You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
{{ message }}
This repository was archived by the owner on Aug 29, 2023. It is now read-only.
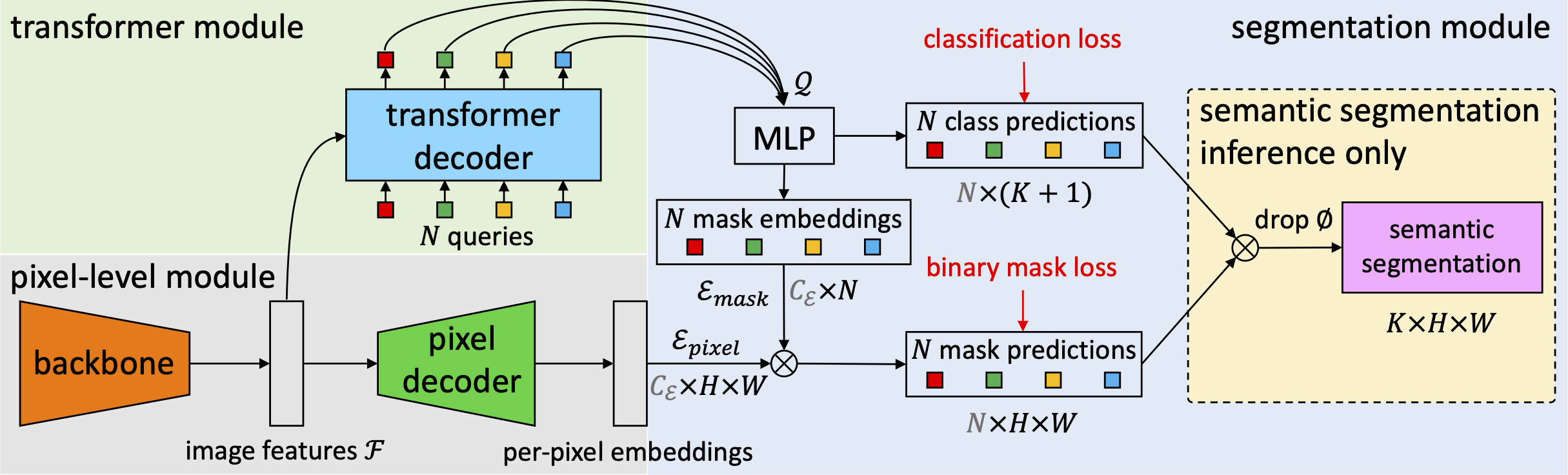
Checkout Mask2Former, a universal architecture based on MaskFormer meta-architecture that
achieves SOTA on panoptic, instance and semantic segmentation across four popular datasets (ADE20K, Cityscapes, COCO, Mapillary Vistas).
Features
Better results while being more efficient.
Unified view of semantic- and instance-level segmentation tasks.
Support major semantic segmentation datasets: ADE20K, Cityscapes, COCO-Stuff, Mapillary Vistas.
However portions of the project are available under separate license terms: Swin-Transformer-Semantic-Segmentation is licensed under the MIT license.
Citing MaskFormer
If you use MaskFormer in your research or wish to refer to the baseline results published in the Model Zoo, please use the following BibTeX entry.
@inproceedings{cheng2021maskformer,
title={Per-Pixel Classification is Not All You Need for Semantic Segmentation},
author={Bowen Cheng and Alexander G. Schwing and Alexander Kirillov},
journal={NeurIPS},
year={2021}
}
About
Per-Pixel Classification is Not All You Need for Semantic Segmentation (NeurIPS 2021, spotlight)