You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This PR proposes a new implementation for Gradient Boosting Decision Trees. This isn't meant to be a replacement of the current sklearn implementation but rather an addition.
This addresses the second bullet point from #8231.
This is a port from pygbm (with @ogrisel, in Numba), which itself uses lots of the optimizations from LightGBM.
Algorithm details and refs
The proposed algorithm roughly corresponds to the 'approximate' variant of the XGBoost paper, except that the data is binned at the very beginning of the training process, instead of at each node of the trees.
See also Algorithm 1 of the LightGBM paper. Section 2.1 is worth a read.
The main differences with the current sklearn implementation are:
Before training, the data is binned into equally-spaced bins (up to 256 bins), which considerably reduces the number of split points to consider. The other advantage is that the data becomes integer-valued, which is faster to handle than real-valued data.
Newton method is used instead of gradient descent
Notes to reviewers
This is going to be a lot of work to review, so please feel free to tell me if there's anything I can do / add that could ease reviewing.
Here's a list of things that probably need to be discussed at some point or that are worth pointing out.
The code is a port of pygbm (from numba to cython). I've ported all the tests as well. So a huge part of the code has already been carefully reviewed (or written) by @ogrisel. There are still a few non-trivial changes to the pygbm's code, to accommodate for the numba -> cython translation.
The code is in sklearn/ensemble._hist_gradient_boosting and the estimators are exposed in sklearn.experimental (which is created here, as a result of a discussion during the Paris sprint).
Y_DTYPE and the associated C type for targets y is double and not float, because with float the numerical checks (test_loss.py) would not pass. Maybe at some point we'll want to also allow floats since using doubles uses twice as much space (which is not negligible, see the attributes of the Splitter class). Like in LightGBM, the targets y, gains, values, and sums of gradient / hessians are doubles, and the gradients and hessians array are floats to save space (14c7d47).
I have only added a short note in the User Guide about the new estimators. I think that the gradient boosting section of the user guide could benefit from an in-depth rewriting. I'd be happy to do that, but in a later PR.
Currently the parallel code uses all possible threads. Do we want to expose n_jobs (openmp-wise, not joblib of course)?
The estimator names are currently HistGradientBoostingClassifier and HistGradientBoostingRegressor.
API differences with current implementation:
Happy to discuss these points of course. In general I tried to match the parameters names with those of the current GBDTs.
New features:
early stopping can be checked with an arbitrary scorer, not just with the loss
validation_fraction can also be an int to specify absolute size of the validation set (not just a proportion)
Changed parameters and attributes:
the losses parameters have different names. I personally think that 'deviance' is just obfuscating for logistic loss.
the n_estimators parameter has been changed to max_iter because unlike the current GBDTs implementations, the underlying "predictor" aren't estimators. They are private and have no fit method. Also, in multiclass classification we build C * max_iter
the estimators_ attribute has been removed for the same reason.
train_score_ is of size n_estimators + 1 instead of n_estimators because it contains the score of the 0th iteration (before the boosting process).
oob_improvement_ is replaced by validation_score_, also with size n_estimators + 1
Unsupported parameters and attributes:
subsample (doesn't really make sense here)
criterion (same)
min_samples_split is not supported, but min_samples_leaf is supported.
anything samples_weights-related
min_impurity_decrease is not supported (we have min_gain_to_split but it is not exposed in the public API)
warm_start
max_features (probably not needed)
staged_decision_function, staged_predict_proba, etc.
init estimator
feature_importances_
the loss_ attribute is not exposed.
Only least squares loss is supported for regression. No least absolute error, huber or quantile loss.
Future improvement, for later PRs (no specific order):
Implement categorical variables support (what to do if there are more than 256 categories?)
Allow for more than 256 bins (requires to "dynamically" encode bins as uint8 or uint32)
Implement handling of missing values
Implement fast PDPs
BinMapper is doing almost the same job as KBinDiscretizer (but it's parallelized) so we could eventually integrate it.
Parallelize loss computations (should speed up early stopping when scoring=='loss')
Find a way to avoid computing predictions of all the trees when checking early stopping with a scorer. At the same time, this could avoid the _in_fit hackish attribute.
Benchmarks
Done on my laptop, intel i5 7th Gen, 4 cores, 8GB Ram.
TLDR:
considerably faster than the current sklearn implem
faster than XGBoost ('hist' method)
faster than CatBoost (not shown here because catboost is much slower than the others and would flatten the plots)
very close to lightgbm. In terms of prediction accuracy results are comparable.
