| CARVIEW |
Specifically, the theory used is Tarski’s theory of concatenation (TC), with the following axioms:
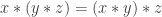





Concatenation is associative, there are at least two different atomic symbols, and two different ways of dividing a text in two have a common beginning, a common ending and differ only in whether the middle part is the end of first half or the beginning the second half. That’s it. This seemingly meager theory, however, turns out to be undecidable, and indeed essentially so.
Before defining what we mean by undecidable, some preliminaries first. The intended model of TC (playing the role of 












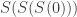
Now we can define the notions corresponding to primitive and general recursivity. The class 



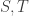











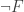

We also need to code the formulas and other syntactic objects of TC within TC (in other words, as sequences of a’s and b’s). Since our theory is a theory of texts, we don’t have to rely on any specifically arithmetical tricks like the Chinese remainder theorem here, we simply enumerate the symbols used in TC and assign the codes 








The last step is the self-referential one. Assume that the consistent theory T containing TC is GD, i.e. the set of the codes of the formulas of T is GD (hence so is its complement). Substitution and coding are GD operations, therefore the operation that assigns the code of the formula 




![t \in X \equiv G[Code(t)] \in T](https://s0.wp.com/latex.php?latex=t+%5Cin+X+%5Cequiv+G%5BCode%28t%29%5D+%5Cin+T&bg=ffffff&fg=333333&s=0&c=20201002)
![Code(G) \in X \equiv G[Code(G)] \in T](https://s0.wp.com/latex.php?latex=Code%28G%29+%5Cin+X+%5Cequiv+G%5BCode%28G%29%5D+%5Cin+T&bg=ffffff&fg=333333&s=0&c=20201002)
![Code(G) \in X \equiv G[Code(G)] \notin T](https://s0.wp.com/latex.php?latex=Code%28G%29+%5Cin+X+%5Cequiv+G%5BCode%28G%29%5D+%5Cnotin+T&bg=ffffff&fg=333333&s=0&c=20201002)



More explicitly: we again have a set of voters 


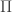
- every candidate can win, given a suitable set of voter preferences (non-imposition)
- knowing the votes of other voters does not give anyone an incentive to change their own vote (stability / non-manipulability)
That is, given the preferences of all voters except for 
First, a quick ultrafilter lemma:
Lemma (a characterization of ultrafilters):
Every family 



Proof: if 







Now, back to social choice theory. Let’s say that for a profile 



Lemma (about stable collective choice):
For any stable collective choice procedure 

Proof: first, we will define a function 
- if voter
- if voter
- every other ranking in the profile remains the same
In other words, 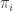

It is not difficult use the stability of ![c[\varphi_i^{xy}(\pi)]=\{x\}](https://s0.wp.com/latex.php?latex=c%5B%5Cvarphi_i%5E%7Bxy%7D%28%5Cpi%29%5D%3D%5C%7Bx%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002)
Now, by the hypothesis of this theorem, 

![c[\varphi^{xy}(\pi^\prime)]=\{x\}](https://s0.wp.com/latex.php?latex=c%5B%5Cvarphi%5E%7Bxy%7D%28%5Cpi%5E%5Cprime%29%5D%3D%5C%7Bx%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002)

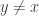
![c[\varphi^{yx}(\pi^\prime)]=\{y\}](https://s0.wp.com/latex.php?latex=c%5B%5Cvarphi%5E%7Byx%7D%28%5Cpi%5E%5Cprime%29%5D%3D%5C%7By%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002)


Combining this lemma with the assumption of non-imposition yields the weak Pareto property: if everyone prefers
Armed with these results, we can now explore the structure of “preventing families”. A set of voters 

Lemma (about preventing families):
: follows easily from the weak Pareto property
: by the previous property and the theorem about collective choice
: easy application of the weak Pareto property
It would seem reasonable to demand that 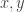
Lemma (neutrality of stable collective choice procedures):


