| CARVIEW |
Navigation Menu
-
Notifications
You must be signed in to change notification settings - Fork 5k
Add option for merging cluster updates #3941
New issue
Have a question about this project? Sign up for a free GitHub account to open an issue and contact its maintainers and the community.
By clicking “Sign up for GitHub”, you agree to our terms of service and privacy statement. We’ll occasionally send you account related emails.
Already on GitHub? Sign in to your account
Conversation
97d3e83 to
139a684
Compare
This change introduces a new configuration parameter for clusters, `time_between_updates`. If this is set, all cluster updates — membership changes, metadata changes on endpoints, or healtcheck state changes — that happen within a `time_between_updates` duration will be merged and delivered at once when the duration ends. This is useful for big clusters (> 1k endpoints) using the subset LB. Partially addresses envoyproxy#3929. Signed-off-by: Raul Gutierrez Segales <rgs@pinterest.com>
139a684 to
431a634
Compare
|
I think arguably we should just improve the performance of updates rather than requiring end users have to configure workarounds like this. OTOH, this seems expedient, so no objections. |
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Couple questions, but this looks good.
| postThreadLocalClusterUpdate(cluster, priority, hosts_added, hosts_removed); | ||
|
|
||
| // Should we coalesce updates? | ||
| if (cluster.info()->lbConfig().has_time_between_updates()) { |
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Is it worth moving this logic into it's own function to keep this lambda easier to read?
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
thought about but then decided against since it isn't that big.. I am happy either way, your call.
|
|
||
| // Ensure the coalesced updates were applied. | ||
| timer->callback_(); | ||
| EXPECT_EQ(1, factory_.stats_.counter("cluster_manager.coalesced_updates").value()); |
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Is it worth validating that the hosts were actually removed?
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
you mean from the intermediate sets? or that added/removed were > 0 (i think they can be 0)?
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
ah, now i know what you meant
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
hmm, might be a bit messy
|
@zuercher @mattklein123 note that i added the new option, @htuch I agree, and we are planning on exploring/working-on making the subset LB thread-aware next. But I think this knob is almost a neccessity for very big clusters where you want protection against healthcheck avalanches. |
|
I suggest renaming this to a more intuitive form like cds_update_merge_window or something along those lines? |
* move coalesced update logic into its own method * extend the unit test to exercise a follow-up delivery of updates Signed-off-by: Raul Gutierrez Segales <rgs@pinterest.com>
|
@rshriram hmm should we just call it |
| PendingUpdates() {} | ||
| Event::TimerPtr timer; | ||
| std::unordered_set<HostSharedPtr> added; | ||
| std::unordered_set<HostSharedPtr> removed; |
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
hmm, these should probably be ordered so that the merged update sees hosts in the same order it would have seen them if they were delivered immediately?
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
maybe not that important and not worth the cost...
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
It's probably easier to debug I think if there is some determinism here. There is no major performance advantage of unordered here most likely.
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
to keep it ordered we'd have to keep two sets (added/removed) to check uniqueness (e.g.: that a host isn't added/removed twice) and we'd also have to keep two vectors (added/removed) to preserve the order..... or am I missing an ordered set data structure hidding somewhere? :-)
|
|
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Yeah, overall this is a very economical way of improving efficiency here.
api/envoy/api/v2/cds.proto
Outdated
| // and delivered in one shot when the duration expires. The start of the duration is when the | ||
| // first update happens. This is useful for big clusters, with potentially noisy deploys that | ||
| // might trigger excessive CPU usage due to a constant stream of healthcheck state changes or | ||
| // membership updates. |
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
... "by default this is not configured and updates apply immediately.".
| updates->added.insert(hosts_added.begin(), hosts_added.end()); | ||
| updates->removed.insert(hosts_removed.begin(), hosts_removed.end()); | ||
|
|
||
| // If there's no timer, create one. |
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Won't this delay the first update after a long period of silence? Should we instead apply immediately in this case? I think we can then just keep track of the last time we applied and only add to a pending queue if < window length.