Comparison between proposed PR and current estimators:
on binary classification only, I don't think it's really needed to do more since the performance difference is striking. Note that for larger sample sizes the current estimators simply cannot run because of the sorting step that never terminates. I don't provide the benchmark code, it's exactly the same as that of benchmarks/bench_fast_gradient_boosting.py:
Comparison between proposed PR and LightGBM / XGBoost:
On the Higgs-Boson dataset: python benchmarks/bench_hist_gradient_boosting_higgsboson.py --lightgbm --xgboost --subsample 5000000 --n-trees 50
Sklearn: done in 28.787s, ROC AUC: 0.7330, ACC: 0.7346
LightGBM: done in 27.595s, ROC AUC: 0.7333, ACC: 0.7349
XGBoost: done in 41.726s, ROC AUC: 0.7335, ACC: 0.7351
Entire log:
~/dev/sklearn(branch:gbm*) » python benchmarks/bench_hist_gradient_boosting_higgsboson.py --subsample 5000000 --n-trees 50 --lightgbm --xgboost nico@cotier
Training set with 5000000 records with 28 features.
Fitting a sklearn model...
Binning 1.120 GB of data: 3.665 s
Fitting gradient boosted rounds:
[1/50] 1 tree, 31 leaves, max depth = 7, in 0.595s
[2/50] 1 tree, 31 leaves, max depth = 9, in 0.602s
[3/50] 1 tree, 31 leaves, max depth = 9, in 0.575s
[4/50] 1 tree, 31 leaves, max depth = 12, in 0.552s
[5/50] 1 tree, 31 leaves, max depth = 11, in 0.583s
[6/50] 1 tree, 31 leaves, max depth = 9, in 0.578s
[7/50] 1 tree, 31 leaves, max depth = 11, in 0.561s
[8/50] 1 tree, 31 leaves, max depth = 10, in 0.524s
[9/50] 1 tree, 31 leaves, max depth = 9, in 0.566s
[10/50] 1 tree, 31 leaves, max depth = 10, in 0.552s
[11/50] 1 tree, 31 leaves, max depth = 14, in 0.523s
[12/50] 1 tree, 31 leaves, max depth = 15, in 0.538s
[13/50] 1 tree, 31 leaves, max depth = 11, in 0.501s
[14/50] 1 tree, 31 leaves, max depth = 12, in 0.522s
[15/50] 1 tree, 31 leaves, max depth = 10, in 0.546s
[16/50] 1 tree, 31 leaves, max depth = 9, in 0.409s
[17/50] 1 tree, 31 leaves, max depth = 13, in 0.457s
[18/50] 1 tree, 31 leaves, max depth = 10, in 0.520s
[19/50] 1 tree, 31 leaves, max depth = 13, in 0.463s
[20/50] 1 tree, 31 leaves, max depth = 10, in 0.399s
[21/50] 1 tree, 31 leaves, max depth = 11, in 0.463s
[22/50] 1 tree, 31 leaves, max depth = 9, in 0.356s
[23/50] 1 tree, 31 leaves, max depth = 8, in 0.529s
[24/50] 1 tree, 31 leaves, max depth = 8, in 0.460s
[25/50] 1 tree, 31 leaves, max depth = 9, in 0.414s
[26/50] 1 tree, 31 leaves, max depth = 8, in 0.516s
[27/50] 1 tree, 31 leaves, max depth = 10, in 0.427s
[28/50] 1 tree, 31 leaves, max depth = 8, in 0.460s
[29/50] 1 tree, 31 leaves, max depth = 7, in 0.445s
[30/50] 1 tree, 31 leaves, max depth = 12, in 0.535s
[31/50] 1 tree, 31 leaves, max depth = 10, in 0.498s
[32/50] 1 tree, 31 leaves, max depth = 12, in 0.521s
[33/50] 1 tree, 31 leaves, max depth = 12, in 0.503s
[34/50] 1 tree, 31 leaves, max depth = 10, in 0.410s
[35/50] 1 tree, 31 leaves, max depth = 9, in 0.368s
[36/50] 1 tree, 31 leaves, max depth = 10, in 0.267s
[37/50] 1 tree, 31 leaves, max depth = 8, in 0.460s
[38/50] 1 tree, 31 leaves, max depth = 11, in 0.500s
[39/50] 1 tree, 31 leaves, max depth = 8, in 0.421s
[40/50] 1 tree, 31 leaves, max depth = 8, in 0.391s
[41/50] 1 tree, 31 leaves, max depth = 9, in 0.502s
[42/50] 1 tree, 31 leaves, max depth = 9, in 0.444s
[43/50] 1 tree, 31 leaves, max depth = 7, in 0.366s
[44/50] 1 tree, 31 leaves, max depth = 8, in 0.473s
[45/50] 1 tree, 31 leaves, max depth = 9, in 0.386s
[46/50] 1 tree, 31 leaves, max depth = 11, in 0.411s
[47/50] 1 tree, 31 leaves, max depth = 8, in 0.457s
[48/50] 1 tree, 31 leaves, max depth = 10, in 0.526s
[49/50] 1 tree, 31 leaves, max depth = 8, in 0.535s
[50/50] 1 tree, 31 leaves, max depth = 10, in 0.487s
Fit 50 trees in 28.738 s, (1550 total leaves)
Time spent finding best splits: 17.347s
Time spent applying splits: 2.356s
Time spent predicting: 1.428s
done in 28.787s, ROC AUC: 0.7330, ACC: 0.7346
Fitting a LightGBM model...
