|
|
|
| CARVIEW |
My recent presentations at SWIB23 (YouTube), and the Bibframe Workshop in Europe, attracted many questions; regarding the how, what, and most importantly the why, of the unique cloud-based Linked Data Management & Discovery System (LDMS) we developed, in partnership with metaphacts and Kewmann, in a two year project for the National Library Board of Singapore (NLB).
Several of the answers were technical in nature. However, somewhat surprisingly they were mostly grounded in what could best be described as business needs, such as:
- Seamless Knowledge Graph integration of records stored, and managed in separate systems
- No change required to the cataloging processes within those systems
- Near real time propagation of source data changes into the consolidated Knowledge Graph
- Consolidated view of all entity references presented for search, discovery, and display
- Individual management, update, or suppression of knowledge graph entities and attributes
Let me explore those a little…
✤ Seamless Knowledge Graph integration of records stored, and managed in separate systems – the source data for NLB’s Knowledge Graph comes from four different systems.
- Library System (ILS) – contains 1.5M+ bibliographic records – exported in MARC-XML format
- Authority System (TTE) – a bespoke system for managing thousands of Singapore and SE Asian name authority records for people, organisation, and places – exported in bespoke CSV format
- Content Management System (CMS) – host of content and data for several individual web portals, serving music, pictures, history, art, and information articles, etc. – exported in Dublin Core format
- National Archives (NAS) – data and content from documents, papers, photographs, maps, speeches, interviews, posters, etc. – exported in Dublin Core format
These immediately provided two significant challenges. Firstly, none of the exported formats are a linked data format. Secondly, the exported formats are different – even the two DC formats differ.
An extensible generic framework to support individual ETL pipeline processes was developed, one pipeline for each source system. Each extracts data from source data files, transforms them into a linked data form, and loads them into the knowledge graph. The pipeline for ILS data utilises open source tools from the Library of Congress (marc2bibframe2) and the Bibframe2Schema.org Community to achieve this in a ‘standard’ way. The other three pipelines use a combination of source specific scripting and transform logic.
When establishing the data model for the knowledge graph, a combination of two vocabularies were chosen. BIBFRAME, to capture detailed bibliographic requirements in a [library sector] standard way, and Schema.org to capture the attributes of all entities in a web-friendly form. Schema.org was chosen as a lingua franca vocabulary (all entities are described in Schema.org in addition to any other terms). This greatly simplified the discovery, management and processing of entities in the system.
✤ No change required to the cataloging processes within those systems – the introduction of a Linked Data system, has established a reconciled and consolidated view of resources across NLB’s systems, but it has not replaced those systems.
This approach has major benefits in enabling the introduction and explorative implementation of Linked Data techniques without being constrained by previous approaches, requiring a big-bang switchover, or directly impacting the day-to-day operations of currently established systems and the teams that manage them.
However, it did introduce implementation challenges for the LDMS. It could not be considered as the single source of truth for source data. The data model and management processes had to be designed to represent a consolidated source of truth for each entity, that may change due to daily cataloging activity in source systems.
✤ Near real time propagation of source data changes into the consolidated Knowledge Graph – unlike many Knowledge Graph systems which are self contained and managed, it is not just local edits that need to be made visible to users in a timely manner. The LDMS receives a large number, sometimes thousands in a day, of updates from source systems. For example, a cataloguer making a change or addition in the library system would expect to see it reflected within the LDMS within a day.
This turn around is achieved by the automatic operation of the ETL pipelines. On a daily basis they check a shared location on the NLB network, to where update files are exported from source systems. Received files are then processed through the appropriate pipeline and loaded into the knowledge graph. Activity logs and any issues arising are reported to the LDMS curator team.
✤ Consolidated view of all entity references presented for search, discovery, and display – in large distributed environments there are inevitably duplicate references to people, places, subjects, organisations, and creative work entities, etc. In practice, these duplications can be numerous.
For example, emanating from the transformation of library system data, there are some 160 individual person entity references for Lee, Kuan Yew (1st Prime Minister of Singapore). Another example, Singapore Art Museum, results in 21 CMS, 1 TTE, and 66 ILS entities. In each case, users would only expect to discover and view one consolidated version of each.
