| CARVIEW |
Below are all the papers at CVPR’22 that we could find by scanning titles and reading the associated papers, sometimes rather superficially because of the sheer number. Please forgive any mis-characterizations and/or omissions, and feel free to flag them by DM to @fdellaert on twitter.
Important note: all of the images below are reproduced from the cited papers, and the copyright belongs to the authors or the organization that published their papers, like IEEE. Below I reproduce a key figure or video for some papers under the fair use clause of copyright law.
NeRF
NeRF was introduced in the seminal Neural Radiance Fields paper by Mildenhall et al. at ECCV 2020. By now NeRF is a phenomenon, but for those that are unfamiliar with it, please refer to the original paper or my two previous blog posts on the subject:
In short, as shown in the figure below, a “vanilla” NeRF stores a volumetric scene representation as the weights of an MLP, trained on many images with known pose:
 Figure: Nerf Overview.
Figure: Nerf Overview.
Fundamentals
Again, many papers address the fundamentals of view-synthesis with NeRF-like methods:
Teaser videos from NeRF in the Dark (see below) which is just one of many papers that blew us away in terms of image synthesis quality.
AR-NeRF replaces the pinhole-based ray tracing with aperture-based ray-tracing, enabling unsupervised learning of depth-of-field and defocus effects. (pdf)
Aug-NeRF uses three different techniques to augment the training data to yield a significant boost in view synthesis quality. (pdf)
Deblur-NeRF take an analysis-by-synthesis approach to recover a sharp NeRF from motion-blurred images, by simulating the blurring process using a learnable, spatially varying blur kernel. (pdf)
DIVeR use a voxel-based representation to guide a deterministic volume rendering scheme, allowing it to render thin structures and other subtleties missed by traditional NeRF rendering. (pdf) Best Paper Finalist
Ha-NeRF😆 uses an appearance latent vector from images with different lighting and effects to render novel views with similarly-styled appearance. (pdf)
HDR-NeRF learns a separate MLP-based tone mapping function to transform the radiance and density of a given ray to a high-dynamic range (HDR) pixel color at that point in the output image. (pdf)
Learning Neural Light Fields learn a 4D lightfield, but transform the 4D input to an embedding space first to enable generalization from sparse 4D training samples, which gives good view dependent results. (pdf)
Mip-NeRF-360 extends the ICCV Mip-NeRF work to unbounded scenes, and also adds a prior that reduces cloudiness and other artifacts. (pdf)
NeRF in the Dark modifes NeRF to train directly on raw images, and provide controls for HDR rendering including tone-mapping, focus, and exposure. (pdf)
NeRFReN enables dealing with reflections by splitting a scene into transmitted and reflected components, and modeling the two components with separate neural radiance fields. (pdf)
NeuRay improves rendering quality by predicting the visibility of 3D points to input views, enabling the radiance field construction to focus on visible image features. (pdf)
Ref-NeRF significantly improves the realism and accuracy of specular reflections by replacing NeRF’s parameterization of view-dependent outgoing radiance with a representation of reflected radiance. (pdf) Best Student Paper Honorable Mention
SRT “processes posed or unposed RGB images of a new area, infers a ‘set-latent scene representation’, and synthesizes novel views, all in a single feed-forward pass.” (pdf)
Priors
One important way to improve the synthesis of new views instead is with various forms of generic or depth-driven priors:
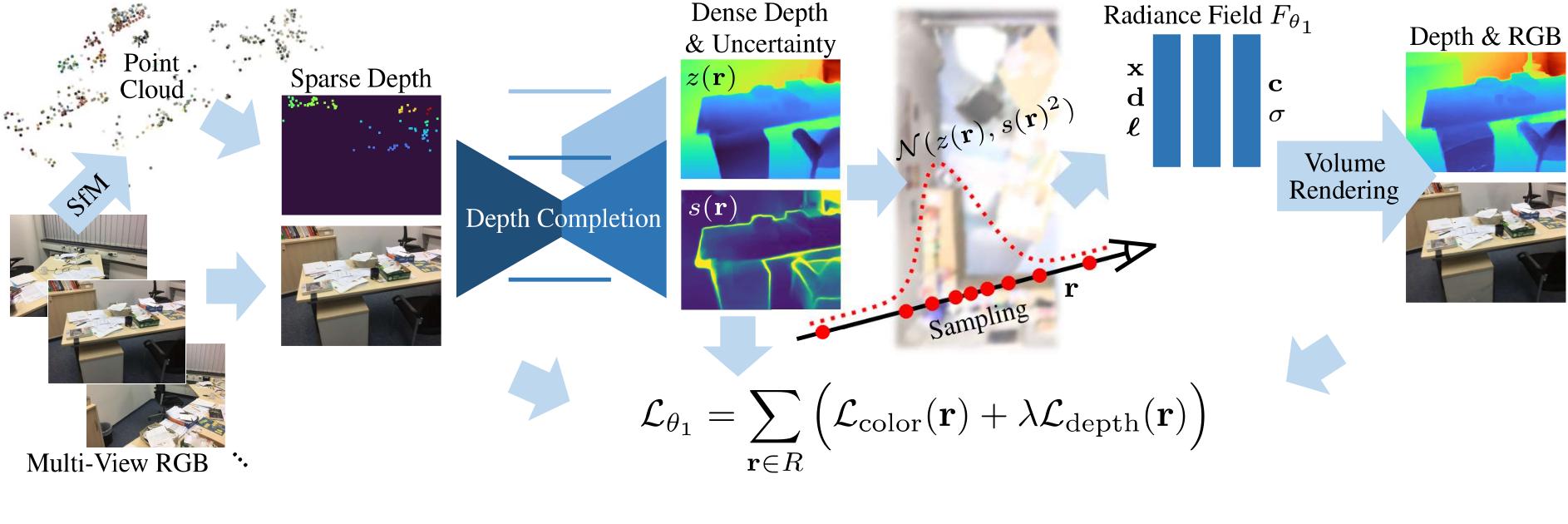 Figure: Dense Depth Priors for NeRF
Figure: Dense Depth Priors for NeRF
Dense Depth Priors for NeRF estimates depth using a depth completion network run on the SfM point cloud in order to constrain NeRF optimization, yielding higher image quality on scenes with sparse input images. (pdf)
Depth-supervised NeRF also uses a depth completion network on structure-from-motion point clouds to impose a depth-supervised loss for faster training time on fewer views of a given scene. (pdf)
InfoNeRF penalizes the NeRF overfitting ray densities on scenes with limited input views through ray entropy regularization, resulting in higher quality depth maps when rendering novel views. (pdf)
RapNeRF focuses on view-consistency to enable view extrapolation, using two new techniques: random ray casting and a ray atlas. (pdf)
RegNeRF enables good reconstructions from a view images by renders patches in unseen views and minimizing an appearance and depth smoothness prior there. (pdf)
Multi-View
Another approach is to use nearby reference views at inference time, following a trend set by IBRNet and MVSNet:
Result from from Light Field Neural Rendering (see below) which uses nearby views and a light-field parameterization to render very non-trivial effects.
