| CARVIEW |
Select Language
HTTP/2 301
server: envoy
x-frame-options: SAMEORIGIN
cache-control: public, s-maxage=86400, max-age=0, must-revalidate
location: https://www.slideshare.net/slideshow/djangocon-2010-scaling-disqus/5148151
x-envoy-upstream-service-time: 599
p3p: CP="OTI DSP COR CUR ADM DEV PSD IVD CONo OUR IND"
x-content-type-options: nosniff
accept-ranges: bytes
age: 0
date: Sat, 11 Oct 2025 04:17:38 GMT
via: 1.1 varnish
x-served-by: cache-bom-vanm7210028-BOM
x-cache: MISS
x-cache-hits: 0
x-timer: S1760156258.674708,VS0,VE847
vary: accept-encoding, x-bot
set-cookie: browser_id=0237ee65-a027-425a-b246-4e875c9caf2f; Domain=.slideshare.net; Path=/; Expires=Thu, 10 Oct 2030 04:17:38 GMT
strict-transport-security: max-age=63072000; includeSubDomains; preload
alt-svc: h3=":443";ma=86400,h3-29=":443";ma=86400,h3-27=":443";ma=86400
content-length: 74
HTTP/2 200
content-type: text/html; charset=utf-8
server: envoy
x-frame-options: SAMEORIGIN
cache-control: public, s-maxage=86400, max-age=0, must-revalidate
x-powered-by: Next.js
etag: "17fkptw1kb6ro27"
content-encoding: gzip
x-envoy-upstream-service-time: 628
p3p: CP="OTI DSP COR CUR ADM DEV PSD IVD CONo OUR IND"
x-content-type-options: nosniff
accept-ranges: bytes
age: 1
date: Sat, 11 Oct 2025 04:17:41 GMT
via: 1.1 varnish
x-served-by: cache-bom-vanm7210028-BOM
x-cache: MISS
x-cache-hits: 0
x-timer: S1760156259.535577,VS0,VE2514
vary: accept-encoding, x-bot
strict-transport-security: max-age=63072000; includeSubDomains; preload
alt-svc: h3=":443";ma=86400,h3-29=":443";ma=86400,h3-27=":443";ma=86400
content-length: 174112
DjangoCon 2010 Scaling Disqus | KEY 









![Pythonic Joins
Allows us to separate datasets
posts = Post.objects.all()[0:25]
# store users in a dictionary based on primary key
users = dict(
(u.pk, u) for u in
User.objects.filter(pk__in=set(p.user_id for p in posts))
)
# map users to their posts
for p in posts:
p._user_cache = users.get(p.user_id)](https://image.slidesharecdn.com/djangocon2010scalingdisqus-100907133713-phpapp01/75/DjangoCon-2010-Scaling-Disqus-17-2048.jpg)






![Removing the Cache
• Django internally caches the results of your QuerySet
• This adds additional memory overhead
# 1 query
qs = Model.objects.all()[0:100]
# 0 queries (we don’t need this behavior)
qs = qs[0:10]
# 1 query
qs = qs.filter(foo=bar)
• Many times you only need to view a result set once
• So we built SkinnyQuerySet](https://image.slidesharecdn.com/djangocon2010scalingdisqus-100907133713-phpapp01/75/DjangoCon-2010-Scaling-Disqus-25-2048.jpg)






![Delayed Signals (cont’d)
We send a specific serialized version
of the model for delayed signals
from disqus.common.signals import delayed_save
def my_func(data, sender, created, **kwargs):
print data[‘id’]
delayed_save.connect(my_func, sender=Post)
This is all handled through our Queue](https://image.slidesharecdn.com/djangocon2010scalingdisqus-100907133713-phpapp01/75/DjangoCon-2010-Scaling-Disqus-32-2048.jpg)


![Caching (cont’d)
• Default (naive) hashing behavior
• Modulo hashed cache key cache for index
to server list.
• Removal of a server causes majority of
cache keys to be remapped to new
servers.
CACHE_SERVERS = [‘10.0.0.1’, ‘10.0.0.2’]
key = ‘my_cache_key’
cache_server = CACHE_SERVERS[hash(key) % len(CACHE_SERVERS)]](https://image.slidesharecdn.com/djangocon2010scalingdisqus-100907133713-phpapp01/75/DjangoCon-2010-Scaling-Disqus-35-2048.jpg)


![Transactions
• TransactionMiddleware got us started, but
down the road became a burden
• For postgresql_psycopg2, there’s a database
option, OPTIONS[‘autocommit’]
• Each query is in its own transaction. This
means each request won’t start in a
transaction.
• But sometimes we want transactions
(e.g., saving multiple objects and rolling
back on error)](https://image.slidesharecdn.com/djangocon2010scalingdisqus-100907133713-phpapp01/75/DjangoCon-2010-Scaling-Disqus-38-2048.jpg)








![Testing (cont’d)
Query Counts
# failures yield a dump of queries
def test_read_slave(self):
Model.objects.using(‘read_slave’).count()
self.assertQueryCount(1, ‘read_slave’)
Selenium
def test_button(self):
self.selenium.click('//a[@class=”dsq-button”]')
Queue Integration
class WorkerTest(DisqusTest):
workers = [‘fire_signal’]
def test_delayed_signal(self):
...](https://image.slidesharecdn.com/djangocon2010scalingdisqus-100907133713-phpapp01/75/DjangoCon-2010-Scaling-Disqus-47-2048.jpg)







Uploaded byzeeg
KEY, PPTX32,794 views
DjangoCon 2010 Scaling Disqus
DISQUS is a comment system that handles high volumes of traffic, with up to 17,000 requests per second and 250 million monthly visitors. They face challenges in unpredictable spikes in traffic and ensuring high availability. Their architecture includes over 100 servers split between web servers, databases, caching, and load balancing. They employ techniques like vertical and horizontal data partitioning, atomic updates, delayed signals, consistent caching, and feature flags to scale their large Django application.
Download as KEY, PPTX











![Pythonic Joins
Allows us to separate datasets
posts = Post.objects.all()[0:25]
# store users in a dictionary based on primary key
users = dict(
(u.pk, u) for u in
User.objects.filter(pk__in=set(p.user_id for p in posts))
)
# map users to their posts
for p in posts:
p._user_cache = users.get(p.user_id)](https://image.slidesharecdn.com/djangocon2010scalingdisqus-100907133713-phpapp01/85/DjangoCon-2010-Scaling-Disqus-17-320.jpg)







![Removing the Cache
• Django internally caches the results of your QuerySet
• This adds additional memory overhead
# 1 query
qs = Model.objects.all()[0:100]
# 0 queries (we don’t need this behavior)
qs = qs[0:10]
# 1 query
qs = qs.filter(foo=bar)
• Many times you only need to view a result set once
• So we built SkinnyQuerySet](https://image.slidesharecdn.com/djangocon2010scalingdisqus-100907133713-phpapp01/85/DjangoCon-2010-Scaling-Disqus-25-320.jpg)






![Delayed Signals (cont’d)
We send a specific serialized version
of the model for delayed signals
from disqus.common.signals import delayed_save
def my_func(data, sender, created, **kwargs):
print data[‘id’]
delayed_save.connect(my_func, sender=Post)
This is all handled through our Queue](https://image.slidesharecdn.com/djangocon2010scalingdisqus-100907133713-phpapp01/85/DjangoCon-2010-Scaling-Disqus-32-320.jpg)