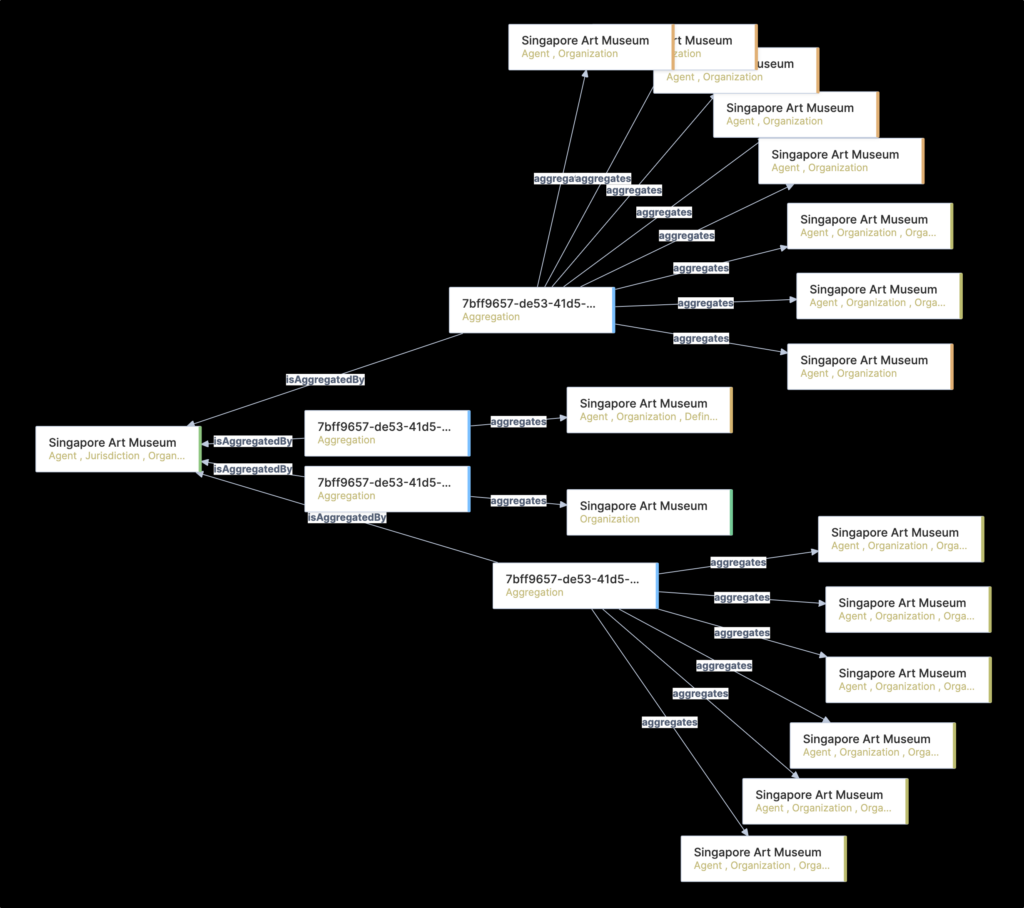
To facilitate the creation of a consolidated single view, whilst acknowledging constantly changing source data, a unique aggregation data model was developed. Aggregation entities track the relationship between source data entities, and then between sources, to resolve into primary entities used for discovery and display.
This approach has resulted in some 6 million primary entities, to be exposed to users, derived from approximately 70 million source entities.

Another way you could view this is as what I describe as an entity iceberg.
70 million Person, Place, Organization, Work, and Subject entities derived from regular updates from source systems, aggregated and reconciled together below the surface. A process that results in a consolidated viewable iceberg tip of 6 million primary entities.
Managed via a staff interface these primary entities drive knowledge graph search, discovery, and display for users.
✤ Individual management, update, or suppression of knowledge graph entities and attributes – no matter how good automatic processing is, it will never be perfect. Equally, as cataloguers and data curators are aware, issues and anomalies lurk in source data, to become obvious when merged with other data. Be it the addition of new descriptive information, or the suppression of a birth date on behalf of a concerned author, some manual curation will be needed. However, simply editing source entities was not an option, as any changes could well then be reversed by the next ETL operation.

The data management interface of the LDMS provides the capability to manually add new attributes to primary entities and suppress others as required. As the changes are applied at a primary entity level, they are independent from and therefore override constantly updating source data.
The two year project, working in close cooperation with NLB’s Data Team, has been a great one to be part of – developing unique yet generic solutions to specific data integration and knowledge graph challenges.