GeoNeRF uses feature-pyramid networks and homography warping to construct cascaded cost volumes on input views that infer local geometry and appearance on novel views, using a transformer-based approach. (pdf)
Light Field Neural Rendering uses a lightfield parameterization for target pixel and its epipolar segments in nearby reference views, to produce high-quality renderings using a novel transformer architecture. (pdf) Best Paper Finalist
NAN builds upon IBRNet and NeRF to implement burst-denoising, now the standard way of coping with low-light imaging conditions. (pdf)
NeRFusion first reconstructs local feature volumes for each view, using neighboring views, and then uses recurrent processing to construct a global neural volume. (pdf)
Performance
A big new trend is the emergence of voxel-based, very fast NeRF variants, many foregoing the large MLP at the center of the original NeRF paper:
Plenoxels (see below) is one of the no-MLP papers that took the NeRF community by storm. DVGO (also below) and instant NGP method, published not at CVPR but at SIGGRAPH 22, are other papers in this space. Goodbye long training times?
DVGO replaces the large MLP with a voxel grid, directly storing opacity as well as local color features, interpolated and then fed into a small MLP to produce view-dependent color. (pdf)
EfficientNeRF learns estimated object geometry from image features for efficient sampling around the surface of the object, reducing the time it takes to render and improving radiance field construction. (pdf)
Fourier PlenOctrees tackles “efficient neural modeling and real-time rendering of dynamic scenes” using “Fourier PlenOctrees”, achieving a 3000x speedup over NeRF. (pdf)
Plenoxels foregoes MLPs altogether and optimizes opacity and view-dependent color (using spherical harmonics) directly on a 3D voxel grid. (pdf)
Point-NeRF uses MVS techniques to obtain a dense point cloud, which is then used for per-point features, which are then fed to a (small) MLP for volume rendering. (pdf)
Large-scale
Large-scale scenes are also of intense interest, with various efforts in that dimension:
Block-NeRF (see below) shows view synthesis derived from 2.8 million images.
Block-NeRF scales NeRF to render city-scale scenes, decomposing the scene into individually trained NeRFs that are then combined to render the entire scene. Results are shown for 2.8M images. (pdf)
Mega-NeRF decomposes a large scene into cells each with a separate NeRF, allowing for reconstructions of large scenes in significantly less time than previous approaches. (pdf)
Urban Radiance Fields allows for accurate 3D reconstruction of urban settings using panoramas and lidar information by compensating for photometric effects and supervising model training with lidar-based depth. (pdf)
Articulated
A second emerging trend is the application of neural radiance field for articulated models of people, or cats 😊:

BANMo (see below) creates a deformable NeRF from your cat videos!
BANMo combines deformable shape models, canonical embeddings, and NeRF-style volume rendering to train high-fidelity, articulated 3D models from many casual RGB videos. (pdf)
DoubleField trains a surface field as well as radiance field, using a shared feature embedding, to allow for high-fidelity human reconstruction and rendering on limited input views. (pdf)
HumanNeRF optimizes for a volumetric representation of a person in a canonical pose, and estimates a motion field for every frame with non-rigid and skeletal components. (pdf)
HumanNeRF (2) estimates human geometry and appearance through a dynamic NeRF approach along with a neural appearance blending model from adjacent views to create dynamic free-viewpoint video using as few as six input views. (pdf)
NeuralHOFusion learns separate human and object models from a sparse number of input masks extracted from RGBD images, resulting in realistic free-viewpoint videos despite occlusions and challenging poses. (pdf)
Structured Local Radiance Fields uses pose estimation to build a set of local radiance fields specific to nodes on an SMPL model which, when combined with an appearance embedding, yields realistic 3D animations. (pdf)
Surface-Aligned NeRF maps a query coordinate to its dispersed projection point on a pre-defined human mesh, using the mesh itself and the view direction to be input to the NeRF for high-quality dynamic rendering. (pdf)
VEOs use a multi-view variant of non-rigid NeRF for object reconstruction and tracking of plushy objects, which can then be rendered in new deformed states. (pdf)
Portrait
Some papers are focused on the generation of controllable face images and/or 3D head models for people, and cats:
GRAM (see below) focuses its radiance fields to be sampled near the surface for some amazing results.
EG3D is a geometry-aware GAN that uses a novel tri-plane volumetric representation (somewhere between implicit and voxels) to allow for real-time rendering to a low-res image, upscaled via super-resolution. (pdf)
FENeRF learns a 3D-aware human face representation with two latent codes, which can generate editable and view-consistent 2D face images. (pdf)
GRAM uses a separate manifold predictor network to constrain the volume rendering samples near the surface, yielding high-quality results with fine details. (pdf)
HeadNeRF integrates 2D rendering into the NeRF rendering process for rendering controllable avatars at 40 fps. (pdf)
RigNeRF enables full control of head pose and facial expressions learned from a single portrait video by using a deformation field that is guided by a 3D morphable face model. (pdf)
StyleSDF combines a conditional SDFNet, a Nerf-style volume renderer, and a 2D style-transfer network to generate high quality face models/images. (pdf)
Editable
Controllable or editable NerFs are closely related:

With CLIP-NeRF (see below) you can edit NeRFs with textual guidance, or example images.