![Caching (cont’d)
• Default (naive) hashing behavior
• Modulo hashed cache key cache for index
to server list.
• Removal of a server causes majority of
cache keys to be remapped to new
servers.
CACHE_SERVERS = [‘10.0.0.1’, ‘10.0.0.2’]
key = ‘my_cache_key’
cache_server = CACHE_SERVERS[hash(key) % len(CACHE_SERVERS)]](https://image.slidesharecdn.com/djangocon2010scalingdisqus-100907133713-phpapp01/85/DjangoCon-2010-Scaling-Disqus-35-320.jpg)


![Transactions
• TransactionMiddleware got us started, but
down the road became a burden
• For postgresql_psycopg2, there’s a database
option, OPTIONS[‘autocommit’]
• Each query is in its own transaction. This
means each request won’t start in a
transaction.
• But sometimes we want transactions
(e.g., saving multiple objects and rolling
back on error)](https://image.slidesharecdn.com/djangocon2010scalingdisqus-100907133713-phpapp01/85/DjangoCon-2010-Scaling-Disqus-38-320.jpg)








![Testing (cont’d)
Query Counts
# failures yield a dump of queries
def test_read_slave(self):
Model.objects.using(‘read_slave’).count()
self.assertQueryCount(1, ‘read_slave’)
Selenium
def test_button(self):
self.selenium.click('//a[@class=”dsq-button”]')
Queue Integration
class WorkerTest(DisqusTest):
workers = [‘fire_signal’]
def test_delayed_signal(self):
...](https://image.slidesharecdn.com/djangocon2010scalingdisqus-100907133713-phpapp01/85/DjangoCon-2010-Scaling-Disqus-47-320.jpg)








More Related Content




![[245] presto 내부구조 파헤치기](https://cdn.slidesharecdn.com/ss_thumbnails/245presto-150915054242-lva1-app6891-thumbnail.jpg?width=600ounds&width=560&fit=bounds)



What's hot




















Viewers also liked




















Similar to DjangoCon 2010 Scaling Disqus



![Bye bye $GLOBALS['TYPO3_DB']](https://cdn.slidesharecdn.com/ss_thumbnails/goodbyedb-180215093653-thumbnail.jpg?width=600ounds&width=560&fit=bounds)





![IVS CTO Night And Day 2018 Winter - [re:Cap] Serverless & Mobile](https://cdn.slidesharecdn.com/ss_thumbnails/ivsctonightandday2018morningsession-serverlessmobilerecap-190115185144-thumbnail.jpg?width=600ounds&width=560&fit=bounds)










