| CARVIEW |
Navigation Menu
-
Notifications
You must be signed in to change notification settings - Fork 22k
SQLite non-GVL-blocking, fair retry interval busy handler #51958
New issue
Have a question about this project? Sign up for a free GitHub account to open an issue and contact its maintainers and the community.
By clicking “Sign up for GitHub”, you agree to our terms of service and privacy statement. We’ll occasionally send you account related emails.
Already on GitHub? Sign in to your account
SQLite non-GVL-blocking, fair retry interval busy handler #51958
Conversation
activerecord/lib/active_record/connection_adapters/sqlite3_adapter.rb
Outdated
Show resolved
Hide resolved
e09a702 to
800069b
Compare
|
Also some of the CI failures are legit (rubocop & Active Record), you can ignore the Action Text failure though. |
800069b to
1a1b94c
Compare
|
... CoPilot and those damned hanging parens. |
1a1b94c to
dec9f1c
Compare
|
I'm guessing that the guides failures are related, but the errors don't really have any messages, so I'm not sure what the problem is and thus how to possibly fix it. But other issues are fixed. |
|
Edit: oh you already got that one... Maybe this one?
>= is not in the error message...
OH the bug report template uses |
|
Ok. I'll simplify the changes for the guides to simply use |
432da1b to
111d8a3
Compare
|
So releasing the GVL when waiting for the write lock is a bit of a double edged sword in my opinion. On one hand it does allow other threads to run, which is certainly a good thing for the throughput of an individual process in most cases. On the other hand, it can cause a situation where you acquired the lock, but then have to wait a very long time to acquire the GVL. So potentially, you are occasionally locking the database for much longer than before. e.g. if you are running 10 threads, you can potentially wait up to 900ms to get the GVL back, and all this time you are holding the In other words, I'm in favor of this change, but have some small reservations. @fractaledmind is the code you used for you benchmark available somewhere? I'd like to experiment with it if I find the time (apologies if it's in your blog post and I missed the link). |
|
I have been using the |
|
@fractaledmind - I've just tried this out on Campfire and it looks good. We are currently using a retry with backoff, but I'm not seeing any performance differences with our load tests with this setting. Did you try out the effects of a small amount of retry backoff in your tests? I wonder if we could get higher throughput without affecting the high percentiles too negatively. |
|
+1 on these changes, so that we can make use of the new version of the Will this likely be slated for Rails 7.2.0? |
@djmb: In the original PR, we benchmarked a number of different implementations of the I don't immediately follow how adding retry backoff could increase throughput tho? Fill me in on your thought here? One thing I needed some time to wrap my head around is how this "queue" behaves differently than the type of queues I was familiar with (a background job queue), and what that difference implies when designing a busy handler. In a typical background job queue, when you say "retry in 1 second", that job will be executed in 1 second. The "retry" is a command that will be honored. When you can command that a job is retried after a particular interval, you don't need to worry about "older jobs" (jobs that have been retried more times) having any sort of penalty relative to "newer jobs" and so having some kind of backoff steps makes sense to distribute execution load. But, with this "queue", we aren't telling SQLite "retry this query in 1 ms" as a command, we are more so saying "you can attempt to run this query again in 1ms". There is no guarantee that the query will actually run, since it has to attempt to acquire the write lock before running. When you switch from commanding a job to run in the future to requesting that a query try to run in the future, now you have to deal with how a backoff starts to penalize "older queries". I wrote an in-depth article on this topic, but the TL;DR is that having backoff1 has a noticeable impact on long-tail latency (p99.99 from my load testing): but when using the "fair" retry interval from the And since we are retrying all queries within 1ms, I don't immediately see how we could increase throughput by retrying older queries after some increased duration. When there are fewer queries, this will have no impact on throughput but only increase latency a bit, since there won't be enough contention on the write lock to prevent the older query from running, but it will only run after N ms instead of 1ms. But, when there are more queries, this will increase latency a lot, but I still don't see how it would increase throughput, as the same number of queries will be executed. Since writes are executed serially, throughput is always constant, right? Again, I'm probably missing something, but this is my reasoning as I understand things. Throughput is fixed, but we can improve latency with by ensuring that the busy handler [1] doesn't block the GLV and [2] has a fair retry interval. Footnotes