CLIP-NeRF supports editing a conditional model using text or image guidance via their CLIP embeddings. (pdf)
CoNeRF takes a single video, along with some attribute annotations, and allow re-rendering while controlling the attributes independently, along with viewpoint. (pdf)
NeRF-Editing allows for editing of a reconstructed mesh output from NeRF by creating a continuous deformation field around edited components to bend the direction of the rays according to its updated geometry. (pdf)
Conditional
Continuing a trend started at ICCV is conditioning NeRF-like models on various latent codes:
🤣LOLNeRF uses pose estimation and segmentation techniques to train a conditional NeRF on single views, which then at inference time can generate different faces with the same pose, or one face in different poses. (pdf)
Pix2NeRF extends π-GAN with an encoder, trained jointly with the GAN, to allow mapping images back to a latent manifold, allowing for object-centric novel view synthesis using a single input image. (pdf)
StylizedNeRF “pre-train a standard NeRF of the 3D scene to be stylized and replace its color prediction module with a style network to obtain a stylized NeRF.” (pdf)
Composition
Close to my interests, compositional approaches that use object-like priors:
Panoptic Neural Fields (PNF) (see below) has many object-NeRFs and a “stuff”-NeRF, supporting many different synthesis outputs.
AutoRF learns appearance and shape priors for a given class of objects to enable single-shot reconstruction for novel view synthesis. (pdf)
PNF fits a separate NeRF to individual object instances, creating a panoptic-radiance field that can render dynamic scenes by composing multiple instance-NeRFs and a single “stuff”-NeRF. (pdf)
Other
Finally, several different (and pretty cool!) applications of NeRF:

DyNeRF (see below) allows free-viewpoint re-rendering of a video once latent descriptions for all frames have been learned.
Dream Fields synthesizes a NeRF from a text caption alone, minimizing a CLIP-based loss as well as regularizing transmittance to reduce artifacts. (pdf)
DyNeRF uses compact latent codes to represent the frames in a 3D video and is able to render the scene from free viewpoints, with impressive volumetric rendering effects. (pdf)
Kubric is not really a NeRF paper but provides “an open-source Python framework that interfaces with PyBullet and Blender to generate photo-realistic scenes” that can directly provide training data to NeRF pipelines. (pdf)
NICE_SLAM uses a hierarchical voxel-grid NeRF variant to render RGBD, for a real-time and scalable parallel tracking and mapping dense SLAM system for RGBD inputs. (pdf)
STEM-NeRF use a differentiable image formation model for Scanning Transmission Electron Microscopes (STEMs) (pdf)
Concluding Thoughts
I am happy that with Panoptic Neural Fields I am finally myself a co-author on a NerF paper, but this is probably the last of these blog posts I will write: it is getting too hard to keep track of all the papers in this space, and growth seems exponential. It is increasingly hard, as well, to come up with ideas in this space without being scooped: I myself was scooped after some months of work on an idea, and I know of many others that found themselves in the same boat. Nevertheless, it is an exciting time to be in 3D computer vision, and I am excited to see what the future will bring.
]]>Important note: all of the images below are reproduced from the cited papers, and the copyright belongs to the authors or the organization that published their papers, like IEEE. Below I reproduce a key figure for some papers under the fair use clause of copyright law.
NeRF
A NeRF stores a volumetric scene representation as the weights of an MLP, trained on many images with known pose.
NeRF was introduced in the (recent but already seminal) Neural Radiance Fields paper by Mildenhall et al. at ECCV 2020. Given a set of posed images, a NeRF model regresses density and color in a 3D volume using a multi-layer perceptron (MLP), that becomes a representation of the 3D scene. One can then use an easily differentiable numerical integration method to approximate a true volumetric rendering step.
As I have argued, the impact of the NeRF paper lies in its brutal simplicity: just an MLP taking in a 5D coordinate and outputting density and color. However, vanilla NeRF left many opportunities to improve upon:
- It is slow, both for training and rendering.
- It can only represent static scenes
- It “bakes in” lighting
- A trained NeRF representation does not generalize to other scenes/objects
Some of the early efforts to improve on NeRF are chronicled on my NeRF Explosion 2020 blog post. In a follow-up on that post, below are all the papers at ICCV’21 that I could find by scanning titles and reading the associated papers.
Fundamentals
Several projects/papers address the fundamentals of view-synthesis with NeRF-like methods in the original, fully-posed multi-view setup:
 Mip-NeRF address the severe aliasing artifacts from vanilla NeRF by adapting the mip-map idea from graphics and replacing sampling the light field by integrating over conical sections along a the viewing rays.
Mip-NeRF address the severe aliasing artifacts from vanilla NeRF by adapting the mip-map idea from graphics and replacing sampling the light field by integrating over conical sections along a the viewing rays.
MVSNeRF trains a model across many scenes and then renders new views conditioned on only a few posed input views, using intermediate voxelized features that encode the volume to be rendered.
DietNeRF is a very out-of-the box method that supervises the NeRF training process by a semantic loss, created by evaluating arbitrary views using CLIP, so it can learn a NeRF from a single view for arbitrary categories.
UNISURF propose to replace the density in NeRF with occupancy, and hierarchical sampling with root-finding, allowing to do both volume and surface rendering for much improved geometry.
NerfingMVS use a sparse depth map from an SfM pipeline to train a scene-specific depth network that subsequently guides the adaptive sampling strategy in NeRF.
Performance
The slow rendering/training of NeRF prompted many more papers on speeding up NeRf, mostly focused on rendering:
FastNeRF factorizes the NeRF volume rendering equation into two branches that are combined to give the same results as NeRF, but allow for much more efficient caching, yielding a 3000x speed up.
KiloNeRF replaces a single large NeRF-MLP with thousands of tiny MLPs, accelerating rendering by 3 orders of magnitude.

PlenOctrees introduce NeRF-SH that uses spherical harmonics to model view-dependent color, and then compresses that into a octree-like data-structure for rendering the result 3000 faster than NeRF.