More from zeeg



























DjangoCon 2010 Scaling Disqus
- 1. Scaling the World’sLargest Django App Jason Yan David Cramer @jasonyan @zeeg
- 2.
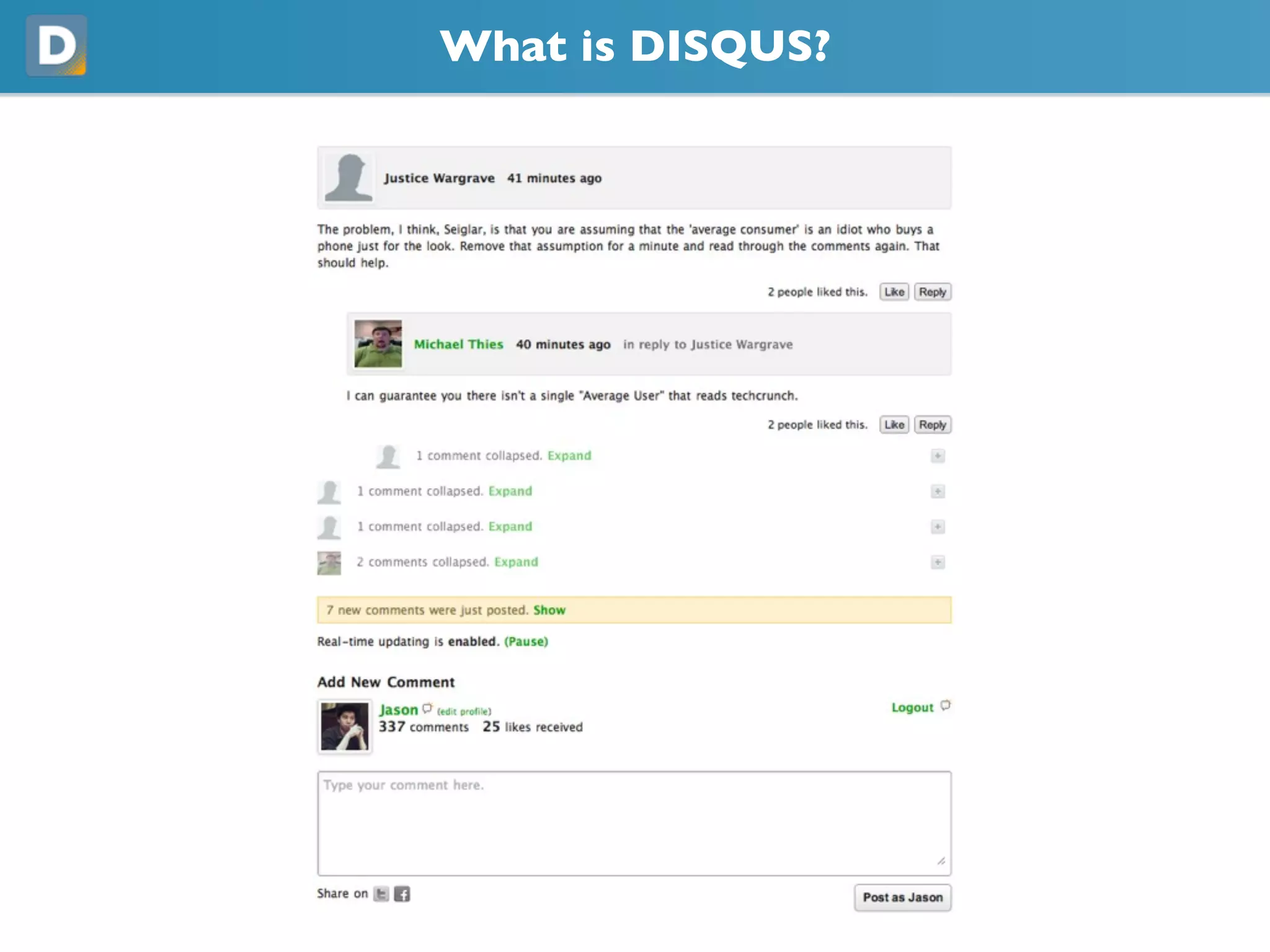
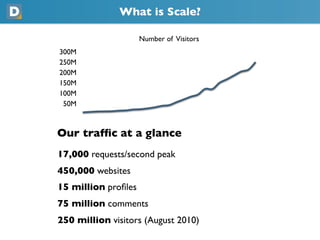
- 3. What is DISQUS? dis·cuss • dĭ-skŭs' We are a comment system with an emphasis on connecting communities https://disqus.com/about/
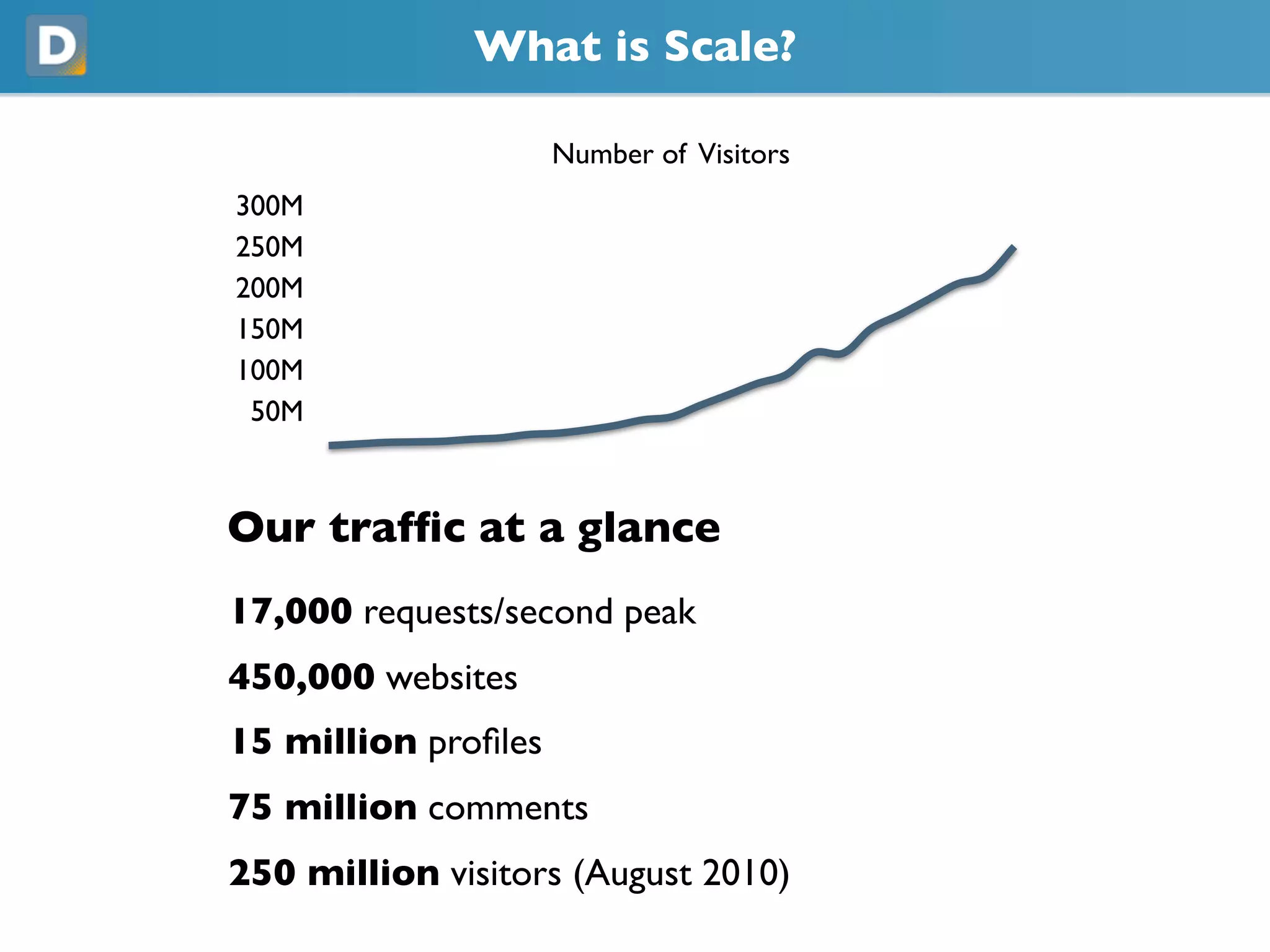
- 4. What is Scale? Number of Visitors 300M 250M 200M 150M 100M 50M Our traffic at a glance 17,000 requests/second peak 450,000 websites 15 million profiles 75 million comments 250 million visitors (August 2010)
- 5. Our Challenges • Wecan’t predict when things will happen • Random celebrity gossip • Natural disasters • Discussions never expire • We can’t keep those millions of articles from 2008 in the cache • You don’t know in advance (generally) where the traffic will be • Especially with dynamic paging, realtime, sorting, personal prefs, etc.
- 6. Our Challenges (cont’d) •High availability • Not a destination site • Difficult to schedule maintenance
- 7.
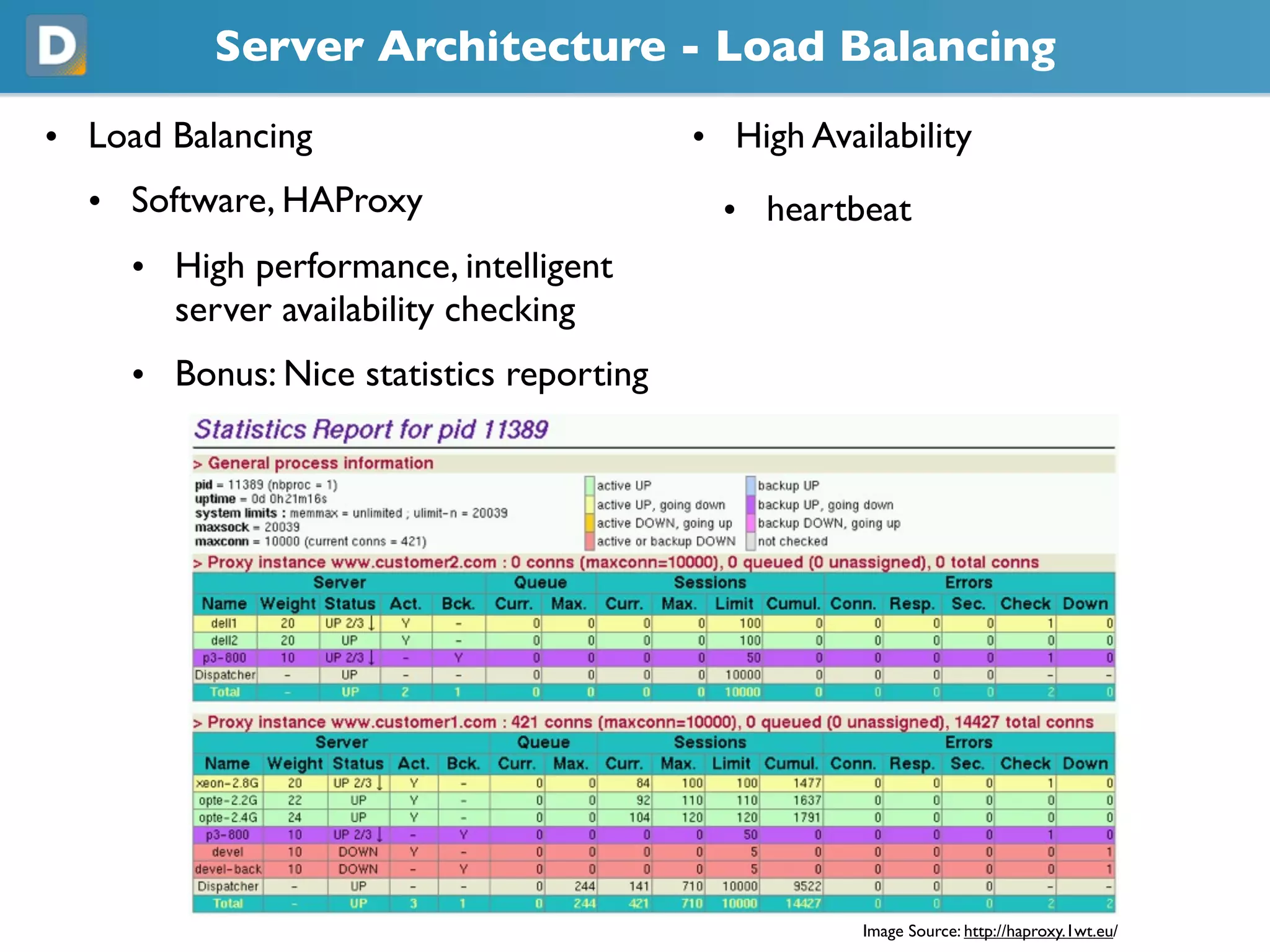
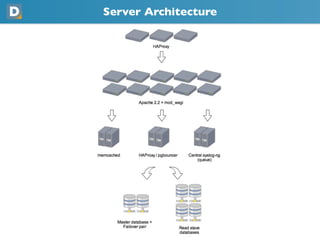
- 8. Server Architecture -Load Balancing • Load Balancing • High Availability • Software, HAProxy • heartbeat • High performance, intelligent server availability checking • Bonus: Nice statistics reporting Image Source: https://haproxy.1wt.eu/
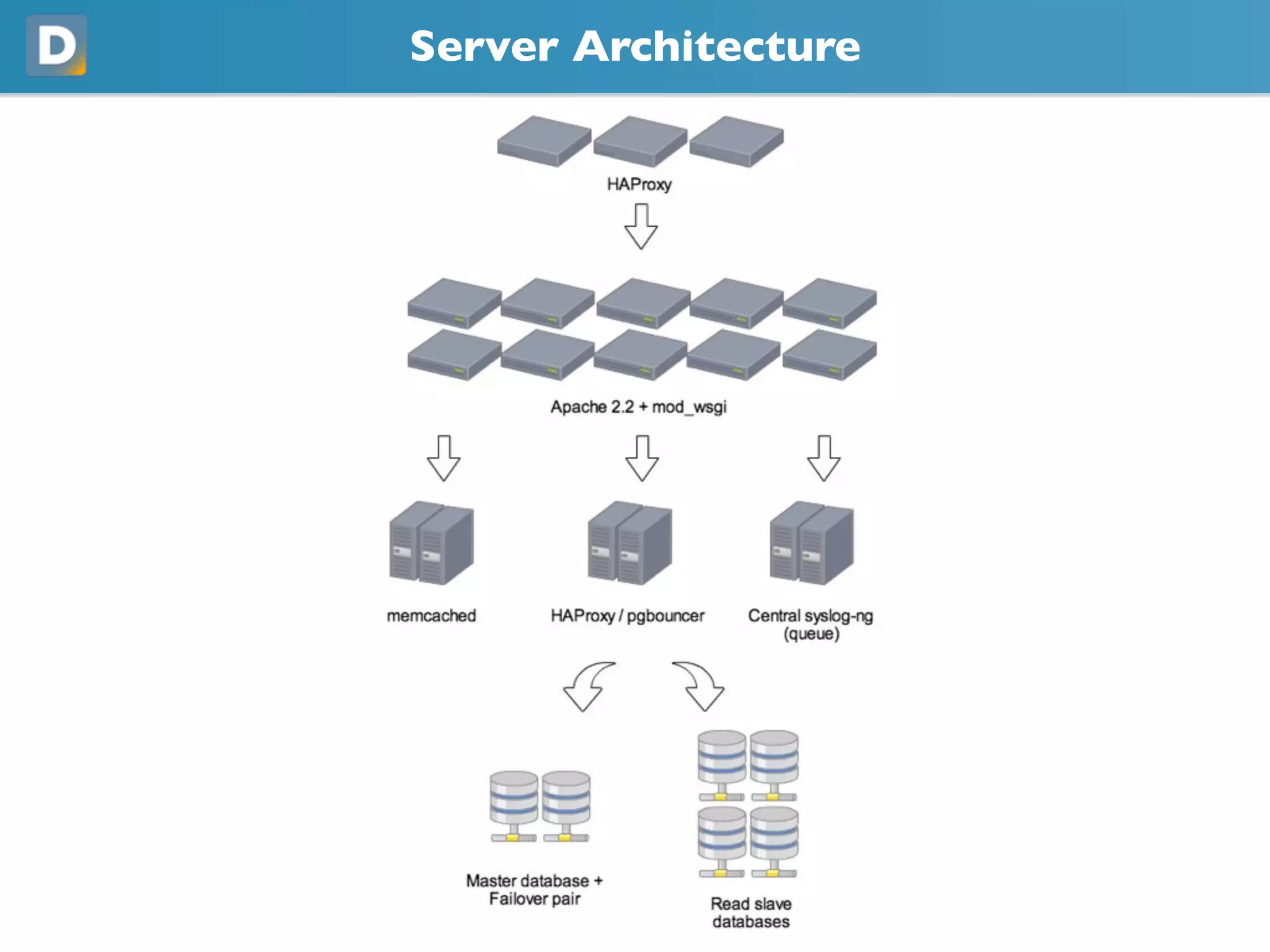
- 9. Server Architecture • ~100Servers • 30% Web Servers (Apache + mod_wsgi) • 10% Databases (PostgreSQL) • 25% Cache Servers (memcached) • 20% Load Balancing / High Availability (HAProxy + heartbeat) • 15% Utility Servers (Python scripts)
- 10. Server Architecture -Web Servers • Apache 2.2 • mod_wsgi • Using `maximum-requests` to plug memory leaks. • Performance Monitoring • Custom middleware (PerformanceLogMiddleware) • Ships performance statistics (DB queries, external calls, template rendering, etc) through syslog • Collected and graphed through Ganglia
- 11. Server Architecture -Database • PostgreSQL • Slony-I for Replication • Trigger-based • Read slaves for extra read capacity • Failover master database for high availability
- 12. Server Architecture -Database • Make sure indexes fit in memory and measure I/O • High I/O generally means slow queries due to missing indexes or indexes not in buffer cache • Log Slow Queries • syslog-ng + pgFouine + cron to automate slow query logging
- 13. Server Architecture -Database • Use connection pooling • Django doesn’t do this for you • We use pgbouncer • Limits the maximum number of connections your database needs to handle • Save on costly opening and tearing down of new database connections
- 14.
- 15. Partitioning • Fairly easyto implement, quick wins • Done at the application level • Data is replayed by Slony • Two methods of data separation
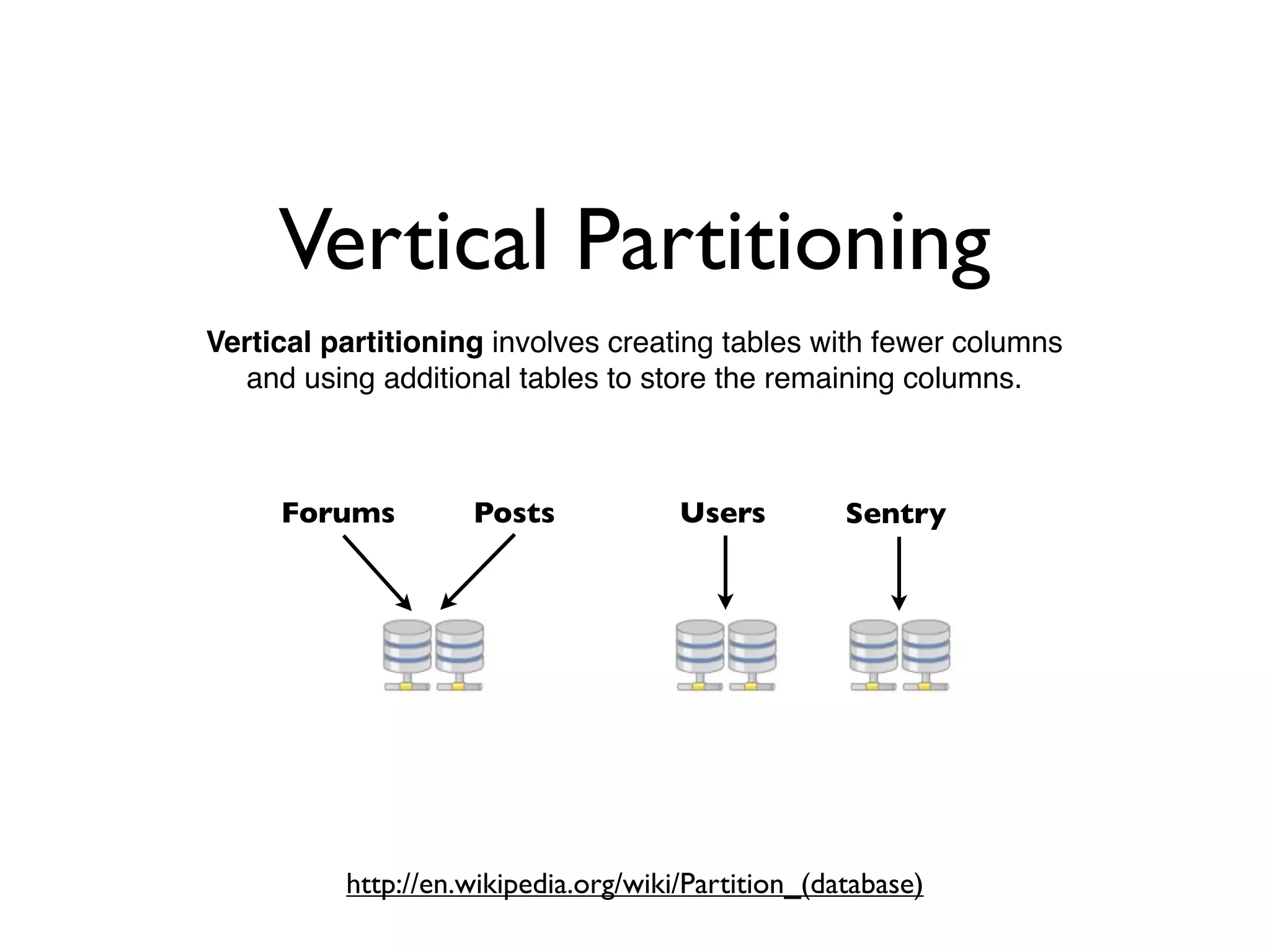
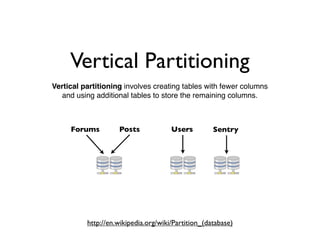
- 16. Vertical Partitioning Vertical partitioninginvolves creating tables with fewer columns and using additional tables to store the remaining columns. Forums Posts Users Sentry https://en.wikipedia.org/wiki/Partition_(database)
- 17. Pythonic Joins Allows us to separate datasets posts = Post.objects.all()[0:25] # store users in a dictionary based on primary key users = dict( (u.pk, u) for u in User.objects.filter(pk__in=set(p.user_id for p in posts)) ) # map users to their posts for p in posts: p._user_cache = users.get(p.user_id)
- 18. Pythonic Joins (cont’d) •Slower than at database level • But not enough that you should care • Trading performance for scale • Allows us to separate data • Easy vertical partitioning • More efficient caching • get_many, object-per-row cache
