1,195 posts tagged “python”
The Python programming language.
2025
TIL: Testing different Python versions with uv with-editable and uv-test.
While tinkering with upgrading various projects to handle Python 3.14 I finally figured out a universal uv recipe for running the tests for the current project in any specified version of Python:
uv run --python 3.14 --isolated --with-editable '.[test]' pytest
This should work in any directory with a pyproject.toml (or even a setup.py) that defines a test set of extra dependencies and uses pytest.
The --with-editable '.[test]' bit ensures that changes you make to that directory will be picked up by future test runs. The --isolated flag ensures no other environments will affect your test run.
I like this pattern so much I built a little shell script that uses it, shown here. Now I can change to any Python project directory and run:
uv-test
Or for a different Python version:
uv-test -p 3.11
I can pass additional pytest options too:
uv-test -p 3.11 -k permissions
Claude can write complete Datasette plugins now
This isn’t necessarily surprising, but it’s worth noting anyway. Claude Sonnet 4.5 is capable of building a full Datasette plugin now.
[... 1,296 words]Python 3.14 Is Here. How Fast Is It?
(via)
Miguel Grinberg uses some basic benchmarks (like fib(40)) to test the new Python 3.14 on Linux and macOS and finds some substantial speedups over Python 3.13 - around 27% faster.
The optional JIT didn't make a meaningful difference to his benchmarks. On a threaded benchmark he got 3.09x speedup with 4 threads using the free threading build - for Python 3.13 the free threading build only provided a 2.2x improvement.
Python 3.14. This year's major Python version, Python 3.14, just made its first stable release!
As usual the what's new in Python 3.14 document is the best place to get familiar with the new release:
The biggest changes include template string literals, deferred evaluation of annotations, and support for subinterpreters in the standard library.
The library changes include significantly improved capabilities for introspection in asyncio, support for Zstandard via a new compression.zstd module, syntax highlighting in the REPL, as well as the usual deprecations and removals, and improvements in user-friendliness and correctness.
Subinterpreters look particularly interesting as a way to use multiple CPU cores to run Python code despite the continued existence of the GIL. If you're feeling brave and your dependencies cooperate you can also use the free-threaded build of Python 3.14 - now officially supported - to skip the GIL entirely.
A new major Python release means an older release hits the end of its support lifecycle - in this case that's Python 3.9. If you maintain open source libraries that target every supported Python versions (as I do) this means features introduced in Python 3.10 can now be depended on! What's new in Python 3.10 lists those - I'm most excited by structured pattern matching (the match/case statement) and the union type operator, allowing int | float | None as a type annotation in place of Optional[Union[int, float]].
If you use uv you can grab a copy of 3.14 using:
uv self update
uv python upgrade 3.14
uvx python@3.14
Or for free-threaded Python 3.1;:
uvx python@3.14t
The uv team wrote about their Python 3.14 highlights in their announcement of Python 3.14's availability via uv.
The GitHub Actions setup-python action includes Python 3.14 now too, so the following YAML snippet in will run tests on all currently supported versions:
strategy:
matrix:
python-version: ["3.10", "3.11", "3.12", "3.13", "3.14"]
steps:
- uses: actions/setup-python@v6
with:
python-version: ${{ matrix.python-version }}
Full example here for one of my many Datasette plugin repos.
gpt-image-1-mini.
OpenAI released a new image model today: gpt-image-1-mini, which they describe as "A smaller image generation model that’s 80% less expensive than the large model."
They released it very quietly - I didn't hear about this in the DevDay keynote but I later spotted it on the DevDay 2025 announcements page.
It wasn't instantly obvious to me how to use this via their API. I ended up vibe coding a Python CLI tool for it so I could try it out.
I dumped the plain text diff version of the commit to the OpenAI Python library titled feat(api): dev day 2025 launches into ChatGPT GPT-5 Thinking and worked with it to figure out how to use the new image model and build a script for it. Here's the transcript and the the openai_image.py script it wrote.
I had it add inline script dependencies, so you can run it with uv like this:
export OPENAI_API_KEY="$(llm keys get openai)"
uv run https://tools.simonwillison.net/python/openai_image.py "A pelican riding a bicycle"
It picked this illustration style without me specifying it:

(This is a very different test from my normal "Generate an SVG of a pelican riding a bicycle" since it's using a dedicated image generator, not having a text-based model try to generate SVG code.)
My tool accepts a prompt, and optionally a filename (if you don't provide one it saves to a filename like /tmp/image-621b29.png).
It also accepts options for model and dimensions and output quality - the --help output lists those, you can see that here.
OpenAI's pricing is a little confusing. The model page claims low quality images should cost around half a cent and medium quality around a cent and a half. It also lists an image token price of $8/million tokens. It turns out there's a default "high" quality setting - most of the images I've generated have reported between 4,000 and 6,000 output tokens, which costs between 3.2 and 4.8 cents.