SNeRG precompute and “bake” a NeRF into a new Sparse Neural Radiance Grid (SNeRG) representation, enabling real-time rendering.
RtS focuses on rendering derivatives efficiently and correctly for a variety of surface representations, including NeRF, using a fast “Surface NeRF” or sNerF renderer.
Pose-free
Another trend is to remove the need for (exact) pose supervision, which started with ‘NeRF–’ (on Arxiv), and is done by no less than three papers at ICCV:
BARF optimizes for the scene and the camera poses simultaneously, as in “bundle adjustment”, in a coarse-to-fine manner.

SCNeRF is similar to BARF, but additionally optimizes over intrinsics, including radial distortion and per-pixel non-linear distortion.
GNeRF distinguishes itself from other the pose-free NeRF efforts by virtue of a “rough initial pose” network, which uses GAN-style training a la GRAF, which solves the (hard) initialization problem.
Conditional
One of the largest areas of activity, at least in terms of number of papers, is conditioning NeRF-like models on various latent codes:
GRF is, like PixelNeRF and IBRNet at CVPR, closer to image-based rendering, where only a few images are used at test time. Unlike PixelNeRF GRF operates in a canonical space rather than in view space.
GSN is a generative model for scenes: it takes a global code that is translated into a grid of local codes, each associated with a local radiance model. A small convnet helps upscaling the final output.

GANcraft translates a semantic block world into a set of voxel-bound NeRF-models that allows rendering of photorealistic images corresponding to this “Minecraft” world, additionally conditioned a style latent code.
CodeNeRF Trains a GRAF-style conditional NeRF (a shape and appearance latent code) and then optimizes at inference time over both latent codes and the object pose.
Composition
Conditional NeRFs are the bread and butter of efforts that do various cool things with composing scenes:
EditNeRF learns a category-specific conditional NeRF model, inspired by GRAF but with an instance-agnostic branch, and show a variety of strategies to edit both color and shape interactively.

ObjectNeRF trains a voxel embedding feeding two pathways: scene and objects. By modifying the voxel embedding the objects can be moved, cloned, or removed.
Dynamic
At least four efforts focus on dynamic scenes, using a variety of schemes, including some that I already discussed earlier:
Teaser videos from the Nerfies web-page showing how a casually captured “selfie video” can be turned into free-viewpoint videos, by fitting a deformation field in addition to the usual NeRF density/color representation.
Nerfies and its underlying D-NeRF model deformable videos using a second MLP applying a deformation for each frame of the video.
NeRFlow is a concurrent effort, which learns “a single consistent continuous spatial-temporal radiance field that is constrained to generate consistent 4D view synthesis across both space and time”.
NR-NeRF also uses a deformation MLP to model non-rigid scenes. It has no reliance on pre-computed scene
AD-NeRF train a conditional nerf from a short video with audio, concatenating DeepSpeech features and head pose to the input, enabling new audio-driven synthesis as well as editing of the input clip.
DynamicVS is attacking the very challenging free-viewpoint video synthesis problem, and uses scene-flow prediction along with many regularization results to produce impressive results.
Articulated
Building on this, a cool trend is skeleton-driven NeRFs, that promise to be useful for animating avatars and the like:
NARF use pose supervision to train a small local occupancy network per articulated part, which is then used to modulate a conditionally trained NeRF model.
AnimatableNeRF use a tracked skeleton from mocap data and multi-view video to train skeleton-based blend-fields that then transform the radiance field, enabling skeleton-driven synthesis of people’s avatars.
Other
Finally, here are some other very cool papers using NeRF-technology that defy easy categorization:

IMAP is an awesome paper that uses NeRF as the scene representation in an online visual SLAM system, learning a 3D scene online and tracking a moving camera against it.
MINE learns to predict a density/color multi-plane representation, conditioned on a single image, which can then be used for NeRF-style volume rendering.
NeRD or “Neural Reflectance Decomposition” uses physically-based rendering to decompose the scene into spatially varying BRDF material properties, enabling re-lighting of the scene.
Semantic-NERF add a segmentation renderer before injecting viewing directions into NeRF and generate high resolution semantic labels for a scene with only partial, noisy or low-resolution semantic supervision.

CO3D contributes an amazing dataset of annotated object videos, and evaluates 15 methods on single-scene reconstruction and learning 3D object categories, including a new SOTA “NerFormer” model.
Finally, CryoDRGN2 attacks the challenging problem of reconstructing protein structure and pose from a “multiview” set of cryo-EM density images. It is unique among NeRF-style papers as it works in the Fourier domain.
