| CARVIEW |
Navigation Menu
-
Notifications
You must be signed in to change notification settings - Fork 7
Finetuning
During the "Scaling responsible MLOps with Azure Machine Learning"
breakout session you saw Bea creating some amazing training
pipelines in AzureML. We will primarily be using the az ml
CLI commands to get this done.
There are comprehensive docs on setting up the
Azure CLI.
Once installed, we need to add the az ml CLI extension
(see docs). The commands in this page assume
that you configured your default resource group, workspace, and location, which you can do with the following command:
az configure --defaults group=$GROUP workspace=$WORKSPACE location=$LOCATION
If you're not quite sure what to set these variables to, check your current defaults in the Azure ML Studio. This is what I see:
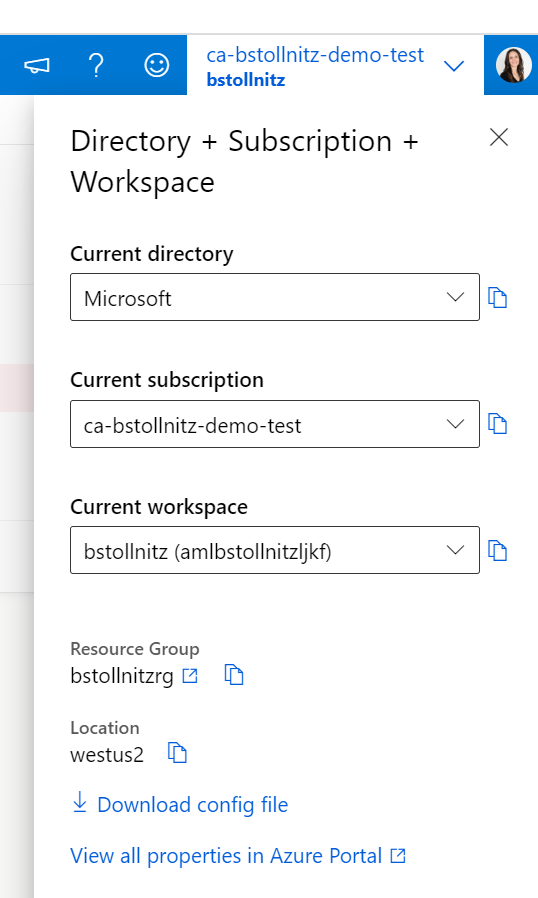