The project continues, building on the capabilities derived from this constantly updated consolidated view of the resources curated by NLB. Work is already underway in the areas of user interface integration with other systems, and enrichment of knowledge graph data from external sources such as the Library of Congress – Watch this space.
]]> Recently I gave a presentation to the 2023 LD4 Conference on Linked Data entitled From Ambition to Go Live: The National Library Board of Singapore’s journey to an operational Linked Data Management & Discovery System which describes one of the projects I have been busy with for the last couple of years.
Recently I gave a presentation to the 2023 LD4 Conference on Linked Data entitled From Ambition to Go Live: The National Library Board of Singapore’s journey to an operational Linked Data Management & Discovery System which describes one of the projects I have been busy with for the last couple of years.
The whole presentation is available to view on YouTube.
In response to requests for more detail, this post focuses in on one aspect of that project – the import pipeline that on a daily basis automatically ingests MARC data, exported from NLB Singapore’s ILS system, into the Linked Data Management and Discovery System (LDMS).
The LDMS, supporting infrastructure, and user & management interfaces have been created in a two-year project for NLB by a consortium of vendors: metaphacts GmbH, KewMann, and myself as Data Liberate.
The MARC ingestion pipeline is one of four pipelines that keep the Knowledge Graph, underpinning the LDMS, synchronised with additions, updates, and deletions from the many source systems that NLB curate and host. This enables the system to provide a near-real-time reconciled and consolidated linked data view of the entities described across their disparate source systems.
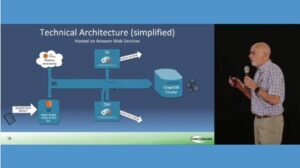
Below is a simplified diagram showing the technical architecture of the LDMS implemented in a Singapore Government instance of Amazon Web Services (AWS). Export files from source systems, are dropped in a shared location where they are picked up by import control scripts, passed to appropriate import pipeline processes, the output from which are then uploaded into a GraphDB Knowledge Graph. The Data Management and Discovery interfaces running on metaphactory platform then interact with that Knowledge Graph.

Having set the scene, let us zoom in on the ILS pipeline and its requirements and implementation.
Input
Individual Marc-XML files, one per MARC record, exported from NLB’s ILS system, are placed in the shared location. They are picked up by timed python scripts and passed for processing.
MARC to BIBFRAME
The first step in the pipeline is to produce BIBFRAME-RDF equivalents to the individual MARC records. For this, use was made of the open-source scripts shared by the Library of Congress (LoC) – marc2bibframe2.
marc2bibframe2 was chosen for a few reasons. Firstly, it closely follows the MARC 21 to BIBFRAME 2.0 Conversion Specifications published by LoC, which are recognised across the bibliographic world. Secondly, they are designed to read MARC-XML files in the form output from the ILS source. Also they are in the form of XSLT scripts which could be easily wrapped and controlled in the chosen python based environment.
That wrapping consists of a python script that takes care of multiple file handling, and caching and reuse of the xslt transform module so that one is not created for every individual file transform. The python script was constructed so that it could be run on a local file system, for development and debug, and also deployed, for production operations, as AWS Lambda virtual processes using AWS S3 virtual file structures.
The output from the process is individual RDF-XML files containing a representation of the entities (Work, Instance, Item, Organization, Person, Subject, etc.) implicitly described in the source MARC data. A mini RDF knowledge graph for each record processed.
BIBFRAME and Schema.org
The next step in the pipeline is to add Schema.org entity types and properties to the BIBFRAME. This is to satisfy the dual requirements in the LDMS for all entities to be described, as a minimum, with Schema.org, and having Schema.org to share on the web.
This step was realised by making use of another open-source project – Bibframe2Schema.org*. Somewhat counter intuitively the core of this project is a SPARQL script, making you think you might need to fully implement an RDF triplestore to use it. Fortunately that is not the case. Taking inspiration from the project’s schemaise.py; a python script was produced to make use of the rdflib python module to simply create a memory triplestore from the contents of each RDF-XML file, then run the SPARQL query against it.
The SPARQL query uses INSERT commands to add Schema.org triples to those loaded into the store created from the BIBFRAME RDF files output form the pipeline’s first step. The final BIBFRAME/Schema.org cocktail of triples are output as RDF files for subsequent loading into the Knowledge Graph.
Using python scripting components shared with the marc2bibframe wrapping scripts, this step has been created to either be tested locally, or run as AWS Lambda processes. Picking up the RDF-XML input files in S3 where they were placed by the first step.