Agenda for ICCV
For people attending ICCV, here is a quick guide to all the sessions where the papers above will be presented (all posted times are in EDT):
Session 3
Paper Session 3A and 3B: Tuesday, October 12 12:00 PM – 1:00 PM and Thursday, October 14, 7:00 PM – 8:00 PM
- CryoDRGN2: CryoDRGN2: Ab initio neural reconstruction of 3D protein structures from real cryo-EM images (Other)
Session 5
Paper Session 5A and 5B: Tuesday, October 12, 4:00 PM – 5:00 PM and Thursday, October 14, 9:00 AM – 10:00 AM
- Mip-NeRF: Mip-NeRF: A Multiscale Representation for Anti-Aliasing Neural Radiance Fields (Fundamentals)
- DietNeRF: Putting NeRF on a Diet: Semantically Consistent Few-Shot View Synthesis (Fundamentals)
- UNISURF: UNISURF: Unifying Neural Implicit Surfaces and Radiance Fields for Multi-View Reconstruction (Fundamentals)
- NerfingMVS: NerfingMVS: Guided Optimization of Neural Radiance Fields for Indoor Multi-View Stereo (Fundamentals)
- GNeRF: GNeRF: GAN-Based Neural Radiance Field Without Posed Camera (Pose-free)
- BARF: BARF: Bundle-Adjusting Neural Radiance Fields (Pose-free)
- SCNeRF: Self-Calibrating Neural Radiance Fields (Pose-free)
- PlenOctrees: PlenOctrees for Real-Time Rendering of Neural Radiance Fields (Performance)
- SNeRG: Baking Neural Radiance Fields for Real-Time View Synthesis (Performance)
- RtS: Differentiable Surface Rendering via Non-Differentiable Sampling (Performance)
- EditNeRF: Editing Conditional Radiance Fields (Composition)
- Nerfies: Nerfies: Deformable Neural Radiance Fields (Dynamic)
- AD-NeRF: AD-NeRF: Audio Driven Neural Radiance Fields for Talking Head Synthesis (Dynamic)
- DynamicVS: Dynamic View Synthesis from Dynamic Monocular Video (Dynamic)
- NARF: Neural Articulated Radiance Field (Articulated)
- IMAP: iMAP: Implicit Mapping and Positioning in Real-Time (Other)
Session 8
Paper Session 8A and 8B: Wednesday, October 13, 9:00 AM – 10:00 AM and Friday, October 15, 4:00 PM – 5:00 PM
- CO3D: Common Objects in 3D: Large-Scale Learning and Evaluation of Real-life 3D Category Reconstruction (Other)
Session 10
Paper Session 10A and 10B: Wednesday, October 13, 5:00 PM – 6:00 PM and Friday, October 15, 10:00 AM – 11:00 AM
- CodeNeRF: CodeNeRF: Disentangled Neural Radiance Fields for Object Categories (Conditional)
- NR-NeRF: Non-Rigid Neural Radiance Fields: Reconstruction and Novel View Synthesis of a Deforming Scene from Monocular Video (Dynamic)
- NeRD: NeRD: Neural Reflectance Decomposition from Image Collections (Other)
- MINE: MINE: Towards Continuous Depth MPI With NeRF for Novel View Synthesis (Other)
Session 11
Paper Session 11A and 11B: Wednesday, October 13, 6:00 PM – 7:00 PM and Friday, October 15,11:00 AM – 12:00 PM
- MVSNeRF: MVSNeRF: Fast Generalizable Radiance Field Reconstruction From Multi-View Stereo (Fundamentals)
- FastNeRF: FastNeRF: High-Fidelity Neural Rendering at 200FPS (Performance)
- KiloNeRF: KiloNeRF: Speeding Up Neural Radiance Fields With Thousands of Tiny MLPs (Performance)
- GSN: Unconstrained Scene Generation With Locally Conditioned Radiance Fields (Conditional)
- GANcraft: GANcraft: Unsupervised 3D Neural Rendering of Minecraft Worlds (Conditional)
- ObjectNeRF: Learning Object-Compositional Neural Radiance Field for Editable Scene Rendering (Composition)
- NeRFlow: Neural Radiance Flow for 4D View Synthesis and Video Processing (Dynamic)
- AnimatableNeRF: Animatable Neural Radiance Fields for Modeling Dynamic Human Bodies (Articulated)
Session 12
Paper Session 12A and 12B: Wednesday, October 13, 7:00 PM – 8:00 PM and Friday, October 15, 12:00 PM – 1:00 PM
- GRF: GRF: Learning a General Radiance Field for 3D Scene Representation and Rendering (Conditional)
- Semantic-NERF: In-Place Scene Labelling and Understanding with Implicit Scene Representation (Other)
Concluding Thoughts
It is clear that neural radiance fields have created somewhat of a revolution in the areas of 3D representation and view-synthesis, as evidenced by the 30+ papers above in a single conference, merely a year after the NeRF paper was published at ECCV. I have no “deep” thoughts to share about this at the moment, but I hope you at least enjoyed the rundown above!
]]>The result that got me hooked on wanting to know everything about NeRF :-).
Besides the COVID-19 pandemic and political upheaval in the US, 2020 was also the year in which neural volume rendering exploded onto the scene, triggered by the impressive NeRF paper by Mildenhall et al. This blog post is my way of getting up to speed in a fascinating and very young field and share my journey with you; I created it for the express intent to teach this material in a grad computer vision course. To be clear, I have not contributed to any of the papers below. I wish I had, as I stand in awe of the explosion of creative energy around this topic!
To start with some definitions, the larger field of Neural rendering is defined by the excellent review paper by Tewari et al. as
“deep image or video generation approaches that enable explicit or implicit control of scene properties such as illumination, camera parameters, pose, geometry, appearance, and semantic structure.”
It is a novel, data-driven solution to the long-standing problem in computer graphics of the realistic rendering of virtual worlds.
Neural volume rendering refers to methods that generate images or video by tracing a ray into the scene and taking an integral of some sort over the length of the ray. Typically a neural network like a multi-layer perceptron encodes a function from the 3D coordinates on the ray to quantities like density and color, which are integrated to yield an image.
Outline: Below I first discuss some very relevant related work that lead up to the “NeRF explosion”, then discuss the two papers that I think started it all, followed by an annotated bibliography on follow-up work. I am going wide rather than deep, but provide links to all project sites or Arxiv entries, so you can deep-dive yourself. Besides this post, the review paper mentioned above is great background, and Yen-Chen Lin, a PhD student at MIT CSAIL, has curated an Awesome NeRF repository on GitHub with papers, bibtex, and links to some talks.
Important note: all of the images below are reproduced from the cited papers, and the copyright belongs to the authors or the organization that published their papers, like IEEE. Below I reproduce a key figure for each paper under the fair use clause of copyright law.
The Prelude: Neural Implicit Surfaces
The immediate precursors to neural volume rendering are the approaches that use a neural network to define an implicit surface representation. Many 3D-aware image generation approaches used voxels, meshes, point clouds, or other representations, typically based on convolutional architectures. But at CVPR 2019, no less than three papers introduced the use of neural nets as scalar function approximators to define occupancy and/or signed distance functions.
Occupancy networks
Occupancy networks is one of two methods at CVPR 2019 that introduce implicit, coordinate-based learning of occupancy. A network consisting of 5 ResNet blocks take a feature vector and a 3D point and predict binary occupancy. They also show single-view reconstruction results on real images from KITTI.
Occupancy as a learned classifier.