And this is how I configured my defaults:

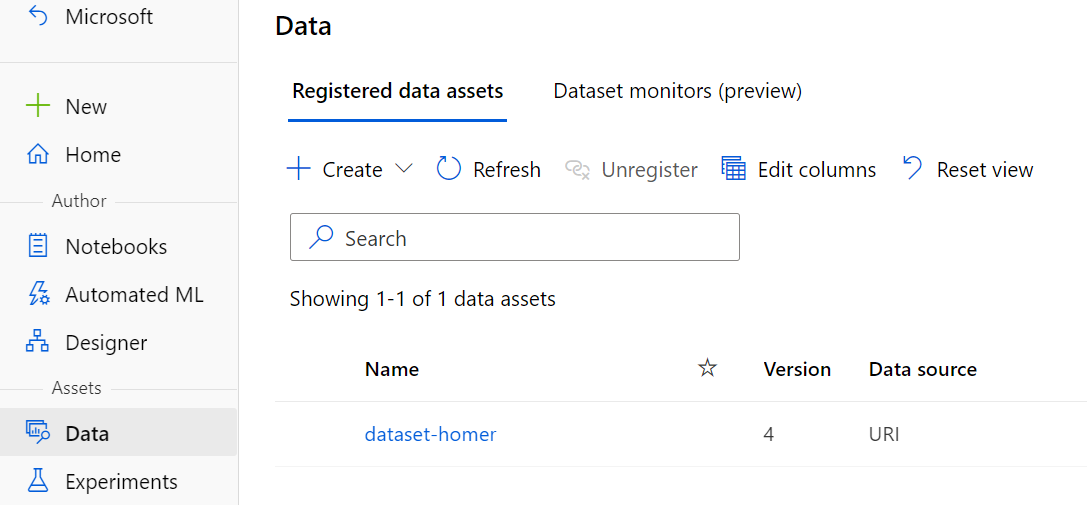
The following command registers the raw Homer file dataset:
az ml data create -f cloud/data.yml
You can verify that the dataset has been created using the Azure ML Studio:
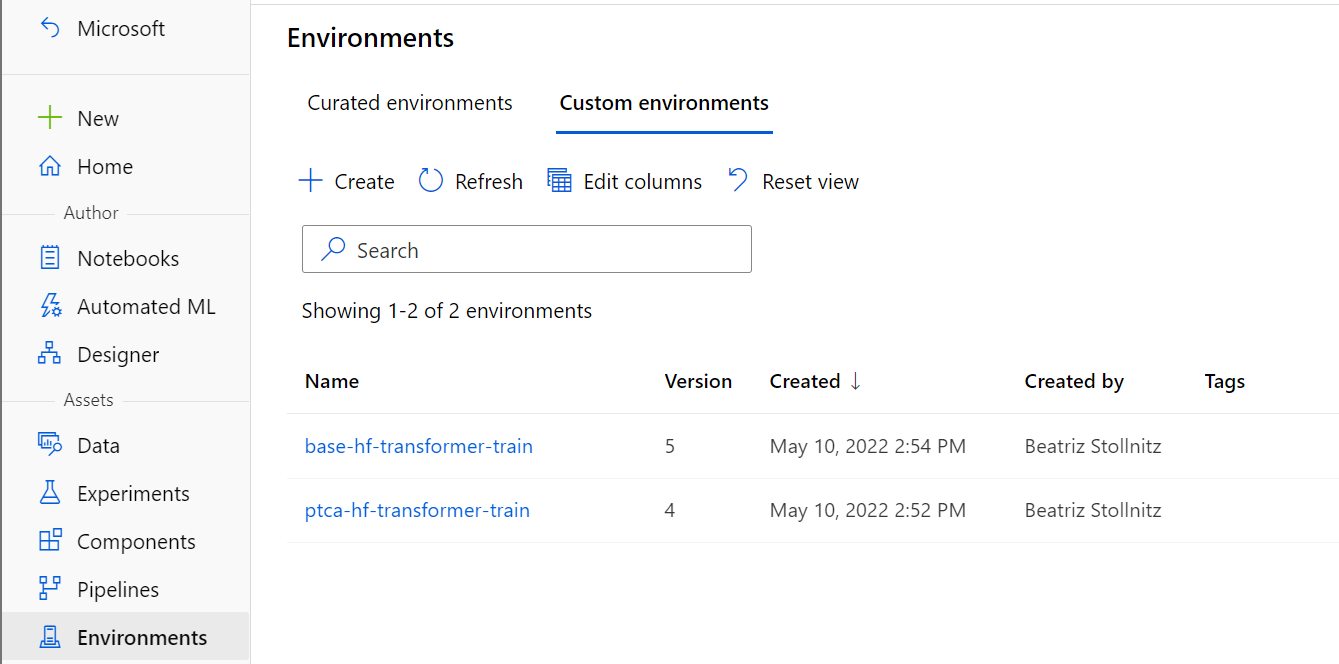
There are two environment yml files in the project, one for the accelerated container, and another one for the normal one. The pipeline uses both.
az ml environment create -f environments/ptca-train/ptca_train.yml
and
az ml environment create -f environments/base-train/base_train.yml
These commands can take a bit of time (since containers are being built).
Verify that they were created in the Azure ML Studio:
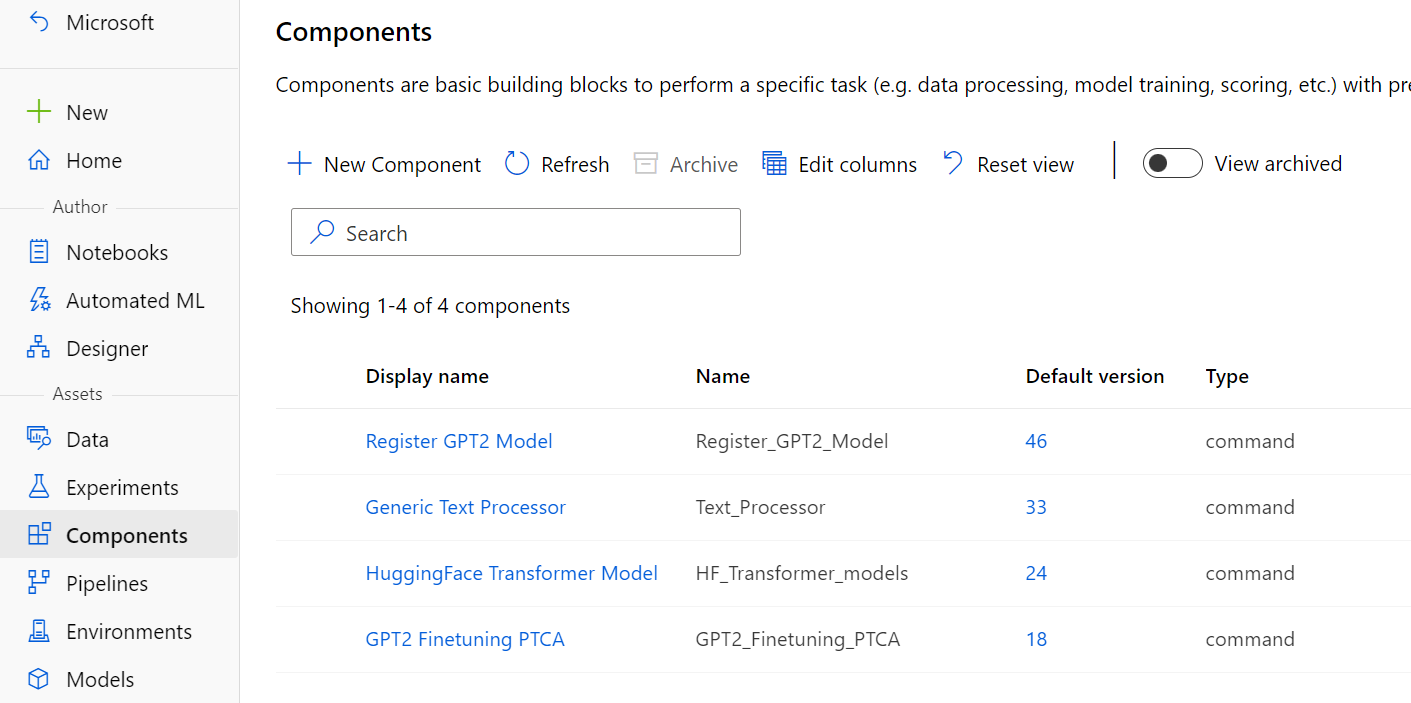
The following commands register each AzureML component used in the pipeline.