It is never that simple
For the vast majority of needs these two pipeline steps work together well, producing often thousands of RDF files for loading into the Knowledge Graph every day.
However things are never that simple in significant production oriented projects. There are invariably site specific tweaks required to get the results you need from the open-source modules you use. In our case such tweaks included: changing hash URIs to externally referenceable slash URIs; replacing blank nodes with URIs; and correcting a couple of anomalies with the assignment of subject URIs in the LoC script.
Fortunately the schemaise.py script already had the capability to call pre and post processing python modules, which allowed the introduction of some bespoke logic without diverging from the methods of operation of the open-source modules.
And into the graph…
The output from all the pipelines, including ILS, are RDF data files ready for loading into the Knowledge Graph using the standard APIs made available by GraphDB. As entity descriptions are loaded into the Knowledge Graph, reconciliation and consolidation processes are triggered which result in a single real world entity view for users of the system. My next post will provide an insight into how that is achieved.
*Richard Wallis is Chair of the Bibframe2Schema.rg W3C Community Group.
See Richard presenting in person on this and other aspects of this project at the following upcoming conferences:
- SWIB 23 Semantic Web in Libraries Conference September 12th 2023 , Berlin Germany
- BIBFRAME Workshop in Europe September 19th 2023, Brussels Belgium
 I am honoured to have been invited to speak at the CILIP Conference 2019, in Manchester UK, July 3rd. My session, in the RDA, ISNIs and Linked Data track, shares the title of this post: Library Metadata Evolution: The Final Mile?
I am honoured to have been invited to speak at the CILIP Conference 2019, in Manchester UK, July 3rd. My session, in the RDA, ISNIs and Linked Data track, shares the title of this post: Library Metadata Evolution: The Final Mile?
Why this title, and why the question mark?
I have been rattling around the library systems industry/sector for nigh on thirty years, with metadata always being somewhere near the core of my thoughts. From that time as a programmer wrestling with the new to me ‘so-called’ standard MARC; reacting to meet the challenges of the burgeoning web; through the elephantine gestation of RDA; several experiments with linked library data; and the false starts of BIBFRAME, it has consistently never scaled to the real world beyond the library walls and firewall.
When Schema.org arrived on the scene I thought we might have arrived at the point where library metadata could finally blossom; adding value outside of library systems to help library curated resources become first class citizens, and hence results, in the global web we all inhabit. But as yet it has not happened.
The why not yet, is something that has been concerning me of late. The answer I believe is that we do not yet have a simple, mostly automatic, process to take data from MARC, process it to identify entities (Work, Instance, Person, Organisation, etc.) and deliver it as Linked Data (BIBFRAME), supplemented with the open vocabulary used on the web (Schema.org).
Many of the elements of this process are, or nearly are, in place. The Library of Congress site provides conversion scripts from MARCXML to BIBFRAME, the Bibframe2Schema.org group are starting to develop conversion processes to take that BIBFRAME output and add Schema.org.
So what’s missing? A key missing piece is entity reconciliation.
The BIBFRAME conversion scripts identity the Work for the record instance being processed. However, they do not recognise Works they have previously processed. What is needed is a repeatable reliable, mostly automatic process for reconciling the many unnecessarily created duplicate Work descriptions in the current processes. Reconciliation is also important for other entity types, but with the aid of VIAF, ISNI, LC’s name and other identifier authorities, most of the groundwork for those is well established.
There are a few other steps required to achieve the goal of being able to deliver search engine targeted structured library metadata to the web at scale, such as crowbarring the output into out ageing user interfaces, but none I believe more important than giving them data about reconciled entities.
Although my conclusions here may seem a little pessimistic, I am convinced we are on that last mile which will take us to a place and time where library curated metadata is a first class component of search engine knowledge graphs and is likely to lead a user to a library enabled fulfilment as to a commercial one.
[schemaapprating]
]]> The recent release of the Schema.org vocabulary (version 3.5) includes new types and properties, proposed by the W3C Schema Architypes Community Group, specifically target at facilitating the web sharing of archives data to aid discovery.
The recent release of the Schema.org vocabulary (version 3.5) includes new types and properties, proposed by the W3C Schema Architypes Community Group, specifically target at facilitating the web sharing of archives data to aid discovery.