Occupancy Networks: Learning 3D Reconstruction in Function Space, Lars Mescheder, Michael Oechsle, Michael Niemeyer, Sebastian Nowozin, and Andreas Geiger, CVPR 2019.
IM-Net
IM-NET is the other one, and uses a 6-layer MLP decoder that predicts binary occupancy given a feature vector and a 3D coordinate. The authors show that this “implicit decoder” can be used for auto-encoding, shape generation (GAN-style), and single-view reconstruction.
3D Shapes generated using a GAN using IM-NET as the decoder.
Learning Implicit Fields for Generative Shape Modeling, Zhiqin Chen and Hao Zhang, CVPR 2019.
DeepSDF
Finally, also at CVPR 2019, DeepSDF directly regresses a signed distance function or SDF, rather than binary occupancy, from a 3D coordinate and optionally a latent code. It uses an 8-layer MPL with skip-connections to layer 4 (setting a trend!) that outputs the signed distance.
The Stanford bunny rendered through a learned signed distance function (SDF).
DeepSDF: Learning Continuous Signed Distance Functions for Shape Representation, Jeong Joon Park, Peter Florence, Julian Straub, Richard Newcombe, and Steven Lovegrove, CVPR 2019.
PIFu
Building on this, the ICCV 2019 PIFu paper showed that it was possible to learn highly detailed implicit models by re-projecting 3D points into a pixel-aligned feature representation. This idea will later be reprised, with great effect, in PixelNeRF.
PIFu regresses color and an SDF from pixel aligned features, enabling single-view reconstruction.
PIFu: Pixel-Aligned Implicit Function for High-Resolution Clothed Human Digitization, Shunsuke Saito, Zeng Huang, Ryota Natsume, Shigeo Morishima, Angjoo Kanazawa, and Hao Li, ICCV 2019.
Building on Implicit Functions
Several other approaches built on top of the implicit function idea, and generalize to training from 2D images. Of note are Structured Implicit Functions, CvxNet, BSP-Net, Deep Local Shapes, Scene Representation Networks, Differentiable Volumetric Rendering, the Implicit Differentiable Renderer, and NASA.
Also published at ICCV 2019, Structured Implicit Functions showed that you can combine these implicit representations, e.g., simply by summing them. Another way to combine signed distance functions is by taking a pointwise max (in 3D), as done in CvxNet, a paper which has a number of other elegant techniques to reconstruct an object from depth or RGB images. BSP-Net is in many ways similar to CvxNet, but uses binary space partitioning at its core, yielding a method that outputs polygonal meshes natively, rather than via an expensive meshing method. Finally, Deep Local Shapes, store a DeepSDF latent code in a voxel grid as to represent larger, extended scenes.
A Scene Representation Network or SRN is quite similar to DeepSDF in terms of architecture, but adds a differentiable ray marching algorithm to find the closest point of intersection of a learnt implicit surface, and add an MLP to regress color, enabling it to be learned from multiple posed images.
Similar to the SRN work, the CVPR 2020 Differentiable Volumetric Rendering paper shows that an implicit scene representation can be coupled with a differentiable renderer, making it trainable from images. They use the term volumetric renderer, but really the main contribution is a clever trick to make the computation of depth to the implicit surface differentiable: no integration over a volume is used.
The Implicit Differentiable Renderer work from Weizmann presented at NeurIPS 2020 is similar, but it has a more sophisticated surface light field representation, and the authors also show that they can refine camera pose during training.
Finally, Neural Articulated Shape Approximation or NASA composes implicit functions to represent articulated objects such as human bodies.
Neural Volume Rendering
As far as I know, two papers introduced volume rendering into the view synthesis field, with NeRF being the simplest and ultimately the most influential.
A word about naming: the two papers below and all Nerf-style papers since build upon the work above that encode implicit surfaces, and so the term implicit neural methods is used quite a bit. However, I personally associate that term more with level-set representations for curves and surfaces. What they do have in common with occupancy/SDF-style networks is that MLP’s are used as functions from coordinates in 3D to scalar or multi-variate fields, and hence these methods are also sometimes called coordinate-based scene representation networks. Of that larger set, we’re concerned with volume rendering versions of those below.
Neural Volumes
AFAIK, true volume rendering for view synthesis was introduced in the Neural Volumes paper from Facebook Reality Labs, regressing a 3D volume of density and color, albeit still in a voxel-based representation.
In the “Neural Volumes” approach, a latent code is decoded into a 3D volume, and a new image is then obtained by volume rendering.
Neural Volumes: Learning Dynamic Renderable Volumes from Images, Stephen Lombardi, Tomas Simon, Jason Saragih, Gabriel Schwartz, Andreas Lehrmann, and Yaser Sheikh, Siggraph 2019.
One of the most interesting quotes from this paper hypothesizes about the success of neural volume rendering approaches (emphasis is mine):
[We] propose using a volumetric representation consisting of opacity and color at each position in 3D space, where rendering is realized through integral projection. During optimization, this semi-transparent representation of geometry disperses gradient in- formation along the ray of integration, effectively widening the basin of convergence, enabling the discovery of good solutions.
I think that resonates with many people, and partially explains the success of neural volume rendering. I won’t go into any detail about the method itself, but the paper is a great read. Instead, let’s dive right into NeRF itself below…
NeRF
The paper that got everyone talking was the Neural Radiance Fields or NeRF paper, with three first authors from Berkeley. In essence, they take the DeepSDF architecture but regress not a signed distance function, but density and color. They then use an (easily differentiable) numerical integration method to approximate a true volumetric rendering step.
The figures below illustrate both the overall setup and some detail about the rendering procedure.
New views are rendered by integrating the density and color at regular intervals along each viewing ray.
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis, Ben Mildenhall, Pratul Srinivasan, Matthew Tancik*, Jonathan Barron, Ravi Ramamoorthi, Ren Ng, ECCV 2020.
One of the reasons NeRF is able to render with great detail is because it encodes a 3D point and associated view direction on a ray using periodic activation functions, i.e., Fourier Features. This innovation was later generalized to multi-layer networks with periodic activations, aka SIREN (SInusoidal REpresentation Networks). Both were published later at NeurIPS 2020.
