I am currently working at Tencent (2024.7-), where my focus is on human motion capture and generation under multimodal inputs. Prior to this, I was a Ph.D. student in Computer Science at Zhejiang University from 2019 to 2024, under the supervision of Xiaowei Zhou. My research interests lie at the intersection of computer vision and computer graphics, with a particular emphasis on 3D human pose estimation and generation, 3D reconstruction, and novel view synthesis.
During my past career, my main focus was on the EasyMoCap repository. The goal of this repository is to make human motion capture more accessible and straightforward. It encompasses a collection of code from my work over the past few years and includes essential tools for the field of human motion capture, such as camera calibration, interactive keypoint annotation, visualization, and more.
Demos
Professional Motion Capture with Multi-Camera Systems
Simple Motion Capture from Complex Internet Videos
Novel View Synthesis
4D Scene Reconstruction and Editing
Selected Publications
2024
2023
Reconstructing Close Human Interactions from Multiple Views
Qing Shuai, Zhiyuan Yu, Zhize Zhou, Lixin Fan, Haijun Yang, Can Yang, and Xiaowei Zhou
ACM Transactions on Graphics (TOG) 2023
2022
Novel View Synthesis of Human Interactions from Sparse Multi-view Videos
Shuai Qing, Geng Chen, Fang Qi, Peng Sida, Shen Wenhao, Zhou Xiaowei, and Bao Hujun
@inproceedings{shuai2022multinb,title={Novel View Synthesis of Human Interactions from Sparse
Multi-view Videos},author={Qing, Shuai and Chen, Geng and Qi, Fang and Sida, Peng and Wenhao, Shen and Xiaowei, Zhou and Hujun, Bao},booktitle={SIGGRAPH Conference Proceedings},year={2022},}
2021
Reconstructing 3D Human Pose by Watching Humans in the Mirror
Fang Qi, Shuai* Qing, Dong Junting, Bao Hujun, and Zhou Xiaowei
@inproceedings{fang2021mirrored,title={Reconstructing 3D Human Pose by Watching Humans in the Mirror},author={Qi, Fang and Qing, Shuai* and Junting, Dong and Hujun, Bao and Xiaowei, Zhou},booktitle={CVPR},year={2021},}
2020
Motion Capture from Internet Videos
Dong* Junting, Shuai* Qing, Zhang Yuanqing, Liu Xian, Zhou Xiaowei, and Bao Hujun
@article{peng2023implicit,title={Implicit Neural Representations with Structured Latent Codes for Human Body Modeling},journal={TPAMI},year={2023},publisher={IEEE},}
Representing Volumetric Videos As Dynamic MLP Maps
@inproceedings{Peng_2023_CVPR,author={Peng, Sida and Yan, Yunzhi and Shuai, Qing and Bao, Hujun and Zhou, Xiaowei},title={Representing Volumetric Videos As Dynamic MLP Maps},booktitle={CVPR},month=jun,year={2023},pages={4252-4262},}
Learning Analytical Posterior Probability for Human Mesh Recovery
Qi Fang, Kang Chen, Yinghui Fan, Qing Shuai, Jiefeng Li, and Weidong Zhang
@inproceedings{Fang_2023_CVPR,author={Fang, Qi and Chen, Kang and Fan, Yinghui and Shuai, Qing and Li, Jiefeng and Zhang, Weidong},title={Learning Analytical Posterior Probability for Human Mesh Recovery},booktitle={CVPR},month=jun,year={2023},pages={8781-8791},}
Reconstructing Close Human Interactions from Multiple Views
Qing Shuai, Zhiyuan Yu, Zhize Zhou, Lixin Fan, Haijun Yang, Can Yang, and Xiaowei Zhou
ACM Transactions on Graphics (TOG) Jun 2023
Motion capture method based on unsynchorized videos
Hujun Bao, Xiaowei Zhou, DONG Junting, and Qing Shuai
Aug 2023
iVS-Net: Learning Human View Synthesis from Internet Videos
@inproceedings{shuai2022multinb,title={Novel View Synthesis of Human Interactions from Sparse
Multi-view Videos},author={Qing, Shuai and Chen, Geng and Qi, Fang and Sida, Peng and Wenhao, Shen and Xiaowei, Zhou and Hujun, Bao},booktitle={SIGGRAPH Conference Proceedings},year={2022},}
QuickPose: Real-Time Multi-View Multi-Person Pose Estimation in Crowded Scenes
Zhou Zhize, Shuai Qing, Wang Yize, Fang Qi, Ji Xiaopeng, Li Fashuai, Bao Hujun, and Zhou Xiaowei
This work proposes a real-time algorithm for reconstructing 3D human poses in crowded scenes from multiple calibrated views. The key challenge of this problem is to efficiently match 2D observations across multiple views. Previous methods perform multi-view matching either at the full-body level, which is sensitive to 2D pose estimation error, or at the part level, which ignores 2D constraints between different types of body parts in the same view. Instead, our approach reasons about all plausible skeleton proposals during multi-view matching, where each skeleton may consist of an arbitrary number of parts instead of being a whole body or a single part. To this end, we formulate the multi-view matching problem as mode seeking in the space of skeleton proposals and develop an efficient algorithm named QuickPose to solve the problem, which enables real-time motion capture in crowded scenes. Experiments show that the proposed algorithm achieves the state-of-the-art performance in terms of both speed and accuracy on public datasets.
