Key takeaways:
- PyTorch and vLLM have been organically integrated to accelerate cutting-edge generative AI applications, such as inference, post-training and agentic systems.
- Prefill/Decode Disaggregation is a crucial technique for enhancing generative AI inference efficiency in terms of both latency and throughput at scale.
- Prefill/Decode Disaggregation has been enabled in Meta internal inference stack, serving large scale Meta traffic. Through the collaboration effort between Meta and vLLM teams, the Meta vLLM disagg implementation has demonstrated improved performance compared to the Meta internal LLM inference stack.
- Meta optimizations and reliability enhancements are being upstreamed to the vLLM community.
In our previous post, PyTorch + vLLM, we shared the exciting news that vLLM joins PyTorch Foundation and highlighted several integration achievements between PyTorch and vLLM, along with planned initiatives. One key initiative is the large-scale prefill-decode (P/D) disaggregation for inference, aimed at boosting throughput within latency budgets for Meta’s LLM products. Over the past two months, Meta engineers have dedicated significant effort to implementing an internal P/D disagg integration with vLLM, resulting in improved performance compared to Meta’s existing internal LLM inference stack in both TTFT (Time to First Token) and TTIT (Time to Iterative Token) metrics. vLLM has native integration with llm-d and dynamo. Within Meta, we have developed abstractions that accelerate KV transfer to our serving cluster topologies and setup. This post will focus on Meta’s customization to vLLM and integration with upstream vLLM.
Disaggregated Prefill/Decode
In LLM inference, the first token relies on the input prompt tokens provided by users, and all the following tokens are generated one token at a time in an autoregressive manner. We call the first token generation as “prefill”, and the remaining token generation as “decode”.
While running essentially the same set of operations, prefill and decode exhibit quite different characteristics. Some notable characteristics are:
- Prefill
- Compute bound
- Token length and batch size bound latency
- Happens once per request
- Decode
- Memory bound
- Batch size bound efficiency
- Dominant in overall latency
Prefill/Decode disagg is proposed to decouple prefill and decode into separate hosts, where the decode hosts redirect the requests to prefill hosts for the first token generation and handle remaining by itself. We intend to scale prefill and decode inference independently, leading to more efficient resource utilization and improvements in both latency and throughput.

