You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Hi, this is my GSoC project to add digit and text recognition samples.
Status Update:
The detailed tutorial of OCR models usage method and how to train your own OCR model have been added to the doc/tutorials/dnn/dnn_OCR/dnn_OCR.markdown.
1. digit recognition
Take the live image from the camera, use connected component analysis to detect potential regions with each digit, and use the LeNet to classify.
With CPU only (i5-8300), it can achieve 12 FPS.
2. scene text recognition
My laptop environment is CPU: i5-8300, GPU: 1050, Ubuntu 18
Take the live image from the camera, use EAST as text detector. After getting the detector output, crop these bounding box as the input of the text recognizer based on VGG Net. Finally, print the result near the box. Using GPU can achieve around 9FPS.
After loading the model into OpenCV, test the performance of the text recognition model on different data sets. And the result is filled in following table:
@zihaomu, thank you very much! I've tested your code and it works great!
Can you, please, also update text_detection.py to use the same model for detection and add OCR part?
@vpisarev Thank you for your reply.
Indeed, the implementation of text_detection.py does have errors. In order not to affect this PR of GSoC, I have created a new PR #17992.
Add this suggestion to a batch that can be applied as a single commit.This suggestion is invalid because no changes were made to the code.Suggestions cannot be applied while the pull request is closed.Suggestions cannot be applied while viewing a subset of changes.Only one suggestion per line can be applied in a batch.Add this suggestion to a batch that can be applied as a single commit.Applying suggestions on deleted lines is not supported.You must change the existing code in this line in order to create a valid suggestion.Outdated suggestions cannot be applied.This suggestion has been applied or marked resolved.Suggestions cannot be applied from pending reviews.Suggestions cannot be applied on multi-line comments.Suggestions cannot be applied while the pull request is queued to merge.Suggestion cannot be applied right now. Please check back later.
Hi, this is my GSoC project to add digit and text recognition samples.
Status Update:
The detailed tutorial of OCR models usage method and how to train your own OCR model have been added to the doc/tutorials/dnn/dnn_OCR/dnn_OCR.markdown.
1. digit recognition
Take the live image from the camera, use connected component analysis to detect potential regions with each digit, and use the LeNet to classify.
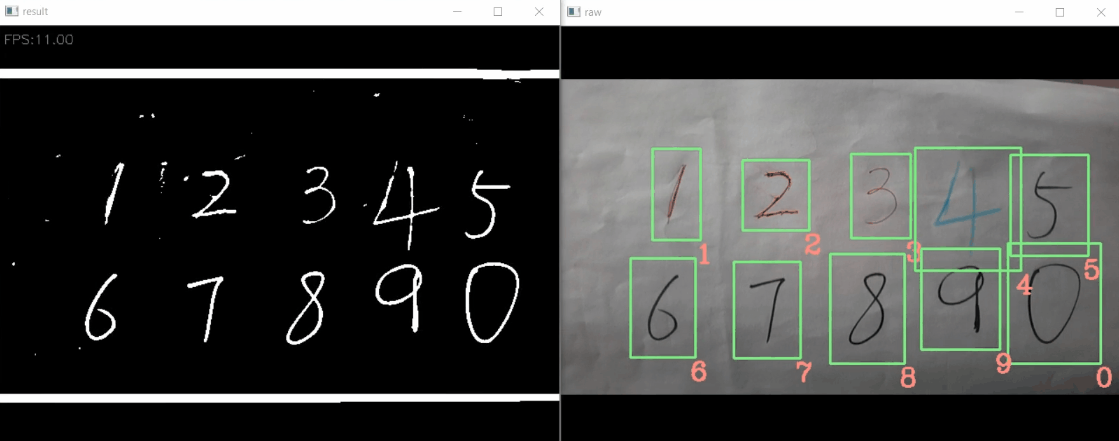
With CPU only (i5-8300), it can achieve 12 FPS.
2. scene text recognition
My laptop environment is CPU: i5-8300, GPU: 1050, Ubuntu 18
Take the live image from the camera, use EAST as text detector. After getting the detector output, crop these bounding box as the input of the text recognizer based on VGG Net. Finally, print the result near the box. Using GPU can achieve around 9FPS.
After loading the model into OpenCV, test the performance of the text recognition model on different data sets. And the result is filled in following table:
These pre-trained models can be found here https://drive.google.com/drive/folders/1cTbQ3nuZG-EKWak6emD_s8_hHXWz7lAr?usp=sharing. The FPS in the table is the performance of the text recognition model on my computer, and does not include the text detection model.
Pull Request Readiness Checklist
See details at https://github.com/opencv/opencv/wiki/How_to_contribute#making-a-good-pull-request
Patch to opencv_extra has the same branch name.