- 19. Designating Masters • Alleviatessome of the write load on your primary application master • Masters exist under specific conditions: • application use case • partitioned data • Database routers make this (fairly) easy
- 20. Routing by Application classApplicationRouter(object): def db_for_read(self, model, **hints): instance = hints.get('instance') if not instance: return None app_label = instance._meta.app_label return get_application_alias(app_label)
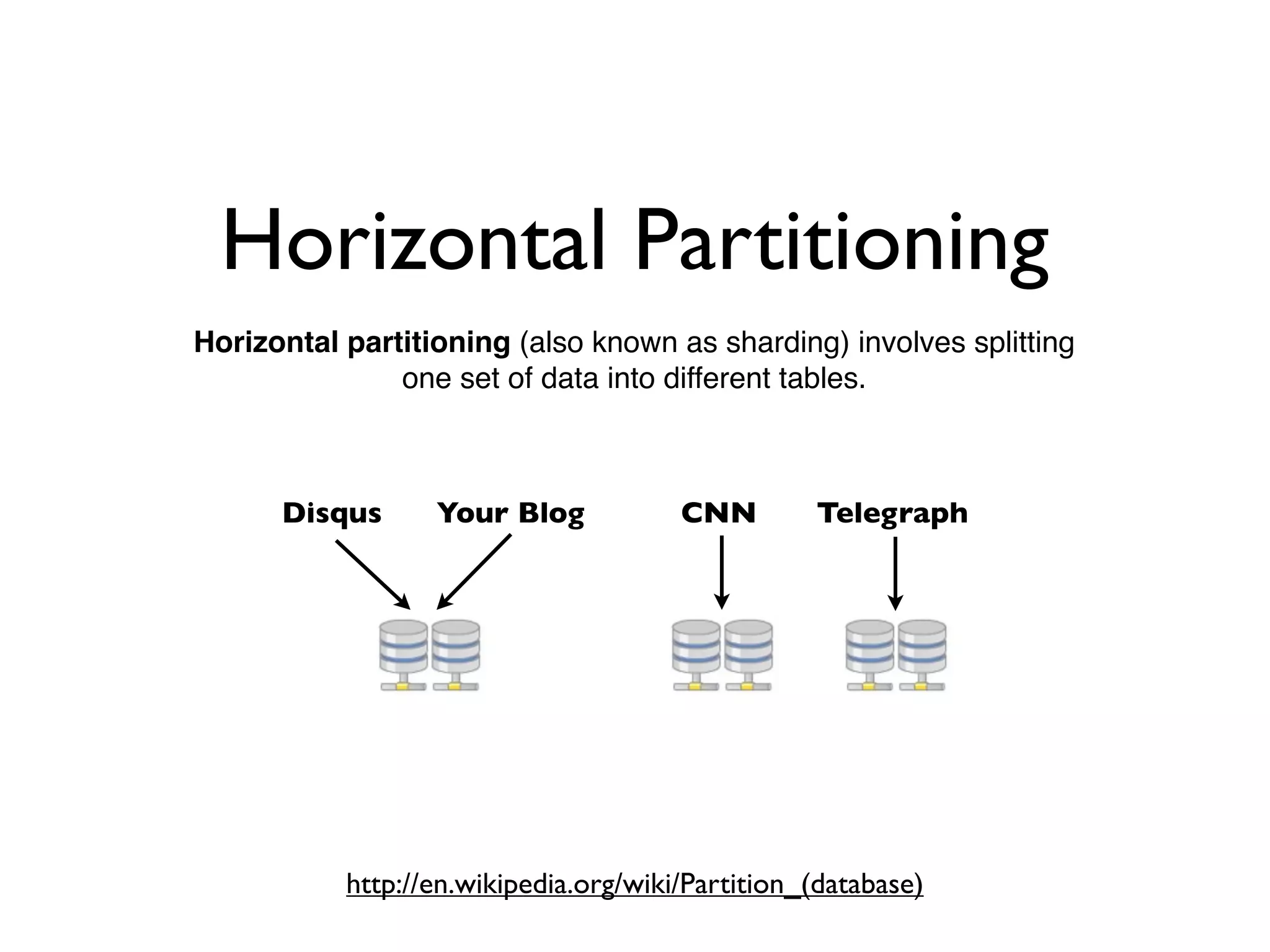
- 21. Horizontal Partitioning Horizontal partitioning(also known as sharding) involves splitting one set of data into different tables. Disqus Your Blog CNN Telegraph https://en.wikipedia.org/wiki/Partition_(database)
- 22. Horizontal Partitions • Someforums have very large datasets • Partners need high availability • Helps scale the write load on the master • We rely more on vertical partitions
- 23. Routing by Partition classForumPartitionRouter(object): def db_for_read(self, model, **hints): instance = hints.get('instance') if not instance: return None forum_id = getattr(instance, 'forum_id', None) if not forum_id: return None return get_forum_alias(forum_id) # What we used to do Post.objects.filter(forum=forum) # Now, making sure hints are available forum.post_set.all()
- 24. Optimizing QuerySets • Wereally dislike raw SQL • It creates more work when dealing with partitions • Built-in cache allows sub-slicing • But isn’t always needed • We removed this cache
- 25. Removing the Cache •Django internally caches the results of your QuerySet • This adds additional memory overhead # 1 query qs = Model.objects.all()[0:100] # 0 queries (we don’t need this behavior) qs = qs[0:10] # 1 query qs = qs.filter(foo=bar) • Many times you only need to view a result set once • So we built SkinnyQuerySet
- 26. Removing the Cache(cont’d) Optimizing memory usage by removing the cache class SkinnyQuerySet(QuerySet): def __iter__(self): if self._result_cache is not None: # __len__ must have been run return iter(self._result_cache) has_run = getattr(self, 'has_run', False) if has_run: raise QuerySetDoubleIteration("...") self.has_run = True # We wanted .iterator() as the default return self.iterator() https://gist.github.com/550438
- 27. Atomic Updates • Keepsyour data consistent • save() isnt thread-safe • use update() instead • Great for things like counters • But should be considered for all write operations
- 28. Atomic Updates (cont’d) Thread safety is impossible with .save() Request 1 post = Post(pk=1) # a moderator approves post.approved = True post.save() Request 2 post = Post(pk=1) # the author adjusts their message post.message = ‘Hello!’ post.save()
- 29. Atomic Updates (cont’d) So we need atomic updates Request 1 post = Post(pk=1) # a moderator approves Post.objects.filter(pk=post.pk) .update(approved=True) Request 2 post = Post(pk=1) # the author adjusts their message Post.objects.filter(pk=post.pk) .update(message=‘Hello!’)
- 30. Atomic Updates (cont’d) A better way to approach updates def update(obj, using=None, **kwargs): """ Updates specified attributes on the current instance. """ assert obj, "Instance has not yet been created." obj.__class__._base_manager.using(using) .filter(pk=obj) .update(**kwargs) for k, v in kwargs.iteritems(): if isinstance(v, ExpressionNode): # NotImplemented continue setattr(obj, k, v) https://github.com/andymccurdy/django-tips-and-tricks/blob/master/model_update.py
- 31. Delayed Signals • Queueinglow priority tasks • even if they’re fast • Asynchronous (Delayed) signals • very friendly to the developer • ..but not as friendly as real signals
- 32. Delayed Signals (cont’d) We send a specific serialized version of the model for delayed signals from disqus.common.signals import delayed_save def my_func(data, sender, created, **kwargs): print data[‘id’] delayed_save.connect(my_func, sender=Post) This is all handled through our Queue
- 33. Caching • Memcached • Usepylibmc (newer libMemcached-based) • Ticket #11675 (add pylibmc support) • Third party applications: • django-newcache, django-pylibmc
- 34. Caching (cont’d) • libMemcached/ pylibmc is configurable with “behaviors”. • Memcached “single point of failure” • Distributed system, but we must take precautions. • Connection timeout to memcached can stall requests. • Use `_auto_eject_hosts` and `_retry_timeout` behaviors to prevent reconnecting to dead caches.
- 35. Caching (cont’d) • Default (naive) hashing behavior • Modulo hashed cache key cache for index to server list. • Removal of a server causes majority of cache keys to be remapped to new servers. CACHE_SERVERS = [‘10.0.0.1’, ‘10.0.0.2’] key = ‘my_cache_key’ cache_server = CACHE_SERVERS[hash(key) % len(CACHE_SERVERS)]
- 36. Caching (cont’d) • Betterapproach: consistent hashing • libMemcached (pylibmc) uses libketama (https://tinyurl.com/lastfm-libketama) • Addition / removal of a cache server remaps (K/n) cache keys (where K=number of keys and n=number of servers) Image Source: https://sourceforge.net/apps/mediawiki/kai/index.php?title=Introduction
- 37. Caching (cont’d) • Thunderingherd (stampede) problem • Invalidating a heavily accessed cache key causes many clients to refill cache. • But everyone refetching to fill the cache from the data store or reprocessing data can cause things to get even slower. • Most times, it’s ideal to return the previously invalidated cache value and let a single client refill the cache. • django-newcache or MintCache (https:// djangosnippets.org/snippets/793/) will do this for you. • Prefer filling cache on invalidation instead of deleting from cache also helps to prevent the thundering herd problem.
- 38. Transactions • TransactionMiddleware gotus started, but down the road became a burden • For postgresql_psycopg2, there’s a database option, OPTIONS[‘autocommit’] • Each query is in its own transaction. This means each request won’t start in a transaction. • But sometimes we want transactions (e.g., saving multiple objects and rolling back on error)
- 39. Transactions (cont’d) • Tips: • Use autocommit for read slave databases. • Isolate slow functions (e.g., external calls, template rendering) from transactions. • Selective autocommit • Most read-only views don’t need to be in transactions. • Start in autocommit and switch to a transaction on write.
- 40. Scaling the Team •Small team of engineers • Monthly users / developers = 40m • Which means writing tests.. • ..and having a dead simple workflow
- 41. Keeping it Simple •A developer can be up and running in a few minutes • assuming postgres and other server applications are already installed • pip, virtualenv • settings.py
- 42. Setting Up Local 1.createdb -E UTF-8 disqus 2. git clone git://repo 3. mkvirtualenv disqus 4. pip install -U -r requirements.txt 5. ./manage.py syncdb && ./manage.py migrate
- 43. Sane Defaults settings.py from disqus.conf.settings.defaultimport * try: from local_settings import * except ImportError: import sys, traceback sys.stderr.write("Can't find 'localsettings.py’n”) sys.stderr.write("nThe exception was:nn") traceback.print_exc() local_settings.py from disqus.conf.settings.dev import *
- 44. Continuous Integration • Dailydeploys with Fabric • several times an hour on some days • Hudson keeps our builds going • combined with Selenium • Post-commit hooks for quick testing • like Pyflakes • Reverting to a previous version is a matter of seconds