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
addressed in the latest commit
* fix documentation * rename config knob to `update_merge_window` * apply updates immediately when outside of window Signed-off-by: Raul Gutierrez Segales <rgs@pinterest.com>
Signed-off-by: Raul Gutierrez Segales <rgs@pinterest.com>
| // Has an update_merge_window gone by since the last update? If so, don't schedule | ||
| // the update so it can be applied immediately. | ||
| auto delta = std::chrono::steady_clock::now() - updates->last_updated; | ||
| uint64_t delta_ms = std::chrono::duration_cast<std::chrono::milliseconds>(delta).count(); |
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Nit: these intermediate vars can be const.
| return false; | ||
| } | ||
|
|
||
| // Record the updates — preserving order — that should be applied when the timer fires. |
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
FWIW, I was arguing for just a deterministic ordering, e.g. using set vs. unordered_set in my earlier comment, rather than arrival ordering. But, I don't mind if we stick with this.
| } | ||
|
|
||
| // Record the updates — preserving order — that should be applied when the timer fires. | ||
| for (auto host : hosts_added) { |
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Nit: const auto& host here and below.
| // Record the updates — preserving order — that should be applied when the timer fires. | ||
| for (auto host : hosts_added) { | ||
| if (updates->added_seen.count(host) != 1) { | ||
| updates->added.push_back(host); |
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Where does added_seen and removed_seen get inserted into?
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
oops, good catch
| } | ||
|
|
||
| for (auto host : hosts_removed) { | ||
| if (updates->removed_seen.count(host) != 1) { |
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
What about sequences of ops in which a host is added, removed and added back again? I'm not sure if we have correctness here.
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
hmm, becomes trickier with ordering so we should probably avoid that. if we just kept the sets, we can handle cancellations (added/removed). we'd have to decide if want drop cancelled out ops (i say yes).
| cm_stats_.coalesced_updates_.inc(); | ||
|
|
||
| // Reset everything. | ||
| updates->timer = nullptr; |
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
I see, you nuke it here. I'd suggest keeping the timer alive and just doing disable/enable, it probably doesn't matter, but one less wasted allocation/free.
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
it would be nice to avoid the allocation/free pair, but then we'd have to check if the timer is enabled or not by looking at the last update timestamp... at which point things become a bit more involved. Preferences?
On a related note, the logic to apply an update immediately if the last update happened within a merge window should probably also check if a timer exists (e.g. timer != nullptr). Otherwise, updates could lose their order.
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
I guess we can add a bool to track the timer's state
| PendingUpdatesPtr updates) { | ||
| // Deliver pending updates. | ||
| postThreadLocalClusterUpdate(cluster, priority, updates->added, updates->removed); | ||
| cm_stats_.coalesced_updates_.inc(); |
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Should we also count non-coalesced updates? Or can we just infer this from total?
| @@ -361,6 +362,23 @@ class ClusterManagerImpl : public ClusterManager, Logger::Loggable<Logger::Id::u | |||
| // This map is ordered so that config dumping is consistent. | |||
| typedef std::map<std::string, ClusterDataPtr> ClusterMap; | |||
|
|
|||
| struct PendingUpdates { | |||
| PendingUpdates() {} | |||
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Not needed?
| std::unordered_set<HostSharedPtr> removed_seen; | ||
| MonotonicTime last_updated; | ||
| }; | ||
| typedef std::shared_ptr<PendingUpdates> PendingUpdatesPtr; |
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Nit: prefer using here.
| // Ensure the coalesced updates were applied again. | ||
| timer->callback_(); | ||
| EXPECT_EQ(2, factory_.stats_.counter("cluster_manager.coalesced_updates").value()); | ||
| } |
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
I think a test that has add, remove, add for the same host would be interesting.
* use const when possible * use using instead of typedef * drop ordering of add/remove insertions * handle cancelled pairs of (add, remove) * remove unneeded struct constructor Will follow-up in another commit tomorrow with: * reuse timer instead of destroying/reallocating * add test for host added/removed/added Signed-off-by: Raul Gutierrez Segales <rgs@pinterest.com>
Signed-off-by: Raul Gutierrez Segales <rgs@pinterest.com>
| @@ -361,6 +362,20 @@ class ClusterManagerImpl : public ClusterManager, Logger::Loggable<Logger::Id::u | |||
| // This map is ordered so that config dumping is consistent. | |||
| typedef std::map<std::string, ClusterDataPtr> ClusterMap; | |||
|
|
|||
| struct PendingUpdates { | |||
| Event::TimerPtr timer; | |||
| std::set<HostSharedPtr> added; | |||
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
This hashes on the pointer value I think. Do we have a guarantee that two identical hosts will have the same pointer value from the caller of scheduleUpdate()?
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
yeah good point, we should track the host's address instead.
| if (updates->removed.count(host) == 1) { | ||
| updates->removed.erase(host); | ||
| } else { | ||
| updates->added.insert(host); |
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Do we want to take the latest value for host, since it might have a new health status etc? As this works today, if we do add(unhealthy), add(healthy), only the unhealthy status for the host is set, since insert just returns false the second time.
Again, as with add, remove, add, I think we would benefit from some more tests here.
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
yes, we want the latest value. and yep, will follow-up with comprehensive testing.