While the NeRF paper was ostensibly published at ECCV 2020, at the end of August, it first appeared on Arxiv in the middle of March, sparking an explosion of interest on twitter. I remember seeing the video and being amazed at the quality of the synthesized views, but even more so at the incredible detail in the visualized depth maps, e.g., the figure at the top of this post, or this Christmas tree:
It is worth visiting the (elaborate) project site and looking at all the videos. If you’re new to NeRF, prepare to be amazed :-)
Arguably, the impact of the NeRF paper lies in its brutal simplicity: just an MLP taking in a 5D coordinate and outputting density and color. There are some bells and whistles, notably the positional encoding and a stratified sampling scheme, but many researchers were taken aback (I think) that such a simple architecture could yield such impressive results. That being said, vanilla NeRF left many opportunities to improve upon:
- It is slow, both for training and rendering.
- It can only represent static scenes
- It “bakes in” lighting
- A trained NeRF representation does not generalize to other scenes/objects
In this Arxiv-fueled computer vision world, these opportunities were almost immediately capitalized on, with almost 25 papers appearing on Arxiv over the past 6 months, the vast majority in the last month even (presumably, a subset of the +10K CVPR submissions). Below I list all of them I could find, and discuss representative papers in each category.
Performance
Several projects/papers aim at improving the rather slow training and rendering time of the original NeRF paper.
Using an octree as an organizing data structure, the NSVF paper claims both Neural Volumes and NeRF as special cases. Feature embeddings on the vertices of each voxel are interpolated and fed to a (smaller) NLP outputting density and color, as in NeRF.
Neural Sparse Voxel Fields, Lingjie Liu, Jiatao Gu, Kyaw Zaw Lin, Tat-Seng Sua, and Christian Theobalt, NeurIPS 2020.
Neural Sparse Voxel Fields (see Figure above) organizes the scene into a sparse voxel octree to speed up rendering by a factor of 10.
NERF++ proposed to model the background with a separate NeRF to handle unbounded scenes.
DeRF decomposes the scene into “soft Voronoi diagrams” to take advantage of accelerator memory architectures.
AutoInt greatly speeds up rendering by learning the volume integral directly. This is an interesting and much more general paper, BTW!
Learned Initializations uses meta-learning to find a good weight initialization for faster training.
JaxNeRF uses JAX (https://github.com/google/jax) to dramatically speed up training, from days to hours.
Dynamic
At least four efforts focus on dynamic scenes, using a variety of schemes.
Teaser videos from the Nerfies web-page showing how a casually captured “selfie video” can be turned into free-viewpoint videos, by fitting a deformation field in addition to the usual NeRF density/color representation.
Nerfies (see video above) and its underlying D-NeRF model deformable videos using a second MLP applying a deformation for each frame of the video.
Space-Time Neural Irradiance Fields simply use time as an additional input. Carefully selected losses are needed to successfully train this method to render free-viewpoint videos (from RGBD data!).
Neural Scene Flow Fields instead train from RGB but use monocular depth predictions as a prior, and regularize by also outputting scene flow, used in the loss.
D-NeRF is quite similar to the Nerfies paper and even uses the same acronym, but seems to limit deformations to translations.
NeRFlow is the latest dynamic NeRF variant to appear on Arxiv, and also uses a Nerfies style deformation MLP, with a twist: it integrates scene flow across time to obtain the final deformation.
Portrait
Besides Nerfies, two other papers focus on avatars/portraits of people.
Dynamic Neural Radiance Fields are quite similar to Nerfies in terms of task, but use a morphable face model to simplify training and rendering.
Dynamic Neural Radiance Fields for Monocular 4D Facial Avatar Reconstruction, Guy Gafni, Justus Thies, Michael Zollhöfer, and Matthias Nießner.
DNRF is focused on 4D avatars and hence impose a strong inductive bias by including a deformable face model into the pipeline. This gives parametric control over the dynamic NeRF.
Portrait NeRF creates static NeRF-style avatars, but does so from a single RGB headshot. To make this work, light-stage training data is required.
Relighting
Another dimension in which NeRF-style methods have been augmented is in how to deal with lighting, typically through latent codes that can be used to re-light a scene.
NeRF-W was one of the first follow-up works on NeRF, and optimizes a latent appearance code to enable learning a neural scene representation from less controlled multi-view collections.
Neural Reflectance Fields improve on NeRF by adding a local reflection model in addition to density. It yields impressive relighting results, albeit from single point light sources.
NeRV uses a second “visibility” MLP to support arbitrary environment lighting and “one-bounce” indirect illumination.
NeRD, as other methods in this section, go beyond NeRF in learning more complex local reflectance models along with density. NeRD itself also learns a global illumination model for each scene in the training set , as illustrated in panel d.
NeRD: Neural Reflectance Decomposition from Image Collections, Mark Boss, Raphael Braun, Varun Jampani, Jonathan Barron, Ce Liu, and Hendrik Lensch.
NeRD or “Neural Reflectance Decomposition” is another effort in which a local reflectance model is used, and additionally a low-res spherical harmonics illumination is inferred for a given scene.
Shape
Latent codes can also be used to encode shape priors.
GRAF (and other conditional variants of NeRF) add latent codes for shape and/or appearance, so neural volume rendering can be used in generative fashion, as well as inference.
GRAF: Generative Radiance Fields for 3D-Aware Image Synthesis, Katja Schwarz, Yiyi Liao, Michael Niemeyer, Andreas Geiger.
GRAF i.e., a “Generative model for RAdiance Fields”is a conditional variant of NeRF, adding both appearance and shape latent codes, while viewpoint invariance is obtained through GAN-style training.
pi-GAN Is similar to GRAF but uses a SIREN-style implementation of NeRF, where each layer is modulated by the output of a different MLP that takes in a latent code.
pixelNeRF is closer to image-based rendering, where N images are used at test time. It is based on PIFu, creating pixel-aligned features that are then interpolated when evaluating a NeRF-style renderer.