Proof: let us first show that 

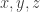


for
for
for
for




Then by the weak Pareto property,
, but
and
. Thus,
.
The same reasoning applied to
and the profile:
for
for
for
for
shows that
.
Applying this result to properties (3) and (4) of preventing families, we see that the unique preventing family
Lemma:
The preventing family
Proof: the first two conditions of the ultrafilter lemma are satisfied. As for the last one, let us assume that 

for
for
for
otherwise
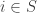


By the weak Pareto property, 
In view of the fact that every ultrafilter on a finite set is principal (consists precisely of its subsets containing a given element), this concludes the proof of the Gibbard-Satterthwaite theorem: every stable, non-imposed collective choice procedure for at least three alternatives is dictatorial. Conversely, a free ultrafilter on an infinite set corresponds to a stable non-dictatorial collective choice procedure (or, more accurately, a collective choice function).
]]>Let us first define a more general notion. A filter
(non-triviality)
(superset property)
(finite intersection property)
An ultrafilter 
(maximality)
By non-triviality and the finite intersection property, only one of these options can hold, hence every ultrafilter on 
The intuitive interpretation of an (ultra)filter is that it specifies which subsets are to be considered “large”. A property holds for “almost all” elements of a set if the set of elements for which it holds is contained in the relevant (ultra)filter – for example, if its complement is finite. (This is a generalization of the measure-theoretic notion of “almost everywhere”, i.e. on a set of full measure. Indeed, an ultrafilter can be thought of as a finitely additive zero-one measure.) This interpretation suggests a natural connection to social choice theory – if “almost all” voters prefer A to B, we would ideally like to rank A higher than B.
And indeed, this is what Arrow’s conditions imply (the following proof is based on these notes by A. McLennan [pdf]). Arrow considers a situation in which we have a set of voters 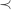
- If every voters prefers x to y, the society prefers x to y. (unanimity)
- The social preference between x and y depends only on the voters’ preferences between x and y, i.e. not on their ranking of other alternatives. (independence of irrelevant alternatives)
We will say that a set of voters 



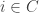
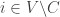


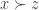
We now wish to prove that the family of decisive sets does in fact form an ultrafilter. First, non-triviality immediately follows from unanimity. Second, the intersection property. Let us assume that 
for


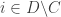
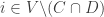
Then 

Third, maximality. Consider the set of preferences 
And finally, the superset property follows from the fact that if 

If 
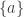
For an infinite number of voters, the existence of such a function cannot be disproven and in fact follows from the Axiom of Choice or the weaker Boolean Prime Ideal Theorem (although calling it a “procedure” is somewhat hyperbolic due to the non-constructive nature of free ultrafilters). If there are only two alternatives to choose from, Arrow’s result is complemented by May’s theorem, which states that simple majority voting is the canonical choice.
And an interesting, if only tangentially related factoid to end with: for exactly three choices and a large number of voters, the relative prevalence of the Condorcet effect (cycles in social preference which prevent us from applying a simple majority rule) tends to 
roughly corresponds to our pre-theoretical notion of temperature)? If it is, one would (or at least I would) expect the alternative interpretation to deal with phenomena which are still statistical in nature (we assume that the fluctuations in different parts of the system are averaged out, spatiotemporally in thermodynamics), unidirectional and governed by a general class of quantitative relationships rather than one specific equation.
Well, I don’t know the first thing about economics, but it was the first thing to come to my mind. And it turns out my hunch was correct, there is indeed a portion of economics which can be axiomatized in essentially the same way as thermodynamics, as shown by E. Smith and D.K. Foley in their paper Classical thermodynamics and economic general equilibrium theory. (It may be worthwhile to think about how you would draw an analogy between the two before continuing.)
The role of thermodynamic systems in the formalism is taken over by the so-called quasi-linear neoclassical economies, which means we assume that each agent 



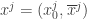
In fact, in a quasi-linear economy, we can aggregate the agents’ individual endowments and postulate that the equilibrium state maximizes their total utility from the non-linear goods, and the price 

