You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
We study algorithms for k-means clustering, focusing on a trade-off between explainability and accuracy.
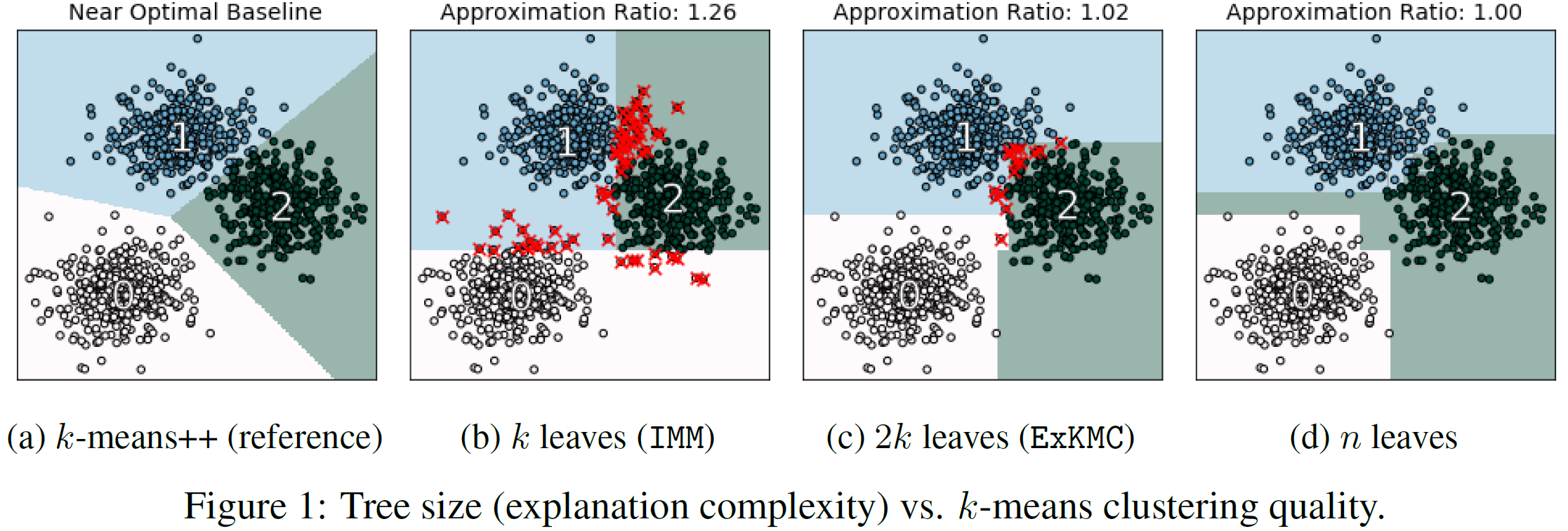
We partition a dataset into k clusters via a small decision tree.
This enables us to explain each cluster assignment by a short sequence of single-feature thresholds.
While larger trees produce more accurate clusterings, they also require more complex explanations.
To allow flexibility, we develop a new explainable k-means clustering algorithm, ExKMC, that takes an additional parameter k' ≥ k and outputs a decision tree with k' leaves.
We use a new surrogate cost to efficiently expand the tree and to label the leaves with one of k clusters.
We prove that as k' increases, the surrogate cost is non-increasing, and hence, we trade explainability for accuracy.
fromExKMC.TreeimportTreefromsklearn.datasetsimportmake_blobs# Create datasetn=100d=10k=3X, _=make_blobs(n, d, k, cluster_std=3.0)
# Initialize tree with up to 6 leaves, predicting 3 clusterstree=Tree(k=k, max_leaves=2*k)
# Construct the tree, and return cluster labelsprediction=tree.fit_predict(X)
# Tree plot saved to filenametree.plot('filename')
@article{dasgupta2020explainable,
title={Explainable $k$-Means and $k$-Medians Clustering},
author={Dasgupta, Sanjoy and Frost, Nave and Moshkovitz, Michal and Rashtchian, Cyrus},
journal={arXiv preprint arXiv:2002.12538},
year={2020}
}