You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
The 36th AAAI Conference on Artificial Intelligence (AAAI), 2022, Oral
Introduction
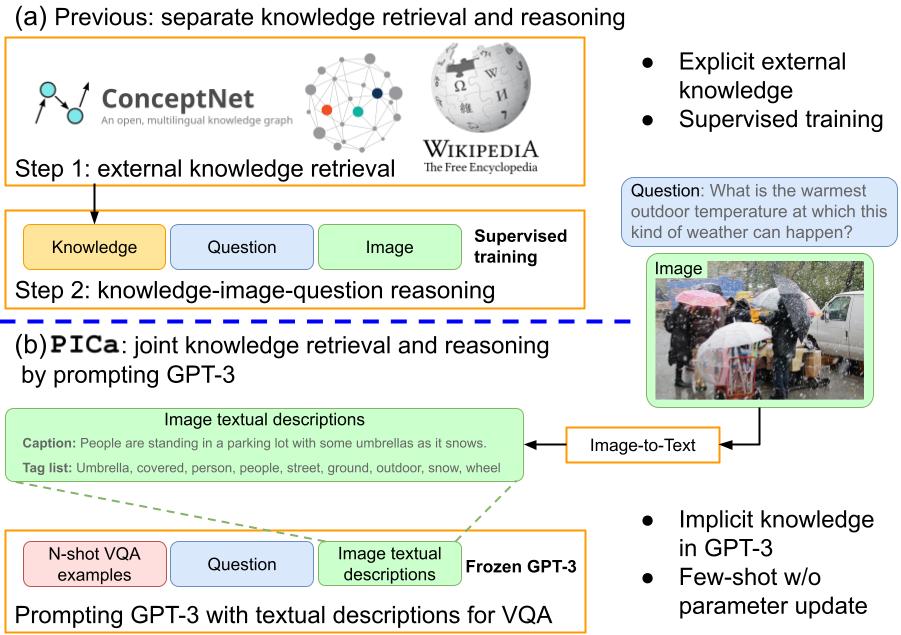
Can GPT-3 benefit multimodal tasks? We provide an empirical study of GPT-3 for knowledge-based VQA, named PICa. We show that prompting GPT-3 via the use of image captions with only 16 examples surpasses supervised sota by an absolute +8.6 points on the OK-VQA dataset (from 39.4 to 48.0).
Citation
@inproceedings{yang2021empirical,
title={An Empirical Study of GPT-3 for Few-Shot Knowledge-Based VQA},
author={Yang, Zhengyuan and Gan, Zhe and Wang, Jianfeng and Hu, Xiaowei and Lu, Yumao and Liu, Zicheng and Wang, Lijuan},
booktitle={AAAI},
year={2022}
}
Prepare the data
The cached files for converted OKVQA data, predicted text representations, and similarity features are in the coco_annotations, input_text, and coco_clip_new folders, respectively.
Running
We experimented with the older engine davinci instead of the current default text-davinci-001 that is boosted for instruction tuning, see more discussion here.
Outputs will be saved to format_answer and prompt_answer folders. format_answer is used for final evaluation, following the vqav2 format. prompt_answer contains the input prompt for human interpretation.
output_saved provides the cached predictions.
About
An Empirical Study of GPT-3 for Few-Shot Knowledge-Based VQA, AAAI 2022 (Oral)