| CARVIEW |
CTRL-O: Language-Controllable Object-Centric Visual Representation Learning

Overview CTRL-O at a Glance
Language Control
Control which objects are represented using natural language queries and referring expressions
Weak Supervision
Works without requiring mask supervision, applicable to a wide range of real-world scenarios
Multimodal Applications
Enables both instance-specific text-to-image generation and visual question answering capabilities

Left: Standard object-centric learning assigns arbitrary slots with no semantic labels. Right: CTRL-O introduces language-based control, enabling specific object targeting and multimodal applications.
Object-centric representation learning aims to decompose visual scenes into fixed-size vectors called "slots" or "object files", where each slot captures a distinct object. Current state-of-the-art object-centric models have shown remarkable success in object discovery in diverse domains, including complex real-world scenes. However, these models suffer from a key limitation: they lack controllability. Specifically, current object-centric models learn representations based on their preconceived understanding of objects and parts, without allowing user input to guide which objects are represented.
Introducing controllability into object-centric models could unlock a range of useful capabilities, such as the ability to extract instance-specific representations from a scene. In this work, we propose a novel approach for user-directed control over slot representations by conditioning slots on language descriptions. The proposed ConTRoLlable Object-centric representation learning approach, which we term CTRL-O, achieves targeted object-language binding in complex real-world scenes without requiring mask supervision. Next, we apply these controllable slot representations on two downstream vision language tasks: text-to-image generation and visual question answering. We find that the proposed approach enables instance-specific text-to-image generation and also achieves strong performance on visual question answering.
Architecture CTRL-O

CTRL-O builds upon DINOSAUR's object discovery framework, which uses Slot Attention to decompose images into object-centric representations. Our key innovation is introducing language-based control through three main components: (1) Query-based Slot Initialization, where we condition slots on language queries to target specific objects; (2) Decoder Conditioning, where we enhance language grounding by conditioning the decoder on control queries; and (3) Control Contrastive Loss, which enforces proper grounding by ensuring that slots bind to their corresponding language queries through a contrastive learning objective. This approach enables precise object-language binding without requiring mask supervision, making it applicable to real-world scenarios.
Evaluation Object Discovery Results
Our evaluation shows that CTRL-O significantly outperforms existing approaches and benefits from key architectural components.
Component Ablation Analysis
| Slot Init. | GT Masks | CL | DC | Binding Hits | FG-ARI | mBO |
|---|---|---|---|---|---|---|
| 71.2 | 69.8 | 35.4 | ||||
| 8.1 | 34.52 | 22.42 | ||||
| 10.11 | 43.83 | 25.76 | ||||
| 56.3 | 44.8 | 27.3 | ||||
| 61.3 | 47.5 | 27.2 |
CTRL-O Model Component Ablation for Grounding. CL = Contrastive Loss, DC = Decoder Conditioning.
Object Discovery Performance
| Approach | Model | FG-ARI | mBO |
|---|---|---|---|
| Unsupervised | DINOSAUR (MLP Dec.) | 40.5 | 27.7 |
| DINOSAUR (TF. Dec.) | 34.1 | 31.6 | |
| Stable-LSD | 35.0 | 30.4 | |
| SlotDiffusion | 37.3 | 31.4 | |
| Weak Supervision | Stable-LSD (Bbox Supervision) | - | 30.3 |
| CTRL-O (Trained on COCO) | 47.5 | 27.2 |
Comparison of CTRL-O with unsupervised and weakly-supervised object-centric approaches on the COCO dataset.
Results Visual Grounding with Language Queries
Our approach enables precise binding between language descriptions and visual objects in complex scenes without requiring mask supervision.
Visual Grounding Examples

Referring Expression Comprehension Performance
| Methods | Sup. | Pretraining dataset | Fine tuning | RefCOCO | RefCOCO+ | Gref | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| val | testA | testB | val | testA | testB | val | ||||
| GroupViT | T | CC12M+YFCC | 7.99 | 6.16 | 10.51 | 8.49 | 6.79 | 10.59 | 10.68 | |
| GroupViT | T | CC12M+YFCC | 10.82 | 11.11 | 11.29 | 11.14 | 10.78 | 11.84 | 12.77 | |
| MaskCLIP | T | WIT | 11.52 | 11.85 | 12.06 | 11.87 | 12.01 | 12.57 | 12.74 | |
| MaskCLIP | T | WIT | 19.45 | 18.69 | 21.37 | 19.97 | 18.93 | 21.48 | 21.11 | |
| Shatter & Gather | T | VG | 21.80 | 19.00 | 24.96 | 22.20 | 19.86 | 24.85 | 25.89 | |
| CTRL-O | T | VG | 21.80 | 20.10 | 21.57 | 21.90 | 21.54 | 21.36 | 25.32 | |
| CTRL-O | T+P | VG | 28.2 | 33.13 | 27.05 | 25.87 | 30.58 | 22.58 | 30.50 | |
Performance comparison on referring expression comprehension. Sup: T = Text supervision, T+P = Text + Phrase supervision.
CTRL-O with combined text and phrase supervision significantly outperforms existing approaches, achieving the best results on most benchmarks.
Overview of CTRL-O Downstream Tasks