az ml component create -f components/finetune-ptca.yml
az ml component create -f components/huggingface.yml
az ml component create -f components/process.yml
az ml component create -f components/register_model.yml
You can verify these were created by checking the Azure ML Studio:
This command creates and runs the ML pipeline. The
first step is to change the target compute to match
the name of your compute cluster.
Go to the pipeline.yml
file and change compute: nc24rs-v3-gpu-cluster to match
the name of your cluster, which you can find by navigating to "Compute" and then "Compute clusters" in the Azure ML UI. Now you're ready to run this
command:
az ml job create -f cloud/pipeline.yml
This takes several minutes to run (we're training and registering a hefty language model).
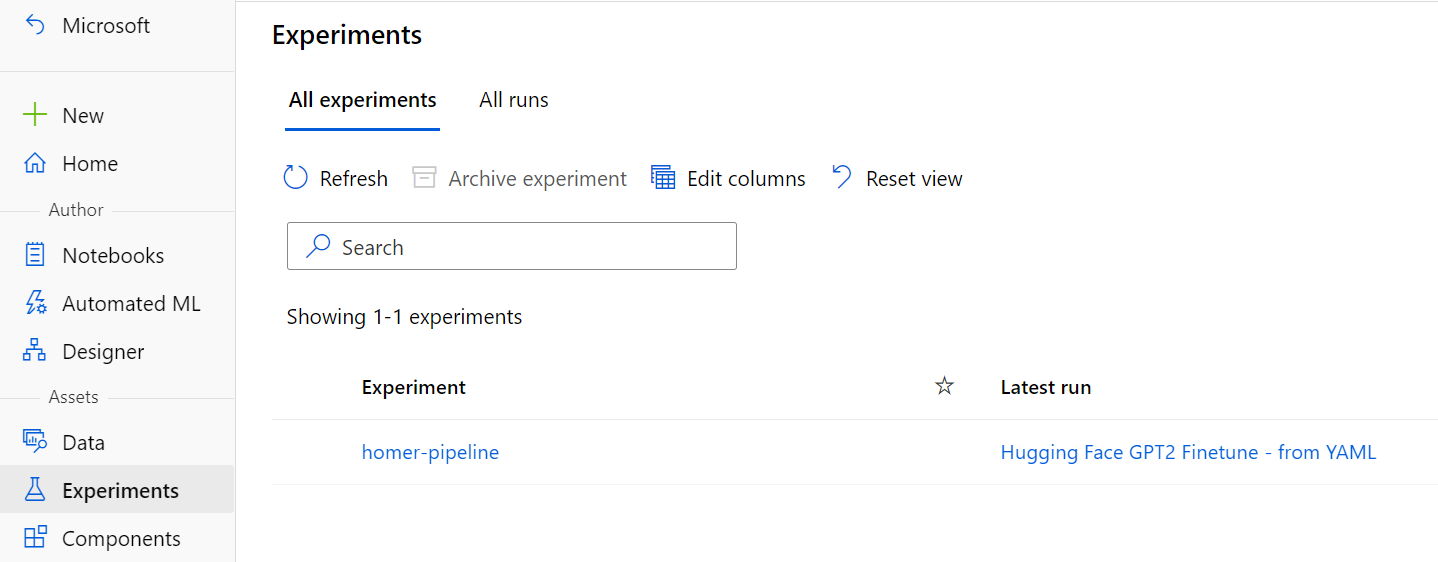
You can check progress by going to the "Experiments" section in the Azure ML Studio, and clicking on the experiment name: