You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
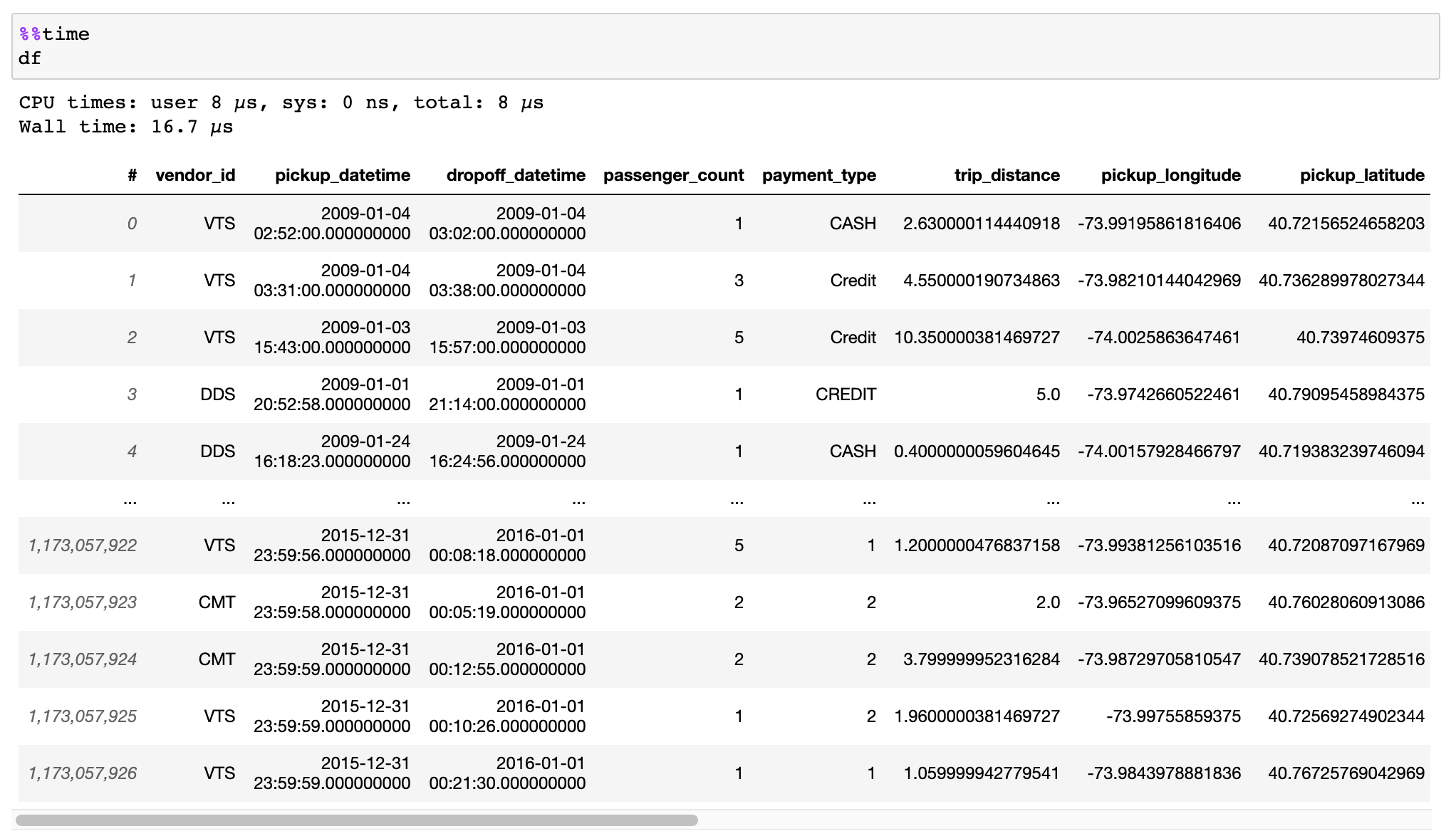
Vaex is a high performance Python library for lazy Out-of-Core DataFrames
(similar to Pandas), to visualize and explore big tabular datasets. It
calculates statistics such as mean, sum, count, standard deviation etc, on an
N-dimensional grid for more than a billion (10^9) samples/rows per
second. Visualization is done using histograms, density plots and 3d
volume rendering, allowing interactive exploration of big data. Vaex uses
memory mapping, zero memory copy policy and lazy computations for best
performance (no memory wasted).
Lazy streaming from S3 supported in combination with memory mapping.