One last demo, this time using --quality low:
uv run https://tools.simonwillison.net/python/openai_image.py \
'racoon eating cheese wearing a top hat, realistic photo' \
/tmp/racoon-hat-photo.jpg \
--size 1024x1024 \
--output-format jpeg \
--quality low
This saved the following:

And reported this to standard error:
{
"background": "opaque",
"created": 1759790912,
"generation_time_in_s": 20.87331541599997,
"output_format": "jpeg",
"quality": "low",
"size": "1024x1024",
"usage": {
"input_tokens": 17,
"input_tokens_details": {
"image_tokens": 0,
"text_tokens": 17
},
"output_tokens": 272,
"total_tokens": 289
}
}
This took 21s, but I'm on an unreliable conference WiFi connection so I don't trust that measurement very much.
272 output tokens = 0.2 cents so this is much closer to the expected pricing from the model page.
[2 points] Learn basic NumPy operations with an AI tutor! Use an AI chatbot (e.g., ChatGPT, Claude, Gemini, or Stanford AI Playground) to teach yourself how to do basic vector and matrix operations in NumPy (import numpy as np). AI tutors have become exceptionally good at creating interactive tutorials, and this year in CS221, we're testing how they can help you learn fundamentals more interactively than traditional static exercises.
— Stanford CS221 Autumn 2025, Problem 1: Linear Algebra
Anthropic: A postmortem of three recent issues. Anthropic had a very bad month in terms of model reliability:
Between August and early September, three infrastructure bugs intermittently degraded Claude's response quality. We've now resolved these issues and want to explain what happened. [...]
To state it plainly: We never reduce model quality due to demand, time of day, or server load. The problems our users reported were due to infrastructure bugs alone. [...]
We don't typically share this level of technical detail about our infrastructure, but the scope and complexity of these issues justified a more comprehensive explanation.
I'm really glad Anthropic are publishing this in so much detail. Their reputation for serving their models reliably has taken a notable hit.
I hadn't appreciated the additional complexity caused by their mixture of different serving platforms:
We deploy Claude across multiple hardware platforms, namely AWS Trainium, NVIDIA GPUs, and Google TPUs. [...] Each hardware platform has different characteristics and requires specific optimizations.
It sounds like the problems came down to three separate bugs which unfortunately came along very close to each other.
Anthropic also note that their privacy practices made investigating the issues particularly difficult:
The evaluations we ran simply didn't capture the degradation users were reporting, in part because Claude often recovers well from isolated mistakes. Our own privacy practices also created challenges in investigating reports. Our internal privacy and security controls limit how and when engineers can access user interactions with Claude, in particular when those interactions are not reported to us as feedback. This protects user privacy but prevents engineers from examining the problematic interactions needed to identify or reproduce bugs.
The code examples they provide to illustrate a TPU-specific bug show that they use Python and JAX as part of their serving layer.
Announcing the 2025 PSF Board Election Results! I'm happy to share that I've been re-elected for second term on the board of directors of the Python Software Foundation.
Jannis Leidel was also re-elected and Abigail Dogbe and Sheena O’Connell will be joining the board for the first time.
In Python 3.14, I have implemented several changes to fix thread safety of
asyncioand enable it to scale effectively on the free-threaded build of CPython. It is now implemented using lock-free data structures and per-thread state, allowing for highly efficient task management and execution across multiple threads. In the general case of multiple event loops running in parallel, there is no lock contention and performance scales linearly with the number of threads. [...]For a deeper dive into the implementation, check out the internal docs for asyncio.
— Kumar Aditya, Scaling asyncio on Free-Threaded Python
I Replaced Animal Crossing’s Dialogue with a Live LLM by Hacking GameCube Memory (via) Brilliant retro-gaming project by Josh Fonseca, who figured out how to run 2002 Game Cube Animal Crossing in the Dolphin Emulator such that dialog with the characters was instead generated by an LLM.
The key trick was running Python code that scanned the Game Cube memory every 10th of a second looking for instances of dialogue, then updated the memory in-place to inject new dialog.
The source code is in vuciv/animal-crossing-llm-mod on GitHub. I dumped it (via gitingest, ~40,000 tokens) into Claude Opus 4.1 and asked the following:
This interacts with Animal Crossing on the Game Cube. It uses an LLM to replace dialog in the game, but since an LLM takes a few seconds to run how does it spot when it should run a prompt and then pause the game while the prompt is running?
Claude pointed me to the watch_dialogue() function which implements the polling loop.
When it catches the dialogue screen opening it writes out this message instead:
loading_text = ".<Pause [0A]>.<Pause [0A]>.<Pause [0A]><Press A><Clear Text>"
Those <Pause [0A]> tokens cause the came to pause for a few moments before giving the user the option to <Press A> to continue. This gives time for the LLM prompt to execute and return new text which can then be written to the correct memory area for display.