1 The authors draw an analogy between 
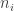
(The native Evenki are a Tungusic people related to the Manchu.)
]]>I mentioned all of those mostly so that you can, if you wish, think them through and come up with examples / counter-examples. The only ordering principles relevant here are those pertaining to any.
Let’s look at some examples from [1] (the asterisk marks ungrammaticality):
If any members contributes, I’ll be happy.
If every member contributes, I’ll be happy.
* If Jane wins, anybody is happy.
If Jane wins, everybody is happy.
Jane can win any match.
Jane can win every match.
* Jane has won any match.
Jane has won every match.
Jane hasn’t won any match.
Jane hasn’t won every match.
* Mary believes that Jane will win any match.
John has not dated any girl.
John has not dated every girl.
* Any girl has not been dated by John.
Every girl has not been dated by John.
I included a plenty of examples for a reason – try analyzing some of them for yourself to see how (G.any/every) along with the rules for preference determine the meaning of these sentences. Some of them are straightforward, some of them probably need some commentary. The difference in meaning between sentences like “Jane can win any/every match” is seen as a matter of talking about all possible matches vs. talking about actual matches only. Perhaps a clearer example is seen in [3]:
Any candidate will be considered on his merits.
Every candidate will be considered on his merits.
There is clearly a difference in meaning between, again involving a difference in the range of quantification. Either we first choose a particular future (the actual one) and quantify over individuals in it, or we first quantify over individuals in various possible futures and claim that all of them will be considered on their own merits (or would be if such a future were to occur). We can say that every candidate happens to be left-handed, but we can’t really say that any candidate happens to be left-handed. On the other hand, “any” is not assumed to have any special precedence over “intensional operators” like “hope”, hence in sentences like “Mary hopes that Jane will win any/every match” Hintikka claims that “the choice of the ‘world’ is absorbed to the intensional operator and hence precedes the choice of an individual involved either in (G.every) or (G.any)”.
You may have noticed a regularity in the un/grammaticality of these any constructions. In fact, studying such constructions led Hintikka to formulate the following principle, which he calls the any-thesis:
The word ‘any’ is acceptable (grammatical) in a given context X – and Y – Z if and only if an exchange of ‘any’ for ‘every’ results in a grammatical expression which is not identical in meaning with X – any Y – Z.
This is a well-formed condition, as the rules of game semantics for English unambiguously determine whether the sentences are equivalent or not (even when one of them is ungrammatical according to this rule). I’ll give you some time to ponder on the linguistic implications of this thesis. Meanwhile, a technical note: in [3], Hintikka relaxes the condition that the resulting expression be grammatical, as it can fail to be for completely unrelated reasons (for example not being a suitable antecedent for a pronoun, as in “if Bill has every donkey, he beats it”).
The obvious thing to notice is that in defining grammaticality in terms of meaning, it goes against the classical generativist idea of syntax (grammar) being independent of semantics. But even if semantics is taken into account, it is usually in the form of some simple, algorithmic rules. That is, we still have an algorithm which can tell us whether any given sentence belongs to the set of grammatical English sentences or not (such a set is then called “recursive”). In contrast, the any-thesis would imply that the set of grammatical English sentences is not recursive. Indeed, it is not even recursively enumerable! (That would mean having an algorithm which is guaranteed to confirm that a grammatical sentence indeed is grammatical but which is not guaranteed to terminate if it is not.)
Why? Well, the set of theorems of first-order predicate logic is not recursive (assuming we have at least one two-place predicate), and having a procedure to determine the logical equivalence of sentence of the form “if any X, then Y” and “if every X, then Y” would enable us to create a decision procedure for first-order predicate logic (details in [1]). So the set of grammatical sentences of the fragment of English we are considering is not recursive. What’s more, if we have a recursive test for sentences which would be grammatical if it were not for the any-thesis, then it cannot even be recursively enumerable – since there is a recursive enumeration of the ungrammatical sentences of our fragment (why?), it would contradict our weaker result, as a set is recursive iff it and its complement (in a recursive set) are both recursively enumerable (intuitively speaking, one could run both enumerations in parallel and every sentence is bound to pop up in one or the other). By a similar argument, it follows that the whole set of grammatical English sentences is not recursively enumerable either.
But this flatly contradicts the basic principles of generativism and what Hintikka calls the “recursive paradigm”. If the thesis is true, it follows that grammar cannot be conceived as based on generative rules as Chomsky would have us believe. And even if you disagree with this particular thesis (i.e. you disagree with some ordering principle proposed by Hintikka), it demonstrates that you cannot a priori exclude such rules from consideration, so there doesn’t appear to be any a priori reason to assume that the generativist enterprise can be successful and restrict ourselves to generativist accounts only, as we cannot rule out the existence of some similar semantic-based criterion of grammaticality. At the very least, the Chomskian must not only present valid counter-examples against the any-thesis, but also convincing arguments that such rules simply cannot operate in natural languages.
There is much more to discuss about game semantics and Hintikka, but I think I’ll end my attempt at an introduction here, for now at any rate. I hope it has been at least somewhat informative. If anyone’s interested in Hintikka’s polemic with Chomsky, check out article [2] (available in its entirety on Google Books). For a bit more about the “recursive” vs. “strategic” paradigm, try [4] (partly available online).
As for my opinion about this whole thing, I dunno. On the one hand, it seems unrealistic to assume that people would judge that grammaticality of complicated sentences including any by testing, on some level, their equivalence with the corresponding every construction. On the other hand, the concept of grammaticality partly breaks down when we’re dealing with sufficiently complicated sentences, so the set of “all” grammatical English sentences is to a large extent an artifact of the theory anyway, a matter of how we choose to extrapolate from the actual data which consists of grammaticality judgements of relatively simple sentences. In line with this, one way of interpreting the result (assuming the thesis holds for sentences of “normal” length) which is not completely unrealistic psychologically would be to assume that we do have a procedure which raises a red flag if it notices that the any construction is equivalent to the corresponding every construction and does so quite reliably for constructions of reasonable complexity and to extrapolate our notion of grammaticality from this. And Hintikka’s way of extrapolating seems quite elegant.
