skip anywhere in the specific program.

288 microseconds to collapse a 1_000_000 element stream. Or about 25x faster. Nice!
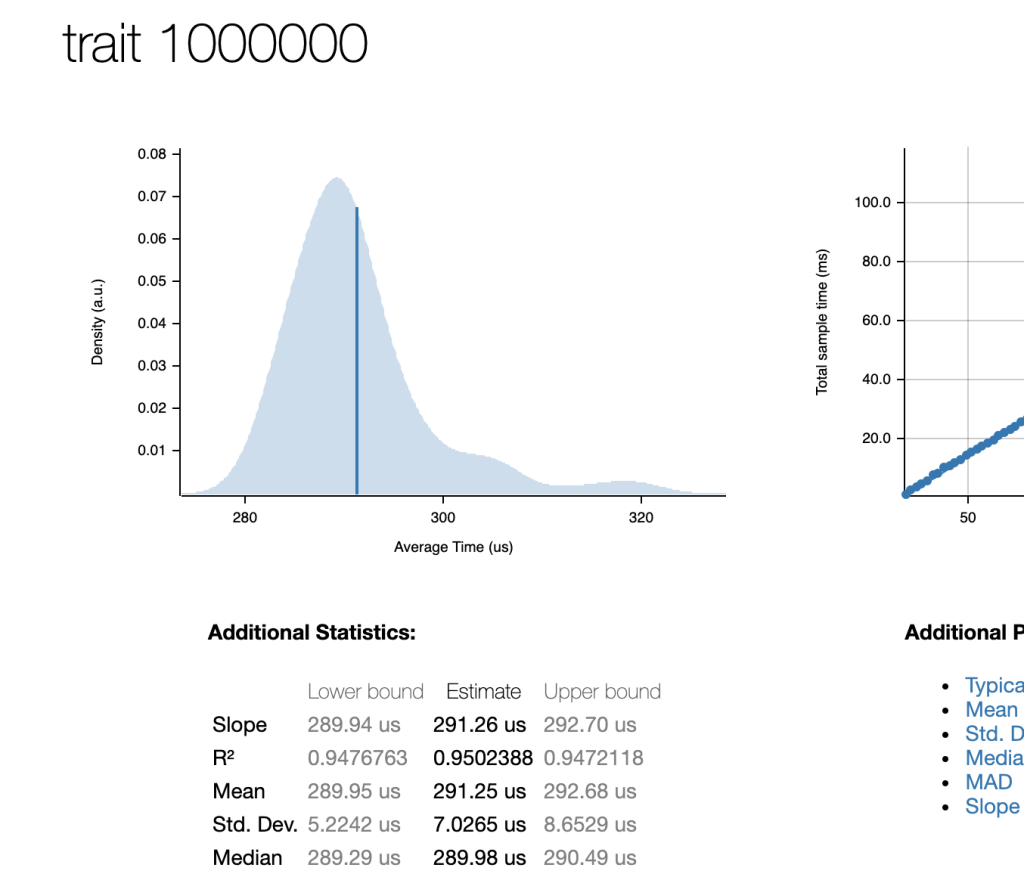
So the type information and commitment to not allocating to the heap does a lot of work for us here. I ask cargo rustc --bin stream_test --release -- --emit asm for fun. And this is basically what I want to see: a single loop, no allocation, a bit of math. Great.

It’s converted the %2 / *2 body into adding a straight i64 addition loop with strides. I suspect with a bit of prodding it could resolve this statically to a constant but that’s just a toy anyway. All the intermediate data structures are gone.
Overall, that’s a pretty satisfying result. With minimal effort I got a fusing iterator/stream API that performs well out of the box. The Rust defaults nudge code towards low overhead by default. That can feel quite satisfying.
]]>Now, I’m switching track to a software engineering role at Facebook, in the same organization. I’m interested in bug prevention strategies when you have a very large scale, highly automated CI system. Given all the great tools we have to find bugs, how do you best integrate them into development processes, particularly when there are thousands of engineers in the loop.
And, in case you’re wondering, I’ll be hacking in some mix of Rust, Hack, maybe a bit of Haskell or OCaml, probably some Python in the mix, and some ML + data viz/data analysis.

 SMT solvers are automated tools to solve the “Satisfiability Modulo Theories” problem — that is, determining whether a given logical formula can be satisfied. However, unlike SAT solvers, SMT solvers generalize to solving such NP-complete problems that contain not just boolean variables, but more useful types, such as lists, tuples, arrays, integers and reals. And they do this while retaining very good performance (with yearly shootouts for the best solvers). As a result, SMT solvers provide a big hammer for solving many difficult problems automatically.