[LightGBM] [Warning] min_sum_hessian_in_leaf is set=0.001, min_child_weight=0.001 will be ignored. Current value: min_sum_hessian_in_leaf=0.001
[LightGBM] [Warning] min_sum_hessian_in_leaf is set=0.001, min_child_weight=0.001 will be ignored. Current value: min_sum_hessian_in_leaf=0.001
[LightGBM] [Warning] Starting from the 2.1.2 version, default value for the "boost_from_average" parameter in "binary" objective is true.
This may cause significantly different results comparing to the previous versions of LightGBM.
Try to set boost_from_average=false, if your old models produce bad results
[LightGBM] [Info] Number of positive: 2649426, number of negative: 2350574
[LightGBM] [Info] Total Bins 6143
[LightGBM] [Info] Number of data: 5000000, number of used features: 28
[LightGBM] [Info] [binary:BoostFromScore]: pavg=0.529885 -> initscore=0.119683
[LightGBM] [Info] Start training from score 0.119683
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 7
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 9
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 8
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 11
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 11
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 8
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 10
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 8
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 13
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 11
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 11
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 10
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 11
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 9
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 12
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 11
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 9
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 10
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 12
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 13
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 9
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 8
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 9
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 9
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 8
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 8
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 8
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 10
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 9
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 8
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 8
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 10
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 11
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 10
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 9
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 8
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 12
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 11
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 10
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 10
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 10
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 15
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 11
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 8
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 12
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 9
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 10
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 11
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 11
[LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 8
done in 27.595s, ROC AUC: 0.7333, ACC: 0.7349
Fitting an XGBoost model...
[16:33:14] Tree method is selected to be 'hist', which uses a single updater grow_fast_histmaker.
[16:33:24] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=7
[16:33:25] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=9
[16:33:26] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=9
[16:33:26] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=8
[16:33:27] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=10
[16:33:28] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=9
[16:33:29] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=9
[16:33:29] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=12
[16:33:30] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=10
[16:33:31] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=12
[16:33:31] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=11
[16:33:32] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=13
[16:33:33] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=10
[16:33:33] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=10
[16:33:34] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=9
[16:33:35] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=9
[16:33:35] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=11
[16:33:36] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=9
[16:33:36] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=10
[16:33:37] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=12
[16:33:38] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=10
[16:33:38] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=10
[16:33:39] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=9
[16:33:39] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=10
[16:33:40] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=12
[16:33:41] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=10
[16:33:41] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=8
[16:33:42] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=9
[16:33:42] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=9
[16:33:43] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=12
[16:33:44] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=9
[16:33:44] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=8
[16:33:45] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=7
[16:33:45] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=11
[16:33:46] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=7
[16:33:47] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=7
[16:33:47] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=9
[16:33:48] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=9
[16:33:48] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=9
[16:33:49] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=9
[16:33:50] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=9
[16:33:50] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=10
[16:33:50] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=9
[16:33:51] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=8
[16:33:52] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=10
[16:33:52] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=11
[16:33:53] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=8
[16:33:53] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=11
[16:33:54] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=9
[16:33:54] /workspace/src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=12
done in 41.726s, ROC AUC: 0.7335, ACC: 0.7351
coverage run is using is looking up it's configuration file by default from $PWD/.coveragerc. Because we do not run that command from the source repo root folder, but from a empty TEST_DIR subfolder, it did not pick up the configuration and used the default line-by-line coverage reporting which cannot be combined with the branch/arc-based coverage report.
@NicolasHug I fixed the coverage thingy. Reading the coverage report, there is a bunch of things that we could improve with respect to test coverage. But this is experimental and I don't want to delay the merge further. Let's merge once my last commit is green on CI.
Congratulations on this work! This is so important.
Also, I love the way that the "experimental" import was handled. Beautiful choice! It should stand as a reference for the future in similar situations.
Add this suggestion to a batch that can be applied as a single commit.This suggestion is invalid because no changes were made to the code.Suggestions cannot be applied while the pull request is closed.Suggestions cannot be applied while viewing a subset of changes.Only one suggestion per line can be applied in a batch.Add this suggestion to a batch that can be applied as a single commit.Applying suggestions on deleted lines is not supported.You must change the existing code in this line in order to create a valid suggestion.Outdated suggestions cannot be applied.This suggestion has been applied or marked resolved.Suggestions cannot be applied from pending reviews.Suggestions cannot be applied on multi-line comments.Suggestions cannot be applied while the pull request is queued to merge.Suggestion cannot be applied right now. Please check back later.
This PR proposes a new implementation for Gradient Boosting Decision Trees. This isn't meant to be a replacement of the current sklearn implementation but rather an addition.
This addresses the second bullet point from #8231.
This is a port from pygbm (with @ogrisel, in Numba), which itself uses lots of the optimizations from LightGBM.
Algorithm details and refs
The main differences with the current sklearn implementation are:
Notes to reviewers
This is going to be a lot of work to review, so please feel free to tell me if there's anything I can do / add that could ease reviewing.
Here's a list of things that probably need to be discussed at some point or that are worth pointing out.
The code is a port of pygbm (from numba to cython). I've ported all the tests as well. So a huge part of the code has already been carefully reviewed (or written) by @ogrisel. There are still a few non-trivial changes to the pygbm's code, to accommodate for the numba -> cython translation.
Like [MRG] new K-means implementation for improved performances #11950, this PR uses OpenMP parallelism with Cython
The code is in
sklearn/ensemble._hist_gradient_boostingand the estimators are exposed insklearn.experimental(which is created here, as a result of a discussion during the Paris sprint).Y_DTYPEand the associated C type for targetsyis double and not float, because with float the numerical checks (test_loss.py) would not pass. Maybe at some point we'll want to also allow floats since using doubles uses twice as much space (which is not negligible, see the attributes of theSplitterclass).I have only added a short note in the User Guide about the new estimators. I think that the gradient boosting section of the user guide could benefit from an in-depth rewriting. I'd be happy to do that, but in a later PR.
Currently the parallel code uses all possible threads. Do we want to expose
n_jobs(openmp-wise, not joblib of course)?The estimator names are currently
HistGradientBoostingClassifierandHistGradientBoostingRegressor.API differences with current implementation:
Happy to discuss these points of course. In general I tried to match the parameters names with those of the current GBDTs.
New features:
validation_fractioncan also be an int to specify absolute size of the validation set (not just a proportion)Changed parameters and attributes:
n_estimatorsparameter has been changed tomax_iterbecause unlike the current GBDTs implementations, the underlying "predictor" aren't estimators. They are private and have nofitmethod. Also, in multiclass classification we build C * max_iterestimators_attribute has been removed for the same reason.train_score_is of sizen_estimators + 1instead ofn_estimatorsbecause it contains the score of the 0th iteration (before the boosting process).oob_improvement_is replaced byvalidation_score_, also with sizen_estimators + 1Unsupported parameters and attributes:
subsample(doesn't really make sense here)criterion(same)min_samples_splitis not supported, butmin_samples_leafis supported.samples_weights-relatedmin_impurity_decreaseis not supported (we havemin_gain_to_splitbut it is not exposed in the public API)warm_startmax_features(probably not needed)staged_decision_function,staged_predict_proba, etc.initestimatorfeature_importances_loss_attribute is not exposed.Future improvement, for later PRs (no specific order):
_in_fithackish attribute.Benchmarks
Done on my laptop, intel i5 7th Gen, 4 cores, 8GB Ram.