- 45. Continuous Integration (cont’d) Hudson makes integration easy
- 46. Testing • It’s notfun breaking things when you’re the new guy • Our testing process is fairly heavy • 70k (Python) LOC, 73% coverage, 20 min suite • Custom Test Runner (unittest) • We needed XML, Selenium, Query Counts • Database proxies (for read-slave testing) • Integration with our Queue
- 47. Testing (cont’d) Query Counts #failures yield a dump of queries def test_read_slave(self): Model.objects.using(‘read_slave’).count() self.assertQueryCount(1, ‘read_slave’) Selenium def test_button(self): self.selenium.click('//a[@class=”dsq-button”]') Queue Integration class WorkerTest(DisqusTest): workers = [‘fire_signal’] def test_delayed_signal(self): ...
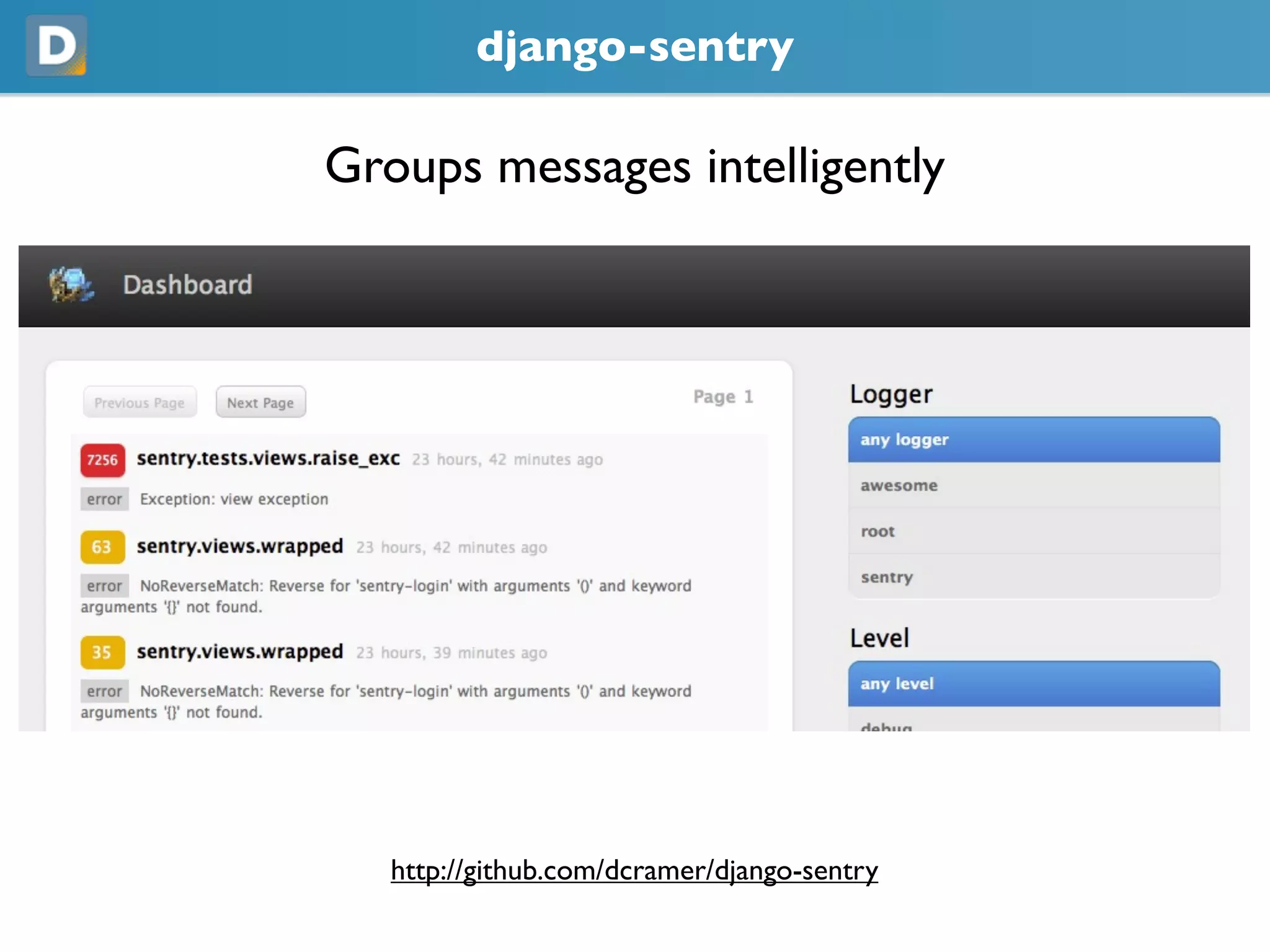
- 48. Bug Tracking • Switchedfrom Trac to Redmine • We wanted Subtasks • Emailing exceptions is a bad idea • Even if its localhost • Previously using django-db-log to aggregate errors to a single point • We’ve overhauled db log and are releasing Sentry
- 49. django-sentry Groups messages intelligently https://github.com/dcramer/django-sentry
- 50. django-sentry (cont’d) Similar feelto Django’s debugger https://github.com/dcramer/django-sentry
- 51. Feature Switches • Weneeded a safety in case a feature wasn’t performing well at peak • it had to respond without delay, globally, and without writing to disk • Allows us to work out of trunk (mostly) • Easy to release new features to a portion of your audience • Also nice for “Labs” type projects
- 52.
- 53. Final Thoughts • Thelanguage (usually) isn’t your problem • We like Django • But we maintain local patches • Some tickets don’t have enough of a following • Patches, like #17, completely change Django.. • ..arguably in a good way • Others don’t have champions Ticket #17 describes making the ORM an identify mapper
- 54. Housekeeping Birds of a Feather Want to learn from others about performance and scaling problems? Or play some StarCraft 2? We’re Hiring! DISQUS is looking for amazing engineers
- 55.
- 56. References django-sentry https://github.com/dcramer/django-sentry Our Feature Switches https://cl.ly/2FYt AndyMcCurdy’s update() https://github.com/andymccurdy/django-tips-and-tricks Our PyFlakes Fork https://github.com/dcramer/pyflakes SkinnyQuerySet https://gist.github.com/550438 django-newcache https://github.com/ericflo/django-newcache attach_foreignkey (Pythonic Joins) https://gist.github.com/567356
Editor's Notes
- #2 Hi. I'm Jason (and I'm David), and we're from Disqus.
- #3 Show of hands, How many of you know what DISQUS is?
- #4 For those of you who are not familiar with us, DISQUS is a comment system that focuses on connecting communities. We power discussions on such sites as CNN, IGN, and more recently Engadget and TechCrunch. Our company was founded back in 2007 by my co-founder, Daniel Ha, and I back where we started working out of our dorm room. Our decision to use Django came down primarily to our dislike for PHP which we were previously using. Since then, we've grown Disqus to over 250+ million visitors a month.
- #5 We've peaked at over 17,000 requests per second, to Django, and we currently power comments on nearly half a million websites which accounts for more than 15 million profiles who have left over 75 million comments.