SMT solvers are automated tools to solve the “Satisfiability Modulo Theories” problem — that is, determining whether a given logical formula can be satisfied. However, unlike SAT solvers, SMT solvers generalize to solving such NP-complete problems that contain not just boolean variables, but more useful types, such as lists, tuples, arrays, integers and reals. And they do this while retaining very good performance (with yearly shootouts for the best solvers). As a result, SMT solvers provide a big hammer for solving many difficult problems automatically.
They are so interesting they’ve been described as a disruptive technology in formal methods. They are more automated than interactive theorem provers, while still providing high-end expressive capability.
And they’re growing in use in industrial applications. In the Cryptol toolset, for example, SMT solvers are used to determine if two implementations of a cryptographic function are functionally identical; Microsoft uses SMT solvers for device driver verification; and they’ve been used for large scale test generation, planning and routing problems.
The challenge now is to make such power easily available to programmers without a formal methods background.
To do this, my approach is to embed the SMT solver into a good programming language, as an embedded DSL. Embedded languages let us hide significant complexity, using the host language’s combining forms to build up complex structures from simple primitives — instead of starting with a complex API in the first place.
If you already know the host language, you can program in the EDSL. If you know Haskell, you can program an SMT solver.
The code is available:
- cabal install yices-painless (depends on an install of Yices from SRI)
- darcs get https://code.haskell.org/~dons/code/yices-painless/
- Haddock documentation (since Hackage won’t generate the docs without Yices headers)
Scripting a Solver
SMT solvers are typically scripted in an imperative fashion: variables are declared, and then facts about those variables are asserted, step by step. The resulting set of declarations is passed to the solver to determine satisifiability (and to find any satisfying values to assign to the variables, if possible). From a programming language perspective, these declarations and assertions look like (typed) (pure) functions with free variables.
The standard SMT-LIB format (accepted by most SMT solvers) looks something like:
(define p::bool)
(define q::bool)
(define r::bool)
(assert (=> (and (=> p q) (=> q r)) (=> p r)))
Which we’ll write in our EDSL in Haskell as:
\p q r -> (p → q && q → r) → (p → r)
Haskell’s type inference can fill in the types in the EDSL, and infix notation also helps clean things up.
Such a proposition may be passed to a solver, like so:
> solve $ \p q r -> (p → q && q → r) → (p → r)
Satisfiable!
r => False
q => True
p => True
We start with something that looks like a Haskell function (but is actually a function in the EDSL), which can be interpreted by a solver, with Haskell’s language machinery filling in types, and checking safety.
In this post I’ll talk about how I designed yices-painless, an EDSL that embeds SMT scripting support deeply into Haskell (deeply, in that the Haskell type system will check the types of the SMT propositions). The work is based on the language embedding approach taken by Chakravarty et al’s, accelerate arrays language (for GPU programming), using higher-order abstract syntax to support elegant variable binding, with a type-preserving translation to a form that can be executed by the underlying solver.
Designing the EDSL

For a client problem at work, I was interested in trying an SMT solver. The Yices SMT solver from SRI is a high-performance SMT solver with a well-documented C interface, which is a good place to start experimenting. The design challenge was to get from the imperative C interface we have to use, to the typed, pure Haskell embedding that we want to write.
To do this, we build up several layers of abstraction, each one removing redundancy and hiding unnecessary complexity:
- The base layer, Yices itself, a big blob of compiled C or C++ code, exporting 150+ functions.
- Yices.Painless.Base.C: Stitching Yices to Haskell via a full (and straightforward) FFI bindings (150+ Haskell functions, and a few types)
- Yices.Painless.Base: The FFI bindings are just as unsafe as the C layer, so in the next abstraction layer we automate the resource managment, use native Haskell types, and native Haskell abstractions (e.g. lazy lists instead of iteratees). The number of functions exposed is reduced as a result, making the API simpler. This layer is still imperative (all functions are in IO), but relatively useful.
- Yices.Painless.Language: The AST layers are the big step up in expressive power: we design an abstract syntax tree to represent the embedded language, along with a set of primitive functions and types. This pure data structure will be interpreted (or compiled to SMT-LIB format), generating calls to the imperative layer. We thus have very strong separation between the messy, error-prone imperative model, and the correct-by-construction pure AST. We have just simple constants, variables, conditions and a handful of (polymorphic) primitive functions, relying on the language to build up complex expressions from a few simple forms.
