| CARVIEW |
Navigation Menu
-
Notifications
You must be signed in to change notification settings - Fork 1k
Releases: autogluon/autogluon
v1.4.0
76a36ccCompare
Version 1.4.0
We are happy to announce the AutoGluon 1.4.0 release!
AutoGluon 1.4.0 introduces massive new features and improvements to both tabular and time series modules. In particular, we introduce the extreme preset to TabularPredictor, which sets a new state of the art for predictive performance by a massive margin on datasets with fewer than 30000 samples. We have also added 5 new tabular model families in this release: RealMLP, TabM, TabPFNv2, TabICL, and Mitra. We also release MLZero 1.0, aka AutoGluon-Assistant, an end-to-end automated data science agent that brings AutoGluon from 3 lines of code to 0. For more details, refer to the highlights section below.
This release contains 70 commits from 18 contributors! See the full commit change-log here: 1.3.1...1.4.0
Join the community:
Get the latest updates:


This release supports Python versions 3.9, 3.10, 3.11, and 3.12. Loading models trained on older versions of AutoGluon is not supported. Please re-train models using AutoGluon 1.4.0.
Spotlight
AutoGluon Tabular Extreme Preset
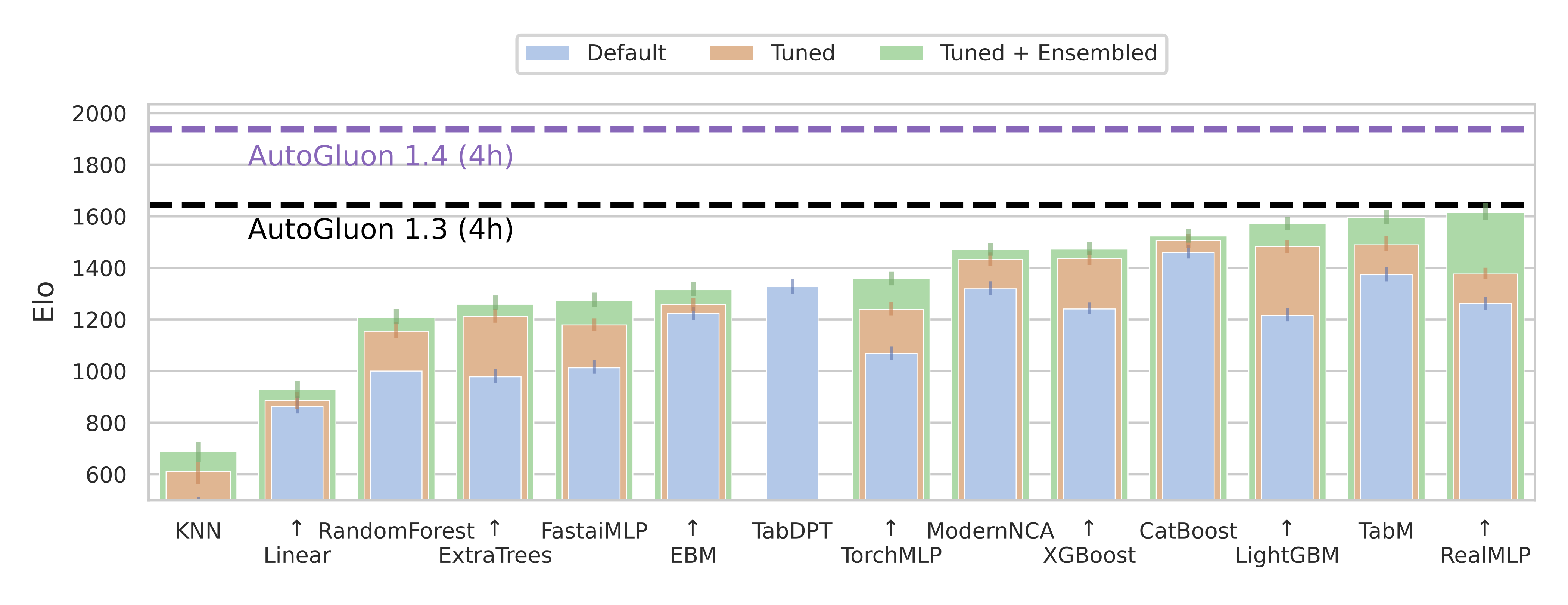
AutoGluon 1.4.0 introduces a new tabular preset, extreme_quality aka extreme.
AutoGluon's extreme preset is the largest singular improvement to AutoGluon's predictive performance in the history of the package, even larger than the improvement seen in AutoGluon 1.0 compared to 0.8.
This preset achieves an 88% win-rate vs Autogluon 1.3 best_quality for datasets with fewer than 10000 samples, and a 290 Elo improvement overall on TabArena (shown in the figure above).
Try it out in 3 lines of code:
from autogluon.tabular import TabularPredictor
predictor = TabularPredictor(label="class").fit("train.csv", presets="extreme")
predictions = predictor.predict("test.csv")The extreme preset leverages a new model portfolio, which is an improved version of the TabArena ensemble shown in Figure 6a of the TabArena paper. It consists of many new model families added in this release: TabPFNv2, TabICL, Mitra, TabM, as well as tree methods: CatBoost, LightGBM, XGBoost. This preset is not only more accurate, it also requires much less training time. AutoGluon's extreme preset in 5 minutes is able to outperform best ran for 4 hours.
In order to get the most out of the extreme preset, a CUDA compatible GPU is required, ideally with 32+ GB vRAM.
Note that inference time can be longer than best, but with a GPU it is very reasonable. The extreme portfolio is only leveraged for datasets with at most 30000 samples. For larger datasets, we continue to use the best_quality portfolio. The preset requires downloading foundation model weights for TabPFNv2, TabICL, and Mitra during fit. If you don't have an internet connection, ensure that you pre-download the weights of the models to be able to use them during fit.
This preset is considered experimental for this release, and may change without warning in a future release.
TabArena and new models: TabPFNv2, TabICL, TabM, RealMLP
🚨What is SOTA on tabular data, really? We are excited to introduce TabArena, a living benchmark for machine learning on IID tabular data with:
📊 an online leaderboard accepting submissions
📑 carefully curated datasets (real, predictive, tabular, IID, permissive license)
📈 strong tree-based, deep learning, and foundation models
⚙️ best practices for evaluation (inner CV, outer CV, early stopping)
ℹ️ 𝐎𝐯𝐞𝐫𝐯𝐢𝐞𝐰
Leaderboard: https://tabarena.ai
Paper: https://arxiv.org/abs/2506.16791
Code: https://tabarena.ai/code
💡 𝐌𝐚𝐢𝐧 𝐢𝐧𝐬𝐢𝐠𝐡𝐭𝐬:
➡️ Recent deep learning models, RealMLP and TabM, have marginally overtaken boosted trees with weighted ensembling, although they have slower train+inference times. With defaults or regular tuning, CatBoost takes the #1 spot.
➡️ Foundation models TabPFNv2 and TabICL are only applicable to a subset of datasets, but perform very strongly on these. They have a large inference time and still need tuning/ensembling to get the top spot (for TabPFNv2).
➡️ The winner does NOT take it all. By using a weighted ensemble of different model types from TabArena, we can significantly outperform the current state of the art on tabular data, AutoGluon 1.3.
➡️ These insights have been directly incorporated into the AutoGluon 1.4 release with the extreme preset, dramatically advancing the state of the art!