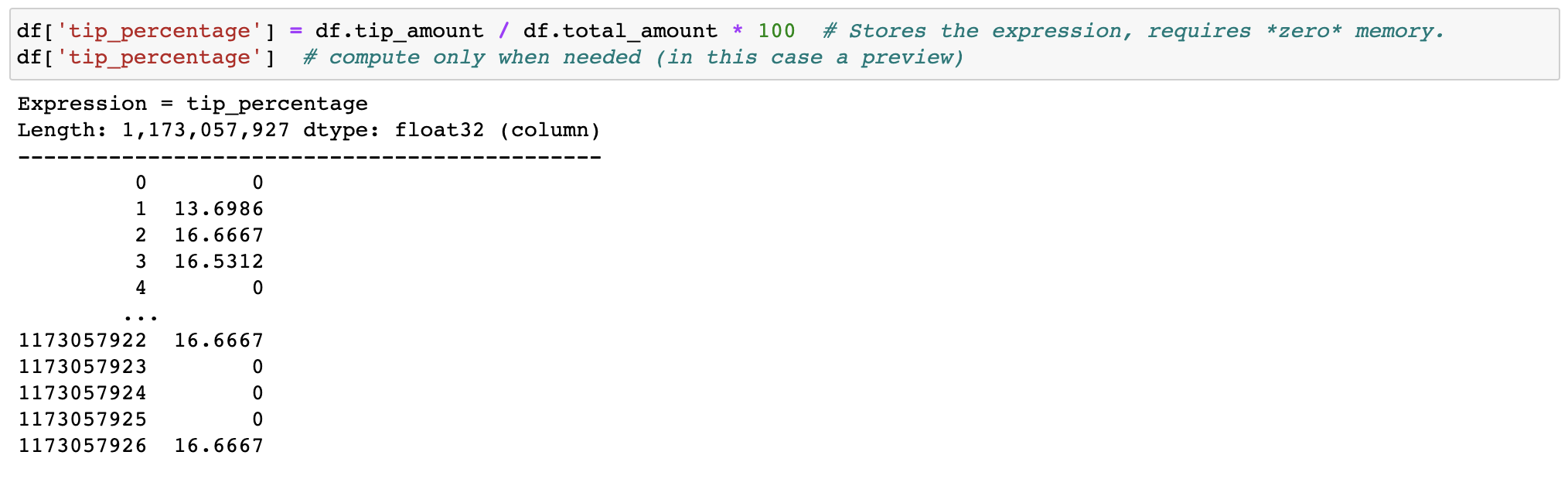
Expression system
Don't waste memory or time with feature engineering, we (lazily) transform your data when needed.
Out-of-core DataFrame
Filtering and evaluating expressions will not waste memory by making copies; the data is kept untouched on disk, and will be streamed only when needed. Delay the time before you need a cluster.
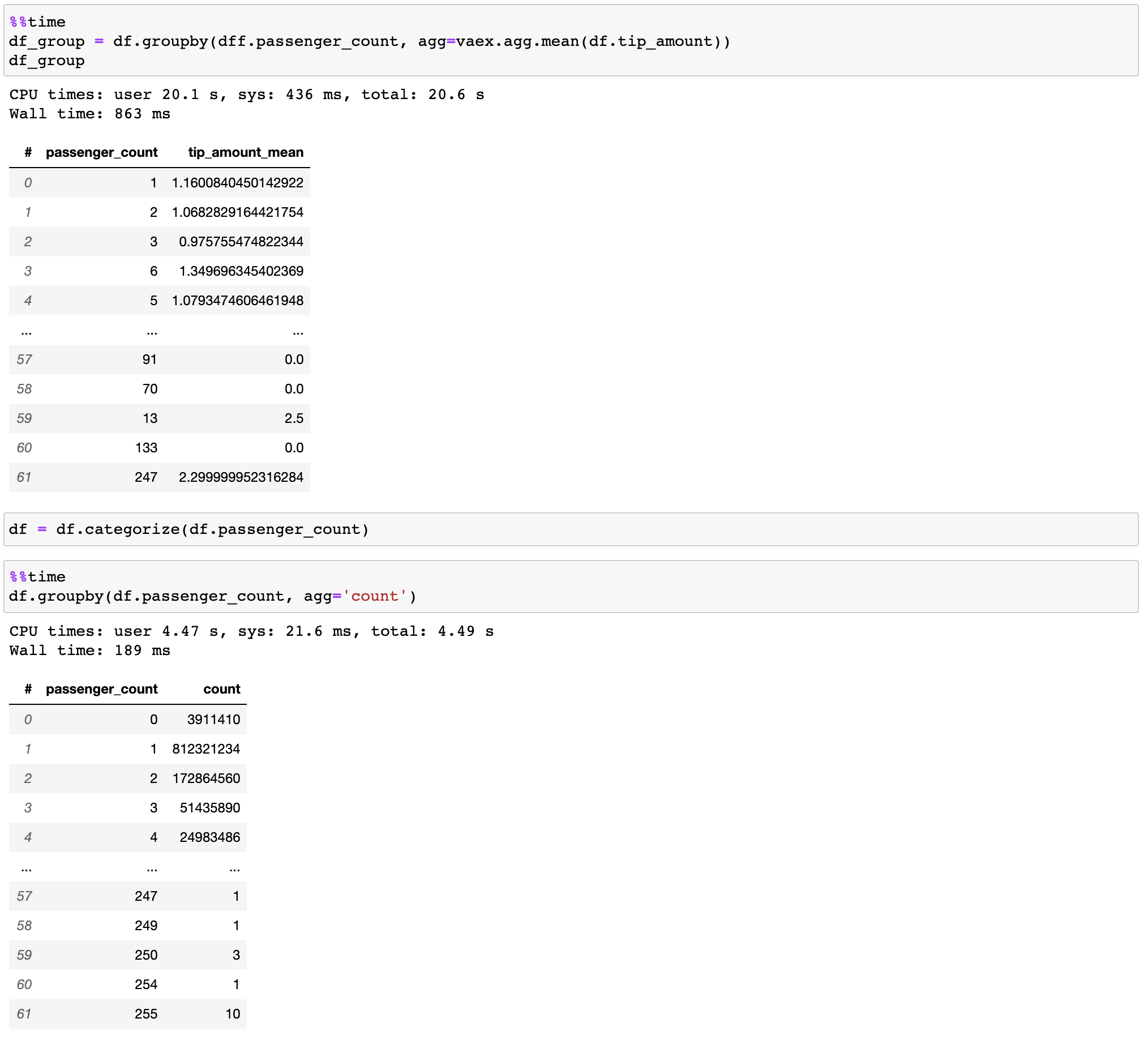
Fast groupby / aggregations
Vaex implements parallelized, highly performant groupby operations, especially when using categories (>1 billion/second).