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
@htuch note that a health change does not get treated as an add/remove:
https://github.com/envoyproxy/envoy/blob/master/source/common/upstream/upstream_impl.cc#L902
That is, if (only) a host's health flipped you'd get called with no new added/removed hosts in which case we'd still do the right thing. Which is, calling postThreadLocalClusterUpdate() with empty vectors for hosts_added and hosts_removed.
Anyway, I'll back all of these claims with tests.
|
Hey just noting that I would like to review thus but I probably won't be able to until Friday. Sorry for the delay. |
* track host by address, not by its shared_ptr * ensure we always publish updates with the latest copy of the host Signed-off-by: Raul Gutierrez Segales <rgs@pinterest.com>
Ensure we are calling `postThreadLocalClusterUpdate` at the right time with the right values. I'll follow-up with tests that exercise as many updates combinations as possible: * added/removed/added * unhealthy/healthy/added/removed/added * etc. Just wanted to get the basic helpers in place. Signed-off-by: Raul Gutierrez Segales <rgs@pinterest.com>
|
@mattklein123 yeah no worries, things are still moving around and I still need to add significant test coverage for this. Thanks! |
Signed-off-by: Raul Gutierrez Segales <rgs@pinterest.com>
* add/remove/add -> add * remove/add/remove -> remove * existing host changes multiple times (e.g.: failed/active/failed -> failed) * metadata/metadata/metadata -> latest metadata * weight/weight/weight -> latest weight Signed-off-by: Raul Gutierrez Segales <rgs@pinterest.com>
|
Ok, I am starting to feel a bit more confident about this although it still needs more polish probably. I'll let the paint dry for a bit and then I'll do another pass to add more missing tests. |
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
LGTM, nice work. @htuch can you take a quick pass over the most recent set of changes?
Lets only bump `merged_updates_offwindow` if merging is on. Signed-off-by: Raul Gutierrez Segales <rgs@pinterest.com>
|
(sorry, pushed one more 1-line change to avoid a new counter when merging is disabled). |
|
@rgs1 for the last commit can you add a stat expectation in one of the tests that would have caught that? |
* renamed counters for consistency with existing counters * test for offwindow updates * test that merging related counters don't get updated when merging is disabled Signed-off-by: Raul Gutierrez Segales <rgs@pinterest.com>
|
@mattklein123 done — added 2 more tests: one for merging disabled and the other one for offwindow updates that don't trigger a merge. Also, renamed the new counters to make them more consistent with the stats that are already there. LMK what you think. |
Signed-off-by: Raul Gutierrez Segales <rgs@pinterest.com>
Signed-off-by: Raul Gutierrez Segales <rgs@pinterest.com>
|
So this is how CPU usage looks with & without merging updates: a) the first 25 minutes are without merging enabled Throughout the whole test, I am causing ~600 health checks to fail and then to immediately pass again in a loop.
That smoothness is exactly what we were looking for :-) Note that this is with a merge window of 10s. cc: @htuch @mattklein123 |
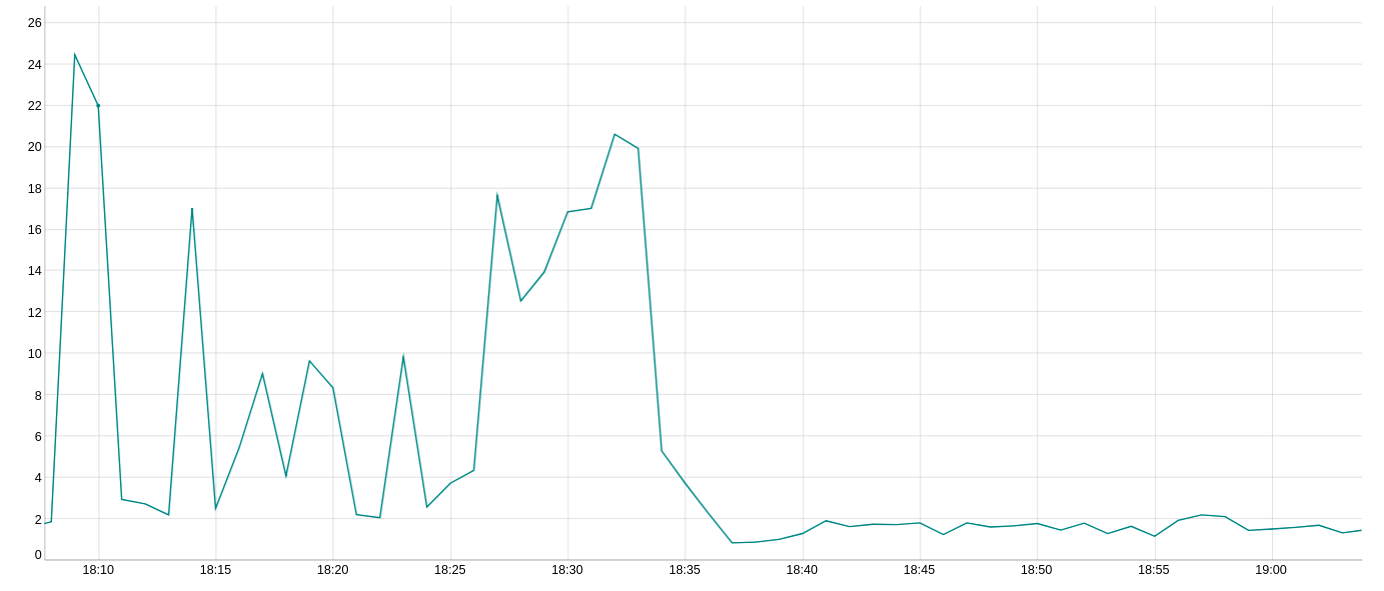
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Awesome work, great to see the graph. One last question.