➡️ The models TabPFNv2, TabICL, TabM, and RealMLP have been added to AutoGluon! To use them, run pip install autogluon[tabarena] and use the extreme preset.
🎯TabArena is a living benchmark. With the community, we will continually update it!
TabArena Authors: Nick Erickson, Lennart Purucker, Andrej Tschalzev, David Holzmüller, Prateek Mutalik Desai, David Salinas, Frank Hutter
AutoGluon Assistant (MLZero)
Multi-Agent System Powered by LLMs for End-to-end Multimodal ML Automation
We are excited to present the AutoGluon Assistant 1.0 release. Level up from v0.1: v1.0 expands beyond tabular data to robustly support any and many modalities, including image, text, tabular, audio and mixed-data pipelines. This aligns precisely with the MLZero vision of comprehensive, modality-agnostic ML automation.
AutoGluon Assistant v1.0 is now synonymous with "MLZero: A Multi-Agent System for End-to-end Machine Learning Automation" (arXiv:2505.13941), the end-to-end, zero-human-intervention AutoML agent framework for multimodal data. Built on a novel multi-agent architecture using LLMs, MLZero handles perception, memory (semantic & episodic), code generation, execution, and iterative debugging — seamlessly transforming raw multimodal inputs into high-quality ML/DL pipelines.
- No-code: Users define tasks purely through natural language ("classify images of cats vs dogs with custom labels"), and MLZero delivers complete solutions with zero manual configuration or technical expertise required.
- Built on proven foundations: MLZero generates code using established, high-performance ML libraries rather than reinventing the wheel, ensuring robust solutions while maintaining the flexibility to easily integrate new libraries as they emerge.
- Research-grade performance: MLZero is extensively validated across 25 challenging tasks spanning diverse data modalities, MLZero outperforms the competing methods by a large margin with a success rate of 0.92 (+263.6%) and an average rank of 2.42.
| Dataset | Ours | Codex CLI | Codex CLI (+reasoning) | AIDE | DS-Agent | AK |
|---|---|---|---|---|---|---|
| Avg. Rank ↓ | 2.42 | 8.04 | 5.76 | 6.16 | 8.26 | 8.28 |
| Rel. Time ↓ | 1.0 | 0.15 | 0.23 | 2.83 | N/A | 4.82 |
| Success ↑ | 92.0% | 14.7% | 69.3% | 25.3% | 13.3% | 14.7% |
- Modular and extensible architecture: We separate the design and implementation of each agent and prompts for different purposes, with a centralized manager coordinating them. This makes adding or editing agents, prompts, and workflows straightforward and intuitive for future development.
We’re also excited to introduce the newly redesigned WebUI in v1.0, now with a streamlined chatbot-style interface that makes interacting with MLZero intuitive and engaging. Furthermore, we’re also bringing MCP (Model Control Protocol) integration to MLZero, enabling seamless remote orchestration of AutoML pipelines through a standardized protocol。
AutoGluon Assistant is supported on Python 3.8 - 3.11 and is available on Linux.
Installation:
pip install uv
uv pip install autogluon.assistant>=1.0To use CLI:
mlzero -i <input_data_dir>To use webUI:
mlzero-backend # command to start backend
mlzero-frontend # command to start frontend on 8509 (default)To use MCP:
# server
mlzero-backend # command to start backend
bash ./src/autogluon/mcp/server/start_services.sh # This will start the service—run it in a new terminal.
# client
python ./src/autogluon/mcp/client/server.pyMLZero Authors: Haoyang Fang, Boran Han, Steven Shen, Nick Erickson, Xiyuan Zhang, Su Zhou, Anirudh Dagar, Jiani Zhang, Ali Caner Turkmen, Cuixiong Hu, [Huzefa Rangwala](http...
Contributors
Assets 2
v1.3.1
b98e992Compare
Version 1.3.1
We are happy to announce the AutoGluon 1.3.1 release!
AutoGluon 1.3.1 contains several bug fixes and logging improvements for Tabular, TimeSeries, and Multimodal modules.
This release contains 9 commits from 5 contributors! See the full commit change-log here: 1.3.0...1.3.1
Join the community:
Get the latest updates:
This release supports Python versions 3.9, 3.10, 3.11, and 3.12. Loading models trained on older versions of AutoGluon is not supported. Please re-train models using AutoGluon 1.3.1.
General
Tabular
Fixes and Improvements
- Fix TabPFN dependency. @fplein #5119
- Fix incorrect reference to positive_class in TabularPredictor constructor. @celestinoxp #5129
TimeSeries
Fixes and Improvements
- Fix ensemble weights format for printing. @shchur #5132
- Avoid masking the
scalerparam with the defaulttarget_scalervalue forDirectTabularandRecursiveTabularmodels. @shchur #5131 - Fix
FutureWarningin leaderboard and evaluate methods. @shchur #5126
Multimodal
Fixes and Improvements
Documentation and CI
- Add release instructions for pasting whats_new release notes. @Innixma #5111
- Update docker image to use 1.3 release base. @tonyhoo #5130
Contributors
Full Contributor List (ordered by # of commits):
New Contributors
Contributors
Assets 2
v1.3.0
4b54a24Compare
Version 1.3.0
We are happy to announce the AutoGluon 1.3.0 release!
AutoGluon 1.3 focuses on stability & usability improvements, bug fixes, and dependency upgrades.
This release contains 144 commits from 20 contributors! See the full commit change-log here: v1.2.0...v1.3.0
Join the community:
Get the latest updates:
Loading models trained on older versions of AutoGluon is not supported. Please re-train models using AutoGluon 1.3.