When the Group, which I have the privilege to chair, approached the challenge of building a proposal to make Schema.org useful for archives, it was identified that the vocabulary could be already used to describe the things & collections that you find in archives. What was missing was the ability to identify the archive holding organisation, and the fact that an item is being held in an archives collection.
The first part of this was simple, resulting in the creation of a new Type ArchiveOrganisation. Joining the many subtypes of the generic LocalBusiness type, it inherits all the useful properties for describing such organisations. Using the (Multi Typed Entity – MTE) capability of the vocabulary, it can be used to describe an organisation that is exclusively an Archive or one that has archiving as part of of its remit – for example one that is both a Library and an ArchiveOrganization.
The need to identify the ‘things‘ that make up the content of an archive, be they individual items, collections, or collections of collections resulted in the creation of a second new type: ArchiveComponent.
In theory we could have introduced archive types for each type thing you might find in an archive, such as ArchivedBook, ArchivedPhotograph, etc. – obvious at first but soon gets difficult to scope and maintain. Instead we took the MTE approach of creating a type (ArchiveComponent) could be added to the description of any thing, to provide the archive-ness needed. This applies equally to Collection and individual types such as Book, Photograph, Manuscript etc.
In addition to these two types, a few helpful properties were part of the proposals: holdingArchive & itemLocation are available for ArchiveComponent; archiveHeld for ArchiveOrganization; collectionSize for Collection; materialExtent.
To help get your head around the use of these types and properties, here is a very simple example in JSON-LD format:
{
"@context": "carview.php?tsp=https://schema.org",
"@type": "ArchiveOrganization",
"name": "Example Archives",
"@id": "https://examplearchive.org",
"archiveHeld": {
"@type": ["ArchiveComponent","Collection"],
"@id": "https://examplearchive.org/coll1",
"name": "Example Archive Collection",
"collectionSize": 1,
"holdingArchive": "https://examplearchive.org",
"hasPart": {
"@type": ["ArchiveComponent","Manuscript"],
"@id": "https://examplearchive.org/item1",
"name": "Interesting Manuscript",
"description": "Interesting manuscript - on loan to the British Library",
"itemLocation": "https://bl.uk",
"isPartOf": "https://examplearchive.org/coll1"
}
}
}`
These proposals gained support from many significant organisations and I look forward to seeing these new types and properties in use in the wild very soon helping to make archives and their contents visible and discoverable on the web.
]]>
Yesterday I presented in a session at the IFLA WLIC in Kuala Lumpur – my core theme being that there is a need to use two [linked data] vocabularies when describing library resources — Bibframe for cataloguing and [linked] metadata interchange — Schema.org for sharing on the web for discovery.
 To emphasise the applicability, or lack of, for each vocabulary to these broad use cases I said something like “As my mother would have said: for aiding discovery on the web Bibframe is about as much use as a chocolate teapot ”.
To emphasise the applicability, or lack of, for each vocabulary to these broad use cases I said something like “As my mother would have said: for aiding discovery on the web Bibframe is about as much use as a chocolate teapot ”.
 This was picked up in a tweet by Tina Thomas (@yegtinat):
This was picked up in a tweet by Tina Thomas (@yegtinat):
Useful tidbit about choices #libraries have for discoverability of library catalog content on the web. Bibframe is “about as useful as a chocolate teapot” #wlic2018
Although Tina does reference some context I’m sure her quote (from me) Bibframe is “about as useful as a chocolate teapot” is going to follow me around for some while!
 In the presentation I explored the linked data vocabulary options for libraries and, by implication, their system suppliers. The conclusion being that the two key best options were Bibframe 2.0 and Schema.org — the former for cataloguing support, the latter for providing data on the web (for search engines to consume) to aid discovery beyond library interfaces. The conclusion also being the need to adopt both vocabularies as the pros & cons of each cover the breadth of library linked data use cases, and the mutual limitations of each:
In the presentation I explored the linked data vocabulary options for libraries and, by implication, their system suppliers. The conclusion being that the two key best options were Bibframe 2.0 and Schema.org — the former for cataloguing support, the latter for providing data on the web (for search engines to consume) to aid discovery beyond library interfaces. The conclusion also being the need to adopt both vocabularies as the pros & cons of each cover the breadth of library linked data use cases, and the mutual limitations of each:
| Cataloguing Data Exchange |
Web Sharing Discovery |
|
|---|---|---|
| Bibframe | ✓ | ✗ |
| Schema.org | ✗ | ✓ |
As a fallback, for those currently without systems that can support linked data, there is another option I call Linky MARC. This an enhancement to MARC, recommended by the PCC Task Group on URIs in MARC, for a consistent approach for storing http URIs in MARC subfields $0 & $1. This is not Linked Data, but a standardised way of storing links, without corrupting them, for future use.