References (all papers by Hintikka):
[1] Quantifiers in Natural Languages: Some Logical Problems (1977), in Game-Theoretical Semantics
[2] On the Any-Thesis and the Methodology of Linguistics (1980), in Paradigms for Language Theory and Other Essays
[3] Rejoinder to Peacocke (1979), in Game-Theoretical Semantics
[4] Paradigms for Language Theory (1990), in Paradigms for Language Theory and Other Essays
]]>The rules
Now that we have an idea of what game semantics looks like, let’s see how one could apply it to English. The natural rules that correspond to our rules for propositional connectives (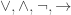
For existential quantification it is:
(G.some) When the game has reached a sentence of the form
X – some Y who Z – W,
a person may be chosen by myself. Let the proper name of that person be ‘b‘. Then the game is continued with respect to the sentence
X – b – W, b is a Y, and b Z.
An analogical rule (G.a(n)) can be devised for a(n).For universal quantification:
(G.every) When the game has reached a sentence of the form
X – every Y who Z – W,
a person may be chosen by Nature. Let the proper name of that person be ‘d‘. Then the game is continued with respect to the sentence
X – d – W if d is a Y and if d Z.
The rule (G.any) is analogical. Here we assume that Y and Z are singular and that the ‘who’ is the subject of ‘who Z’. The rules could be modified to deal with more general situations, but Hintikka does not go into that here.
The dependencies
So, we have defined some transformations which allow us to change an English sentence into a simpler English sentence. The natural question is, which order to we apply them in, and, since we are dealing with a game, what is their “informational status” (i.e. dependence, in the sense I talked about last time). I will discuss the first question in the next post (where we’ll finally get to the relevance of all this to linguistics itself), let us now concentrate on the latter. Hintikka argues that there are English sentences which do not exhibit a linear ordering of quantification. He provides an example:
Some novel by every novelist is mentioned in some survey by every critic.
This he interprets as being true only if the novel depends only on the novelist and the survey only on the critic. I.e. it is true in a state of affairs where
The bestselling book by every author is referred to in the longest essay by every critic
but not in a state of affairs where
The bestselling book by every author is referred to in the obituary essay on him by every critic.
I don’t know how about you, but I’d probably be quite willing to assent to the original statement even in such a situation. I would probably interpret it is “for every author and every critic, there is a book by the former which is mentioned in an essay by the latter” (but don’t mind my opinions). Against this, Hintikka gives an argument which I’m not sure I like, namely he appeals to the principle of charity and claims that even though the “literal meaning” of the sentence is as he says, people tend to interpret it the other way, because that’s the way “which is most likely to make the intended meaning of [the] utterance true” – just like the natural interpretation of “someone is hit by a car every week on this street” is simply an instance of the principle of charity, rather than an exception to the left-to-right ordering principle of English quantifiers.
Consider the sentence
John has not shown any of his paintings to some of his friends.
The natural interpretation is clearly that there are friends of John’s to whom he has shown none of paintings. But this seems to violate the left-to-right ordering principle (we would expect the scope of “any” to be greater than the scope of “some”). The principle of charity line of argument doesn’t seem to be applicable here, as it would not be anything out of ordinary if there were there were no paintings of John’s which he has shown to all of his friends. Partially-ordered quantification comes to the rescue, as we can simply interpret the two quantifiers to be independent of each other, which however turns out to be equivalent to the natural interpretation. Hintikka makes it clear that this is not due to some special behaviour of the “not”, as a similar analysis can be given for “John has shown all his paintings to some of his friends” (think it through yourself).
The other argument given is that “some novel by John is mentioned in some survey by every critic” clearly follows from the original sentence, but the “linear” interpretation (“there is one novel by John which is mentioned in some survey by every author”) is, according to Hintikka, “patently counter-intuitive”. Similarly with “some novel by every author is mentioned by every critic”. It is also argued that this nesting be arbitrarily complicated, that is that every sentence with branching quantifiers corresponds to some grammatical English sentence. Myself, I wouldn’t go as far as calling them patently counter-intuitive but I admit that in this case Hintikka’s interpretation seems acceptable. What I think Hintikka neglects, however, is that his sentences are a bit too abstract – I would say that their interpretation can also be expected to depend on stress (and possibly other prosodic features, too). I don’t think it’s possible to interpret the sentence “some novel by John is mentioned in some survey by every critic” (italics denoting stress) the way Hintikka does.
The implications
But however you feel about his particular examples, it seems undeniable that there are English sentences which can be naturally interpreted his way (for me, it would probably be sentences like “a particular book of every author is mentioned in a particular essay of every critic”). At the very least, even if you are unimpressed by any of his examples, they show that there is no a priori reason to assume that classical first-order predicate calculus can in general adequately capture quantification in natural language.
The importance of these findings (if true) is summarized at the end of Hintikka’s 1973 paper Quantifiers vs. Quantification Theory (according to the editor the first paper to discuss game semantics for natural language):
“Since our results suggest that the whole of f.p.o. quantification theory is built into the semantics of English quantifiers, it follows that the semantics of a relatively small fragment of English, viz. of English quantifiers plus a few supporting constructions, is a much subtler and much more complicated subject than anyone seems to have suspected. In the eyes of a logician, it seems to be powerful beyond the wildest dreams of linguists and of philosophers of language.”
Next time, I’ll try to wrap up this little introduction to Hintikka with his thesis concerning the interplay of syntax and semantics.
]]>A philosopher/logician I have long wanted to familiarize myself with is Jaakko Hintikka, one of the originators of game semantics – a semantics for logic based on game theory. So I picked up Game-Theoretical Semantics (edited by Esa Saarinen) at my library and plunged in. It turns out Hintikka has some interesting things to say about both formal logic and natural language. I originally intended to make a single post, but it seems best to split it into two parts, one dealing with the semantics itself, the other with applying it to natural language.
As you see, I am terrible at writing introductory fluff, so let’s get down to business. This post should be understandable to anyone with at least a cursory knowledge of formal logic. Just to refresh your memory: 