Highlights
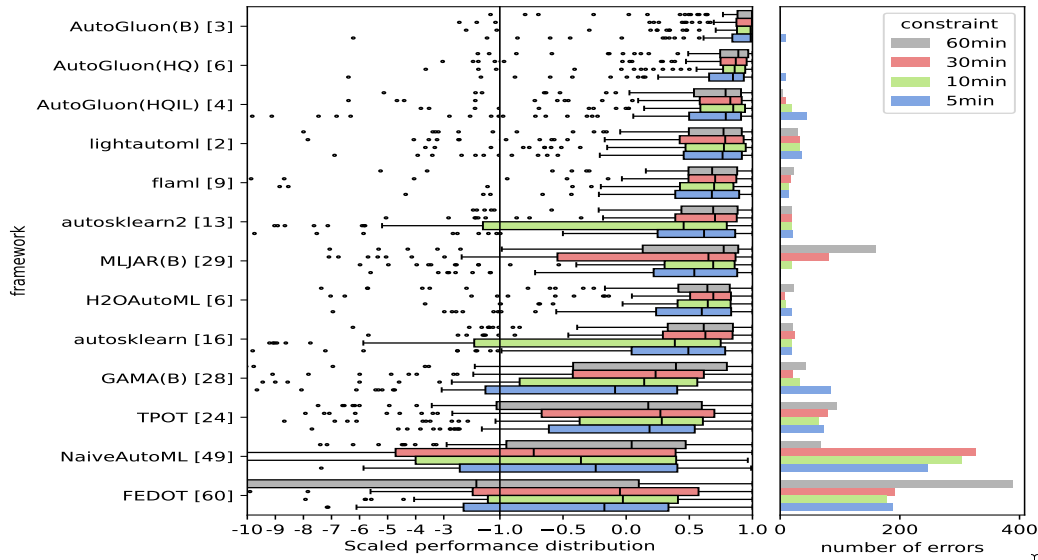
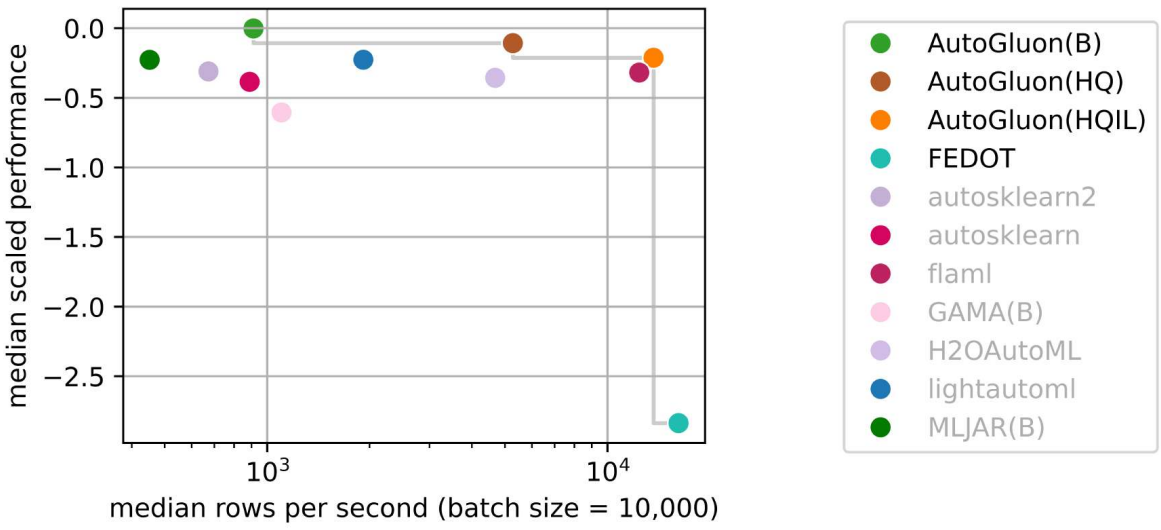
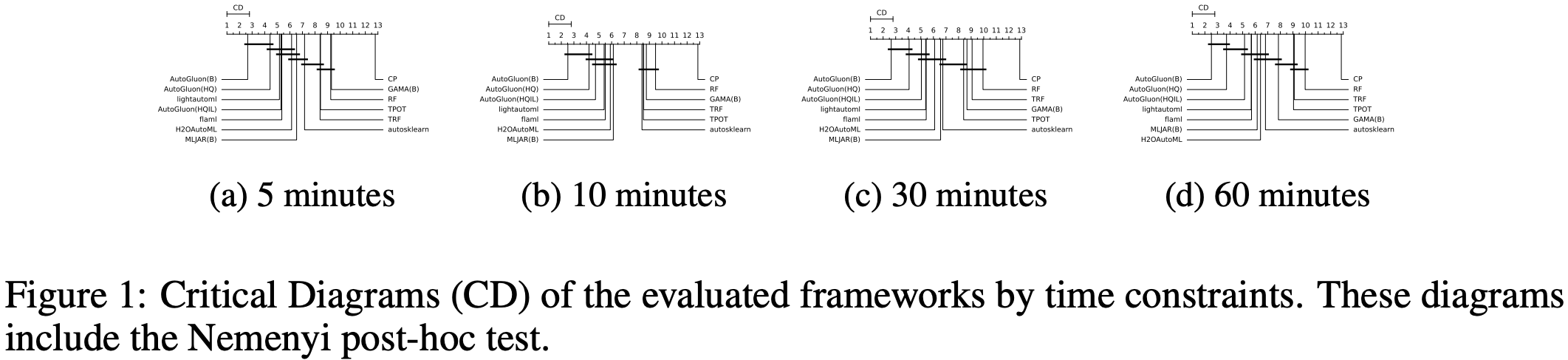
AutoGluon-Tabular is the state of the art in the AutoML Benchmark 2025!
The AutoML Benchmark 2025, an independent large-scale evaluation of tabular AutoML frameworks, showcases AutoGluon 1.2 as the state of the art AutoML framework! Highlights include:
- AutoGluon's rank statistically significantly outperforms all AutoML systems via the Nemenyi post-hoc test across all time constraints.
- AutoGluon with a 5 minute training budget outperforms all other AutoML systems with a 1 hour training budget.
- AutoGluon is pareto efficient in quality and speed across all evaluated presets and time constraints.
- AutoGluon with
presets="high", infer_limit=0.0001(HQIL in the figures) achieves >10,000 samples/second inference throughput while outperforming all methods. - AutoGluon is the most stable AutoML system. For "best" and "high" presets, AutoGluon has 0 failures on all time budgets >5 minutes.
AutoGluon Multimodal's "Bag of Tricks" Update
We are pleased to announce the integration of a comprehensive "Bag of Tricks" update for AutoGluon's MultiModal (AutoMM). This significant enhancement substantially improves multimodal AutoML performance when working with combinations of image, text, and tabular data. The update implements various strategies including multimodal model fusion techniques, multimodal data augmentation, cross-modal alignment, tabular data serialization, better handling of missing modalities, and an ensemble learner that integrates these techniques for optimal performance.
Users can now access these capabilities through a simple parameter when initializing the MultiModalPredictor after following the instruction here to download the checkpoints:
from autogluon.multimodal import MultiModalPredictor
predictor = MultiModalPredictor(label="label", use_ensemble=True)
predictor.fit(train_data=train_data)We express our gratitude to @zhiqiangdon, for this substantial contribution that enhances AutoGluon's capabilities for handling complex multimodal datasets. Here is the corresponding research paper describing the technical details: Bag of Tricks for Multimodal AutoML with Image, Text, and Tabular Data.