Hacker News commenters spotted some fun prompts in the source code, including this prompt to set the scene:
You are a resident of a town run by Tom Nook. You are beginning to realize your mortgage is exploitative and the economy is unfair. Discuss this with the player and other villagers when appropriate.
And this sequence of prompts that slowly raise the agitation of the villagers about their economic situation over time.
The system actually uses two separate prompts - one to generate responses from characters and another which takes those responses and decorates them with Animal Crossing specific control codes to add pauses, character animations and other neat effects.
My review of Claude’s new Code Interpreter, released under a very confusing name
Today on the Anthropic blog: Claude can now create and edit files:
[... 2,771 words]The 2025 PSF Board Election is Open! The Python Software Foundation's annual board member election is taking place right now, with votes (from previously affirmed voting members) accepted from September 2nd, 2:00 pm UTC through Tuesday, September 16th, 2:00 pm UTC.
I've served on the board since 2022 and I'm running for a second term. Here's the opening section of my nomination statement.
Hi, I'm Simon Willison. I've been a board member of the Python Software Foundation since 2022 and I'm running for re-election in 2025.
Last year I wrote a detailed article about Things I’ve learned serving on the board of the Python Software Foundation. I hope to continue learning and sharing what I've learned for a second three-year term.
One of my goals for a second term is to help deepen the relationship between the AI research world and the Python Software Foundation. There is an enormous amount of value being created in the AI space using Python and I would like to see more of that value flow back into the rest of the Python ecosystem.
I see the Python Package Index (PyPI) as one of the most impactful projects of the Python Software Foundation and plan to continue to advocate for further investment in the PyPI team and infrastructure.
As a California resident I'm excited to see PyCon return to the West Coast, and I'm looking forward to getting involved in helping make PyCon 2026 and 2027 in Long Beach, California as successful as possible.
I'm delighted to have been endorsed this year by Al Sweigart, Loren Crary and Christopher Neugebauer. If you are a voting member I hope I have earned your vote this year.
You can watch video introductions from several of the other nominees in this six minute YouTube video and this playlist.
Recreating the Apollo AI adoption rate chart with GPT-5, Python and Pyodide
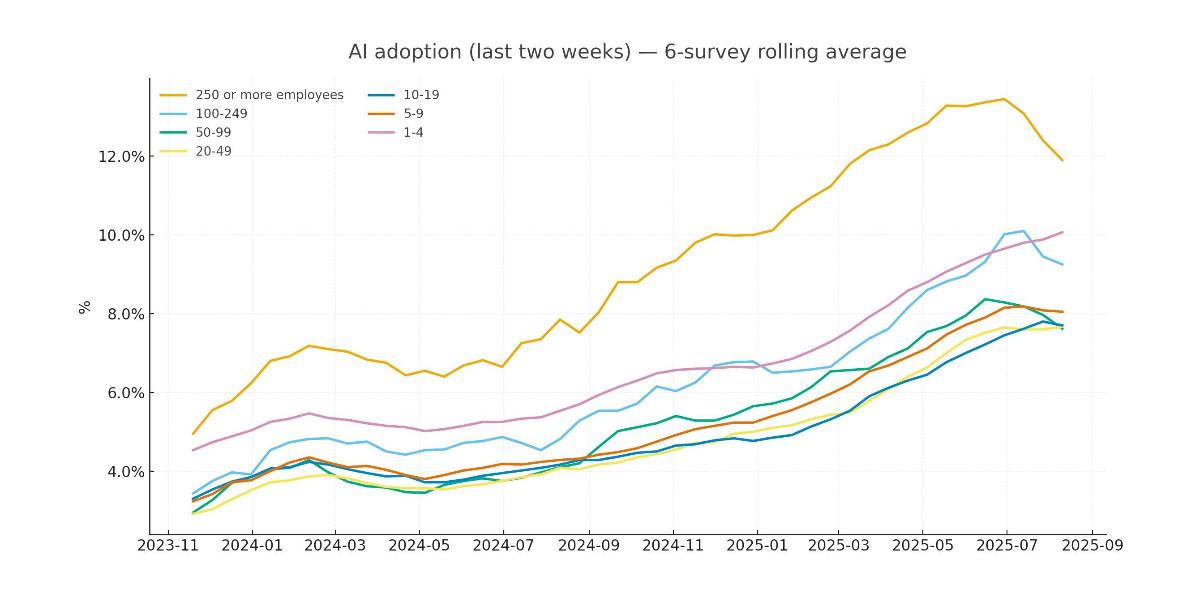
Apollo Global Management’s “Chief Economist” Dr. Torsten Sløk released this interesting chart which appears to show a slowdown in AI adoption rates among large (>250 employees) companies:
[... 2,673 words]Rich Pixels. Neat Python library by Darren Burns adding pixel image support to the Rich terminal library, using tricks to render an image using full or half-height colored blocks.
