Event cameras, which capture pixel-level brightness changes asynchronously, provide rich motion information that is often missed during traditional frame-based camera exposures, thereby offering fresh perspectives for motion deblurring. Although current approaches incorporate event intensity, they neglect essential spatial motion information. Unlike their CNN architectures, Transformers excel in modeling long-range dependencies but struggle with establishing relevant non-local connections in sparse events and fail to highlight significant interactions in dense images. To address these limitations, we introduce a Motion-Adaptive Transformer network (MAT) that utilizes spatial motion information to forge robust global connections. The core design is an Adaptive Motion Mask Predictor (AMMP) that identifies key motion regions, guiding the Motion-Sparse Attention (MSA) to eliminate irrelevant event tokens and enabling the Motion-Aware Attention (MAA) to focus on relevant ones, thereby enhancing long-range dependency modeling. Additionally, we elaborately design a Cross-Modal Intensity Gating mechanism that efficiently merges intensity data across modalities while minimizing parameter use. The learnable Expansion-Controlled Spatial Gating further optimizes the transmission of event features. Comprehensive testing confirms that our approach sets a new benchmark in image deblurring, surpassing previous methods by up to 0.60dB on the GoPro dataset, 1.04dB on the HS-ERGB dataset, and achieving an average improvement of 0.52dB across two real-world datasets.
This repository contains the official implementation of our paper "Motion-adaptive Transformer for Event-based Image Deblurring", accepted at the AAAI 2025.
This is the overview of our network's architecture:
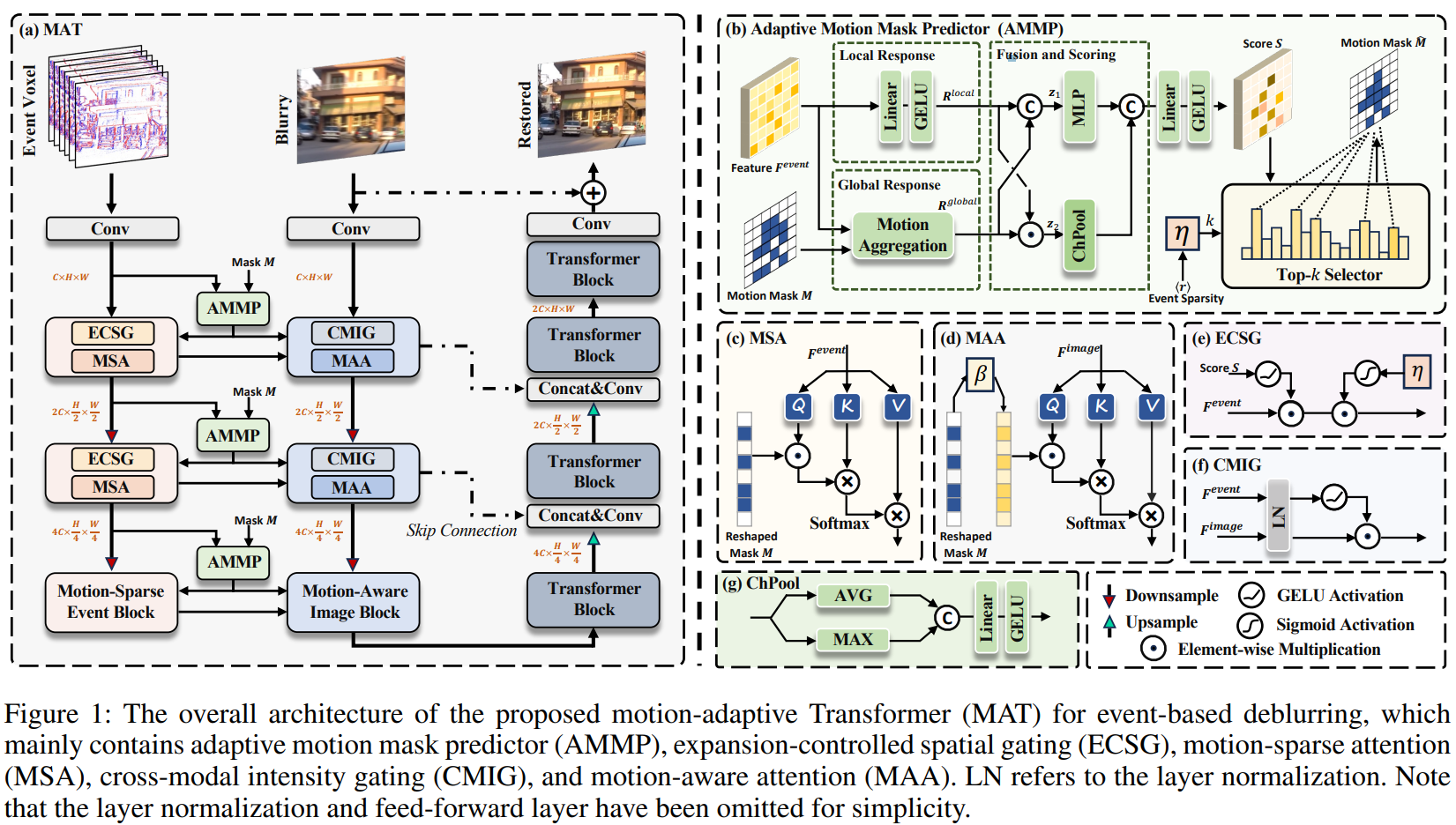
See more details in [paper].
- Release the pretrained models.
- Release the visual results of MAT.
Use the following command line for the installation of dependencies required to run MAT.
git clone https://github.com/QUEAHREN/DemosaicFormer.git
cd DemosaicFormer
conda create -n pytorch181 python=3.7
conda activate pytorch181
conda install pytorch=1.8 torchvision cudatoolkit=10.2 -c pytorch
pip install matplotlib scikit-learn scikit-image opencv-python yacs joblib natsort h5py tqdm
pip install einops gdown addict future lmdb numpy pyyaml requests scipy tb-nightly yapf lpips
You can download the visual results of our MAT on GoPro, HS-ERGB, REBlur, and REVD datasets in [GOOGLE DRIVE].
If you find our work useful in your research, please consider citing:
@InProceedings{MAT_2025_AAAI,
author={Xu, Senyan and Sun, Zhijing and Zhong, Mingchen and Cao, Chengzhi and Liu, Yidi and Fu, Xueyang and Chen, Yan},
booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
volume={39},
number={9},
pages={8942--8950},
year={2025}
}
Should you have any question, please contact syxu@mail.ustc.edu.cn
Acknowledgment: This code is based on the BasicSR toolbox.