You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
PyTorch implementation of the InfoNCE loss from "Representation Learning with Contrastive Predictive Coding".
In contrastive learning, we want to learn how to map high dimensional data to a lower dimensional embedding space.
This mapping should place semantically similar samples close together in the embedding space, whilst placing semantically distinct samples further apart.
The InfoNCE loss function can be used for the purpose of contrastive learning.
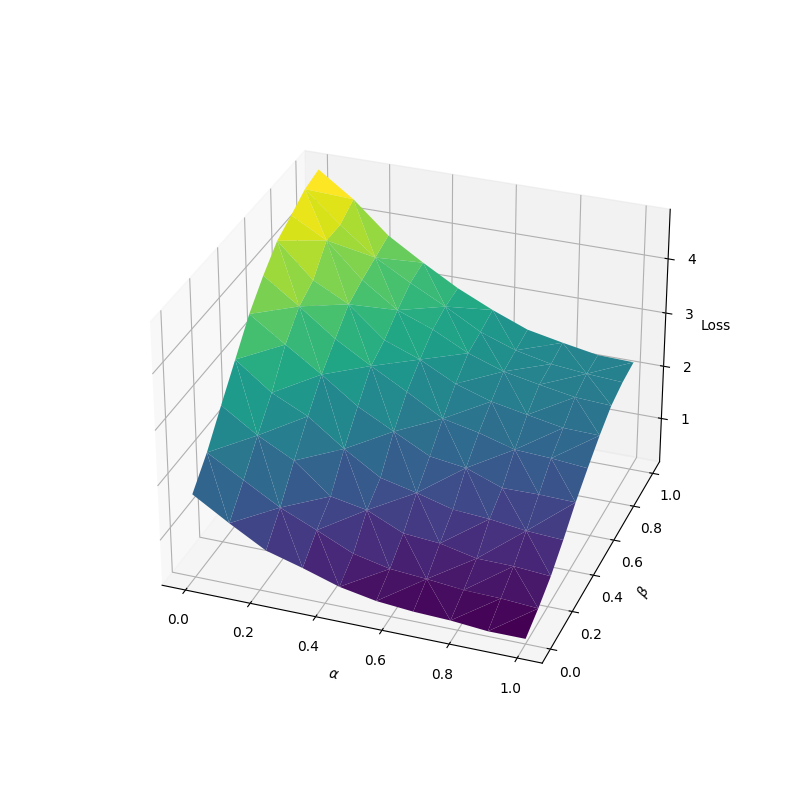
Suppose we have some initial mean vectors µ_q, µ_p, µ_n and a covariance matrix Σ = I/10, then we can plot the value of the InfoNCE loss by sampling from distributions with interpolated mean vectors.
Given interpolation weights α and β, we define the distribution Q ~ N(µ_q, Σ) for the query samples, the distribution P_α ~ N(αµ_q + (1-α)µ_p, Σ) for the positive samples
and the distribution N_β ~ N(βµ_q + (1-β)µ_n, Σ) for the negative samples.
Shown below is the value of the loss with inputs sampled from the distributions defined above for different values of α and β.
About
PyTorch implementation of the InfoNCE loss for self-supervised learning.