- #6 As you can imagine we have some big challenges when it comes to scaling a large Django application. For one, it’s hard to predict when events happen like last year with Michael Jackson’s death, and more recently, the Gulf Oil Spill. Another challenge we have is the fact that discussions never expire. When you visit that blog post from 2008 we have to be ready to serve those comments immediately. Not only does THAT make caching difficult, but we also have to deal with things such as dynamic paging, realtime commenting, and other personal preferences. This makes it even more important to be able to serve those quickly without relying on the cache.
- #7 So we also have some interesting infrastructure problems when it comes to scaling Disqus. We're not a destination website, so if we go down, it affects other sites as well as ours. Because of this, it's difficult for us to schedule maintenance, so we face some interesting scaling and availbility challenges.
- #8 As you can see, we have tried to keep the stack pretty thin. This is because, as we've learned, the more services we try to add, the more difficult it is to support. And especially because we have a small team, this becomes difficult to manage. So we use DNS load balancing to spread the requests to multiple HAProxy servers which are our software load balancers. These proxy requests to our backend app servers which run mod_wsgi. We use memcache for caching, and we have a custom wrapper using syslog for our queue. For our data store, we use PostgreSQL, and for replication, we use Slony for failover and read slaves.
- #9 As I said, we use HAProxy for HTTP load balancing. It's a high performance software load balancer with intelligent failure detection. It also provides you with nice statistics of your requests. We use heartbeat for high availability and we have it take over the IP address of the down machine.
- #10 We have about 100GB of cache. Because of our high availability requirements, 20% are allocated to high availability and load balancing.
- #11 Our web servers are pretty standard. We use mod_wsgi mostly because it just works. Performance wise, you're really going to be bottlenecked on the application. The cool thing we do is that we actually hasve a custom middleware that does performance monitoring. What this does is ship data from our application about external calls like database, cache calls, and we collect it and graph it with Ganglia.
- #12 The more interesting aspect of our server architecture is how we have our database setup. As I mentioned, we use Postgres as our database. Honestly, we used it because Django recommended it, and my recommendation is that if you’re not already an expert in a database, you're better off going with Postgres. We use slony for replication Slony is trigger-based which means that every write is captured and strored in a log table and those events are replayed to slave databases. This is nice over otehr methods such as log shipping because it allows us to have flexible schemas across read lsaves. For example, some of our read slaves have different indexes. We also use slony for failover for high availbility.
- #13 There are a few things we do to keep our database healthy. We keep our indexes in memory, and when we can't, we partition our data. We also have application-specific indexes on our readslaves. Another important thing we've done is measure I/O. Any time we've seen high I/O is usually because we're missing indexes or indexes aren't fitting in memory. Lastly, we monitor slow queries. We send logs to pgfouine via syslog which genererates a nice report showing you which queries are the slowest.
- #14 The last thing we've found to be really helpful is switching to database connection pool. Remember, Django doesn't do this for you. We use pgbouncer for this, and there are a few easy wins for using it. One is that it limits the maximum connections to the database so it doesn't have to handle as many concurrent connections. Secpondly, you save the cost of opening and tearing down new connections per request.