I have loaded the presentation on SlideShare for those of you that want explore further.
]]>
 Do you have a list of terms relevant to your data?
Do you have a list of terms relevant to your data?
Things such as subjects, topics, job titles, a glossary or dictionary of terms, blog post categories, ‘official names’ for things/people/organisations, material types, forms of technology, etc., etc.
Until now these have been difficult to describe in Schema.org. You either had to mark them up as a Thing with a name property, or as a well known Text value.
The latest release of Schema.org (3.4) includes two new Types – DefinedTerm and DefinedTermSet – to make life easier in this area.
The best way to describe potential applications of these very useful types is with an example:
Imagine you are an organisation that promotes and provides solid fuel technology….
In product descriptions and articles you endlessly reference solid fuel types such as “Coal”, “Biomass”, “Peat”, “Coke”, etc. For the structured of your data, in product descriptions or article subjects, these terms have important semantic value, so you want to pick them out in your structured data descriptions that you give the search engines.
Using the new Schema.org types, it could look something like this:
"@context": "carview.php?tsp=https://schema.org",
"@graph": [
{
"@type": "DefinedTerm",
"@id": "https://hotexample.com/terms/sf1",
"name": "Coal",
"inDefinedTermSet": "https://hotexample.com/terms"
},
{
"@type": "DefinedTerm",
"@id": "https://hotexample.com/terms/sf2",
"name": "Coke",
"inDefinedTermSet": "https://hotexample.com/terms"
},
{
"@type": "DefinedTerm",
"@id": "https://hotexample.com/terms/sf3",
"name": "Biomass",
"inDefinedTermSet": "https://hotexample.com/terms"
},
{
"@type": "DefinedTerm",
"@id": "https://hotexample.com/terms/sf4",
"name": "Peat",
"inDefinedTermSet": "https://hotexample.com/terms"
},
{
"@type": "DefinedTermSet",
"@id": "https://hotexample.com/terms",
"name": "Solid Fuel Terms"
}
]
}
As DefinedTermSet is a subtype of CreativeWork, it therefore provides many properties to describe the creator, datePublished, license, etc. of the set of terms.
Adding other standard properties could enhance individual term definitions with fuller descriptions, links to other representations of the same thing, and short codes.
For example:
{
"@type": "DefinedTerm",
"@id": "https://hotexample.com/terms/sf1",
"name": "Coal",
"description": "A combustible black or brownish-black sedimentary rock",
"termCode": "SFT1",
"sameAs": "https://en.wikipedia.org/wiki/Coal",
"inDefinedTermSet": "https://hotexample.com/terms"
}
There are several other examples to be found on the type definition pages in Schema.org.
For those looking for ways to categorise things, with category codes and the like, take a look at the subtypes of these new Types – CategoryCode and CategoryCodeSet.
The potential uses of this are endless, it will be great to see how it gets adopted.
]]> The latest release of Schema.org (3.4) includes some significant enhancements for those interested in marking up tourism, and trips in general.
The latest release of Schema.org (3.4) includes some significant enhancements for those interested in marking up tourism, and trips in general.
Tourism
For tourism markup two new types TouristDestination and TouristTrip have joined the already useful TouristAttraction:
- TouristDestination – Defined as a Place that contains, or is colocated with, one or more TourstAttractions, often linked by a similar theme or interest to a particular touristType.
- TouristTrip – A created itinerary of visits to one or more places of interest (TouristAttraction/TouristDestination) often linked by a similar theme, geographic area, or interest to a particular touristType.
These new types, introduced from proposals by The Tourism Structured Web Data Community Group, help complete the structured data mark up picture for tourism.
Any thing, place, cemetery, museum, mountain, amusement park, etc., can be marked up as a tourist attraction. A city, tourist board area, country, etc., can now be marked up as a tourist destination that contains one or more individual attractions. (See example)
In addition, a trip around and between tourist attractions, destinations, and other places, can be marked up including optional provider and offer information. (See examples)
I believe that these additions will cover a large proportion of structured data needs of tourism enthusiasts and the industry that serves them.