, I choose
, Nature chooses
, I choose a member of
, Nature chooses a member of
The rules are called, naturally enough, (G.
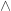


Using this process, we ultimately arrive at an atomic sentence 

Thus we have defined a semantics for first-order predicate calculus which determines which sentences are true and which are false. That this definition is reasonable should be obvious. Assuming the Axiom of Choice, one can easily use induction to prove that this definition of truth is equivalent to Tarski’s (truth = satisfaction by every assignment of objects to variables). The problematic step is where we have to jump from “for every 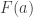
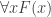
In fact, the easy modifiability to deal with non-classical logics is one of the main advantages of game semantics. For one thing, we might require the strategies to be computable functions. For another, the semantics works for a more general theory than classical logic if we relax a condition we have been tacitly assuming all along. Namely, the requirement of perfect information – that both players are informed about the previous choices made by their adversary (and remember their own) and their subsequent choices depend on them. The theory we get when we no longer assume such a dependence is called finite partially-ordered quantification or branching quantification. A typical formula with a branching quantifier might look like this:

This implies that the choice of 
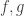

This sentence is not equivalent to any sentence of regular first-order predicate logic. On the other hand, the sentence:

is equivalent simply to:
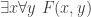
This, obviously, is an exception rather than the norm – it can be proven that (validity in) this logic of finite partially-ordered quantification is recursively equivalent to (validity in) second-order logic, i.e. there is an algorithm to turn a sentence in second-order logic (where we can quantify over predicates in addition to individuals) into an equivalent sentence in this “branching” logic. And second-order logic is, of course, a much stronger theory than first-order logic.
What implications all this has for natural language (English in particular) will be discussed next time.
]]>Instead, I’d like to write about some not too advanced maths and logic, language(s), analytic philosophy and political theory. Possibly more, possibly less.
It goes without saying that you’re encouraged to leave comments of any kind. As much as writing one’s thoughts down in a coherent manner helps to expose their hidden inconsistencies, feedback or not, the point of having a blog isn’t really to just keep throwing browserfuls of text into an insatiable electronic abyss, is it?
So enjoy this blog, write comments and let’s hope that I won’t look back at this post in a couple of weeks and laugh at how naive I was to think that I would keep updating it semi-regularly.
Cheers.
]]>