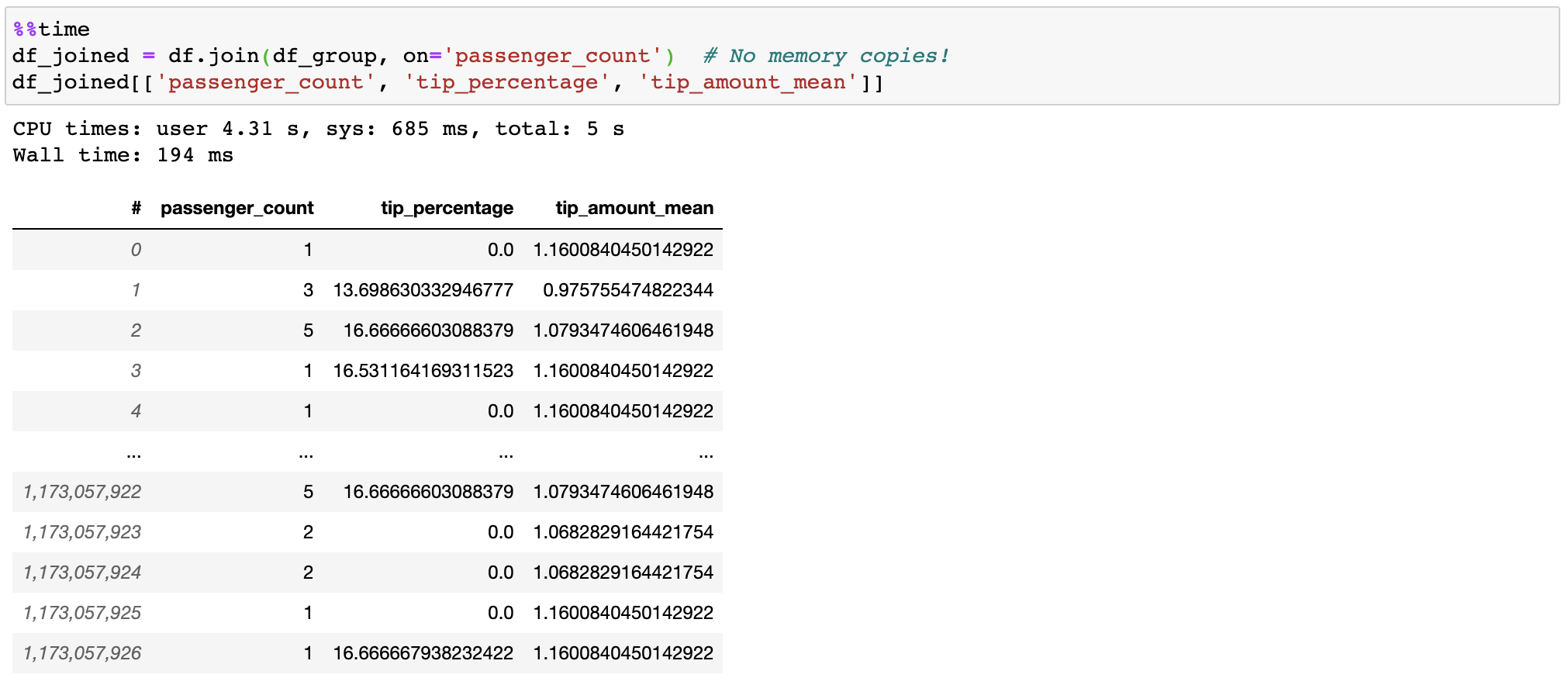
Fast and efficient join
Vaex doesn't copy/materialize the 'right' table when joining, saving gigabytes of memory. With subsecond joining on a billion rows, it's pretty fast!