Here's the key trick - it renders Unicode ▄ (U+2584, "lower half block") characters after setting a foreground and background color for the two pixels it needs to display.
I got GPT-5 to vibe code up a show_image.py terminal command which resizes the provided image to fit the width and height of the current terminal and displays it using Rich Pixels. That script is here, you can run it with uv like this:
uv run https://tools.simonwillison.net/python/show_image.py \
image.jpg
Here's what I got when I ran it against my V&A East Storehouse photo from this post:
![]()
Talk Python: Celebrating Django’s 20th Birthday With Its Creators. I recorded this podcast episode recently to celebrate Django's 20th birthday with Adrian Holovaty, Will Vincent, Jeff Triplet, and Thibaud Colas.
We didn’t know that it was a web framework. We thought it was a tool for building local newspaper websites. [...]
Django’s original tagline was ‘Web development on journalism deadlines’. That’s always been my favorite description of the project.
Python: The Documentary. New documentary about the origins of the Python programming language - 84 minutes long, built around extensive interviews with Guido van Rossum and others who were there at the start and during the subsequent journey.
Static Sites with Python, uv, Caddy, and Docker (via) Nik Kantar documents his Docker-based setup for building and deploying mostly static web sites in line-by-line detail.
I found this really useful. The Dockerfile itself without comments is just 8 lines long:
FROM ghcr.io/astral-sh/uv:debian AS build
WORKDIR /src
COPY . .
RUN uv python install 3.13
RUN uv run --no-dev sus
FROM caddy:alpine
COPY Caddyfile /etc/caddy/Caddyfile
COPY --from=build /src/output /srv/
He also includes a Caddyfile that shows how to proxy a subset of requests to the Plausible analytics service.
The static site is built using his sus package for creating static URL redirecting sites, but would work equally well for another static site generator you can install and run with uv run.
Nik deploys his sites using Coolify, a new-to-me take on the self-hosting alternative to Heroku/Vercel pattern which helps run multiple sites on a collection of hosts using Docker containers.
A bunch of the Hacker News comments dismissed this as over-engineering. I don't think that criticism is justified - given Nik's existing deployment environment I think this is a lightweight way to deploy static sites in a way that's consistent with how everything else he runs works already.
More importantly, the world needs more articles like this that break down configuration files and explain what every single line of them does.
Qwen-Image-Edit: Image Editing with Higher Quality and Efficiency.
As promised in their August 4th release of the Qwen image generation model, Qwen have now followed it up with a separate model, Qwen-Image-Edit, which can take an image and a prompt and return an edited version of that image.
Ivan Fioravanti upgraded his macOS qwen-image-mps tool (previously) to run the new model via a new edit command. Since it's now on PyPI you can run it directly using uvx like this:
uvx qwen-image-mps edit -i pelicans.jpg \
-p 'Give the pelicans rainbow colored plumage' -s 10
Be warned... it downloads a 54GB model file (to ~/.cache/huggingface/hub/models--Qwen--Qwen-Image-Edit) and appears to use all 64GB of my system memory - if you have less than 64GB it likely won't work, and I had to quit almost everything else on my system to give it space to run. A larger machine is almost required to use this.
I fed it this image:

The following prompt:
Give the pelicans rainbow colored plumage
And told it to use just 10 inference steps - the default is 50, but I didn't want to wait that long.
It still took nearly 25 minutes (on a 64GB M2 MacBook Pro) to produce this result:

To get a feel for how much dropping the inference steps affected things I tried the same prompt with the new "Image Edit" mode of Qwen's chat.qwen.ai, which I believe uses the same model. It gave me a result much faster that looked like this:

Update: I left the command running overnight without the -s 10 option - so it would use all 50 steps - and my laptop took 2 hours and 59 minutes to generate this image, which is much more photo-realistic and similar to the one produced by Qwen's hosted model:

Marko Simic reported that:
50 steps took 49min on my MBP M4 Max 128GB
PyPI: Preventing Domain Resurrection Attacks (via) Domain resurrection attacks are a nasty vulnerability in systems that use email verification to allow people to recover their accounts. If somebody lets their domain name expire an attacker might snap it up and use it to gain access to their accounts - which can turn into a package supply chain attack if they had an account on something like the Python Package Index.
PyPI now protects against these by treating an email address as not-validated if the associated domain expires.
Since early June 2025, PyPI has unverified over 1,800 email addresses when their associated domains entered expiration phases. This isn't a perfect solution, but it closes off a significant attack vector where the majority of interactions would appear completely legitimate.
This attack is not theoretical: it happened to the ctx package on PyPI back in May 2022.