TLDR:
Comparison between proposed PR and current estimators:
on binary classification only, I don't think it's really needed to do more since the performance difference is striking. Note that for larger sample sizes the current estimators simply cannot run because of the sorting step that never terminates. I don't provide the benchmark code, it's exactly the same as that of
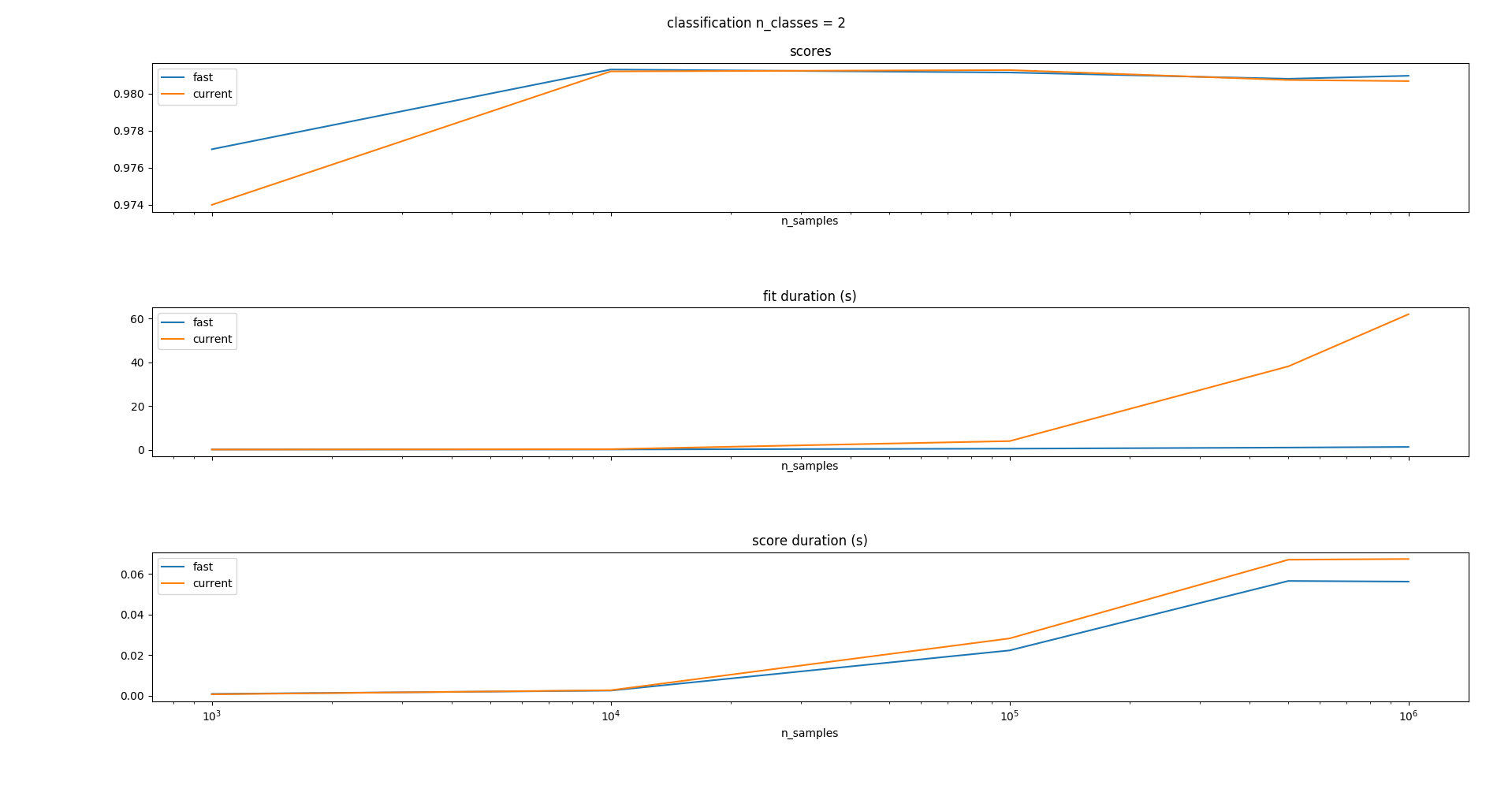
benchmarks/bench_fast_gradient_boosting.py:Comparison between proposed PR and LightGBM / XGBoost:
On the Higgs-Boson dataset:
python benchmarks/bench_hist_gradient_boosting_higgsboson.py --lightgbm --xgboost --subsample 5000000 --n-trees 50Sklearn: done in 28.787s, ROC AUC: 0.7330, ACC: 0.7346