Trips
Whilst working on the new TouristTrip type, it became clear that there was a need for a more generic Trip type, which has also been introduced in this release. Trip is now the super-type for BusTrip, Flight, TrainTrip, and TouristTrip. It provides common properties for arrivalTime, departureTime, offers, and provider. In addition, from the tourism work, it introduces properties hasPart, isPartOf, and itinerary, enabling the marking up of a trip with several destinations and possibly sub-trips — for example “A weekend in London” – “A weekend in London: Day 1” – “A weekend in London: Day 2”.
Together these enhancements to Schema.org are not massive, but potentially they can greatly improve capabilities around travel and tourism.
(Tourist map image from mappery.com)
]]>So where are we now?
I believe we are [finally] on the cusp of establishing a de facto approach for libraries and their system suppliers – not there yet but getting there. Out of the mists of experimentation, funded cooperative projects, [mostly National Library] examples, and much discussion, is emerging a couple or three simple choices.
The proverbial $64,000 question being – what are those choices?

- BIBFRAME 2.0 – the currently promoted on the Library of Congress site BIBFRAME version, building on the previous disparate versions of BIBFRAME.
- Schema.org – the structured web data vocabulary, supported by all the major search engines, actively promoted by Google, Bing, Yahoo!, Yandex, and many others to aid indexing of resources, and implemented on millions of web sites in all sectors.
- Linky MARC – the ability/recommendations by the PCC Task Group on URIs in MARC to include entity URIs for people, organisations, etc. in MARC records.
Note: the name Linky MARC is of my own construction to differentiate from previous examples of MARC syntax for URLs etc. - Do nothing – kind of obvious!
So what is the correct answer? — Like most things in life, it depends on the answers to further questions:
- Do you, or your customers, want to take advantage of the benefits of Linked Data to:
- Share Linked Data with other libraries?
- Take advantage of entity based cataloguing, work based searching, etc.
- Do you, or your customers, want their resources to be more visible and discoverable on the web; being more likely to be an answer to a search/question asked of a search provider such as Google?
- Do you want to capture web links and URIs in cataloguing, but your system does not support Linked Data?
The simple message of this post is, if you answered yes to any of these questions is:
- BIBFRAME 2.0 needs to be in your plans for implementation.
- Schema.org needs to be in your plans for implementation.
- Linky MARC is a good interim solution until you can answer yes to 1. & 2.
As referenced above, these choices are as relevant to the suppliers and developers of library systems, as much as it is to individual libraries, who are often only able to able gain advantage from features developed on their behalf.
For those interested in the thought processes and experience that lead me to my statements here: I invite you to attend, and/or watch out for my slides from, my presentation at the 84th IFLA General Conference and Assembly in Kuala Lumpur, 24-30 August 2018. I am speaking in the Celebrating IT Innovations in Libraries session (13:45 Sunday 26th August), and will be around for chats & meetings for most of the conference (contact me if you would like to meet up).
For those who will not get the pleasure of travelling to Malaysia in August, here briefly are some of those thoughts and observations:
BIBFRAME 2.0, launched a few years after the first release of BIBFRAME by the Library of Congress. That first version, was a major step forward towards a Linked Data standard for libraries, but it was viewed by many as unsatisfactory for being not a good enough Linked Data representation and yet not reflecting traditional cataloging practices sufficiently. Several differing versions of BIBFRAME then emerged, pushing things forward whilst causing confusion for those wondering what to do about potentially using it.
This second, published by the Library of Congress, version took on board some of those these criticisms and as a result has become a version that is probably good enough to implement. Perfect? No. Complete and finished? No, But good enough.
With the weight and momentum, provided by the Library of Congress, behind it it is looking like being the one standard that all system suppliers and developers will eventually support in some form. There are many potential benefits that could flow from implementing BIBFRAME (Work-based discovery, entity-based cataloging, interlinking with and enrichment by external resources, etc). However benefits that will not flow directly from adopting BIBFRAME are improvements to the visibility and discoverability of resources on the web by library users — search engines showing no interest in harvesting BIBFRAME.
Schema.org, launched at a similar time to BIBFRAME, is a general purpose vocabulary designed to be embedded in web pages (for crawling by search engines) from all sectors.
In the early days, it was a bit limited in its capability for describing bibliographic resources, but that was addressed by the W3C Schema Bib Extend Community Group. Also, until recently, there was some scepticism as to if the search engines were utilising Schema.org data to aid discovery. Something they have now acknowledged it does.