- Surface Syntax: Finally, we expose the EDSL language via smart surface syntax, overloaded via Haskell’s type classes: Bits, Num, String. And now programmers need only use Haskell’s native math and bit functions, syntax and types, to build propositions. Type inference and checking works, as well as proper scoping of variables in the propositions. This user-facing layer looks and feels exactly like Haskell, yet it is translated to a form that drives an imperative C library.
The surface layer reveals the power of a good EDSL: hiding unnecessary complexity, increasing expressivity (compare the few functions (and combinators) in the EDSL layer at the top, with the 150+ functions in the C API).
The EDSL reduces the cognitive load on the programmer by an order of magnitude.
Implementation
The Base Layers
The base layers are the most straightforward part of the system. First, we write a natural FFI binding to every function exposed by the Yices C API. Each C function gets an FFI import; value types are represented by types defined in the Haskell FFI report (e.g. CInt, CString), while Yices types allocated and controlled by Yices are typed in Haskell with empty data types (e.g. YExpr), giving us increased type safety (compared to using void pointers).
The FFI layer is then wrapped in resource handling code, hiding a set of functions from an C++ iterator behind a single function returning a lazy list). The FFI bindings are about 350 lines of code; the wrapper layer another 500. Most of this can be generated.
The Typed AST
Following Chakravarty’s approach, we represent the embedded language with a surface syntax (supporting numerical and scalar polymorphic operations), which builds a nameless AST (variables in the EDSL are represented as Haskell variables). The typed embedding gives us a type checker for the DSL for free. The AST is decorated with type information, so we can resolve overloading (in the EDSL), and do other type-based operations. The EDSL itself is just over 1000 lines of Haskell.
The language is relatively simple: variables (of any scalar type), literals (of any scalar type), conditionals, and a range of built-in functions. Variables are bound/quantified at the top level of the EDSL.
data Exp t where
Tag :: (IsScalar t) => Int -> Exp t
Const :: (IsScalar t) => t -> Exp t
Cond :: Exp Bool -> Exp t -> Exp t -> Exp t
PrimApp :: PrimFun (a -> r) -> Exp a -> Exp r
data PrimFun t where
PrimEq :: ScalarType a -> PrimFun ((a, a) -> Bool)
PrimNEq :: ScalarType a -> PrimFun ((a, a) -> Bool)
PrimAdd :: NumType a -> PrimFun ((a, a) -> a)
PrimSub :: NumType a -> PrimFun ((a, a) -> a)
PrimMul :: NumType a -> PrimFun ((a, a) -> a)
...
We can expose these via a type class interface for Exp things, yielding nice surface syntax: (+), (*), (==*), and (/=*). It isn’t possible to write sensible instance of Eq, sadly, as those Haskell type classes wire in return types of Bool (instead of a polymorphic Boolean class). We have to redefine (==) instead.
instance (IsNum t) => Num (Exp t) where (+) = mkAdd (-) = mkSub (*) = mkMul infix 4 ==*, /=*, <*, <=*, >*, >=* -- | Equality lifted into Yices expressions. (==*) :: (IsScalar t) => Exp t -> Exp t -> Exp Bool (==*) = mkEq -- |Inequality lifted into Yices expressions. (/=*) :: (IsScalar t) => Exp t -> Exp t -> Exp Bool (/=*) = mkNEq
The smart constructors build AST nodes, with type information added:
mkAdd :: (IsNum t) => Exp t -> Exp t -> Exp t mkAdd x y = PrimAdd numType `PrimApp` tup2 (x, y) mkMul :: (IsNum t) => Exp t -> Exp t -> Exp t mkMul x y = PrimMul numType `PrimApp` tup2 (x, y) mkEq :: (IsScalar t) => Exp t -> Exp t -> Exp Bool mkEq x y = PrimEq scalarType `PrimApp` tup2 (x, y) mkNEq :: (IsScalar t) => Exp t -> Exp t -> Exp Bool mkNEq x y = PrimNEq scalarType `PrimApp` tup2 (x, y)
Converting to de Bruijn form
This nameless form (via surface syntax) is convenient to write, and solves all the issues with binders for us, but harder to optimize (as propositions are reprsented as opaque functions). So this form is then converted to a form with explicit variables (represented as de Bruijn indices into a variable environment). The approach is identical to the one taken in the accelerate EDSL, with the change that at the top level we support n-ary functions (to represent propositions with n free variables).