@inproceedings{quickpose,author={Zhize, Zhou and Qing, Shuai and Yize, Wang and Qi, Fang and Xiaopeng, Ji and Fashuai, Li and Hujun, Bao and Xiaowei, Zhou},title={QuickPose: Real-Time Multi-View Multi-Person Pose Estimation in Crowded Scenes},year={2022},isbn={9781450393379},publisher={Association for Computing Machinery},address={New York, NY, USA},url={https://doi.org/10.1145/3528233.3530746},doi={10.1145/3528233.3530746},booktitle={SIGGRAPH Conference Proceedings},articleno={45},numpages={9},keywords={human pose estimation, quickshift, multi-person, multi-view},location={Vancouver, BC, Canada},series={SIGGRAPH '22}}
Efficient Neural Radiance Fields for Interactive Free-viewpoint Video
Lin Haotong, Peng Sida, Xu Zhen, Yan Yunzhi, Shuai Qing, Bao Hujun, and Zhou Xiaowei
@inproceedings{lin2022efficient,title={Efficient Neural Radiance Fields for Interactive Free-viewpoint Video},author={Haotong, Lin and Sida, Peng and Zhen, Xu and Yunzhi, Yan and Qing, Shuai and Hujun, Bao and Xiaowei, Zhou},booktitle={SIGGRAPH Asia Conference Proceedings},year={2022},}
Reconstructing Hand-Held Objects from Monocular Video
Di Huang, Xiaopeng Ji, Xingyi He, Jiaming Sun, Tong He, Shuai Qing, Wanli Ouyang, and Xiaowei Zhou
@inproceedings{huang2022hhor,title={Reconstructing Hand-Held Objects from Monocular Video},author={Huang, Di and Ji, Xiaopeng and He, Xingyi and Sun, Jiaming and He, Tong and Qing, Shuai and Ouyang, Wanli and Zhou, Xiaowei},booktitle={SIGGRAPH Asia Conference Proceedings},year={2022},}
Shape Prior Guided Instance Disparity Estimation for 3D Object Detection
Chen Linghao, Sun Jiaming, Xie Yiming, Zhang Siyu, Shuai Qing, Jiang Qinhong, Zhang Guofeng, Bao Hujun, and Zhou Xiaowei
@article{9419782,author={Linghao, Chen and Jiaming, Sun and Yiming, Xie and Siyu, Zhang and Qing, Shuai and Qinhong, Jiang and Guofeng, Zhang and Hujun, Bao and Xiaowei, Zhou},journal={TPAMI},title={Shape Prior Guided Instance Disparity Estimation for 3D Object Detection},year={2022},volume={44},number={9},pages={5529-5540},doi={10.1109/TPAMI.2021.3076678}}
TotalSelfScan: Learning Full-body Avatars from Self-Portrait Videos of Faces, Hands, and Bodies
Junting Dong, Qi Fang, Yudong Guo, Sida Peng, Qing Shuai, Xiaowei Zhou, and Hujun Bao
@inproceedings{NEURIPS2022_589c5bd0,author={Dong, Junting and Fang, Qi and Guo, Yudong and Peng, Sida and Shuai, Qing and Zhou, Xiaowei and Bao, Hujun},booktitle={NeurIPS},editor={Koyejo, S. and Mohamed, S. and Agarwal, A. and Belgrave, D. and Cho, K. and Oh, A.},pages={13654--13667},publisher={Curran Associates, Inc.},title={TotalSelfScan: Learning Full-body Avatars from Self-Portrait Videos of Faces, Hands, and Bodies},volume={35},year={2022}}
2021
Neural Body: Implicit Neural Representations with Structured Latent Codes for Novel View Synthesis of Dynamic Humans
Peng Sida, Zhang Yuanqing, Xu Yinghao, Wang Qianqian, Shuai Qing, Bao Hujun, and Zhou Xiaowei
@inproceedings{fang2021mirrored,title={Reconstructing 3D Human Pose by Watching Humans in the Mirror},author={Qi, Fang and Qing, Shuai* and Junting, Dong and Hujun, Bao and Xiaowei, Zhou},booktitle={CVPR},year={2021},}
Animatable neural radiance fields for modeling dynamic human bodies
Peng Sida, Dong Junting, Wang Qianqian, Zhang Shangzhan, Shuai Qing, Zhou Xiaowei, and Bao Hujun
@inproceedings{peng2021animatable,title={Animatable neural radiance fields for modeling dynamic human bodies},author={Sida, Peng and Junting, Dong and Qianqian, Wang and Shangzhan, Zhang and Qing, Shuai and Xiaowei, Zhou and Hujun, Bao},booktitle={ICCV},pages={14314--14323},year={2021},}
2020
Motion Capture from Internet Videos
Dong* Junting, Shuai* Qing, Zhang Yuanqing, Liu Xian, Zhou Xiaowei, and Bao Hujun

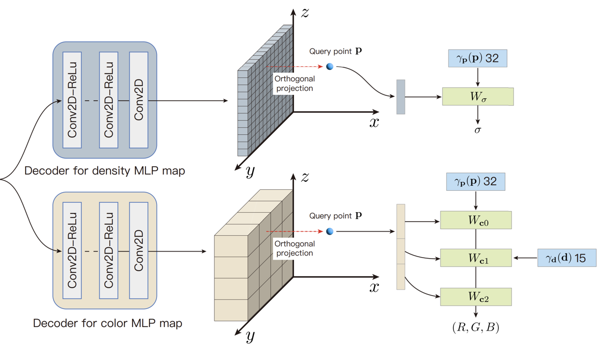
 Efficient Neural Radiance Fields for Interactive Free-viewpoint VideoIn SIGGRAPH Asia Conference Proceedings Aug 2022
Efficient Neural Radiance Fields for Interactive Free-viewpoint VideoIn SIGGRAPH Asia Conference Proceedings Aug 2022