vLLM Integration Overview
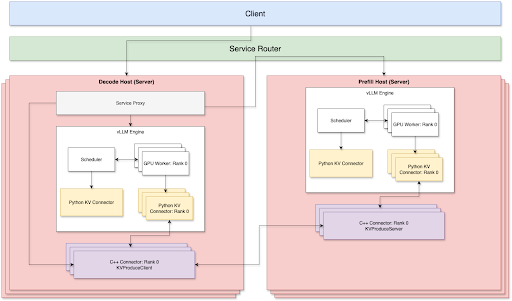
Currently, TP + Disagg is being supported on both prefill and decode sides. There are 3 key components to facilitate optimal P/D disagg serving over TCP network:
- Proxy library
- Python kv connector
- C++ decode kv connector and prefill kv connector, connected via TCP
We handle the routing through a router layer, which takes care of load balancing and connects a prefill node and a decode note through P2P style to reduce network overhead. The prefill node and the decode node could be independently scaled up or down depending on its own workload. Therefore, we don’t need to manually maintain the prefil:decode ratio when running in production.
Components
Service Proxy
The service proxy is attached to the decode server. It forwards requests to a remote prefill host and orchestrates KV cache transfers between the decode and prefill KV connectors. We use Meta’s internal service router solution to do load balancing across all prefill hosts based on server workload and caching hit rate.
- The service proxy would first forward an incoming request to a selected prefill host, and at the same time, establish multiple streaming channels to fetch KV cache from the same prefill host through the underlying Meta C++ connectors.
- The fetched remote KV cache would first be copied to a temporary GPU buffer, waiting for vLLM KV connectors to inject them into the proper KV blocks later.
vLLM Python KV Connector
We have implemented an async KV connector solution based on vLLM v1 KV connector interface. The KV connector would conduct KV cache transfer operations in parallel with the main stream model execution, and ensure there is no contention for their GPU ops from both sides. By doing so, we achieved faster TTIT/TTFT; optimization details can be found in the section below.
- On prefill side:
- The python KV connector would save KV cache to a temporary CPU buffer for a given request after attention calculation is done on each layer, and such saving ops would be conducted through the underlying Meta C++ based connector. By doing so, we ensure the mainstream model execution wouldn’t be blocked at all.
- When KV cache saving is completed, it would be streamed to the remote decode host right away.
- On decode side:
- After the remote KV cache is fetched and copied to a temporary GPU buffer, the python KV connector would start injecting the remote KV cache into the local KV cache blocks assigned by vLLM. This is also conducted through the underlying Meta C++ based connector in its separate C++ threads and CUDA streams.
- When KV injection is done, the python KV connector would release the request back to the vLLM scheduler and such request would be scheduled to run in the next iteration.
- Error handling
- We also implemented a general garbage collector to clean up the idle KV cache buffer fetched from remote to avoid CUDA OOM issue. This covers edge cases like:
- Preempted requests, cancelled/aborted requests, for which remote fetching could be done but local injection is aborted.
- We also implemented a general garbage collector to clean up the idle KV cache buffer fetched from remote to avoid CUDA OOM issue. This covers edge cases like:
Meta C++ Connector
As the KV transfer operations have heavy IO, we choose to implement them in C++ so we can better parallelize data transfer and fine-tune the threading model. All the actual KV transfer operations like over network streaming, local H2D/D2H, KV injection/extraction are all done in their own C++ threads with separate CUDA streams.
Prefill C++ Connector
After model attention calculation is done after each layer, the KV cache is offloaded to the c++ connector on DRAM. It then streams the kv cache back to the decode host for specific requests and layers.
Decode C++ Connector
Receiving a request and its routed prefill host addresses from the proxy layer, it establishes multiple streaming channels to fetch remote KV caches. It buffers the fetched KV cache on DRAM and asynchronously injects it into preallocated GPU KV cache blocks.
Optimizations
Accelerating Network Transmission
- Multi-NIC Support: Multiple frontend Network Interface Cards (NICs) are linked to the closest GPUs, optimizing the connection between decode and prefill KVConnectors.
- Multi-streaming KV Cache Transfer: Single TCP stream is not able to saturate network bandwidth. To maximize network throughput, KV cache is sliced and transferred in parallel using multiple streams.
Optimizing Serving Performance
- Sticky Routing: In prefill forwarding, requests from the same session are consistently directed to the same prefill host. This significantly boosts the prefix cache hit rate for multi-turn use cases.
- Load Balancing: We leverage Meta’s internal service router to effectively distribute workload across various prefill hosts based on each host’s utilization rate. This, combined with sticky routing, enables a 40%-50% prefix cache hit rate while maintaining HBM utilization at 90%.
Fine-tuning vLLM
- Larger Block Size: While vLLM suggests 16 tokens per KV cache block, we found that transferring these smaller blocks between CPU and GPU creates substantial overhead due to numerous small kernel launches during KV Cache injection and extraction. Consequently, we adopted much larger block sizes (e.g., 128, 256) for improved disaggregation performance, along with necessary kernel-side adjustments.
- Disabled Decode Prefix Cache: The decode host loads KV cache from the KV connector, making prefix hash computation an unnecessary overhead for the scheduler. Disabling it on the decode side helped stabilize TTIT (Time To Inter-token).
Improving TTFT (Time To First Token)
- Early First Token Return: The proxy layer receives the response from the prefill tier and immediately returns the first token to the client. Simultaneously, the engine decodes the second token. We also reuse the tokenized prompt from prefill, eliminating an additional tokenization step on the decode side. This ensures that the TTFT for the P/D disaggregation solution is as close as possible to the TTFT from the prefill host.
Enhancing TTIT (Time To Inter-token)
- Exclusive Use of Primitive Types: We observed that Python’s native pickle dump could take three times longer to serialize a tensor than a list of integers when transferring data between the vLLM scheduler and workers. This often caused random scheduler process hangs, negatively impacting TTIT. It’s best practice to avoid creating tensor or complex objects in KVConnectorMetadata and SchedulerOutput.
- Asynchronous KV Loading: We parallelize KV load operations with the vLLM model decode step. This prevents requests awaiting remote KV from blocking requests that are already generating new output tokens.
- Maximizing GPU Operation Overlap: Since KV transfer operations are primarily copy/IO operations and mainstream model forward execution is compute-intensive, we managed to fully overlap KV transfer operations in their own CUDA stream with the main stream model forward execution. This results in no additional latency overhead caused by KV transfer.
- Avoiding CPU Scheduling Contention: Instead of scheduling KV injections (essentially index copy operations) across all layers simultaneously, which can cause kernel scheduling contention during the model forward pass, we schedule per-layer KV injections in sequence, in sync with the model forward pass.
- Non-blocking Copy Operations: All copy (Host to Device/Device to Host) operations are run in a non-blocking manner. We also resolved an issue where the main model forward pass running in the default CUDA stream unintentionally blocked other copy operations from non-blocking CUDA streams.
Performance Results
We benchmarked with Llama4 Maverick on H100 hosts (8xH100 card per host) connected by TCP network. The evaluation used an input length of 2000, an output length of 150.
Under the same batch size, we identified disagg (1P1D) could provide higher throughput

Under the same QPS workload, we identified disagg (1P1D) to provide better control for the overall latency due to the much smoother TTIT curve.


However, we also notice that TTFT would regress in a sharper curve when loadword becomes very large, and there could be due to multiple reasons (as we also mentioned in the next section of what’s more to explore):
- The network becomes a bottleneck through TCP connection.
- 1P1D setup puts more workload pressure on the prefill side as our evaluation is done on more prefill heavy work (2000 inputs vs 150 outputs). Ideally, a higher prefill to decode ratio is desired.

What’s more to explore
- Cache-miss only kv-transfer
- We also prototyped cache-miss only KV-transfer mechanism where we only fetch from remote for the KV cache that is missing on the decode side. For example, if a request has a 40% prefix cache hit, we would only fetch the rest of 60% KV cache from the prefill side. Based on the early observation, it produces a smoother TTFT/TTIT curve when QPS is high.
- Overlap compute-communication for prefill
- For prefill, we also explored the solution where KV cache saving is done in its own CUDA stream, which makes it run in parallel with model forward pass. We plan to further explore this direction and tune the related serving settings to push for better TTFT limits.
- Disagg + DP/EP
- To support Meta’s large-scale vLLM serving, we are implementing the integration of P/D disagg and large scale DP/EP, which aims to achieve the overall optimal throughput and latency by different degrees of load balancing and networking primitive optimizations.
- RDMA communication support
- Currently, we rely on Thrift for data transfer over TCP, which involves a lot of extra tensor movements and network stack overhead. By leveraging advanced communication connectivity such as NVLink and RDMA, we see the opportunity to further improve TTFT and TTIT performance.
- Hardware specific optimization
- Currently, we are productionizing our solution towards the H100 hardware environment, and we have plans to expand hardware specific optimization towards other hardware environments where GB200 is available.
And of course, we will continue to upstream all of this such that the community can take advantage of all of these capabilities in the core vLLM project alongside PyTorch. Please reach out if you would like to collaborate in any way..
Cheers!
Team PyTorch @Meta & vLLM teams