Thanks to Trevor Elliott, and for historical reference, we can convert n-ary functions to their de Bruijn form via a type class, yielding a common type for propositions with arbitrary variables: :: Yices f r => f -> Prop r
Running the Solver
Once we’ve built the AST for the proposition, and replaced all variables with their de Bruijn tags, we can now execute the proposition, recursively calling Yices operations to reconstruct the AST on the Yices side, before asking to solve, finding a satisfying assignment of variables (or not), and returning a model of the bindings.
solve :: (Yices f r) => f -> IO Result
solve q = do
c <- Yices.mkContext
Yices.setTypeChecker True
let t = convertYices q -- convert to de Bruijn form
(g,e) <- execY c t -- build a Yices expression representing the AST
Yices.assert c e -- register it with Yices
Yices.check c -- check for satisfiability, returning the result
Related Work
There’s quite a few bindings to Yices (in particular) in Haskell, but none on Hackage (at the time of writing) done as a deep EDSL (ensuring type safety and lexical scoping). The original inspiration for the work was yices-easy, which exposes a monadic, shallow DSL — and has a good tutorial.
Significant related work is by my colleague at Galois, Levent Erkok, who simultaneously developed “SBV”, a deep EDSL that does support sharing and SMT-LIB access, via heavy type class use. We’ll be sharing code.
The approach to embedding taken is based on the one found in accelerate, which shares similarities with Atkey, Lindley and Yallop‘s approach. The general idea of de Bruijn/HOAS translations was introduced by McBride and McKinna.
Future Work
At the moment, this is basically a proof of concept. Simple propositions can be solved, but its not ready for large scale problems. A few things need to be done:
- Support for sharing in the AST. The EDSL currently loses sharing information, duplicating terms. This isn’t feasible for large problems.
- Operations that require certain sizes of bit vector should check those sizes (e.g. via Iavor Diatchki’s type level natural support for Haskell).
- Support deriving encodings from new Haskell types into Yices types.
- Support for lists, tuples and arrays of variables (some problems have very large numbers of variables)
- Supporting function types.
- Compile the AST to SMT-LIB statements (instead of Yices FFI calls), making it independent of a particular SMT solver (or solver’s license).
- Use it on some big problems.
I’ll be continuing work on this in 2011, and would welcome patches, feedback and use cases.
]]>Semantics of the Inception computational environment
- “Dream” == thread of control == forkIO
- A thread must stay at each level (thread group) for it not to collapse (dreamer)
- Messages can be sent down (music) – e.g. async message passing
- A kick exits a thread up one level (“die”) – throwTo KillThread
- Time degrades quickly 10, 3 mins , 10 mins , 10 years – so adjust scheduler time slices based on levels
- Groups of threads brought together by the dreamer can enter a new environment together (collaborative dreaming) – shared heap
- Arbitrary effects are allowed, (yep, it has IO at the bottom)
- Under sedation, you can disassociate a thread from its control stack, and it is in limbo (some “init” thread group), until it remembers.
- Tokens are (unique) depth counters (0, many).
Your challenge:
- Improve Claessen’s “poor man’s concurrency monad” to support the Inception environment.
- What notion of `bind` and `return` are used?
- Show that the monad laws are satisfied.
- import Control.Monad.Inception and win!
Refer to the published analysis on the use of the inception monad you need to be able to support.
]]>{kind=link}
- The Haskell Platform
- Hackage
- Cabal
You can read the slides as PDF here, or online:
]]>The amount of freely available Haskell code has grown exponentially in the past
two years as Hackage and Cabal have come online. Managing millions of Haskell
code, partitioned thousands of interdependent packages is a serious engineering
challenge that has received little attention from the language research community.
Meanwhile, new adopters of Haskell struggle to deal with the sheer number of
libraries and tools now available.One pragmatic approach to managing this web is the Haskell Platform (HP), a
project to build a blessed, comprehensive set of libraries meeting objective
quality control criteria, and in doing so make expert recommendations on which
packages to use. In its first six weeks of operation the HP had over forty
thousand downloads.The challenge with such a project is to manage the many conflict constraints
for diversity, coverage, and quality when assembling the package set. This talk
will outline the state of the Haskell Platform, the technical approaches taken
to build it, and the roadmap ahead.