| // a timer is enabled. This race condition is fine, since we'll disable the timer here and | ||
| // deliver the update immediately. | ||
|
|
||
| // Why wasn't the update scheduled for later delivery? |
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Sorry what does this comment mean? Is this just tracking the race condition? Is it worth the extra code for this? I think this should be incredibly rare but I agree it can happen.
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
It's for tracking two things:
a) did we not merge this update because we are out of a merge window? i found this stat useful while testing this out, because it tells you how often merging is not needed
b) did we had merged updates pending that we are cancelling (and delivering immediately)? also useful to know how often a merge window is cancelled before expiring.
I'd like to keep these, I think they are useful. Happy to clarify comments/names. Ideas?
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
OK makes sense. I would probably go with the stat name @htuch suggested and put the entirety of what you jus wrote in a comment here? I think that would make it clear.
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Done.
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
@rgs1 LGTM with some minor asks. Ready to ship when addressed. Thanks for the graph, nice improvement!
api/envoy/api/v2/cds.proto
Outdated
| // or metadata updates. By default, this is not configured and updates apply immediately. Also, | ||
| // the first set of updates to be seen apply immediately as well (e.g.: a new cluster). | ||
| // | ||
| // Note: merging does not apply to cluser membership changes (e.g.: adds/removes); this is |
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Nit: s/cluser/cluster/
api/envoy/api/v2/cds.proto
Outdated
| @@ -432,6 +432,17 @@ message Cluster { | |||
| ZoneAwareLbConfig zone_aware_lb_config = 2; | |||
| LocalityWeightedLbConfig locality_weighted_lb_config = 3; | |||
| } | |||
| // If set, all healthcheck/weight/metadata updates that happen within this duration will be | |||
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Nit: s/healthcheck/health check/
| // the update so it can be applied immediately. Ditto if this is not a mergeable update. | ||
| const auto delta = std::chrono::steady_clock::now() - updates->last_updated_; | ||
| const uint64_t delta_ms = std::chrono::duration_cast<std::chrono::milliseconds>(delta).count(); | ||
| const bool offwindow = delta_ms > timeout; |
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Kind of prefer out_of_merge_window for the stats names/vars to be clearer what's happening here. With recent stats optimizations happening, we can use longer names without any memory penalty.
Signed-off-by: Raul Gutierrez Segales <rgs@pinterest.com>
Signed-off-by: Raul Gutierrez Segales <rgs@pinterest.com>
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
k-r4d
This clarifies the meaning of the stats we are tracking when we don't schedule an update for merging & later delivery. Signed-off-by: Raul Gutierrez Segales <rgs@pinterest.com>
|
@htuch (oops, i stepped on your r+ by pushing updated comments). |
|
@rgs1 apologies, one last thing: Can you document the new stats here? https://www.envoyproxy.io/docs/envoy/latest/configuration/cluster_manager/cluster_stats |
Signed-off-by: Raul Gutierrez Segales <rgs@pinterest.com>
|
@mattklein123 something like d81fb7f? |
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Awesome, great work! Thank you!
|
Tested with prod traffic today. Deploys without merging updates: Deploys merging updates: No more scary spikes :-) I was also thinking that an additional safety step, although this probably gives us almost enough safety for now, would be to add support for increasing the merge window size as a response to CPU going above a threshold (using #3954). cc: @htuch @mattklein123 |
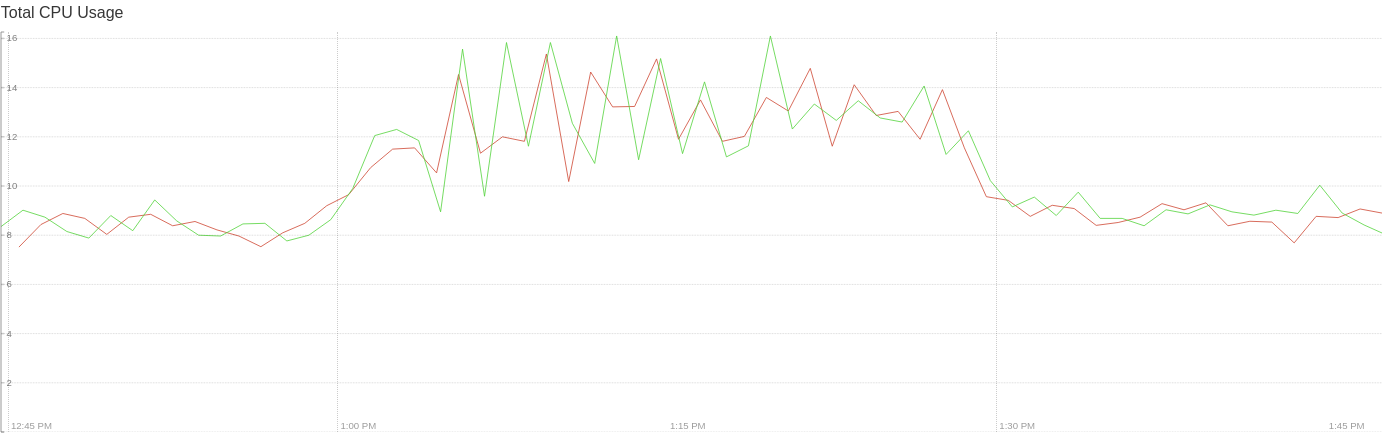
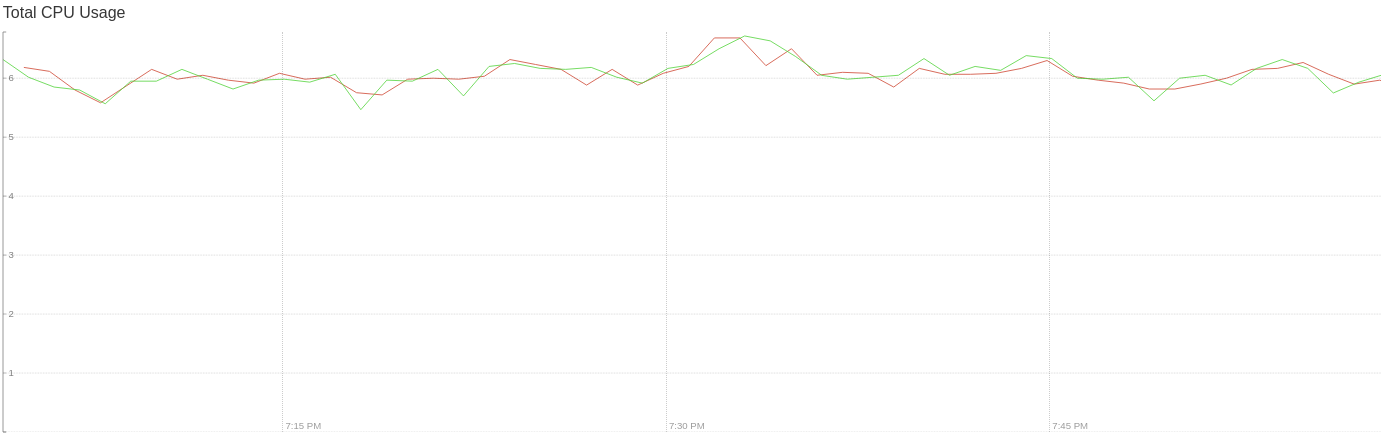
|
@rgs1 awesome on the improvement. I actually wonder if we should eventually default this feature to on at a low threshold, maybe 1s or something? I will open up a follow up issue to track. |
This change introduces a new configuration parameter for clusters,
update_merge_window.If this is set, health check/metadata/weight changes on endpoints that happen
within a
update_merge_windowduration will be merged and deliveredat once when the duration ends.
This is useful for big clusters (> 1k endpoints) using the subset LB.
Note, note, note: hosts added/removed won't be merged into a single
update because it's very hard to do this correctly right now.
Partially addresses #3929.
Signed-off-by: Raul Gutierrez Segales rgs@pinterest.com