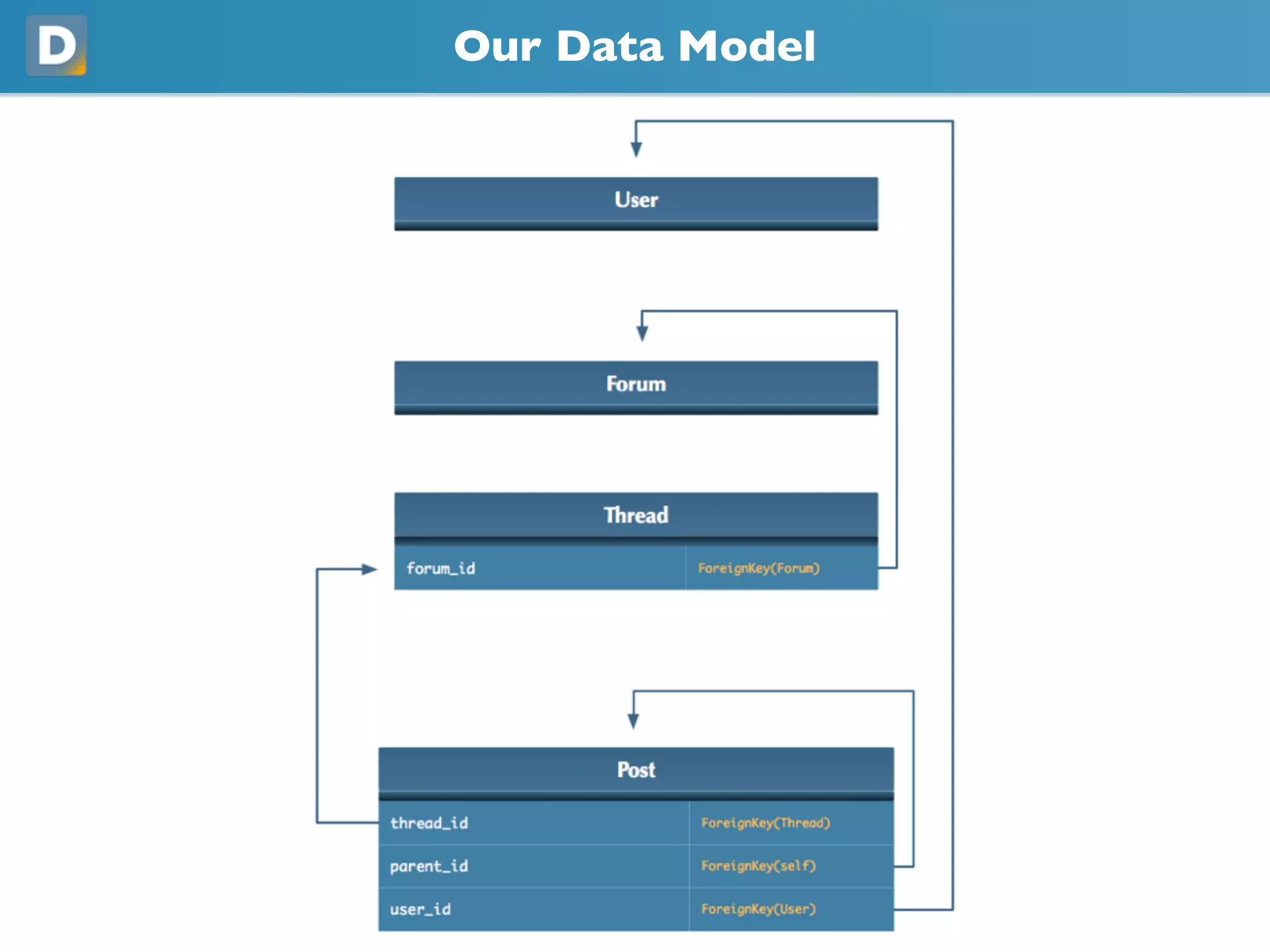
- #15 Moving on to our application, we’ve found that most of the struggle is with the database layer. We’ve got a pretty standard layout if you’re familiar with forums. Forum has many threads, which has many posts. Posts use an adjacency list model, and also reference Users. With this kind of data model, one of our quickest wins has been the ability to partition data.
- #16 It’s almost entirely done at the application level, which makes it fairly easy to implement. The only thing not handled by the app is replication, and Slony does that for us. We handle partitioning in a couple of ways.
- #17 The first of which are vertical partitions. This is probably the simplest thing you can implement in your application. Kill off your joins and spread out your applications on multiple databases. Some database engines might make this easier than others, but Slony allows us to easily replicate very specific data.
- #18 Using this method you’ll need to handle joins in your Python application. We do this by performing two separate queries and mapping the foreign keys to the parent objects. For us the easiest way has been to throw them into a dictionary, iterate through the other queryset, and set the foreignkey cache’s value to the instance.
- #19 A few things to keep in mind when doing pythonic joins. They’re not going to be as fast in the database. You can’t avoid this, but it’s not something you should worry about. With this however, you get plain and simple vertical partitions. You also can cache things a lot easier, and more efficiently fetch them using things like get_many and a singular object cache. Overall your’e trading performance for scale.
- #20 Another benefit that comes from vertical partitioning is the ability to designate masters. We do this to alleviate some of the load on our primary application master. So for example, server FOO might be the source for writes on the Users table, while server BAR handles all of our other forum data. Since we’re using Django 1.2 we also get routing for free through the new routers.
- #21 Here’s an example of a simple application router. It let’s us specify a read-slave based on our app label. So if its users, we go to FOO, if its forums, we go to BAR. You can handle this logic any way you want, pretty simple and powerful.
- #22 While we use vertical partitioning for most cases, eventually you hit an issue where your data just doesn’t scale on a single database. You’re probably familiar with the word sharding, well that’s what we do with our forum data. We’ve set it up so that we can send certain large sites to dedicated machines. This also uses designated masters as we mentioned with the other partitions.
- #23 We needed this when write and read load combined became so big that it was just hard to keep up on a single set of machines. It also gives the nice added benefit of high availability in many situations. Mostly though, it all goes back to scaling our master databases.
- #24 So again we’re using the router here to handle partitioning of the forums. We can specify that CNN goes to this database alias, which could be any number of machines, and everything else goes to our default cluster. The one caveat we found with this, is sometimes hints aren’t present in the router. I believe within the current version of Django they are only available when using a relational lookup, such as a foreign key. All in all it’s pretty powerful, and you just need to be aware of it while writing your queries.