You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
Fault-tolerant, highly scalable GPU orchestration, and a machine learning framework designed for training models with billions to trillions of parameters
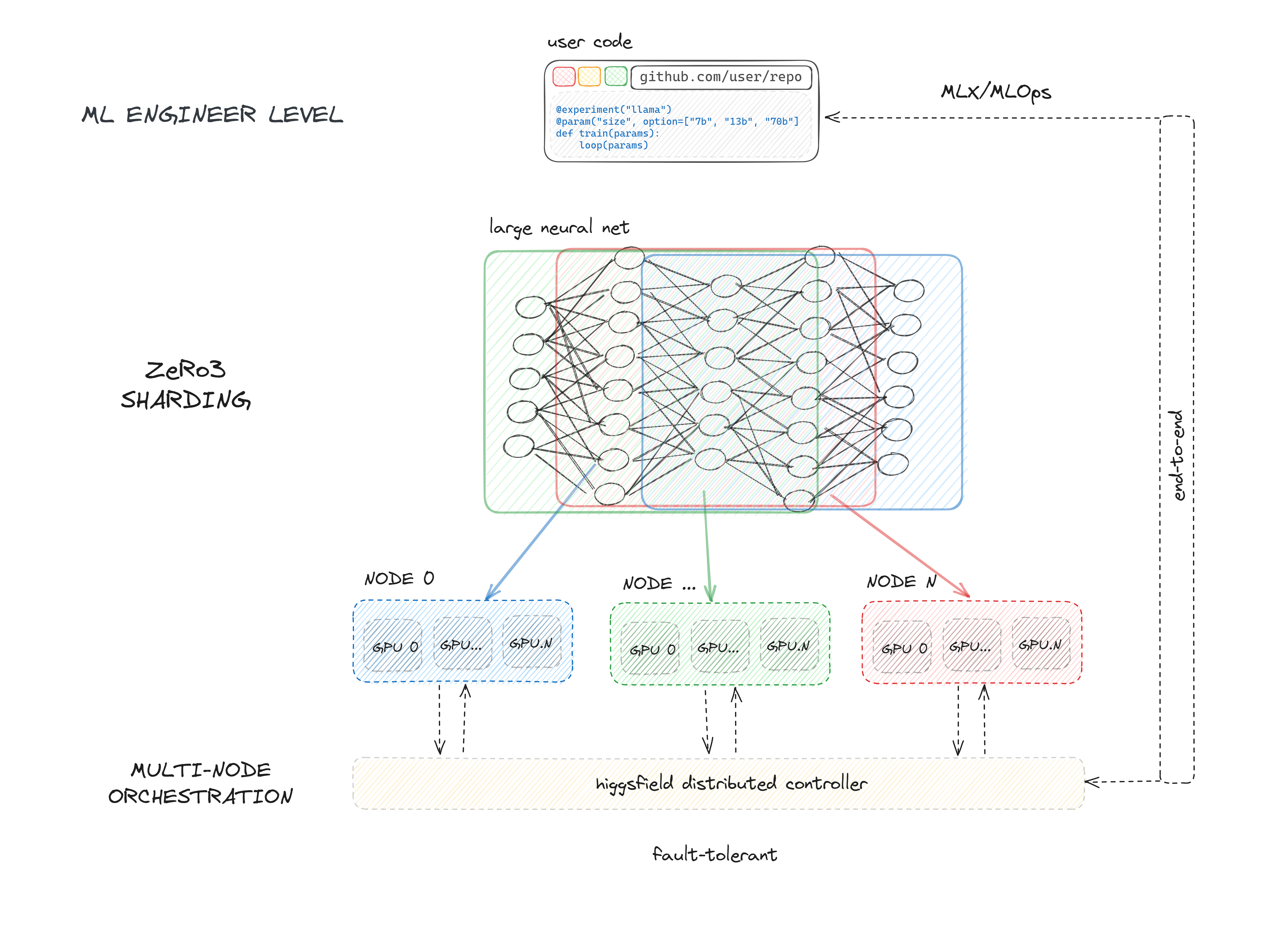
Higgsfield is an open-source, fault-tolerant, highly scalable GPU orchestration, and a machine learning framework designed for training models with billions to trillions of parameters, such as Large Language Models (LLMs).
Higgsfield serves as a GPU workload manager and machine learning framework with five primary functions:
Allocating exclusive and non-exclusive access to compute resources (nodes) to users for their training tasks.
Supporting ZeRO-3 deepspeed API and fully sharded data parallel API of PyTorch, enabling efficient sharding for trillion-parameter models.
Offering a framework for initiating, executing, and monitoring the training of large neural networks on allocated nodes.
Managing resource contention by maintaining a queue for running experiments.
Facilitating continuous integration of machine learning development through seamless integration with GitHub and GitHub Actions.
Higgsfield streamlines the process of training massive models and empowers developers with a versatile and robust toolset.
Install
$ pip install higgsfield==0.0.3
Train example
That's all you have to do in order to train LLaMa in a distributed setting:
We install all the required tools in your server (Docker, your project's deploy keys, higgsfield binary).
Then we generate deploy & run workflows for your experiments.
As soon as it gets into Github, it will automatically deploy your code on your nodes.
Then you access your experiments' run UI through Github, which will launch experiments and save the checkpoints.
Design
We follow the standard pytorch workflow. Thus you can incorporate anything besides what we provide, deepspeed, accelerate, or just implement your custom pytorch sharding from scratch.
Enviroment hell
No more different versions of pytorch, nvidia drivers, data processing libraries.
You can easily orchestrate experiments and their environments, document and track the specific versions and configurations of all dependencies to ensure reproducibility.
Config hell
No need to define 600 arguments for your experiment. No more yaml witchcraft.
You can use whatever you want, whenever you want. We just introduce a simple interface to define your experiments. We have even taken it further, now you only need to design the way to interact.
Compatibility
We need you to have nodes with:
Ubuntu
SSH access
Non-root user with sudo privileges (no-password is required)
Clouds we have tested on:
Azure
LambdaLabs
FluidStack
Feel free to open an issue if you have any problems with other clouds.
Fault-tolerant, highly scalable GPU orchestration, and a machine learning framework designed for training models with billions to trillions of parameters