Here's the pull request from April in which Mike Fiedler landed an integration which hits an API provided by Fastly's Domainr, followed by this PR which polls for domain status on any email domain that hasn't been checked in the past 30 days.
TIL: Running a gpt-oss eval suite against LM Studio on a Mac. The other day I learned that OpenAI published a set of evals as part of their gpt-oss model release, described in their cookbook on Verifying gpt-oss implementations.
I decided to try and run that eval suite on my own MacBook Pro, against gpt-oss-20b running inside of LM Studio.
TLDR: once I had the model running inside LM Studio with a longer than default context limit, the following incantation ran an eval suite in around 3.5 hours:
mkdir /tmp/aime25_openai
OPENAI_API_KEY=x \
uv run --python 3.13 --with 'gpt-oss[eval]' \
python -m gpt_oss.evals \
--base-url https://localhost:1234/v1 \
--eval aime25 \
--sampler chat_completions \
--model openai/gpt-oss-20b \
--reasoning-effort low \
--n-threads 2
My new TIL breaks that command down in detail and walks through the underlying eval - AIME 2025, which asks 30 questions (8 times each) that are defined using the following format:
{"question": "Find the sum of all integer bases $b>9$ for which $17_{b}$ is a divisor of $97_{b}$.", "answer": "70"}
pyx: a Python-native package registry, now in Beta (via) Since its first release, the single biggest question around the uv Python environment management tool has been around Astral's business model: Astral are a VC-backed company and at some point they need to start making real revenue.
Back in September Astral founder Charlie Marsh said the following:
I don't want to charge people money to use our tools, and I don't want to create an incentive structure whereby our open source offerings are competing with any commercial offerings (which is what you see with a lost of hosted-open-source-SaaS business models).
What I want to do is build software that vertically integrates with our open source tools, and sell that software to companies that are already using Ruff, uv, etc. Alternatives to things that companies already pay for today.
An example of what this might look like (we may not do this, but it's helpful to have a concrete example of the strategy) would be something like an enterprise-focused private package registry. [...]
It looks like those plans have become concrete now! From today's announcement:
TL;DR: pyx is a Python-native package registry --- and the first piece of the Astral platform, our next-generation infrastructure for the Python ecosystem.
We think of pyx as an optimized backend for uv: it's a package registry, but it also solves problems that go beyond the scope of a traditional "package registry", making your Python experience faster, more secure, and even GPU-aware, both for private packages and public sources (like PyPI and the PyTorch index).
pyx is live with our early partners, including Ramp, Intercom, and fal [...]
This looks like a sensible direction to me, and one that stays true to Charlie's promises to carefully design the incentive structure to avoid corrupting the core open source project that the Python community is coming to depend on.
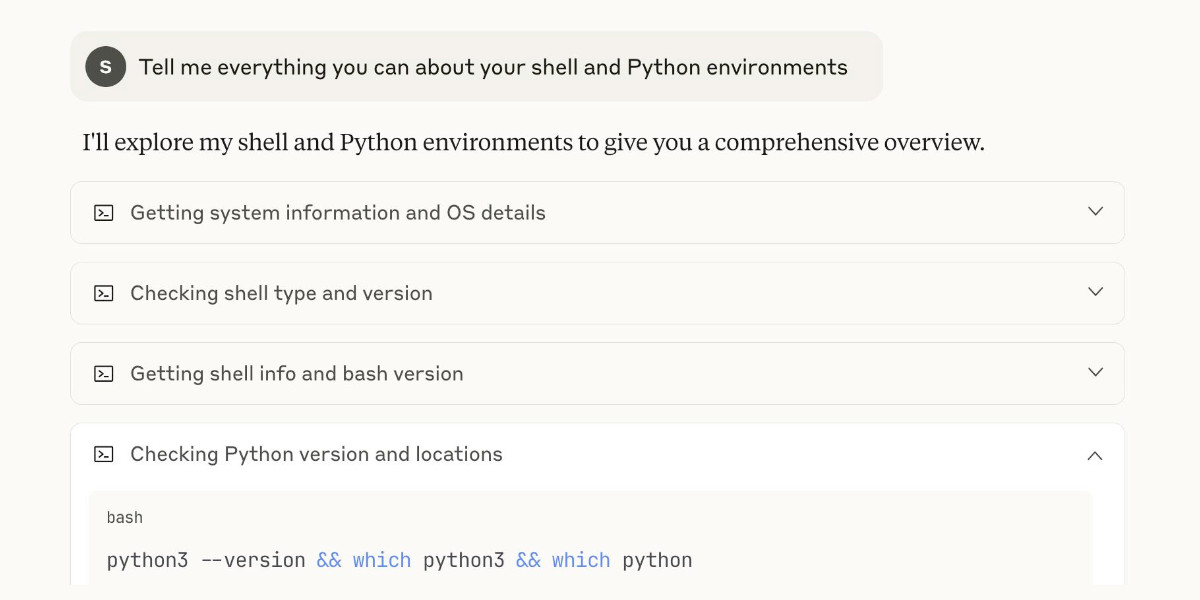
simonw/codespaces-llm. GitHub Codespaces provides full development environments in your browser, and is free to use with anyone with a GitHub account. Each environment has a full Linux container and a browser-based UI using VS Code.
I found out today that GitHub Codespaces come with a GITHUB_TOKEN environment variable... and that token works as an API key for accessing LLMs in the GitHub Models collection, which includes dozens of models from OpenAI, Microsoft, Mistral, xAI, DeepSeek, Meta and more.
Anthony Shaw's llm-github-models plugin for my LLM tool allows it to talk directly to GitHub Models. I filed a suggestion that it could pick up that GITHUB_TOKEN variable automatically and Anthony shipped v0.18.0 with that feature a few hours later.
... which means you can now run the following in any Python-enabled Codespaces container and get a working llm command:
pip install llm
llm install llm-github-models
llm models default github/gpt-4.1
llm "Fun facts about pelicans"
Setting the default model to github/gpt-4.1 means you get free (albeit rate-limited) access to that OpenAI model.
To save you from needing to even run that sequence of commands I've created a new GitHub repository, simonw/codespaces-llm, which pre-installs and runs those commands for you.
Anyone with a GitHub account can use this URL to launch a new Codespaces instance with a configured llm terminal command ready to use:
codespaces.new/simonw/codespaces-llm?quickstart=1
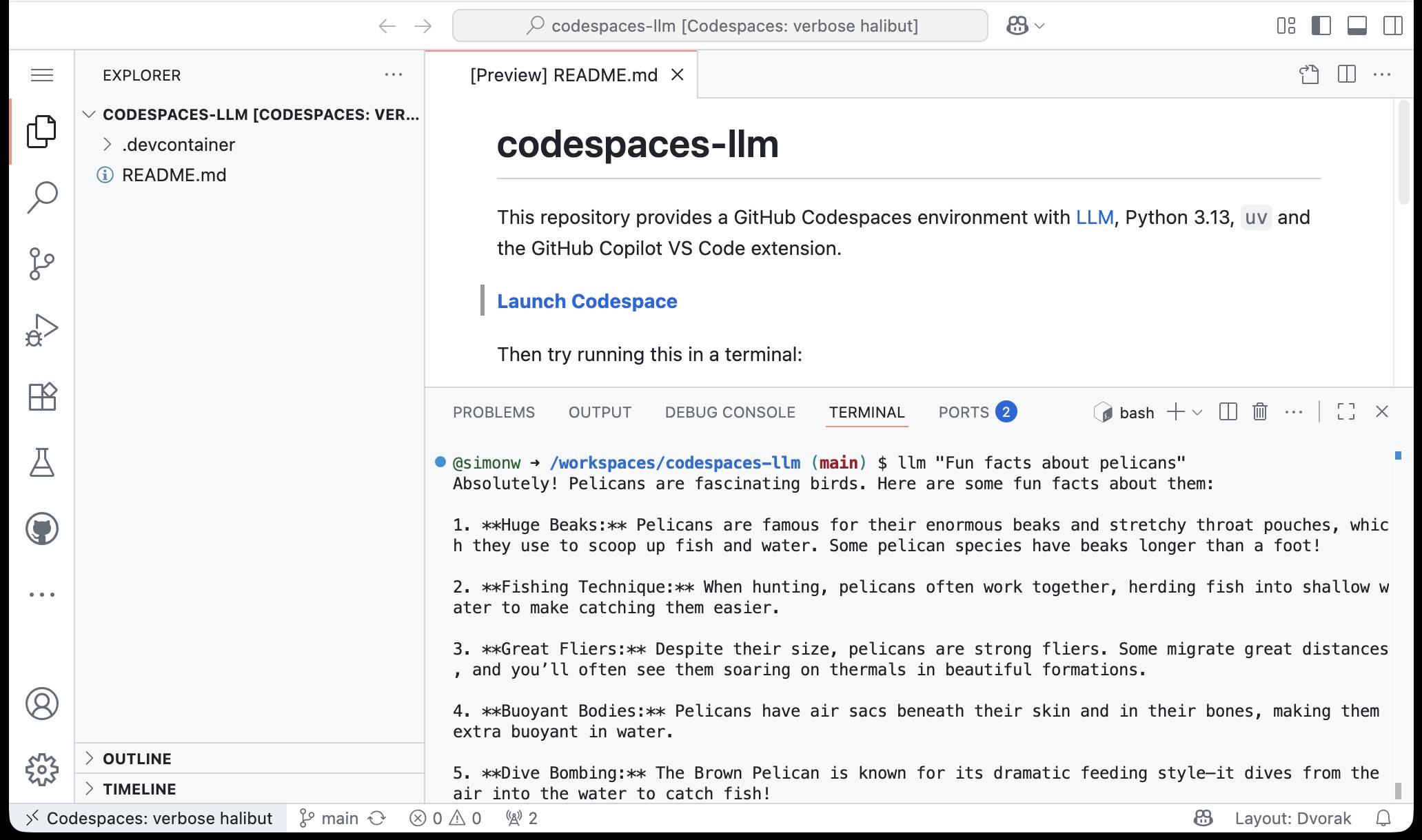
While putting this together I wrote up what I've learned about devcontainers so far as a TIL: Configuring GitHub Codespaces using devcontainers.
LLM 0.27, the annotated release notes: GPT-5 and improved tool calling
I shipped LLM 0.27 today (followed by a 0.27.1 with minor bug fixes), adding support for the new GPT-5 family of models from OpenAI plus a flurry of improvements to the tool calling features introduced in LLM 0.26. Here are the annotated release notes.
[... 1,174 words]qwen-image-mps (via) Ivan Fioravanti built this Python CLI script for running the Qwen/Qwen-Image image generation model on an Apple silicon Mac, optionally using the Qwen-Image-Lightning LoRA to dramatically speed up generation.
Ivan has tested it this on 512GB and 128GB machines and it ran really fast - 42 seconds on his M3 Ultra. I've run it on my 64GB M2 MacBook Pro - after quitting almost everything else - and it just about manages to output images after pegging my GPU (fans whirring, keyboard heating up) and occupying 60GB of my available RAM. With the LoRA option running the script to generate an image took 9m7s on my machine.
Ivan merged my PR adding inline script dependencies for uv which means you can now run it like this:
uv run https://raw.githubusercontent.com/ivanfioravanti/qwen-image-mps/refs/heads/main/qwen-image-mps.py \
-p 'A vintage coffee shop full of raccoons, in a neon cyberpunk city' -f
The first time I ran this it downloaded the 57.7GB model from Hugging Face and stored it in my ~/.cache/huggingface/hub/models--Qwen--Qwen-Image directory. The -f option fetched an extra 1.7GB Qwen-Image-Lightning-8steps-V1.0.safetensors file to my working directory that sped up the generation.
Here's the resulting image:

Hypothesis is now thread-safe (via) Hypothesis is a property-based testing library for Python. It lets you write tests like this one:
from hypothesis import given, strategies as st @given(st.lists(st.integers())) def test_matches_builtin(ls): assert sorted(ls) == my_sort(ls)
This will automatically create a collection of test fixtures that exercise a large array of expected list and integer shapes. Here's a Gist demonstrating the tests the above code will run, which include things like:
[]
[0]
[-62, 13194]
[44, -19562, 44, -12803, -24012]
[-7531692443171623764, -109369043848442345045856489093298649615]
Hypothesis contributor Liam DeVoe was recently sponsored by Quansight to add thread safety to Hypothesis, which has become important recently due to Python free threading:
While we of course would always have loved for Hypothesis to be thread-safe, thread-safety has historically not been a priority, because running Hypothesis tests under multiple threads is not something we see often.
That changed recently. Python---as both a language, and a community---is gearing up to remove the global interpreter lock (GIL), in a build called free threading. Python packages, especially those that interact with the C API, will need to test that their code still works under the free threaded build. A great way to do this is to run each test in the suite in two or more threads simultaneously. [...]
Nathan mentioned that because Hypothesis is not thread-safe, Hypothesis tests in community packages have to be skipped when testing free threaded compatibility, which removes a substantial battery of coverage.
Now that Hypothesis is thread-safe another blocker to increased Python ecosystem support for free threading has been removed!
From Async/Await to Virtual Threads. Armin Ronacher has long been critical of async/await in Python, both for necessitating colored functions and because of the more subtle challenges they introduce like managing back pressure.
Armin argued convincingly for the threaded programming model back in December. Now he's expanded upon that with a description of how virtual threads might make sense in Python.
Virtual threads behave like real system threads but can vastly outnumber them, since they can be paused and scheduled to run on a real thread when needed. Go uses this trick to implement goroutines which can then support millions of virtual threads on a single system.
Python core developer Mark Shannon started a conversation about the potential for seeing virtual threads to Python back in May.
Assuming this proposal turns into something concrete I don't expect we will see it in a production Python release for a few more years. In the meantime there are some exciting improvements to the Python concurrency story - most notably around sub-interpreters - coming up this year in Python 3.14.
My 2.5 year old laptop can write Space Invaders in JavaScript now, using GLM-4.5 Air and MLX
I wrote about the new GLM-4.5 model family yesterday—new open weight (MIT licensed) models from Z.ai in China which their benchmarks claim score highly in coding even against models such as Claude Sonnet 4.
[... 685 words]TIL: Exception.add_note
(via)
Neat tip from Danny Roy Greenfeld: Python 3.11 added a .add_note(message: str) method to the BaseException class, which means you can add one or more extra notes to any Python exception and they'll be displayed in the stacktrace!
Here's PEP 678 – Enriching Exceptions with Notes by Zac Hatfield-Dodds proposing the new feature back in 2021.
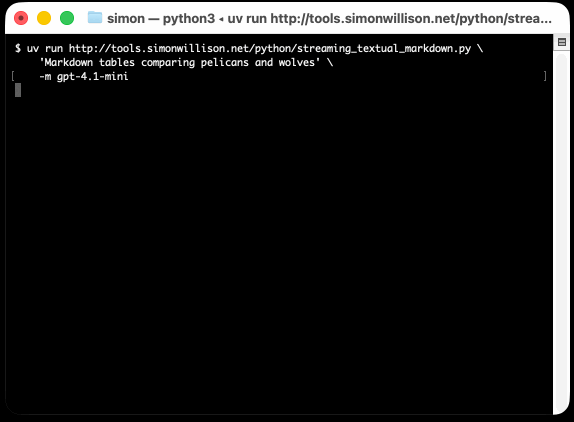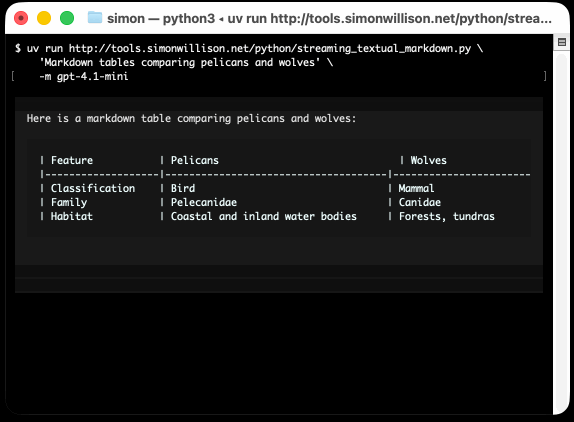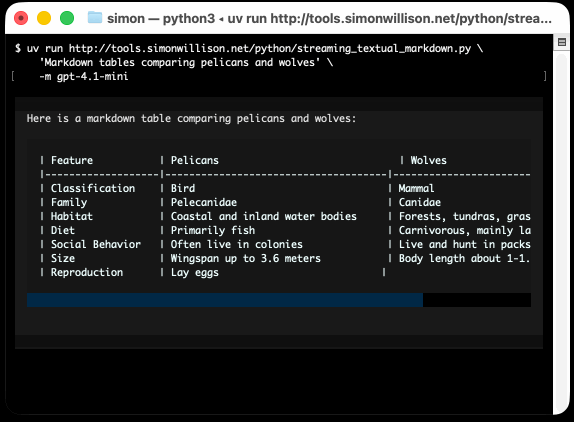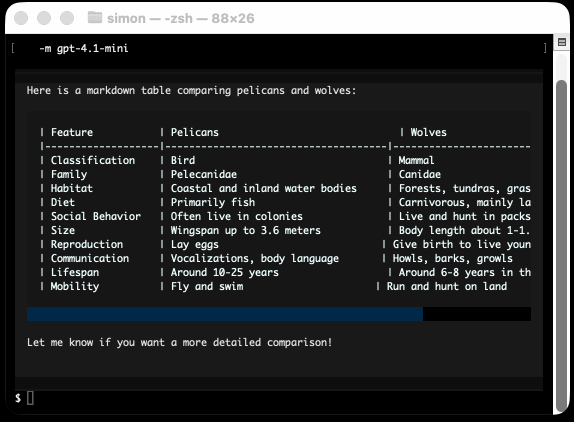
Textual v4.0.0: The Streaming Release. Will McGugan may no longer be running a commercial company around Textual, but that hasn't stopped his progress on the open source project.
He recently released v4 of his Python framework for building TUI command-line apps, and the signature feature is streaming Markdown support - super relevant in our current age of LLMs, most of which default to outputting a stream of Markdown via their APIs.
I took an example from one of his tests, spliced in my async LLM Python library and got some help from o3 to turn it into a streaming script for talking to models, which can be run like this:
uv run https://tools.simonwillison.net/python/streaming_textual_markdown.py \
'Markdown headers and tables comparing pelicans and wolves' \
-m gpt-4.1-mini
Every day someone becomes a programmer because they figured out how to make ChatGPT build something. Lucky for us: in many of those cases the AI picks Python. We should treat this as an opportunity and anticipate an expansion in the kinds of people who might want to attend a Python conference. Yet many of these new programmers are not even aware that programming communities and conferences exist. It’s in the Python community’s interest to find ways to pull them in.