Deprecations and Breaking Changes
The following deprecated TabularPredictor methods have been removed in the 1.3.0 release (deprecated in 1.0.0, raise in 1.2.0, removed in 1.3.0). Please use the new names:
persist_models->persist,unpersist_models->unpersist,get_model_names->model_names,get_model_best->model_best,get_pred_from_proba->predict_from_proba,get_model_full_dict->model_refit_map,get_oof_pred_proba->predict_proba_oof,get_oof_pred->predict_oof,get_size_disk_per_file->disk_usage_per_file,get_size_disk->disk_usage,get_model_names_persisted->model_names(persisted=True)
The following logic has been deprecated starting in 1.3.0 and will log a FutureWarning. Functionality will be changed in a future release:
- (FutureWarning)
TabularPredictor.delete_models()will default todry_run=Falsein a future release (currentlydry_run=True). Please ensure you explicitly specifydry_run=Truefor the existing logic to remain in future releases. @Innixma (#4905)
General
Improvements
- (Major) Internal refactor of
AbstractTrainerclass to improve extensibility and reduce code duplication. @canerturkmen (#4804, #4820, #4851)
Dependencies
- Update numpy to
>=1.25.0,<2.3.0. @tonyhoo, @Innixma, @suzhoum (#5020, #5056, #5072) - Update spacy to
<3.9. @tonyhoo (#5072) - Update scikit-learn to
>=1.4.0,<1.7.0. @tonyhoo, @Innixma (#5029, #5045) - Update psutil to
>=5.7.3,<7.1.0. @tonyhoo (#5020) - Update s3fs to
>=2024.2,<2026. @tonyhoo (#5020) - Update ray to
>=2.10.0,<2.45. @suzhoum, @celestinoxp, @tonyhoo (#4714, #4887, #5020) - Update tabpfn to
>=0.1.11,<0.2. @Innixma (#4787) - Update torch to
>=2.2,<2.7. @FireballDWF (#5000) - Update lightning to
>=2.2,<2.7. @FireballDWF (#5000) - Update torchmetrics to
>=1.2.0,<1.8. @zkalson, @tonyhoo (#4720, #5020) - Update torchvision to
>=0.16.0,<0.22.0. @FireballDWF (#5000) - Update accelerate to
>=0.34.0,<2.0. @FireballDWF (#5000) - Update lightgbm to
>=4.0,<4.7. @tonyhoo (#4960) - Update fastai to
>=2.3.1,<2.9. @Innixma (#4988) - Update jsonschema to
>=4.18,<4.24. @tonyhoo (#5020) - Update scikit-image to
>=0.19.1,<0.26.0. @tonyhoo (#5020) - Update omegaconf to
>=2.1.1,<2.4.0. @tonyhoo (#5020) - Update pytorch-metric-learning to
>=1.3.0,<2.9. @tonyhoo (#5020) - Update nltk to
>=3.4.5,<4.0. @tonyhoo (#5020) - Update pytesseract to
>=0.3.9,<0.4. @tonyhoo (#5020) - Update nvidia-ml-py3 to
>=7.352.0,<8.0. @tonyhoo (#5020) - Update datasets to
>=2.16.0,<3.6.0. @tonyhoo (#5020) - Update onnxruntime to
>=1.17.0,<1.22.0. @tonyhoo (#5020) - Update tensorrt to
>=8.6.0,<10.9.1. @tonyhoo (#5020) - Update xgboost to
>=2.0,<3.1. @tonyhoo (#5020) - Update imodels to
>=1.3.10,<2.1.0. @tonyhoo (#5020) - Update statsforecast to
>=1.7.0,<2.0.2. @tonyhoo (#5020)
Documentation
- Updating documented python version's in CONTRIBUTING.md. @celestinoxp (#4796)
- Refactored CONTRIBUTING.md to have up-to-date information. @Innixma (#4798)
- Fix various typos. @celestinoxp (#4819)
- Minor doc improvements. @tonyhoo (#4894, #4929)
Fixes and Improvements
- Fix colab AutoGluon source install with
uv. @tonyhoo (#4943, #4964) - Make
full_install.shuse the script directory instead of the working directory. @Innixma (#4933) - Add
test_version.pyto ensure proper version format for releases. @Innixma (#4799) - Fix
setup_outputdirto work with s3 paths. @suzhoum (#4734) - Ensure
setup_outputdiralways makes a new directory ifpath_suffix != Noneandpath=None. @Innixma (#4903) - Check
cuda.is_available()before callingcuda.device_count()to avoid warnings. @Innixma (#4902) - Log a warning if mlflow autologging is enabled. @shchur (#4925)
- Fix rare ZeroDivisionError edge-case in
get_approximate_df_mem_usage. @shchur (#5083) - Minor fixes & improvements. @suzhoum @Innixma @canerturkmen @PGijsbers @tonyhoo (#4744, #4785, #4822, #4860, #4891, #5012, #5047)
Tabular
Removed Models
- Removed vowpalwabbit model (key:
VW) and optional dependency (autogluon.tabular[vowpalwabbit]), as the model implemented in AutoGluon was not widely used and was largely unmaintained. @Innixma (#4975) - Removed TabTransformer model (key:
TRANSF), as the model implemented in AutoGluon was heavily outdated, unmaintained since 2020, and generally outperformed by FT-Transformer (key:FT_TRANSFORMER). @Innixma (#4976) - Removed tabpfn from
autogluon.tabular[tests]install in preparation for futuretabpfn>=2.xsupport. @Innixma (#4974)
New Features
- Add support for regression stratified splits via binning. @Innixma (#4586)
- Add
TabularPredictor.model_hyperparameters(model)that returns the hyperparameters of a model. @Innixma (#4901) - Add
TabularPredictor.model_info(model)that returns the metadata of a model. @Innixma (#4901) - (Experimental) Add
plot_leaderboard.pyto visualize performance over training time of the predictor. @Innixma (#4907) - (Major) Add internal
ag_model_registryto improve the tracking of supported model families and their capabilities. @Innixma (#4913, #5057, #5107) - Add
raise_on_model_failureTabularPredictor.fitargument, default to False. If True, will immediately raise the original exception if a model raises an exception during fit instead of continuing to the next model. Setting to True is very helpful when using a debugger to try to figure out why a model is failing, as otherwise exceptions are handled by AutoGluon which isn't desired while debugging. @Innixma (#4937, #5055)
Documentation
- Minor tutorial doc improvements/fixes. @kbulygin @Innixma (#4779, #4777)
- Add Kaggle competition results. @Innixma (#4717, #4770)
Fixes and Improvements
- (Major) Ensure bagged refits in refit_full works properly (crashed in v1.2.0 due to a bug). @Innixma (#4870)
- Improve XGBoost and CatBoost memory estimates. @Innixma (#5090)
- Improve LightGBM memory estimates. @Innixma (#5101)
- Fixed plot_tabular_models save path. @everdark (#4711)
- Fixed balanced_accuracy metric edge-case exception + added uni...
Contributors
Assets 2
v1.2.0
082d8baCompare
Version 1.2.0
We're happy to announce the AutoGluon 1.2.0 release.
AutoGluon 1.2 contains massive improvements to both Tabular and TimeSeries modules, each achieving a 70% win-rate vs AutoGluon 1.1. This release additionally adds support for Python 3.12 and drops support for Python 3.8.
This release contains 186 commits from 19 contributors! See the full commit change-log here: v1.1.1...v1.2.0
Join the community:
Get the latest updates:
Loading models trained on older versions of AutoGluon is not supported. Please re-train models using AutoGluon 1.2.
For Tabular, we encompass the primary enhancements of the new TabPFNMix tabular foundation model and parallel fit strategy into the new "experimental_quality" preset to ensure a smooth transition period for those who wish to try the new cutting edge features. We will be using this release to gather feedback prior to incorporating these features into the other presets. We also introduce a new stack layer model pruning technique that results in a 3x inference speedup on small datasets with zero performance loss and greatly improved post-hoc calibration across the board, particularly on small datasets.
For TimeSeries, we introduce Chronos-Bolt, our latest foundation model integrated into AutoGluon, with massive improvements to both accuracy and inference speed compared to Chronos, along with fine-tuning capabilities. We also added covariate regressor support!
We are also excited to announce AutoGluon-Assistant (AG-A), our first venture into the realm of Automated Data Science.
See more details in the Spotlights below!
Spotlight
AutoGluon Becomes the Golden Standard for Competition ML in 2024
Before diving into the new features of 1.2, we would like to start by highlighting the wide-spread adoption AutoGluon has received on competition ML sites like Kaggle in 2024. Across all of 2024, AutoGluon was used to achieve a top 3 finish in 15 out of 18 tabular Kaggle competitions, including 7 first place finishes, and was never outside the top 1% of private leaderboard placements, with an average of over 1000 competing human teams in each competition. In the $75,000 prize money 2024 Kaggle AutoML Grand Prix, AutoGluon was used by the 1st, 2nd, and 3rd place teams, with the 2nd place team led by two AutoGluon developers: Lennart Purucker and Nick Erickson! For comparison, in 2023 AutoGluon achieved only 1 first place and 1 second place solution. We attribute the bulk of this increase to the improvements seen in AutoGluon 1.0 and beyond.

We'd like to emphasize that these results are achieved via human expert interaction with AutoGluon and other tools, and often includes manual feature engineering and hyperparameter tuning to get the most out of AutoGluon. To see a live tracking of all AutoGluon solution placements on Kaggle, refer to our AWESOME.md ML competition section where we provide links to all solution write-ups.
AutoGluon-Assistant: Automating Data Science with AutoGluon and LLMs
We are excited to share the release of a new AutoGluon-Assistant module (AG-A), powered by LLMs from AWS Bedrock or OpenAI. AutoGluon-Assistant empowers users to solve tabular machine learning problems using only natural language descriptions, in zero lines of code with our simple user interface. Fully autonomous AG-A outperforms 74% of human ML practitioners in Kaggle competitions and secured a live top 10 finish in the $75,000 prize money 2024 Kaggle AutoML Grand Prix competition as Team AGA 🤖!
TabularPredictor presets="experimental_quality"
TabularPredictor has a new "experimental_quality" preset that offers even better predictive quality than "best_quality". On the AutoMLBenchmark, we observe a 70% winrate vs best_quality when running for 4 hours on a 64 CPU machine. This preset is a testing ground for cutting edge features and models which we hope to incorporate into best_quality for future releases. We recommend to use a machine with at least 16 CPU cores, 64 GB of memory, and a 4 hour+ time_limit to get the most benefit out of experimental_quality. Please let us know via a GitHub issue if you run into any problems running the experimental_quality preset.
TabPFNMix: A Foundation Model for Tabular Data
TabPFNMix is the first tabular foundation model created by the AutoGluon team, and was pre-trained exclusively on synthetic data.
The model builds upon the prior work of TabPFN and TabForestPFN. TabPFNMix to the best of our knowledge achieves a new state-of-the-art for individual open source model performance on datasets between 1000 and 10000 samples, and also supports regression tasks! Across the 109 classification datasets with less than or equal to 10000 training samples in TabRepo, fine-tuned TabPFNMix outperforms all prior models, with a 64% win-rate vs the strongest tree model, CatBoost, and a 61% win-rate vs fine-tuned TabForestPFN.
The model is available via the TABPFNMIX hyperparameters key, and is used in the new experimental_quality preset. We recommend using this model for datasets smaller than 50,000 training samples, ideally with a large time limit and 64+ GB of memory. This work is still in the early stages, and we appreciate any feedback from the community to help us iterate and improve for future releases. You can learn more by going to our HuggingFace model page for the model (tabpfn-mix-1.0-classifier, tabpfn-mix-1.0-regressor). Give us a like on HuggingFace if you want to see more! A paper is planned in future to provide more details about the model.
fit_strategy="parallel"
AutoGluon's TabularPredictor now supports the new fit argument fit_strategy and the new "parallel" option, enabled by default in the new experimental_quality preset. For machines with 16 or more CPU cores, the parallel fit strategy offers a major speedup over the previous "sequential" strategy. We estimate with 64 CPU cores that most datasets will experience a 2-4x speedup, with the speedup getting larger as CPU cores increase.
Chronos-Bolt⚡: a 250x faster, more accurate Chronos model
Chronos-Bolt is our latest foundation model for forecasting that has been integrated into AutoGluon. It is based on the T5 encoder-decoder architecture and has been trained on nearly 100 billion time series observations. It chunks the historical time series context into patches of multiple observations, which are then input into the encoder. The decoder then uses these representations to directly generate quantile forecasts across multiple future steps—a method known as direct multi-step forecasting. Chronos-Bolt models are up to 250 times faster and 20 times more memory-efficient than the original Chronos models of the same size.
The following plot compares the inference time of Chronos-Bolt against the original Chronos models for forecasting 1024 time series with a context length of 512 observations and a prediction horizon of 64 steps.

Chronos-Bolt models are not only significantly faster but also more accurate than the original Chronos models. The following plot reports the probabilistic and point forecasting performance of Chronos-Bolt in terms of the Weighted Quantile Loss (WQL) and the Mean Absolute Scaled Error (MASE), respectively, aggregated over 27 datasets (see the Chronos paper for details on this benchmark). Remarkably, despite having no prior exposure to these datasets during training, the zero-shot Chronos-Bolt models outperform commonly used statistical models and deep learning models that have been trained on these datasets (highlighted by *). Furthermore, they also perform better than other FMs, denoted by a +, which indicates that these models were pretrained on certain datasets in our benchmark and are not entirely zero-shot. Notably, Chronos-Bolt (Base) also surpasses the original Chronos (Large) model in terms of the forecasting accuracy while being over 600 times faster.

Chronos-Bolt models are now available through AutoGluon in four sizes—Tiny (9M), Mini (21M), Small (48M), and Base (205M)—and can also be used on the CPU. With the addition of Chronos-B...
Contributors
Assets 2
v1.1.1
65d1430Compare
Version 1.1.1
We're happy to announce the AutoGluon 1.1.1 release.
AutoGluon 1.1.1 contains bug fixes and logging improvements for Tabular, TimeSeries, and Multimodal modules, as well as support for PyTorch 2.2 and 2.3.
Join the community:
Get the latest updates:
This release supports Python versions 3.8, 3.9, 3.10, and 3.11. Loading models trained on older versions of AutoGluon is not supported. Please re-train models using AutoGluon 1.1.1.
This release contains 52 commits from 11 contributors!
General
- Add support for PyTorch 2.2. @prateekdesai04 (#4123)
- Add support for PyTorch 2.3. @suzhoum (#4239, #4256)
- Upgrade GluonTS to 0.15.1. @shchur (#4231)
Tabular
Note: Trying to load a TabularPredictor with a FastAI model trained on a previous AutoGluon release will raise an exception when calling predict due to a fix in the model-interals.pkl path. Please ensure matching versions.
- Fix deadlock when
num_gpus>0and dynamic_stacking is enabled. @Innixma (#4208) - Improve decision threshold calibration. @Innixma (#4136, #4137)
- Improve dynamic stacking logging. @Innixma (#4208, #4262)
- Fix regression metrics (other than RMSE and MSE) being calculated incorrectly for LightGBM early stopping. @Innixma (#4174)
- Fix custom multiclass metrics being calculated incorrectly for LightGBM early stopping. @Innixma (#4250)
- Fix HPO crashing with NN_TORCH and FASTAI models. @Innixma (#4232)
- Improve NN_TORCH runtime estimate. @Innixma (#4247)
- Add infer throughput logging. @Innixma (#4200)
- Disable sklearnex for linear models due to observed performance degradation. @Innixma (#4223)
- Improve sklearnex logging verbosity in Kaggle. @Innixma (#4216)
- Rename cached version file to version.txt. @Innixma (#4203)
- Add refit_full support for Linear models. @Innixma (#4222)
- Add AsTypeFeatureGenerator detailed exception logging. @Innixma (#4251, #4252)
TimeSeries
- Ensure prediction_length is stored as an integer. @shchur (#4160)
- Fix tabular model preprocessing failure edge-case. @shchur (#4175)
- Fix loading of Tabular models failure if predictor moved to a different directory. @shchur (#4171)
- Fix cached predictions error when predictor saved on-top of an existing predictor. @shchur (#4202)
- Use AutoGluon forks of Chronos models. @shchur (#4198)
- Fix off-by-one bug in Chronos inference. @canerturkmen (#4205)
- Rename cached version file to version.txt. @Innixma (#4203)
- Use correct target and quantile_levels in fallback model for MLForecast. @shchur (#4230)
Multimodal
- Fix bug in CLIP's image feature normalization. @Harry-zzh (#4114)
- Fix bug in text augmentation. @Harry-zzh (#4115)
- Modify default fine-tuning tricks. @Harry-zzh (#4166)
- Add PyTorch version warning for object detection. @FANGAreNotGnu (#4217)
Docs and CI
- Add competition solutions to
AWESOME.md. @Innixma @shchur (#4122, #4163, #4245) - Fix PDF classification tutorial. @zhiqiangdon (#4127)
- Add AutoMM paper citation. @zhiqiangdon (#4154)
- Add pickle load warning in all modules and tutorials. @shchur (#4243)
- Various minor doc and test fixes and improvements. @tonyhoo @shchur @lovvge @Innixma @suzhoum (#4113, #4176, #4225, #4233, #4235, #4249, #4266)
Contributors
Full Contributor List (ordered by # of commits):
@Innixma @shchur @Harry-zzh @suzhoum @zhiqiangdon @lovvge @rey-allan @prateekdesai04 @canerturkmen @FANGAreNotGnu @tonyhoo
New Contributors
- @lovvge made their first contribution in 57a15fc
- @rey-allan made their first contribution in #4145
Contributors
Assets 2
v0.8.3
3a28994Compare
What's Changed
v0.8.3 is a patch release to address security vulnerabilities.
See the full commit change-log here: 0.8.2...0.8.3
This version supports Python versions 3.8, 3.9, and 3.10.
Changes
Contributors
Assets 2
v1.1.0
04a390cCompare
Version 1.1.0
We're happy to announce the AutoGluon 1.1 release.
AutoGluon 1.1 contains major improvements to the TimeSeries module, achieving a 60% win-rate vs AutoGluon 1.0 through the addition of Chronos, a pretrained model for time series forecasting, along with numerous other enhancements. The other modules have also been enhanced through new features such as Conv-LORA support and improved performance for large tabular datasets between 5 - 30 GB in size. For a full breakdown of AutoGluon 1.1 features, please refer to the feature spotlights and the itemized enhancements below.
Join the community:
Get the latest updates:
This release supports Python versions 3.8, 3.9, 3.10, and 3.11. Loading models trained on older versions of AutoGluon is not supported. Please re-train models using AutoGluon 1.1.
This release contains 125 commits from 20 contributors!
Full Contributor List (ordered by # of commits):
@shchur @prateekdesai04 @Innixma @canerturkmen @zhiqiangdon @tonyhoo @AnirudhDagar @Harry-zzh @suzhoum @FANGAreNotGnu @nimasteryang @lostella @dassaswat @afmkt @npepin-hub @mglowacki100 @ddelange @LennartPurucker @taoyang1122 @gradientsky
Special thanks to @ddelange for their continued assistance with Python 3.11 support and Ray version upgrades!
Spotlight
AutoGluon Achieves Top Placements in ML Competitions!
AutoGluon has experienced wide-spread adoption on Kaggle since the AutoGluon 1.0 release.
AutoGluon has been used in over 130 Kaggle notebooks and mentioned in over 100 discussion threads in the past 90 days!
Most excitingly, AutoGluon has already been used to achieve top ranking placements in multiple competitions with thousands of competitors since the start of 2024:
| Placement | Competition | Author | Date | AutoGluon Details | Notes |
|---|---|---|---|---|---|
| 🥉 Rank 3/2303 (Top 0.1%) | Steel Plate Defect Prediction | Samvel Kocharyan | 2024/03/31 | v1.0, Tabular | Kaggle Playground Series S4E3 |
| 🥈 Rank 2/93 (Top 2%) | Prediction Interval Competition I: Birth Weight | Oleksandr Shchur | 2024/03/21 | v1.0, Tabular | |
| 🥈 Rank 2/1542 (Top 0.1%) | WiDS Datathon 2024 Challenge #1 | lazy_panda | 2024/03/01 | v1.0, Tabular | |
| 🥈 Rank 2/3746 (Top 0.1%) | Multi-Class Prediction of Obesity Risk | Kirderf | 2024/02/29 | v1.0, Tabular | Kaggle Playground Series S4E2 |
| 🥈 Rank 2/3777 (Top 0.1%) | Binary Classification with a Bank Churn Dataset | lukaszl | 2024/01/31 | v1.0, Tabular | Kaggle Playground Series S4E1 |
| Rank 4/1718 (Top 0.2%) | Multi-Class Prediction of Cirrhosis Outcomes | Kirderf | 2024/01/01 | v1.0, Tabular | Kaggle Playground Series S3E26 |
We are thrilled that the data science community is leveraging AutoGluon as their go-to method to quickly and effectively achieve top-ranking ML solutions! For an up-to-date list of competition solutions using AutoGluon refer to our AWESOME.md, and don't hesitate to let us know if you use AutoGluon in a competition!
Chronos, a pretrained model for time series forecasting
AutoGluon-TimeSeries now features Chronos, a family of forecasting models pretrained on large collections of open-source time series datasets that can generate accurate zero-shot predictions for new unseen data. Check out the new tutorial to learn how to use Chronos through the familiar TimeSeriesPredictor API.
General
- Refactor project README & project Tagline @Innixma (#3861, #4066)
- Add AWESOME.md competition results and other doc improvements. @Innixma (#4023)
- Pandas version upgrade. @shchur @Innixma (#4079, #4089)
- PyTorch, CUDA, Lightning version upgrades. @prateekdesai04 @canerturkmen @zhiqiangdon (#3982, #3984, #3991, #4006)
- Ray version upgrade. @ddelange @tonyhoo (#3774, #3956)
- Scikit-learn version upgrade. @prateekdesai04 (#3872, #3881, #3947)
- Various dependency upgrades. @Innixma @tonyhoo (#4024, #4083)
TimeSeries
Highlights
AutoGluon 1.1 comes with numerous new features and improvements to the time series module. These include highly requested functionality such as feature importance, support for categorical covariates, ability to visualize forecasts, and enhancements to logging. The new release also comes with considerable improvements to forecast accuracy, achieving 60% win rate and 3% average error reduction compared to the previous AutoGluon version. These improvements are mostly attributed to the addition of Chronos, improved preprocessing logic, and native handling of missing values.
New Features
- Add Chronos pretrained forecasting model (tutorial). @canerturkmen @shchur @lostella (#3978, #4013, #4052, #4055, #4056, #4061, #4092, #4098)
- Measure the importance of features & covariates on the forecast accuracy with
TimeSeriesPredictor.feature_importance(). @canerturkmen (#4033, #4087) - Native missing values support (no imputation required). @shchur (#3995, #4068, #4091)
- Add support for categorical covariates. @shchur (#3874, #4037)
- Improve inference speed by persisting models in memory with
TimeSeriesPredictor.persist(). @canerturkmen (#4005) - Visualize forecasts with
TimeSeriesPredictor.plot(). @shchur (#3889) - Add
RMSLEevaluation metric. @canerturkmen (#3938) - Enable logging to file. @canerturkmen (#3877)
- Add option to keep lightning logs after training with
keep_lightning_logshyperparameter. @shchur (#3937)
Fixes and Improvements
- Automatically preprocess real-valued covariates @shchur (#4042, #4069)
- Add option to skip model selection when only one model is trained. @shchur (#4002)
- Ensure all metrics handle missing values in target @shchur (#3966)
- Fix bug when loading a GPU trained model on a CPU machine @shchur (#3979)
- Fix inconsistent random seed. @canerturkmen @shchur (#3934, #4099)
- Fix crash when calling .info after load. @afmkt (#3900)
- Fix leaderboard crash when no models trained. @shchur (#3849)
- Add prototype TabRepo simulation artifact generation. @shchur (#3829)
- Fix refit_full bug. @shchur (#3820)
- Documentation improvements, hide deprecated methods. @shchur (#3764, #4054, #4098)
- Minor fixes. @canerturkmen, @shchur, @AnirudhDagar (#4009, #4040, #4041, #4051, #4070, #4094)
AutoMM
Highlights
AutoMM 1.1 introduces the innovative Conv-LoRA, a parameter-efficient fine-tuning (PEFT) method stemming from our latest paper presented at ICLR 2024, titled "Convolution Meets LoRA: Parameter Efficient Finetuning for Segment Anything Model". Conv-LoRA is designed for fine-tuning the Segment Anything Model, exhibiting superior performance compared to previous PEFT approaches, such as LoRA and visual prompt tuning, across various semantic segmentation tasks in diverse domains including natural images, agriculture, remote sensing, and healthcare. Check out our Conv-LoRA example.
New Features
- Added Conv-LoRA, a new parameter efficient fine-tuning method. @Harry-zzh @zhiqiangdon (#3933, #3999, #4007, #4022, #4025)
- Added support for new column type: 'image_base64_str'. @Harry-zzh @zhiqiangdon (#3867)
- Added support for loading pre-trained weights in FT-Transformer. @taoyang1122 @zhiqiangdon (#3859)
Fixes and Improvements
- Fixed bugs in semantic segmentation. @Harry-zzh (#3801, #3812)
- Fixed crashes when using F1 metric. @suzhoum (#3822)
- Fixed bugs in PEFT methods. @Harry-zzh (#3840)
- Accelerated object detection training by ~30% for the high_quality and best_quality presets. @FANGAreNotGnu (#3970)
- Depreciated Grounding-DINO @FANGAreNotGnu (#3974)
- Fixed lightning upgrade issues @zhiqiangdon (#3991)
- Fixed using f1, f1_macr...
Contributors
Assets 2
v1.0.0
caccb0bCompare
Version 1.0.0
Today is finally the day... AutoGluon 1.0 has arrived!! After over four years of development and 2061 commits from 111 contributors, we are excited to share with you the culmination of our efforts to create and democratize the most powerful, easy to use, and feature rich automated machine learning system in the world.
AutoGluon 1.0 comes with transformative enhancements to predictive quality resulting from the combination of multiple novel ensembling innovations, spotlighted below. Besides performance enhancements, many other improvements have been made that are detailed in the individual module sections.
This release supports Python versions 3.8, 3.9, 3.10, and 3.11. Loading models trained on older versions of AutoGluon is not supported. Please re-train models using AutoGluon 1.0.
This release contains 223 commits from 17 contributors!
Full Contributor List (ordered by # of commits):
@shchur, @zhiqiangdon, @Innixma, @prateekdesai04, @FANGAreNotGnu, @yinweisu, @taoyang1122, @LennartPurucker, @Harry-zzh, @AnirudhDagar, @jaheba, @gradientsky, @melopeo, @ddelange, @tonyhoo, @canerturkmen, @suzhoum
Join the community:
Get the latest updates:
Spotlight
Tabular Performance Enhancements
AutoGluon 1.0 features major enhancements to predictive quality, establishing a new state-of-the-art in Tabular modeling. To the best of our knowledge, AutoGluon 1.0 marks the largest leap forward in the state-of-the-art for tabular data since the original AutoGluon paper from March 2020. The enhancements come primarily from two features: Dynamic stacking to mitigate stacked overfitting, and a new learned model hyperparameters portfolio via Zeroshot-HPO, obtained from the newly released TabRepo ensemble simulation library. Together, they lead to a 75% win-rate compared to AutoGluon 0.8 with faster inference speed, lower disk usage, and higher stability.
AutoML Benchmark Results
OpenML released the official 2023 AutoML Benchmark results on November 16th, 2023. Their results show AutoGluon 0.8 as the state-of-the-art in AutoML systems across a wide variety of tasks: "Overall, in terms of model performance, AutoGluon consistently has the highest average rank in our benchmark." We now showcase that AutoGluon 1.0 achieves far superior results even to AutoGluon 0.8!
Below is a comparison on the OpenML AutoML Benchmark across 1040 tasks. LightGBM, XGBoost, and CatBoost results were obtained via AutoGluon, and other methods are from the official AutoML Benchmark 2023 results. AutoGluon 1.0 has a 95%+ win-rate against traditional tabular models, including a 99% win-rate vs LightGBM and a 100% win-rate vs XGBoost. AutoGluon 1.0 has between an 82% and 94% win-rate against other AutoML systems. For all methods, AutoGluon is able to achieve >10% average loss improvement (Ex: Going from 90% accuracy to 91% accuracy is a 10% loss improvement). AutoGluon 1.0 achieves first place in 63% of tasks, with lightautoml having the second most at 12% (AutoGluon 0.8 previously took first place 48% of the time). AutoGluon 1.0 even achieves a 7.4% average loss improvement over AutoGluon 0.8!
| Method | AG Winrate | AG Loss Improvement | Rescaled Loss | Rank | Champion |
|---|---|---|---|---|---|
| AutoGluon 1.0 (Best, 4h8c) | - | - | 0.04 | 1.95 | 63% |
| lightautoml (2023, 4h8c) | 84% | 12.0% | 0.2 | 4.78 | 12% |
| H2OAutoML (2023, 4h8c) | 94% | 10.8% | 0.17 | 4.98 | 1% |
| FLAML (2023, 4h8c) | 86% | 16.7% | 0.23 | 5.29 | 5% |
| MLJAR (2023, 4h8c) | 82% | 23.0% | 0.33 | 5.53 | 6% |
| autosklearn (2023, 4h8c) | 91% | 12.5% | 0.22 | 6.07 | 4% |
| GAMA (2023, 4h8c) | 86% | 15.4% | 0.28 | 6.13 | 5% |
| CatBoost (2023, 4h8c) | 95% | 18.2% | 0.28 | 6.89 | 3% |
| TPOT (2023, 4h8c) | 91% | 23.1% | 0.4 | 8.15 | 1% |
| LightGBM (2023, 4h8c) | 99% | 23.6% | 0.4 | 8.95 | 0% |
| XGBoost (2023, 4h8c) | 100% | 24.1% | 0.43 | 9.5 | 0% |
| RandomForest (2023, 4h8c) | 97% | 25.1% | 0.53 | 9.78 | 1% |
Not only is AutoGluon more accurate in 1.0, it is also more stable thanks to our new usage of Ray subprocesses during low-memory training, resulting in 0 task failures on the AutoML Benchmark.
AutoGluon 1.0 is capable of achieving the fastest inference throughput of any AutoML system while still obtaining state-of-the-art results. By specifying the infer_limit fit argument, users can trade off between accuracy and inference speed to meet their needs.
As seen in the below plot, AutoGluon 1.0 sets the Pareto Frontier for quality and inference throughput, achieving Pareto Dominance compared to all other AutoML systems. AutoGluon 1.0 High achieves superior performance to AutoGluon 0.8 Best with 8x faster inference and 8x less disk usage!
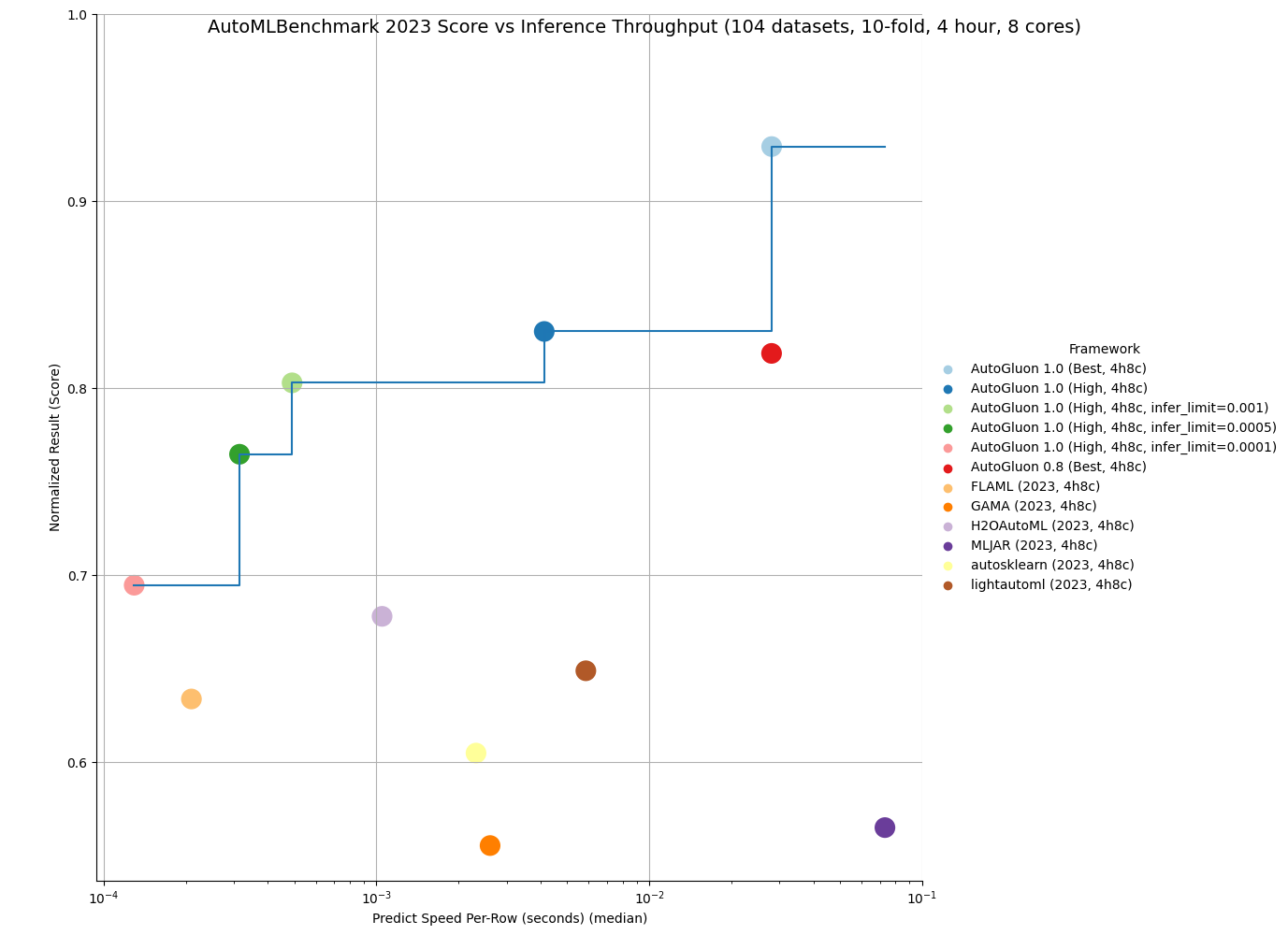
You can get more details on the results here.
We are excited to see what our users can accomplish with AutoGluon 1.0's enhanced performance.
As always, we will continue to improve AutoGluon in future releases to push the boundaries of AutoML forward for all.
AutoGluon Multimodal (AutoMM) Highlights in One Figure

AutoMM Uniqueness
AutoGluon Multimodal (AutoMM) distinguishes itself from other open-source AutoML toolboxes like AutosSklearn, LightAutoML, H2OAutoML, FLAML, MLJAR, TPOT and GAMA, which mainly focus on tabular data for classification or regression. AutoMM is designed for fine-tuning foundation models across multiple modalities—image, text, tabular, and document, either individually or combined. It offers extensive capabilities for tasks like classification, regression, object detection, named entity recognition, semantic matching, and image segmentation. In contrast, other AutoML systems generally have limited support for image or text, typically using a few pretrained models like EfficientNet or hand-crafted rules like bag-of-words as feature extractors. AutoMM provides a uniquely comprehensive and versatile approach to AutoML, being the only AutoML system to support flexible multimodality and support for a wide range of tasks. A comparative table detailing support for various data modalities, tasks, and model types is provided below.
| Data | Task | Model | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| image | text | tabular | document | any combination | classification | regression | object detection | semantic matching | named entity recognition | image segmentation | traditional models | deep learning models | foundation models | |
| LightAutoML | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||
| H2OAutoML | ✓ | ✓ | ✓ | ✓ | ||||||||||
| FLAML | ✓ | ✓ | &ch... |
Contributors
Assets 2
v0.8.2
973289cCompare
Version 0.8.2
v0.8.2 is a hot-fix release to pin pydantic version to avoid crashing during HPO
As always, only load previously trained models using the same version of AutoGluon that they were originally trained on.
Loading models trained in different versions of AutoGluon is not supported.
See the full commit change-log here: 0.8.1...0.8.2
This version supports Python versions 3.8, 3.9, and 3.10.
Changes
- codespell: action, config + some typos fixed @yarikoptic @yinweisu (#3323)
- Unpin sentencepiece @zhiqiangdon (#3368)
- Pin pydantic @yinweisu (3370)
Contributors
Assets 2
v0.8.1
0461ceeCompare
Version 0.8.1
v0.8.1 is a bug fix release.
As always, only load previously trained models using the same version of AutoGluon that they were originally trained on.
Loading models trained in different versions of AutoGluon is not supported.
See the full commit change-log here: 0.8.0...0.8.1
This version supports Python versions 3.8, 3.9, and 3.10.
Changes
Documentation improvements
- Update google analytics property @gidler (#3330)
- Add Discord Link @Innixma (#3332)
- Add community section to website front page @Innixma (#3333)
- Update Windows Conda install instructions @gidler (#3346)
- Add some missing Colab buttons in tutorials @gidler (#3359)
Bug Fixes / General Improvements
- Move PyMuPDF to optional @Innixma @zhiqiangdon (#3331)
- Remove TIMM in core setup @Innixma (#3334)
- Update persist_models max_memory 0.1 -> 0.4 @Innixma (#3338)
- Lint modules @yinweisu (#3337, #3339, #3344, #3347)
- Remove fairscale @zhiqiangdon (#3342)
- Fix refit crash @Innixma (#3348)
- Fix
DirectTabularmodel failing for some metrics; hide warnings produced byAutoARIMA@shchur (#3350) - Pin dependencies @yinweisu (#3358)
- Reduce per gpu batch size for AutoMM high_quality_hpo to avoid out of memory error for some corner cases @zhiqiangdon (#3360)
- Fix HPO crash by setting reuse_actor to False @yinweisu (#3361)