Instance Controllable Image Generation: CTRL-O enables precise control over specific instances in generated images by leveraging its language-guided object representations. Given a query image, we extract slot representations of target objects using language queries (e.g., "bus" or "laptop"). These slots are then projected into CLIP embeddings and appended to the text prompt (e.g., "A photo of a bus. S_bus"), allowing the diffusion model to generate images that preserve the visual identity of specific instances. Unlike previous approaches that require manual mask reconstruction or fixed slot numbers, CTRL-O provides inherent language-based control and flexible instance conditioning.
Visual Question Answering: CTRL-O's language-guided object representations enable stronger vision-language coupling in VQA through a novel slot insertion approach. Given a question, we first extract noun chunks (e.g., "cat", "couch") and use them to condition CTRL-O to obtain corresponding object slots. These slots are then inserted directly into the question at appropriate positions (e.g., "What is the color of the cat [slot] sitting on the couch [slot]?"). The slots are projected to match T5's embedding dimension and fed into the language model, creating a strong coupling between visual and language components from the input stage. This approach allows for more direct interaction between object representations and language understanding.
Instance-Controllable T2I
Instance-specific control over text-to-image generation while maintaining scene context. CTRL-O enables targeted modification of specific objects while preserving the surrounding scene details.

Visual Question Answering
CTRL-O achieves the highest accuracy on VQAv2 in both No-Coupling and Coupling settings, outperforming baseline models.
Related Work Previous Publications
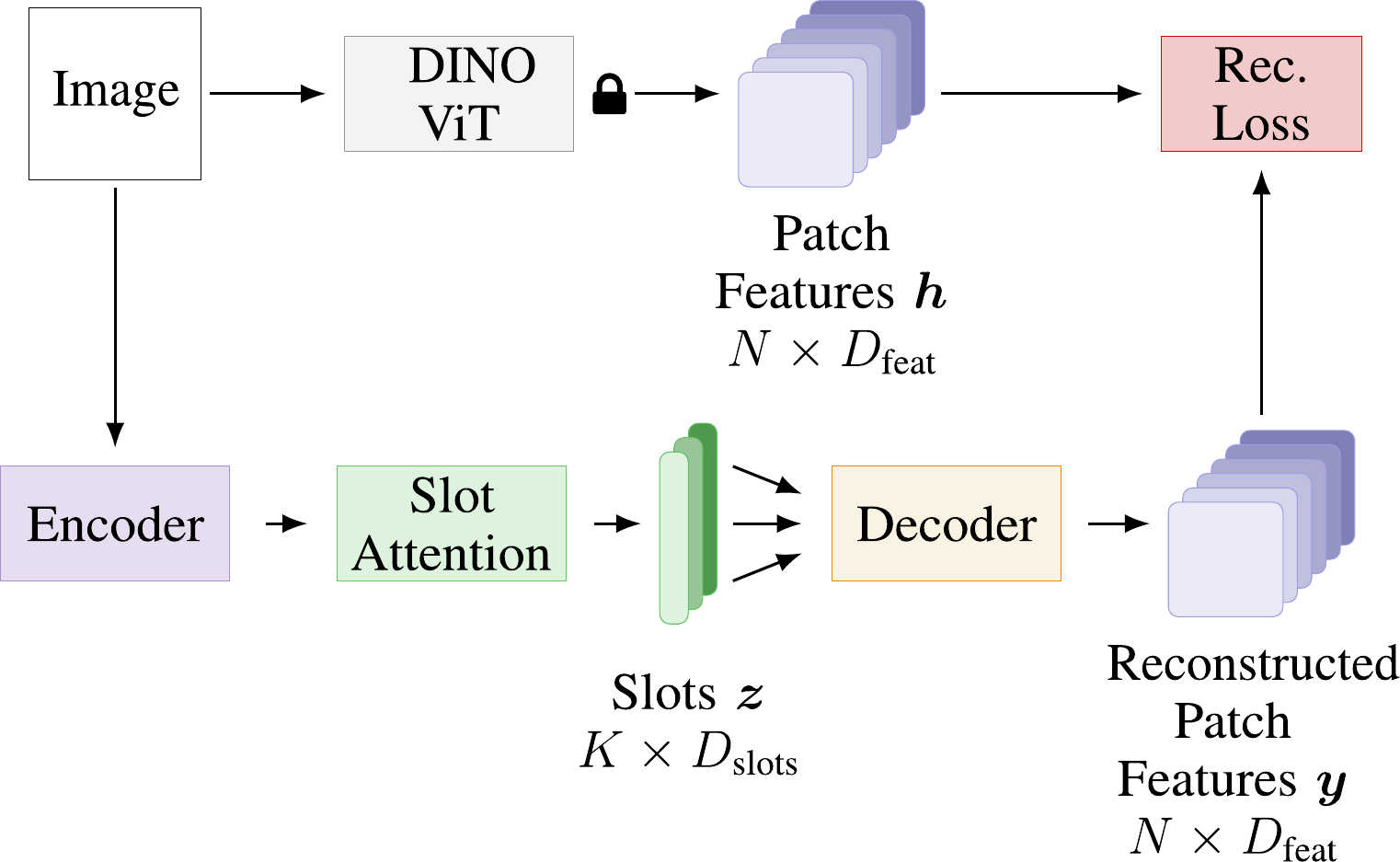
DINOSAUR: Bridging the Gap to Real-World Object-Centric Learning
DINOSAUR is a model for unsupervised object-centric representation learning.
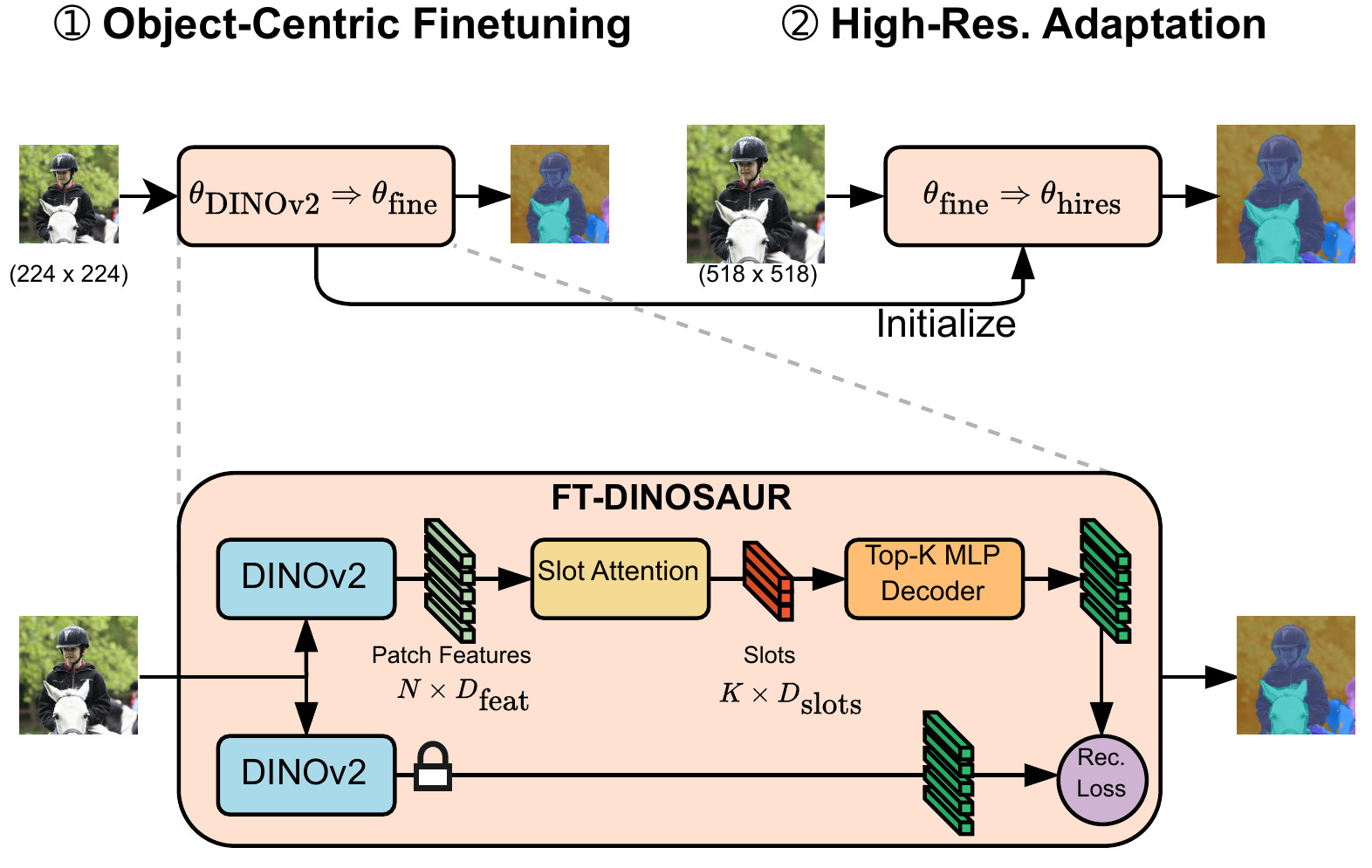
On the Transfer of Object-Centric Representation Learning
Exploring transferability of object-centric representations across domains with a novel fine-tuning strategy
Citation BibTeX
@inproceedings{didolkar2025ctrlo,
title={CTRL-O: Language-Controllable Object-Centric Visual Representation Learning},
author={Didolkar, Aniket Rajiv and Zadaianchuk, Andrii and Awal, Rabiul and Seitzer, Maximilian and Gavves, Efstratios and Agrawal, Aishwarya},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2025}
}