|
fb7a813 to
999062d
Compare
|
@fractaledmind - my concern would be where you have a lot of threads/processes all waiting to get a lock and a single thread that is holding on to the transaction for a long time. Could the polling eat enough resources to cause the thread with the transaction to slow down (especially for polling by threads on the same process as they will need the GVL)? |
|
@djmb: I will try to create a test case to benchmark this. |
|
To consider the impact of polling for the lock, we (myself and @oldmoe) wanted to explore the following three scenarios:
In order to explore a wide range of situations, we had the contentious fast queries run from a composition of processes and threads. The slow queries were always ran from the single parent process in succession. You can find the code used to run the various scenarios in this gist Both modes of the We play with 3 variables to create the various contention situations:
The first situation has the parent process run zero slow queries, so all contention comes from the fast queries that the child connections are running. The ideal case, regardless of the number of child processes and/or threads, is that the script, parent connection, fastest child connection, and slowest child connection all finish in very short durations. This is because the only queries being run inside of the transactions are fast queries ( For the In the worst case, The second scenario has the parent process run one slow query, so all contention comes from the fast queries that the children connection is running. The ideal case is that the gap between the duration for the parent connection and the script duration is minimal, the gap between the fastest and slowest child connection is minimal. This is because the total script execution time should not be majorly impacted by the child processes (thus the small first gap), the children connections should not have any unfairly punished executions since they are all running only fast queries. These are the results we see for the What we observe is that the gap between While the gap between In the third scenario, where the parent connection is running two slow queries with 1ms gap in between executions, we hope to see that the fast child queries are able to acquire the lock between the two slow queries running in the parent. We then similarly want to see that the gap between fastest and slowest child connections is minimal (tho it will be larger than previous scenarios, because the slowest child connection will be the one that has to wait for both slow parent queries to finish). Here are the results for the We see that indeed the fastest child connections remain fast, while the slowest child connections are only slightly faster than the parent connection (the 200ms that we have the child processes sleep before beginning). For the So, I believe it is fair to say that across all three situations, the If we find a "mode" for the If you want, you can view all of the raw results in the full output file |
|
I feel like upgrading sqlite should be a separate worthwhile pr |
|
@fractaledmind - thanks for that! I've tried out your script with some adjustments - 1. do everything in one process so all the threads are all contending for the GVL, 2. get the thread running the slow query to do some CPU intensive work while holding the transaction. The idea is to see if the CPU intensive work is slowed down by the other threads waking to retry. I'm not seeing any significant differences in timings between constant/backoff modes doing that so looks great to me 👍 |
|
Lovely. If you want to share those tweaks with me, I'd love to incorporate into the sandbox so that future explorations of busy handler implementations can be tested against a wide and useful set of scenarios. And I see a conflict now in the PR so I will get that cleaned up and push up a clean PR here shortly. |
f36aacc to
4348c8b
Compare
4348c8b to
03b668b
Compare
|
Fixed the CHANGELOG conflict and see a different test failure. This looks like another flaky test. |
|
@byroot could we get this merged? |
03b668b to
5f72e7f
Compare
| require "active_record/connection_adapters/sqlite3/schema_statements" | ||
|
|
||
| gem "sqlite3", ">= 1.4" | ||
| gem "sqlite3", ">= 2.0" |
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
This was still missing.
activerecord/lib/active_record/connection_adapters/sqlite3_adapter.rb
Outdated
Show resolved
Hide resolved
…GVL-blocking, fair retry interval busy handler implementation Co-Authored-By: Jean Boussier <byroot@ruby-lang.org>
5f72e7f to
2976d37
Compare
|
Alright, I don't really have the time/energy to review the benchmark scripts, so I chose to take them at face value. Anyway, that's a feature provided by the underlying driver, so performance issues with this should be handled upstream. |
ActiveRecord.deprecator.warn(<<~MSG)
The retries option is deprecated and will be removed in Rails 8.0. Use timeout instead.
MSGIs this message OK? I believe |
|
Yes, main was already renamed in 8.0.alpha. |
|
👍 target moved to 8.1 in 7d282b4. |
* Add /gemfiles/vendor/ to .gitignore since the directory is used when installing by using Gemfile under gemfiles/ dir * Rails 6.1 or above should use rspec-rails 6.x to comply its policy https://github.com/rspec/rspec-rails/blob/d0e322b20bb713b200b66d4a7cc21a272d0b4374/README.md#L11-L16 * Rails 8.0 require sqlite3 2.0 or above rails/rails#51958 * Add Ruby 3.3 x Rails 7.2 to test matrix
Rails main requires `sqlite3` version 2: rails/rails#51958
Rails main requires `sqlite3` version 2: rails/rails#51958
Rails main requires `sqlite3` version 2: rails/rails#51958
Motivation / Background
As detailed in #50370, the current use of SQLite's
busy_timeoutfunctionality leads to notable increases in tail latency as well as occasionalSQLite3::BusyException: database is lockederrors since it does not release the GVL while waiting to retry acquiring the SQLite database lock. Version 2.0 of thesqlite3gem introduces a newSQLite3::Database#busy_handler_timeout=method, which provides a non-GVL-blocking, fair retry interval busy handler implementation.cc: @flavorjones @tenderlove @byroot
Detail
This PR points the
timeoutoption thedatabase.ymlconfig file at this new busy handler implementation. In order to ensure that this new method is present, I have also opened #51957 so that Rails 8 defaults to version >= 2.0 for thesqlite3gem.Additional information
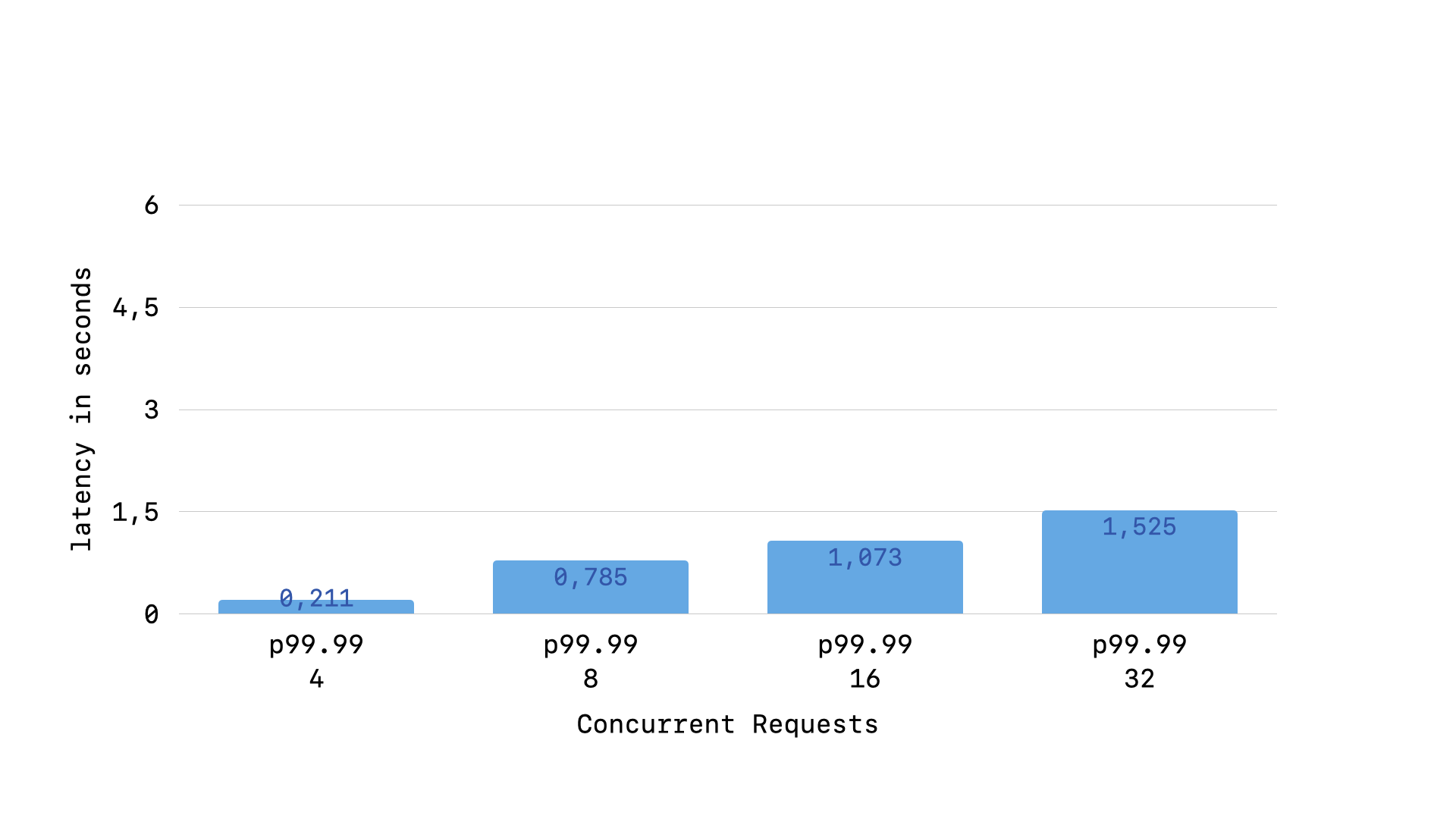
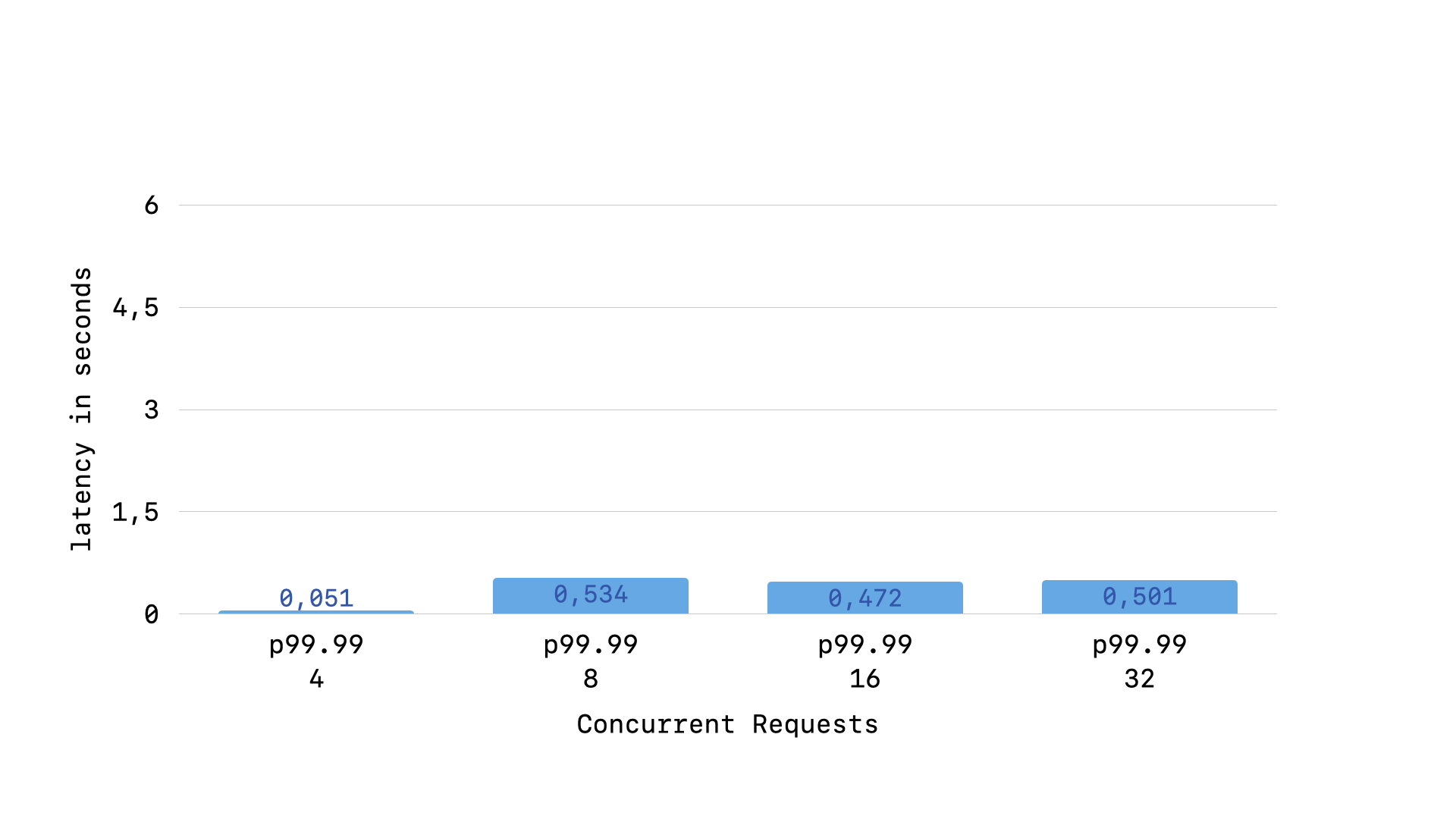
As detailed in my deep dive on this topic, having such a busy handler is essential for running production-grade Rails application using SQLite. In my benchmarks, ensuring that the busy handler doesn't hold the GVL brought p95 latency down from >5s to 0.19s. Then, ensuring that the retry interval was fair for both "old" and "new" queries brought p99.99 latency down from >1.5s to 0.5s.
Checklist
Before submitting the PR make sure the following are checked:
[Fix #issue-number]