| CARVIEW |
CLIPort: What and Where Pathways for Robotic Manipulation
CoRL 2021
We learn one multi-task policy for 9 real-world tasks including folding cloths, sweeping beans etc. with just 179 image-action training pairs.
Abstract
How can we imbue robots with the ability to manipulate objects precisely but also to reason about them in terms of abstract concepts?
Recent works in manipulation have shown that end-to-end networks can learn dexterous skills that require precise spatial reasoning, but these methods often fail to generalize to new goals or quickly learn transferable concepts across tasks. In parallel, there has been great progress in learning generalizable semantic representations for vision and language by training on large-scale internet data, however these representations lack the spatial understanding necessary for fine-grained manipulation. To this end, we propose a framework that combines the best of both worlds: a two-stream architecture with semantic and spatial pathways for vision-based manipulation. Specifically, we present CLIPort, a language-conditioned imitation-learning agent that combines the broad semantic understanding (what) of CLIP with the spatial precision (where) of TransporterNets.
Our end-to-end framework is capable of solving a variety of language-specified tabletop tasks from packing unseen objects to folding cloths, all without any explicit representations of object poses, instance segmentations, memory, symbolic states, or syntactic structures. Experiments in simulation and hardware show that our approach is data-efficient and generalizes effectively to seen and unseen semantic concepts. We even train one multi-task policy for 10 simulated and 9 real-world tasks that shows better or comparable performance to single-task policies.
Video
CLIPort
Two-Stream Architecture
Broadly inspired by (or vaguely analogous to) the two-stream hypothesis in cognitive psychology, we present a two-stream architecture for vision-based manipulation with semantic and spatial pathways. The semantic stream uses a pre-trained CLIP model to encode RGB and language-goal input. Since CLIP is trained with large amounts of image-caption pairs from the internet, it acts as a powerful semantic prior for grounding visual concepts like colors, shapes, parts, texts, and object categories. The spatial stream is a tabula rasa fully-convolutional network that encodes RGB-D input.
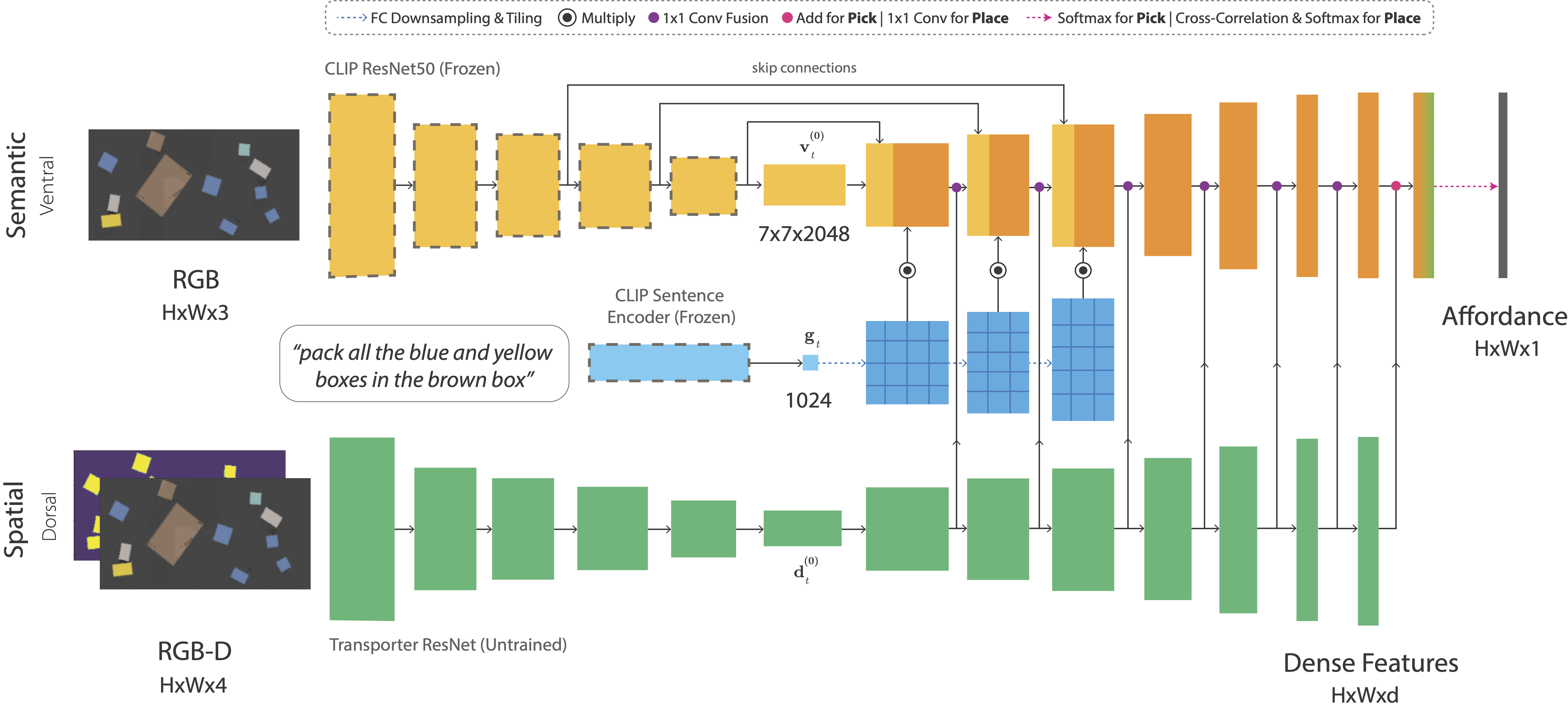
Paradigm 1: Unlike existing object detectors, CLIP is not limited to a predefined set of object classes. And unlike other vision-language models, it's not restricted by a top-down pipeline that detects objects with bounding boxes or instance segmentations. This allows us to forgo the traditional paradigm of training explicit detectors for cloths, pliers, chessboard squares, cherry stems, and other arbitrary things.
TransporterNets
We use this two-stream architecture in all three networks of TransporterNets to predict pick and place affordances at each timestep. TransporterNets first attends to a local region to decide where to pick, then computes a placement location by finding the best match for the picked region through cross-correlation of deep visual features. This structure serves as a powerful inductive bias for learning roto-translationally equivariant representations in tabletop environments.
Credit: Zeng et. al (Google)
Paradigm 2: TransporterNets takes an action-centric approach to perception where the objective is to detect actions rather than detect objects and then learn a policy. Keeping the action-space grounded in the perceptual input allows us to exploit geometric symmetries for efficient representation learning. When combined with CLIP's pre-trained representations, this enables the learning of reusable manipulation skills without any "objectness" assumptions.
Results
Single-Task Models
Trained withOne Multi-Task Model
Trained withAffordance Predictions
Examples of pick and place affordance predictions from multi-task CLIPort models:


BibTeX
@inproceedings{shridhar2021cliport,
title = {CLIPort: What and Where Pathways for Robotic Manipulation},
author = {Shridhar, Mohit and Manuelli, Lucas and Fox, Dieter},
booktitle = {Proceedings of the 5th Conference on Robot Learning (CoRL)},
year = {2021},
}