With the introduction of AI techniques at the search engines, and voice search making discoverability even more important, Schema.org has become a significant factor for all those wanting to be visible on the web. Schema.org therefore has become the de facto choice of vocabulary for publishing structured data on the web.
Linky MARC is a significant step forward in the world of MARC cataloging, enabling the capture and use of web URIs in a consistent way in MARC records. Unlike implementing Linked Data, enhancing a library system to be compatible with these features should not be a major reengineering process. The move to a full Linked Data based system at a later date, could then fully capitalise on these previously captured URIs and links.
To summarise the choice isn’t really which vocabulary to adopt, but when to implement BIBFRAME 2.0 and when to implement Schema.org, and do I need to adopt Linky Marc in the interim?
]]>

Firstly let me credit the source that alerted me to the subject of this post.
Jennifer Slegg of TheSEMPost wrote an article last week entitled Adding Structured Data Helps Google Understand & Rank Webpages Better. It was her report of a conversation with Google’s Webmaster Trends Analyst Gary Illyes at PUBCON Las Vegas 2017.
 Jennifer’s report included some quotes from Gary which go a long way towards clarifying the power, relevance, and importance for Google for embedding Schema.org Structured Data in web pages.
Jennifer’s report included some quotes from Gary which go a long way towards clarifying the power, relevance, and importance for Google for embedding Schema.org Structured Data in web pages.
Those that have encountered my evangelism for doing just that, will know that there have been many assumptions about the potential effects of adding Schema.org Structured Data to your HTML, but this is the first confirmation of those assumptions by Google folks that I am aware of.
To my mind there are two key quotes from Garry, firstly:
But more importantly, add structure data to your pages because during indexing, we will be able to better understand what your site is about.
In the early [only useful for Rich Snippets] days of Schema.org, Google representatives went out of their way to assert that adding Schema.org to a page would NOT influence its position in search results. More recently, ‘non-commital’ could be described as the answer to questions about Schema.org and indexing. Gary’s phrasing is a little interesting “during indexing, we will be able to better understand“, but you can really only drawn certain conclusions from them.
So, this answers one of the main questions I am asked by those looking to me for help in understanding and applying Schema.org.
If I go to the trouble of adding Schema.org to my pages, will Google [and others] take any notice?”
To paraphrase Mr Illyes — Yes.
The second key quote:
And don’t just think about the structured data that we documented on developers.google.com. Think about any schema.org schema that you could use on your pages. It will help us understand your pages better, and indirectly, it leads to better ranks in some sense, because we can rank easier.
So structured data is important, take any schema from schema.org and implement it, as it will help.
This answers directly another common challenge I get when recommending the use of the whole Schema.org vocabulary, and its extensions, as a source of potential Structured Data types for marking up your pages.
The challenge being “where is the evidence that any schema, not documented in the Google Structured Data Pages, will be taken notice of?
So thanks Gary, you have just made my job, and the understanding of those that I help, a heck of a lot easier.
Apart from those two key points there are some other interesting takeaways from his session as reported by Jennifer.
Their recent increased emphasis on things Structured Data:
We launched a bunch of search features that are based on structured data. It was badges on image search, jobs was another thing, job search, recipes, movies, local restaurants, courses and a bunch of other things that rely solely on structure data, schema.org annotations.
It is almost like we started building lots of new features that rely on structured data, kind of like we started caring more and more and more about structured data. That is an important hint for you if you want your sites to appear in search features, implement structured data.
Google’s further increased Structured Data emphasis in the near future:
Next year, there will be two things we want to focus on. The first is structured data. You can expect more applications for structured data, more stuff like jobs, like recipes, like products, etc.
For those who have been sceptical as to the current commitment of Google and others to Schema.org and Structured Data, this should go some way towards settling your concerns.
It is at his point I add in my usual warning against rushing off and liberally sprinkling Schema.org terms across your web pages. It is not like keywords.
The search engines are looking for structured descriptions (the clue is in the name) of the Things (entities) that your pages are describing; the properties of those things; and the relationships between those things and other entities.
Behind Schema.org and Structured Data are some well established Linked Data principles, and to get the most effect from your efforts, it is worth recognising them.
Applying Structured Data to your site is not rocket science, but it does need a little thought and planning to get it right. With organisatons such as Google taking notice, like most things in life, it is worth doing right if you are going to do it at all.
]]>