LightGBM: done in 27.595s, ROC AUC: 0.7333, ACC: 0.7349
XGBoost: done in 41.726s, ROC AUC: 0.7335, ACC: 0.7351
Entire log:
regression task:
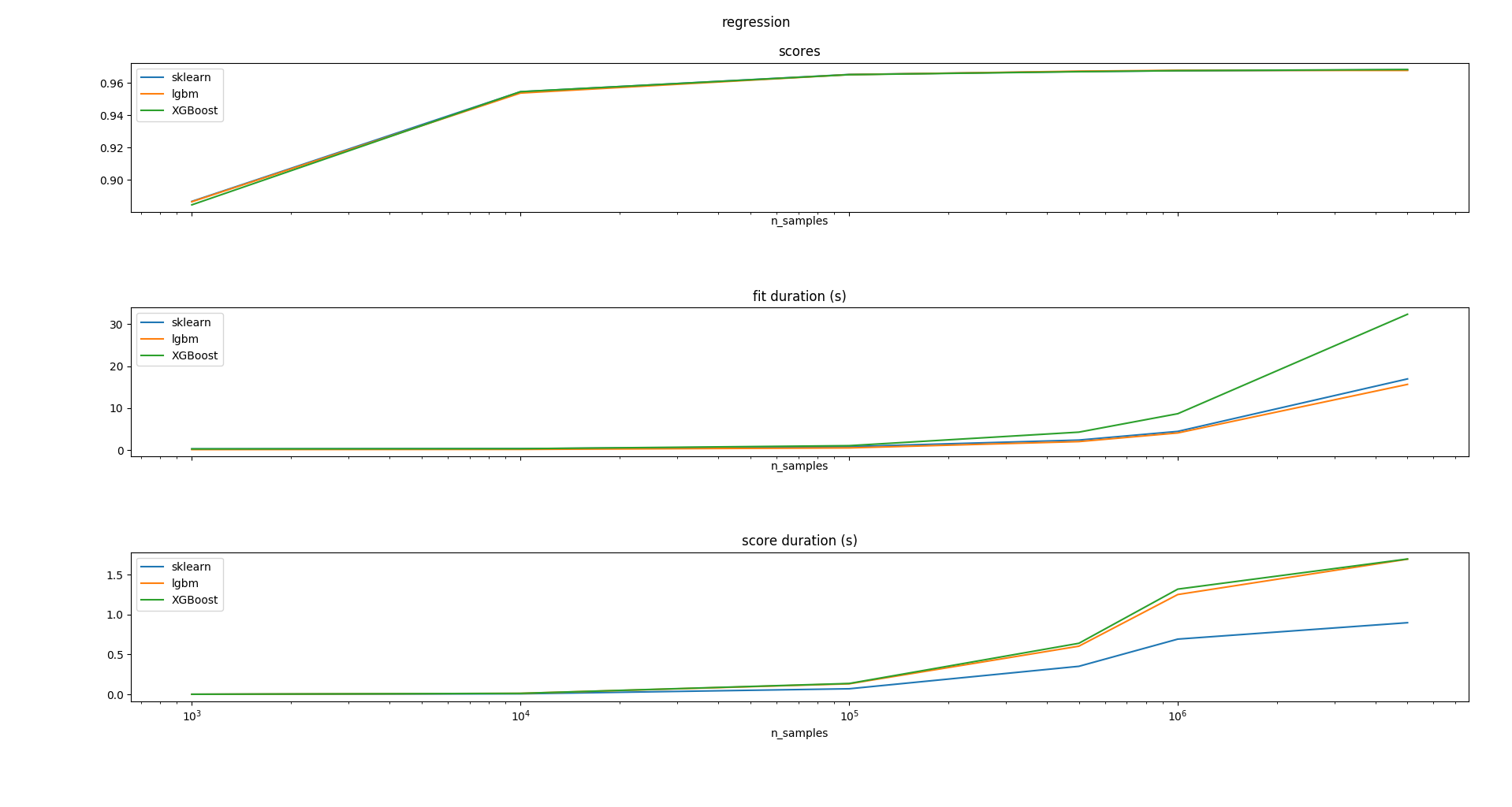
python benchmarks/bench_hist_gradient_boosting.py --lightgbm --xgboost --problem regression --n-samples-max 5000000 --n-trees 50Binary classification task:
python benchmarks/bench_hist_gradient_boosting.py --lightgbm --xgboost --problem classification --n-classes 2 --n-samples-max 5000000 --n-trees 50python benchmarks/bench_hist_gradient_boosting.py --lightgbm --xgboost --problem classification --n-classes 3 --n-samples-max 5000000 --n-trees 50