GRF is pretty close to pixelNeRF in setup, but operates in a canonical space rather than in view space.
Composition
Clearly (?) none of this will scale to large scenes composed of many objects, so an exciting new area of interest is how to compose objects into volume-rendered scenes.
Neural Scene Graphs supports several object-centric NeRF models in a scene graph.
STaR is similar to the Neural Scene Graphs paper, limited to a single object, but not requiring pose supervision at training time.
GIRAFFE supports composition by having object-centric NeRF models output feature vectors rather than color, then compose via averaging, and render at low resolution to 2D feature maps that are then upsampled in 2D.
Object scattering functions (OSFs) were proposed in a very recent paper to support composing scenes with arbitrary object positions (left) and lighting (right).
Object-Centric Neural Scene Rendering, Michelle Guo, Alireza Fathi, Jiajun Wu, and Thomas Funkhouser


Object-Centric Neural Scene Rendering learns “Object Scattering Functions” in object-centric coordinate frames, allowing for composing scenes and realistically lighting them, using Monte Carlo rendering.
Pose Estimation
Finally, at least one paper has used NeRF rendering in the context of (known) object pose estimation.
The iNeRF teaser GIF: iNERF uses NeRF as a synthesis model in a pose optimizer.
iNeRF: Inverting Neural Radiance Fields for Pose Estimation, Lin Yen-Chen, Peter Florence, Jonathan Barron, Alberto Rodriguez, Phillip Isola, and Tsung-Yi Lin.
iNeRF uses a NeRF MLP in a pose estimation framework, and is even able to improve view synthesis on standard datasets by fine-tuning the poses. However, it does not yet handle illumination.
Concluding Thoughts
Neural Volume Rendering and NeRF-style papers have exploded on the scene in 2020, and the last word has not been said. This post definitely does not rise to the level of a thorough review, but I hope that this “explosition” is useful for people working in this area or thinking of joining the fray.
However, if I may venture an opinion, it is far from clear -even in the face of all this excitement- that neural volume rendering is going to carry the day in the end. While the real world does have haze, smoke, transparencies, etcetera, in the end most of the light is scattered into our eyes from surfaces. NeRF-style networks might be easily trainable because of their volume-based approach, but I already see a trend where authors are trying to discover or guess the surfaces after convergence. In fact, the stratified sampling scheme in the original NeRF paper is exactly that. Hence, as we learn from the NeRF explosion I can easily see the field moving back to SDF-style implicit representations or even voxels, at least at inference time.
I want to conclude by giving a shoutout to the 152 authors of the papers I mentioned above: Matan Atzmon, Jonathan Barron, Ronan Basri, Mojtaba Bemana, Alexander Bergman, Sai Bi, Mark Boss, Sofien Bouaziz, Raphael Braun, Rohan Chabra, Eric Chan, Zhiqin Chen, Forrester Cole, Enric Corona, Boyang Deng, Alexey Dosovitskiy, Yilun Du, Daniel Duckworth, Alireza Fathi, Pete Florence, William Freeman, Thomas Funkhouser, Guy Gafni, Meirav Galun, Chen Gao, Andreas Geiger, Kyle Genova, Dan Goldman, Vladislav Golyanik, Jiatao Gu, Michelle Guo, Miloš Hašan, Felix Heide, Geoffrey Hinton, Yannick Hold-Geoffroy, Zeng Huang, Jia-Bin Huang, Eddy Ilg, Phillip Isola, Varun Jampani, Timothy Jeruzalski, Wei Jiang, Angjoo Kanazawa, Yoni Kasten, Peter Kellnhofer, Changil Kim, Julian Knodt, Vladlen Koltun, Johannes Kopf, David Kriegman, Wei-Sheng Lai, Christoph Lassner, Andreas Lehrmann, Hendrik Lensch, Jan Lenssen, JP Lewis, Zhengqi Li, Ke Li, Hao Li, Chia-Kai Liang, Yiyi Liao, Kyaw Zaw Lin, Tsung-Yi Lin, David Lindell, Yaron Lipman, Lingjie Liu, Ce Liu, Stephen Lombardi, Steven Lovegrove, Zhaoyang Lv, Fahim Mannan, Julien Martel, Ricardo Martin-Brualla, Lars Mescheder, Ben Mildenhall, Marco Monteiro, Dror Moran, Francesc Moreno-Noguer, Shigeo Morishima, Karol Myszkowski, Ryota Natsume, Richard Newcombe, Ren Ng, Michael Niemeyer, Matthias Nießner, Simon Niklaus, Mohammad Norouzi, Sebastian Nowozin, Michael Oechsle, Julian Ost, Lionel Ott, Jeong Joon Park, Keunhong Park, Gerard Pons-Moll, Albert Pumarola, Noha Radwan, Ravi Ramamoorthi, Fabio Ramos, Daniel Rebain, Gernot Riegler, Tobias Ritschel, Alberto Rodriguez, Shunsuke Saito, Mehdi Sajjadi, Jason Saragih, Aaron Sarna, Divi Schmidt, Tanner Schmidt, Gabriel Schwartz, Katja Schwarz, Hans-Peter Seidel, Steven Seitz, Yaser Sheikh, Yichang Shih, Tomas Simon, Utkarsh Sinha, Vincent Sitzmann, Noah Snavely, Pratul Srinivasan, Julian Straub, Tat-Seng Sua, Kalyan Sulkavalli, Andrea Tagliasacchi, Matthew Tancik, Joshua Tenenbaum, Ayush Tewari, Christian Theobalt, Justus Thies, Nils Thürey, Edgar Tretschk, Alex Trevithick, Daniel Vlasic, Oliver Wang, Terrence Wang, Gordon Wetzstein, Jiajun Wu, Wenqi Xian, Zexiang Xu, Bo Yang, Lior Yariv, Soroosh Yazdani, Vickie Ye, Lin Yen-Chen, Kwang Moo Yi, Alex Yu, Hong-Xing Yu, Wentao Yuan, Hao Zhang, Kai Zhang, Xiuming Zhang, Yinan Zhang, and Michael Zollhöfer.
]]>